Programa
Engenheiro de dados profissional Em Python
40 h
Eu já era engenheiro de pilha completa há alguns anos quando recebi meu primeiro projeto de engenharia de dados. Até aquele momento, eu havia programado no front-end, desenvolvido APIs e gerenciado e implantado a infraestrutura de nuvem com bastante regularidade.
Como muitos engenheiros de startups em estágio inicial, eu também havia tocado em bancos de dados, projetando uma nova tabela ou esquema aqui e ali e migrando pequenas quantidades de dados. Mas então, a empresa em que eu trabalhava começou a coletar grandes quantidades de dados e o desempenho do banco de dados começou a cair.
Nossos aplicativos estavam ficando mais lentos, a latência estava aumentando e estávamos até enfrentando tempo de inatividade durante os picos de carga. Foi um problema muito frustrante que minha equipe trabalhou duro para resolver. Foi quando aprendi muito sobre bancos de dados, como eles funcionam e como otimizá-los.
Neste blog, explicarei um dos conceitos que realmente fez a diferença na época e que tem feito muitas outras vezes nos últimos anos: sharding de banco de dados.
O sharding de banco de dados é a prática de dividir um banco de dados em subconjuntos menores, ou shards, com cada shard funcionando como seu próprio banco de dados independente. Pense nisso como se você estivesse dividindo uma planilha gigante em várias planilhas menores e mais gerenciáveis, cada uma lidando com sua própria parte da carga de trabalho.
O sharding NÃO é a resposta para todos os problemas do banco de dados.
Há outros métodos de escalonamento horizontal, como replicação ou métodos de escalonamento vertical, que são muito mais fáceis de implementar. Dê uma olhada neles antes de começar a usar o sharding!
O sharding entra em ação quando o banco de dados começa a ter dificuldades para acompanhar as demandas de um aplicativo em crescimento. Talvez sua base de usuários tenha explodido ou seu aplicativo esteja gerando grandes quantidades de dados a cada segundo. Se você estiver percebendo consultas lentas, aumento da latência ou tempo de inatividade frequente durante o pico de tráfego, provavelmente é um sinal de que seu banco de dados está atingindo seus limites.
Um grande motivo para o sharding é a escalabilidade. À medida que seus dados crescem, adicionar mais hardware a um único servidor de banco de dados (escalonamento vertical) só leva você até certo ponto, e isso pode ficar muito caro. O sharding, por outro lado, permite que você dimensione horizontalmente distribuindo dados em vários servidores, cada um lidando com uma parte da carga.
Outro motivo para você escolher o sharding é o desempenho. Mesmo que seu banco de dados possa lidar com o volume de dados, a consulta de grandes quantidades de informações pode levar tempo. Com o sharding, você trabalha com conjuntos de dados menores e mais focados, o que significa consultas mais rápidas e menor contenção de recursos.
Quanto a quando fazer o shard, geralmente é melhor considerá-lo quando seu aplicativo estiver começando a ultrapassar o que um único banco de dados pode suportar. O momento exato depende de muitas variáveis, como seus recursos e o crescimento previsto, e é uma linha um pouco tênue a ser seguida. Implementar o sharding muito cedo pode introduzir uma complexidade desnecessária quando um único banco de dados ou otimizações simples teriam sido suficientes, mas esperar muito tempo pode tornar a transição dolorosa.
Uma boa regra geral é monitorar de perto as métricas de desempenho do seu banco de dados e planejar com antecedência. Se você estiver percebendo gargalos ou um rápido crescimento de dados que possa causar problemas em um futuro próximo, provavelmente é hora de explorar o sharding. Confie em mim, adiantar-se ao problema poupará a você muitas dores de cabeça no futuro!
À primeira vista, sharding e particionamento podem parecer o mesmo conceito, pois ambos envolvem a divisão de dados em partes menores para melhor organização e desempenho. Mas os dois servem a propósitos diferentes e são adequados a diferentes escalas de operação.
O particionamento é o processo de dividir os dados em segmentos lógicos dentro da mesma instância do banco de dados. Esses segmentos, geralmente chamados de partições, podem ser baseados em critérios como intervalo, lista ou hash. Por exemplo, em um banco de dados de usuários, você pode armazenar usuários nascidos em janeiro em uma partição e em fevereiro em outra, todos no mesmo banco de dados.
