
Curso
Introdução a LLMs em Python
3 h
33.6K
A Mistral AI lançou recentemente uma nova família de modelos de raciocínio chamada Magistral. Esses modelos são projetados para se destacarem em domínios específicos, fornecerem raciocínio transparente e oferecerem suporte a várias linguagens.
Neste tutorial, vamos nos concentrar no ajuste fino do Magistral Small no conjunto de dados de raciocínio de MCQs médicos. O Magistral Small é uma variante de código aberto da família Magistral com 24 bilhões de parâmetros. Ele é baseado na versão 3.1 (2503) e tem recursos de raciocínio aprimorados.
Aqui estão as etapas que você seguirá neste tutorial:
Inicialmente, tentei executar o script de ajuste fino no Kaggle, mas mesmo com quantização de 4 bits, as GPUs gratuitas eram insuficientes para essa tarefa. Devido a essas limitações, mudei para o RunPod e selecionei uma instância de GPU A100 SXM, que oferece desempenho mais rápido e VRAM maior.
1. Vá para "Pods" no RunPod, escolha a imagem mais recente do PyTorch, selecione a máquina A100 SXM e implemente seu pod.
Fonte: Meus pods
2. Edite as configurações do pod para aumentar o tamanho do disco do contêiner e adicione o token de acesso Hugging Face para autenticação.
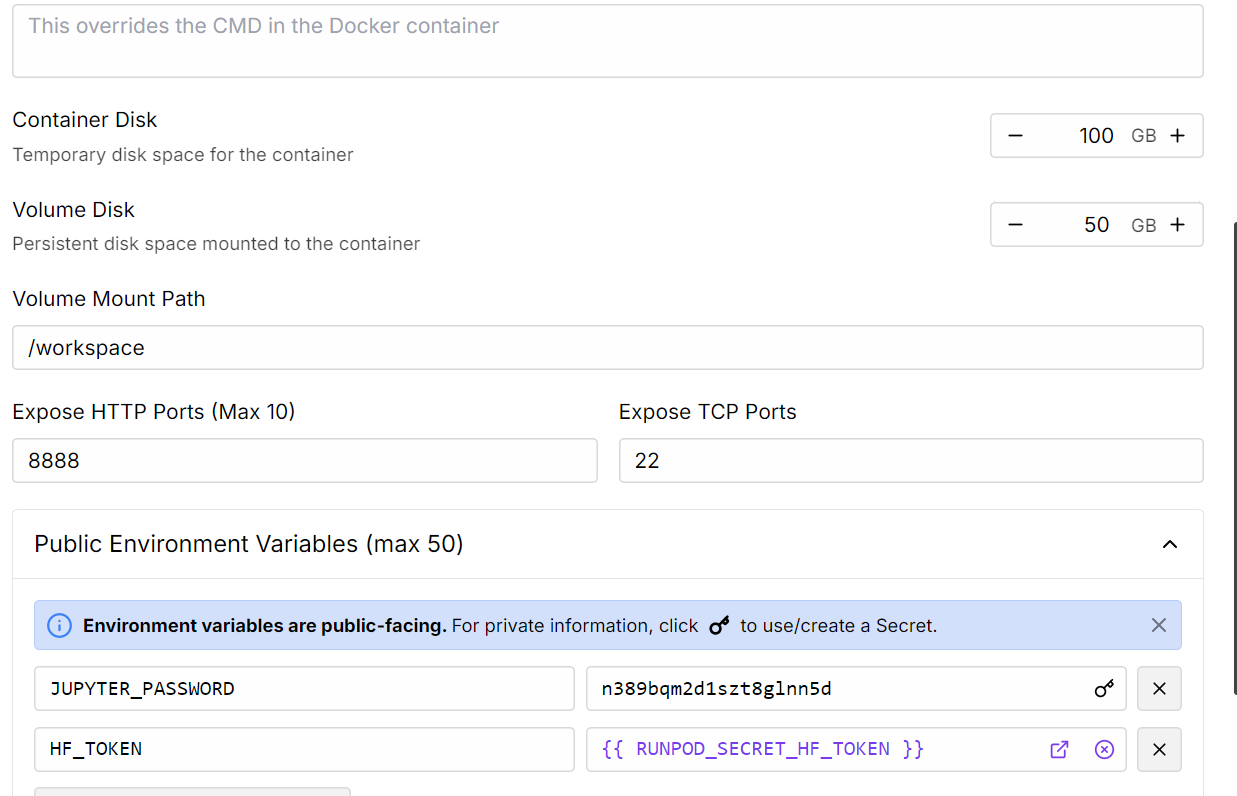
Fonte: Meus pods
3. Quando o pod estiver em execução, clique no botão Connect e inicie uma instância do JupyterLab para desenvolvimento interativo.