O particionamento é uma excelente opção para sistemas de menor escala que ainda não precisam ser dimensionados horizontalmente. Ele melhora o desempenho da consulta ao limitar a quantidade de dados digitalizados durante as consultas e torna o gerenciamento de dados mais eficiente.
O sharding, por outro lado, leva o particionamento para o próximo nível, distribuindo esses segmentos lógicos em vários bancos de dados independentes. Cada shard é um banco de dados autônomo que lida com seus próprios dados e consultas.
Essa abordagem é ideal para sistemas de grande escala em que um único banco de dados não consegue mais lidar com a carga. O sharding oferece escalabilidade e tolerância a falhas, pois cada shard opera de forma independente.
De acordo com minha experiência, o particionamento costuma ser um trampolim para o sharding. Se você estiver começando a ter problemas de desempenho, mas seu banco de dados ainda não estiver no limite máximo, o particionamento pode fazer com que você ganhe tempo enquanto se prepara para uma solução de maior escala, como o sharding.

Se você estiver interessado em design de banco de dados, dê uma olhada neste curso completo de design de banco de dados. Você aprenderá a organizar, gerenciar e otimizar bancos de dados SQL e até mesmo a configurar diferentes tipos de particionamento.
Da mesma forma que acima, o sharding e a replicação costumam ser discutidos lado a lado, mas abordam problemas diferentes e têm casos de uso distintos.
O principal objetivo do sharding é a escalabilidade. Ao dividir os dados e a carga de trabalho em vários bancos de dados, você reduz a carga em um único banco de dados. A fragmentação garante que, à medida que seus dados crescem, você pode adicionar mais fragmentos para acomodá-los, mantendo o desempenho e reduzindo o risco de sobrecarga de um único banco de dados.
A replicação, por outro lado, envolve a criação de cópias dos mesmos dados em vários servidores. Cada réplica contém todo o conjunto de dados e pode manipular operações de leitura de forma independente, o que significa que a replicação se concentra na redundância e na disponibilidade, e não na escalabilidade.
Ao ter várias cópias do seu banco de dados, você se protege contra a perda de dados e garante que o sistema permaneça on-line mesmo que um servidor fique inoperante, mas isso não resolve o problema do aumento do volume de dados. De fato, como cada réplica armazena o conjunto de dados completo, os requisitos de armazenamento aumentam proporcionalmente ao número de réplicas. Além disso, as operaçõesde gravação do podem se tornar um gargalo, pois precisam ser aplicadas a todas as réplicas para manter os dados consistentes.
O fato é que não se trata necessariamente de um ou de outro. Na prática, muitos sistemas de grande escala usam sharding e replicação juntos. Por exemplo, um banco de dados fragmentado também pode ter réplicas de cada fragmento.
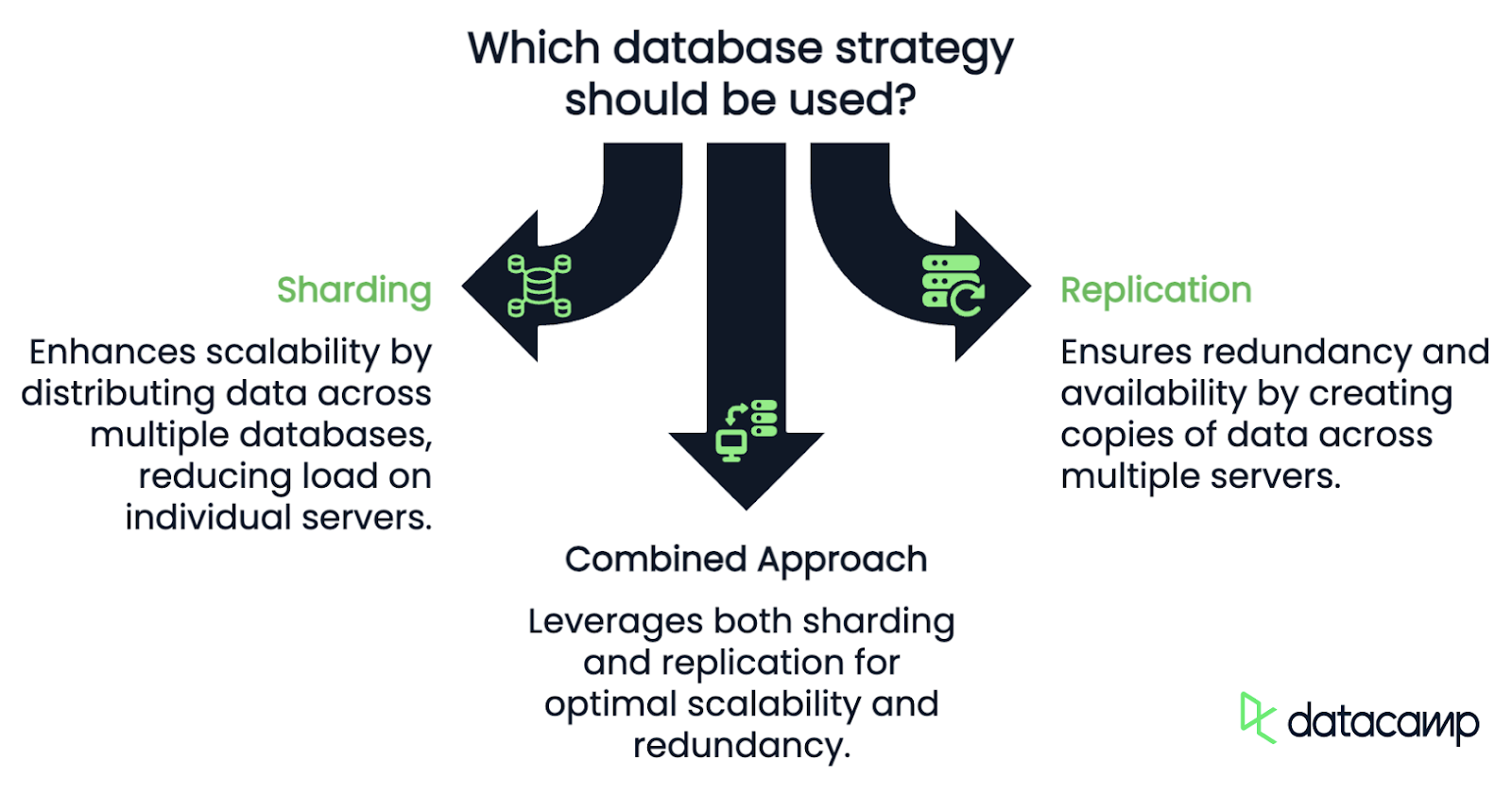
Então, como exatamente o sharding funciona? Vamos dividi-lo em três componentes principais.
A primeira etapa do sharding é descobrir como dividir seus dados. Sua lógica de particionamento é o conjunto de regras que determina como os dados são divididos entre os shards. Há várias maneiras comuns de fazer isso:
A escolha da lógica de particionamento depende das necessidades de seus dados e aplicativos. Pessoalmente, já vi o particionamento baseado em intervalo funcionar bem para dados cronológicos, como históricos de transações, enquanto os métodos baseados em hash funcionaram melhor em sistemas com cargas de trabalho imprevisíveis.
Quando os dados estiverem particionados, você precisará de uma maneira de mapear cada partição para o fragmento correspondente.
Alguns sistemas usam mapeamento estático, em que os dados são atribuídos a shards com base em regras fixas. Outros usam mapeamento dinâmico, geralmente gerenciado por um serviço central de metadados, o que facilita a adição ou remoção de fragmentos conforme necessário. De qualquer forma, o objetivo é garantir que seu sistema saiba exatamente onde encontrar qualquer dado.
Por fim, você precisa de um mecanismo para garantir que as consultas sejam enviadas para o fragmento correto. Isso é chamado de roteamento de consultas e é importante para que o sharding funcione para o seu aplicativo. Quando um aplicativo envia uma consulta, a lógica de roteamento determina qual fragmento (ou fragmentos) contém os dados relevantes e envia a solicitação para lá.
Em alguns casos, isso pode ser tão simples quanto o próprio aplicativo saber para onde enviar cada consulta com base na lógica de particionamento. Em outras configurações, uma camada de proxy ou middleware lida com o roteamento, abstraindo a complexidade do aplicativo. Trabalhei com ambas as abordagens e, embora os proxies adicionem alguma sobrecarga, eles podem poupar muito esforço a você em sistemas maiores.
Não existe uma abordagem única para o sharding. A estratégia que você escolher depende muito da estrutura dos seus dados e de como você os utiliza. Vou falar sobre alguns dos mais comuns, mas há muito mais do que três.