4. Instale todos os pacotes Python necessários
%%capture
%pip install -U transformers==4.52.1
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes5. Faça login no Hugging Face usando seu token de acesso (que você salvou anteriormente). Isso permite que você carregue modelos com gated e, posteriormente, carregue seu modelo e tokenizador ajustados:
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Usaremos a versão quantizada de 4 bits do Unsloth do Magistral-Small para economizar espaço de armazenamento e VRAM. Essa abordagem é muito mais rápida e eficiente do que fazer o download do modelo de precisão total e quantizá-lo manualmente.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "unsloth/Magistral-Small-2506-bnb-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
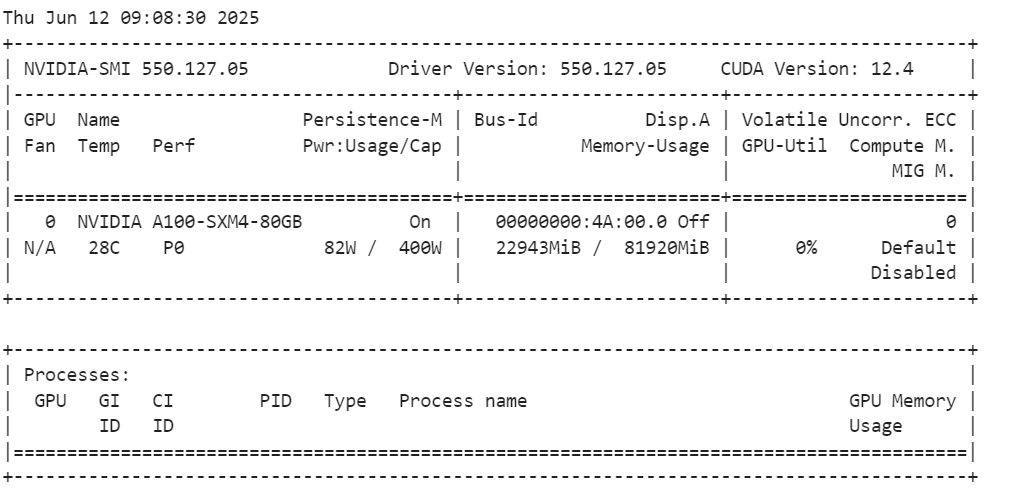
Depois de carregar o modelo, verifique o uso da memória da GPU.
!nvidia-smiComo você pode ver, ele usa apenas 23 GB de VRam.
Defina um modelo de prompt que instrua o modelo a responder com uma das opções fornecidas, incluir o raciocínio nas tags <analysis></analysis> e a resposta final nas tags <answer></answer>.
train_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
{}"""
Crie uma função Python para formatar cada exemplo de acordo com o estilo do prompt e anexar o token EOS, se estiver faltando.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["input"]
outputs = examples["output"]
texts = []
for question, response in zip(inputs, outputs):
# Remove the "Q:" prefix from the question
question = question.replace("Q:", "")
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, response)
texts.append(text)
return {"text": texts}Em seguida, faça o download e carregue o conjunto de dados mamachang/medical-reasoning do Hugging Face. Aplique a função de formatação para criar uma nova coluna de "texto" com o prompt estruturado.
from datasets import load_dataset
dataset = load_dataset(
"mamachang/medical-reasoning",
split="train",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
print(dataset["text"][10])A coluna "texto" contém o prompt do sistema, a pergunta, a análise e a resposta, tudo no formato exigido.

Como o novo SFTTrainer não aceita um tokenizador diretamente, converta o tokenizador em um coletor de dados para modelagem de linguagem.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Antes de fazer o ajuste fino, é importante avaliar o desempenho do modelo básico em seu conjunto de dados. Essa linha de base ajudará você a comparar objetivamente os resultados após o ajuste fino e a medir as melhorias.
Defina um modelo de prompt para inferência que inclua um prompt do sistema, uma seção de pergunta (com um espaço reservado) e uma seção de resposta.
inference_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
<analysis>
"""Selecione a 11ª pergunta do seu conjunto de dados, remova todos os prefixos desnecessários e tokenize-a para a entrada do modelo
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Nesse teste de linha de base, a análise gerada pelo modelo era excessivamente longa e muitas vezes não produzia uma resposta correta ou concisa.