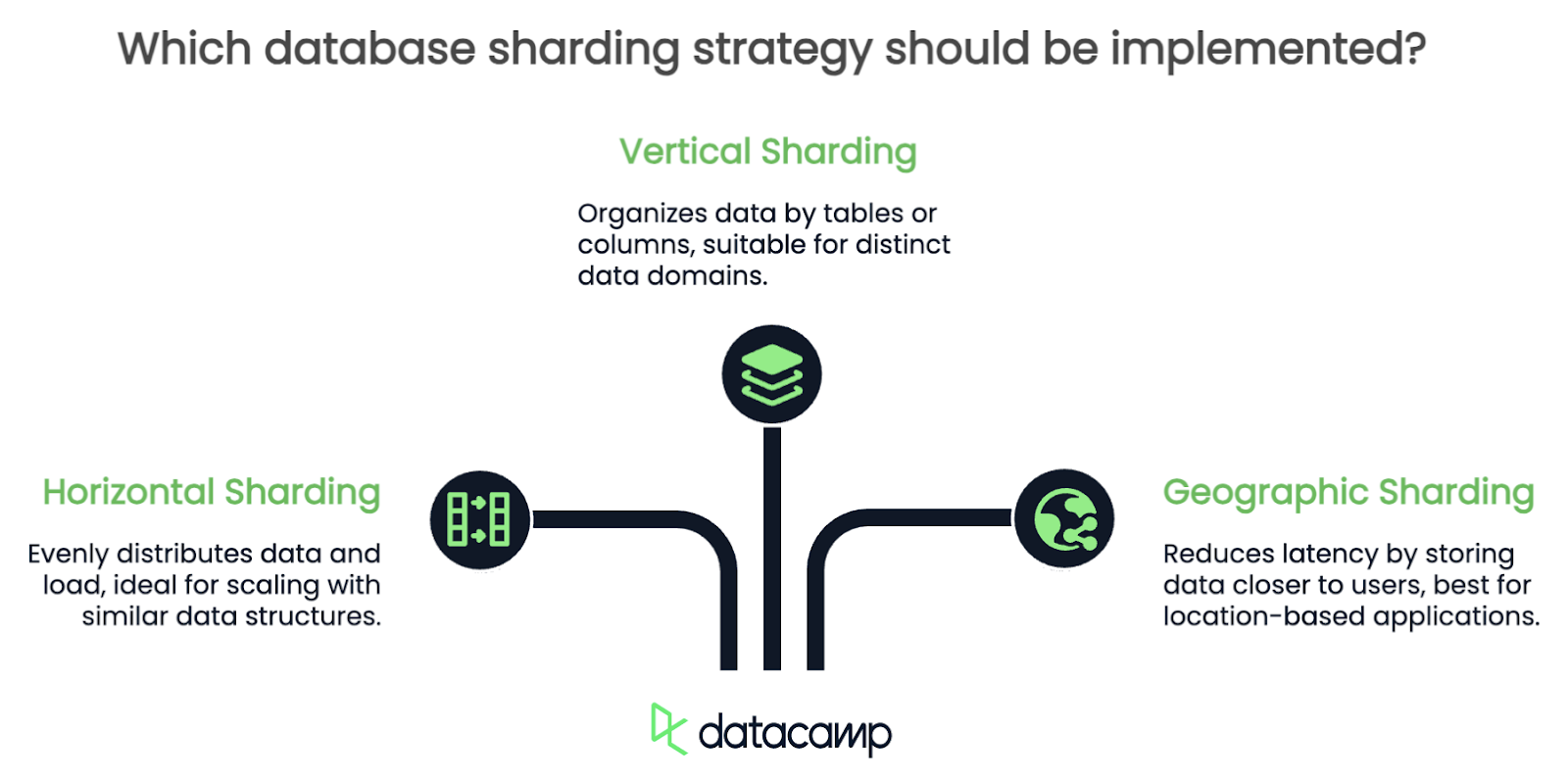
O sharding horizontal divide as linhas de uma tabela em vários shards. Por exemplo, se você estiver gerenciando um banco de dados de usuários, poderá dividi-los em fragmentos com base em seu ID: usuários 1-1000 em um fragmento, 1001-2000 em outro e assim por diante.
Essa abordagem é uma das mais populares porque distribui uniformemente os dados e a carga, facilitando o dimensionamento horizontal à medida que o aplicativo cresce. Isso é especialmente eficaz quando suas tabelas têm muitas linhas com estruturas semelhantes.