Nesta parte, configuraremos o modelo para ajuste fino.
Usaremos o LoRA (Low-Rank Adaptation) para fazer o ajuste fino do modelo, o que reduzirá significativamente nosso espaço de memória e acelerará o processo de treinamento, pois estamos ajustando apenas um pequeno subconjunto dos parâmetros do modelo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)A classeTrainingArguments permite que você configure o tamanho do lote, o otimizador, a taxa de aprendizado e outros hiperparâmetros de treinamento. O site SFTTrainer da biblioteca TRL simplifica o ajuste fino supervisionado ao integrar o modelo, o conjunto de dados, o coletor de dados, os argumentos de treinamento e a configuração do LoRA em um único fluxo de trabalho.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="Magistral-Medical-Reasoning",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)
Para evitar erros de falta de memória (OOM), é importante que você limpe o coletor de lixo do Python e esvazie o cache do CUDA antes de iniciar o treinamento. Isso garante que qualquer memória não utilizada de operações anteriores seja liberada.
Em seguida, inicie o processo de treinamento usando o comando SFTTrainer.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Durante o treinamento, a utilização da GPU chegou a 100%, e havia VRAM suficiente disponível para carregar outro modelo em paralelo.
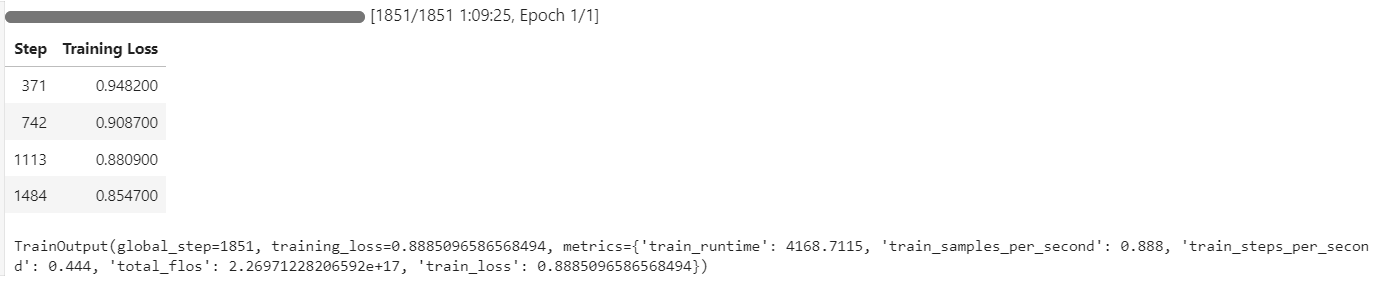
O processo de treinamento levou aproximadamente 1 hora e 10 minutos, com a perda de treinamento diminuindo constantemente a cada etapa, indicando um aprendizado eficaz.
Avaliaremos o desempenho do modelo ajustado usando a mesma 11ª pergunta de amostra do conjunto de dados. Essa abordagem nos permite comparar os resultados com o modelo básico e avaliar as melhorias obtidas com o ajuste fino.
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question,) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])O modelo agora gera uma análise concisa e precisa, e a resposta está correta.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key issue with the validity of this study is confounding. The researchers did not account for other factors that could influence cardiovascular disease risk in adulthood besides childhood diet.
To address confounding, the researchers should have stratified the analysis by potential confounders like family history, physical activity levels, and smoking status. This would allow them to see if the relationship between diet and disease persists even when accounting for these other variables.
Blinding, crossover, matching, and randomization do not address the main validity concern in this study design.
</analysis>
<answer>
D: Stratification
</answer>Para validar ainda mais o desempenho, tente fazer a inferência em outra amostra.
question = dataset[100]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])O modelo continua a fornecer respostas precisas e análises bem estruturadas, demonstrando melhorias consistentes mesmo após apenas uma época de ajuste fino.
<analysis>
This is a clinical vignette describing a 55-year-old man with burning and shooting pain in his feet and lower legs that worsens at night. He has a history of type 2 diabetes mellitus and hypertension.
The key findings are:
- Burning and shooting pain in feet and lower legs
- Pain worsens at night
- History of type 2 diabetes mellitus
This presentation is most consistent with diabetic peripheral neuropathy. The pain distribution, timing, and history of diabetes point towards a distal symmetric sensorimotor polyneuropathy as the etiology. The other options can be ruled out based on the clinical presentation.
</analysis>
<answer>
D: Distal symmetric sensorimotor polyneuropathy
</answer>Depois de fazer o ajuste fino, você pode compartilhar facilmente seu modelo enviando-o para o Hugging Face Hub. Isso o torna acessível para que outras pessoas o utilizem ou o aperfeiçoem ainda mais.
new_model_name = "kingabzpro/Magistral-Small-Medical-QA"
trainer.model.push_to_hub(new_model_name)
trainer.processing_class.push_to_hub(new_model_name)
O modelo aperfeiçoado já está disponível em: kingabzpro/Magistral-Small-Medical-QA
Fonte: kingabzpro/Magistral-Small-Medical-QA
Depois de ajustar e salvar seu LoRA no Hugging Face Hub, você pode recarregá-lo facilmente para análise, inferência ou implementação adicionais como um servidor de inferência. Esse processo envolve limpar sua sessão atual, carregar o modelo básico e o adaptador LoRA e executar a inferência em novos dados. Você pode saber mais sobre como trabalhar com o Hugging Face Hub em nosso curso.
1. Antes de carregar um novo modelo, é recomendável que você exclua todos os objetos existentes do modelo e do treinador e limpe o cache da GPU para evitar problemas de memória.
2. Faça o download do modelo básico e do adaptador LoRA ajustado por você no Hugging Face Hub e, em seguida, mescle-os. Além disso, carregue o tokenizador.
del model
del trainer
torch.cuda.empty_cache()
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
import torch
# Base model
base_model_id = "unsloth/Magistral-Small-2506-bnb-4bit"
# Your fine-tuned LoRA adapter repository
lora_adapter_id = "kingabzpro/Magistral-Small-Medical-QA"
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
# Attach the LoRA adapter
model = PeftModel.from_pretrained(
base_model,
lora_adapter_id,
device_map="auto",
trust_remote_code=True,
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)3. Prepare um prompt de amostra, tokenize-o, gere uma resposta e decodifique o resultado.
# Inference example
prompt = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
A research group wants to assess the relationship between childhood diet and cardiovascular disease in adulthood.
A prospective cohort study of 500 children between 10 to 15 years of age is conducted in which the participants' diets are recorded for 1 year and then the patients are assessed 20 years later for the presence of cardiovascular disease.
A statistically significant association is found between childhood consumption of vegetables and decreased risk of hyperlipidemia and exercise tolerance.
When these findings are submitted to a scientific journal, a peer reviewer comments that the researchers did not discuss the study's validity.
Which of the following additional analyses would most likely address the concerns about this study's design?
{'A': 'Blinding', 'B': 'Crossover', 'C': 'Matching', 'D': 'Stratification', 'E': 'Randomization'},
### Response:
<analysis>
"""
inputs = tokenizer(
[prompt + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])4. A resposta gerada é precisa e se aproxima do estilo e da estrutura do seu conjunto de dados, demonstrando que o modelo ajustado está pronto para inferência e implementação no mundo real.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key concern from the peer reviewer is about the study's validity.
To address concerns about validity, the researchers could perform additional analyses to control for confounding. Matching and stratification would help control for known confounders like socioeconomic status or family history. Crossover and blinding are not applicable to this observational study design. Randomization would not be possible since the study is observational.
</analysis>
<answer>
D: Stratification
</answer>
Se você encontrar problemas ao executar o código acima, consulte o notebook Jupyter fine-tuning-magistral.ipynb no Hugging Face.
Em um guia de ajuste fino separado, analisamos o desempenho do modo destilado do DeepSeek-R1-0528. Enquanto o DeepSeek-R1-0528 teve dificuldades para se adaptar ao estilo específico do conjunto de dados e à precisão, o Magistral demonstrou uma adaptação perfeita e apresentou resultados sólidos com o mínimo de esforço.
Essa experiência reforça minha convicção de que a Mistral AI está emergindo rapidamente como líder no espaço de IA, não apenas em modelos de linguagem, mas também em um amplo espectro de soluções, incluindo visão computacional.
Neste guia, ajustamos com sucesso o mais recente modelo de raciocínio da Mistral AI, o Magistral, em um conjunto de dados de MCQs médicos.
No entanto, é importante observar que o ajuste fino de modelos grandes, como o Magistral, exige um hardware substancial, normalmente GPUs com pelo menos 40 GB de VRAM, pois mesmo a RTX 4090 pode não ser suficiente para algumas configurações. Também fiz experiências com a estrutura Unsloth e sua versão de modelo de 4 bits, mas ainda encontrei problemas de memória da GPU.
Se você estiver procurando um curso prático para se familiarizar com o ajuste fino, não deixe de conferir o Fine-Tuning With Llama 3.
Principais cursos de LLM
Curso
Curso