Ao usar a fragmentação horizontal, você precisa ter muito cuidado ao escolher a lógica de particionamento. Dados mal distribuídos significam cargas de trabalho drasticamente desiguais, e alguns shards ficarão sobrecarregados enquanto outros ficarão ociosos.
No sharding vertical, você divide o banco de dados por tabelas ou colunas. Por exemplo, você pode colocar os perfis de usuário em um fragmento, os dados de transação em outro e os logs em um terceiro. Cada fragmento é essencialmente responsável por um subconjunto específico de dados.
Essa estratégia funciona bem quando seu aplicativo tem domínios de dados claros e distintos que não interagem muito, mas você deve tomar cuidado com as consultas entre shards. Se o seu aplicativo precisar combinar dados de diferentes shards com frequência, o sharding vertical pode, na verdade, criar mais gargalos de desempenho do que você tinha no início!
O sharding geográfico organiza os dados com base na localização do usuário. Por exemplo, todos os dados de usuários europeus podem residir em um fragmento, enquanto os dados norte-americanos residem em outro. Essa estratégia reduz a latência, garantindo que os dados dos usuários sejam armazenados mais perto de onde eles os acessam.
No entanto, o sharding geográfico tem seus próprios desafios. Você precisará lidar cuidadosamente com os usuários que viajam entre regiões ou cujos dados abrangem vários locais. Manter a consistência dos dados entre os shards também pode ser complicado.
Às vezes, a combinação de várias estratégias pode ser a melhor solução - por exemplo, usar sharding horizontal dentro de shards geográficos. O segredo é equilibrar simplicidade, escalabilidade e desempenho. Você terá que manter seu banco de dados depois de criar esses fragmentos, portanto, facilite as coisas para o seu futuro eu!
Você não precisa começar do zero e implementar a fragmentação por conta própria. Há muitas ferramentas e estruturas que facilitam o sharding e oferecem recursos integrados para lidar com a complexidade para você.
ProxySQL atua como uma camada de proxy inteligente e lida com o roteamento de consultas e o balanceamento de carga para o sharded MySQL fragmentados. Ele mantém um mapeamento de qual fragmento contém quais dados e, quando uma consulta chega, ele a encaminha automaticamente para o fragmento apropriado para que seu aplicativo não precise lidar com a lógica.
Eu mesmo nunca trabalhei com o ProxySQL, mas um amigo meu afirmou que sua capacidade de lidar com o roteamento de consultas lhe poupou horas de configuração manual!
MongoDB tem suporte integrado a sharding, o que o torna uma opção popular para lidar com grandes conjuntos de dados não estruturados. O MongoDB usa uma chave de sharding para determinar como os documentos são distribuídos entre os shards, portanto, você precisará escolhê-la com cuidado. Uma escolha inadequada pode levar a uma distribuição desigual dos dados e a problemas de desempenho!
Em seguida, o MongoDB cuida do resto: particionamento, balanceamento de dados e roteamento de consultas automaticamente.
O Citus é uma ótima opção para aqueles que preferem bancos de dados relacionais. O Citus é essencialmente uma extensão que transforma o PostgreSQL em um banco de dados distribuído.
Trabalhei em uma equipe que usou o Citus para dimensionar um aplicativo SaaS, e isso nos permitiu manter a robustez do PostgreSQL e das tabelas estruturadas enquanto lidávamos com grandes quantidades de dados.
O Citus usa um planejador de consultas distribuídas para lidar com consultas complexas entre shards, e é especialmente útil para aplicativos com uso intenso de análise em que você precisa combinar dados de vários shards. A curva de aprendizado foi mais acentuada do que o sharding integrado do MongoDB, mas os resultados valeram a pena!
Espero que este guia tenha dado a você as ferramentas para explorar a fragmentação em seus próprios sistemas (ou a confiança para dizer que essa não é a solução certa para você no momento!) Lembre-se de que não se trata de uma solução única, mas, quando usada com cuidado, é uma ferramenta poderosa para criar arquiteturas escalonáveis e eficientes.
E, como alguém que aprendeu essas lições da maneira mais difícil, meu conselho é o seguinte: não espere até que seu banco de dados esteja de joelhos para começar a pensar em sharding. Planeje com antecedência, experimente e adapte-se! Seu futuro eu (e seus usuários) agradecerão a você.
Aprenda engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Zoumana Keita
12 min
blog
Mike Shakhomirov
11 min
blog
Kurtis Pykes
11 min
blog
Tim Lu
12 min
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
