
Cours
Introduction aux LLM en Python
3 h
33.6K
Mistral AI a récemment lancé une nouvelle famille de modèles de raisonnement appelée Magistral. Ces modèles sont conçus pour exceller dans des domaines spécifiques, fournir un raisonnement transparent et prendre en charge plusieurs langues.
Dans ce tutoriel, nous nous concentrerons sur le réglage fin de Magistral Small sur l'ensemble de données de raisonnement des QCM médicaux. Le Magistral Small est une variante libre de la famille Magistral avec 24 milliards de paramètres. Il est basé sur la version 3.1 (2503) et possède des capacités de raisonnement améliorées.
Voici les étapes que nous allons suivre dans ce tutoriel :
J'ai d'abord essayé d'exécuter le script de réglage fin sur Kaggle, mais même avec une quantification sur 4 bits, les GPU gratuits n'étaient pas suffisants pour cette tâche. En raison de ces limitations, je suis passé à RunPod et j'ai sélectionné une instance de GPU A100 SXM, qui offre des performances plus rapides et une VRAM plus importante.
1. Allez dans "Pods" sur RunPod, choisissez la dernière image PyTorch, sélectionnez la machine A100 SXM, et déployez votre pod.
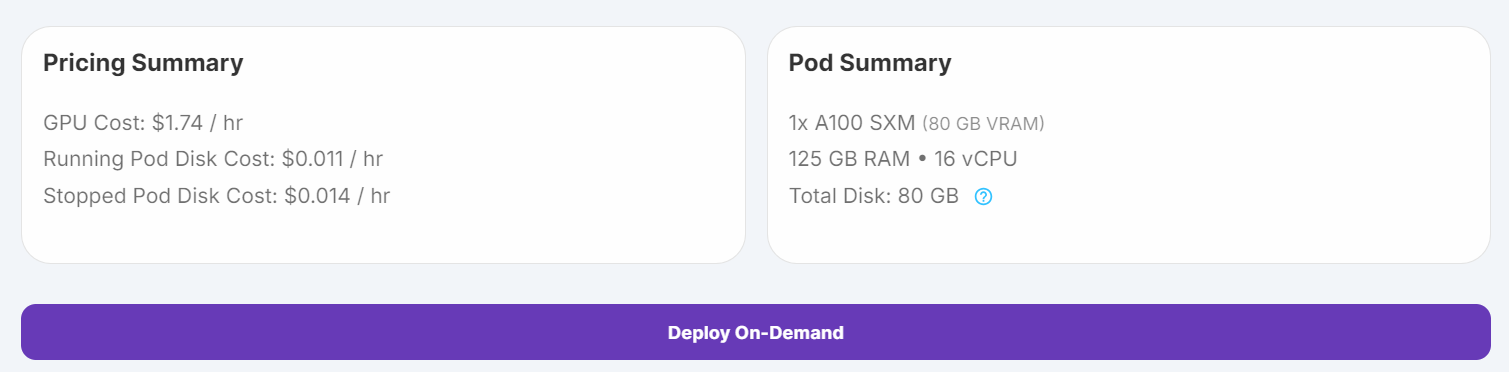
Source : Mes gousses
2. Modifiez les paramètres du Pod pour augmenter la taille du disque du conteneur et ajoutez votre jeton d'accès Hugging Face pour l'authentification.
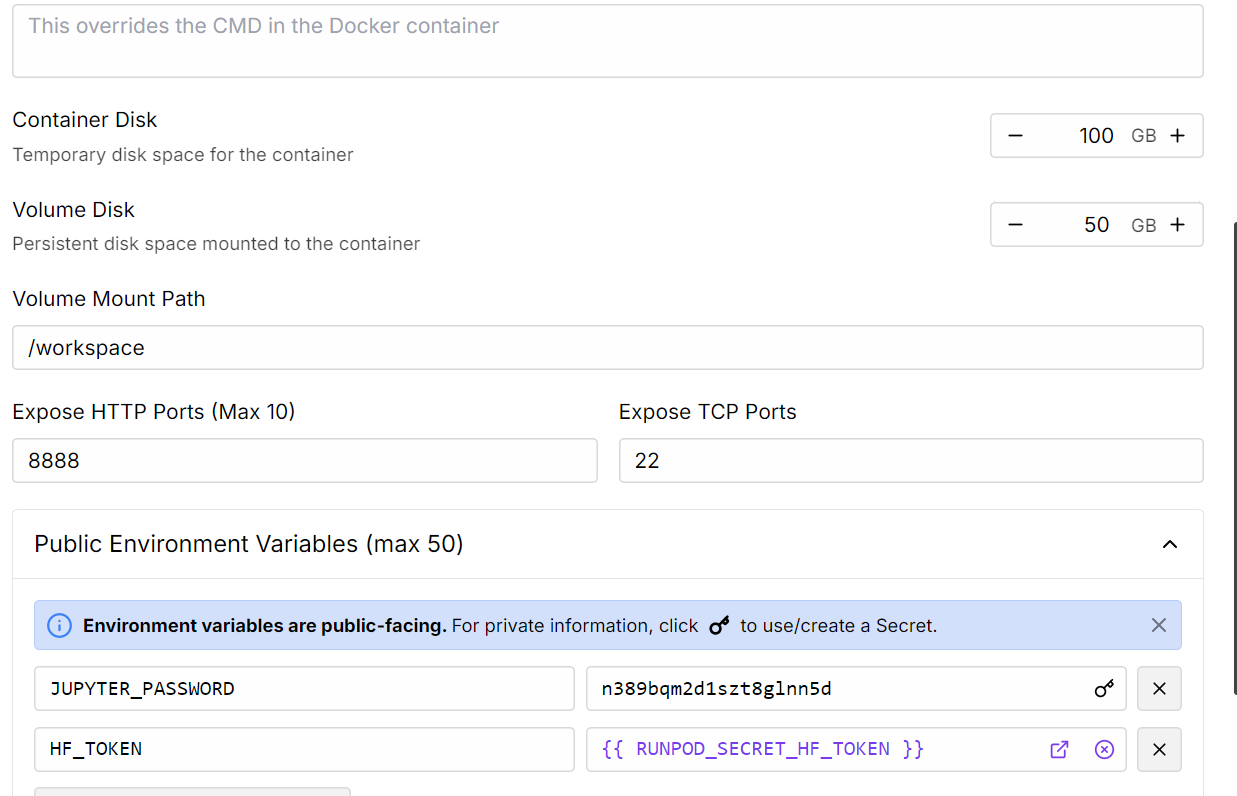
Source : Mes gousses
3. Une fois le pod lancé, cliquez sur le bouton Connect et lancez une instance JupyterLab pour un développement interactif.
4. Installez tous les paquets Python nécessaires
%%capture
%pip install -U transformers==4.52.1
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes5. Connectez-vous à Hugging Face à l'aide de votre jeton d'accès (que vous avez enregistré précédemment). Cela vous permet de charger des modèles de type "gated" et de télécharger ultérieurement votre modèle et votre "tokenizer" affinés :
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Nous utiliserons la version quantifiée à 4 bits d'Unsloth de Magistral-Small pour économiser de l'espace de stockage et de la VRAM. Cette approche est beaucoup plus rapide et efficace que le téléchargement du modèle en pleine précision et sa quantification manuelle.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "unsloth/Magistral-Small-2506-bnb-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
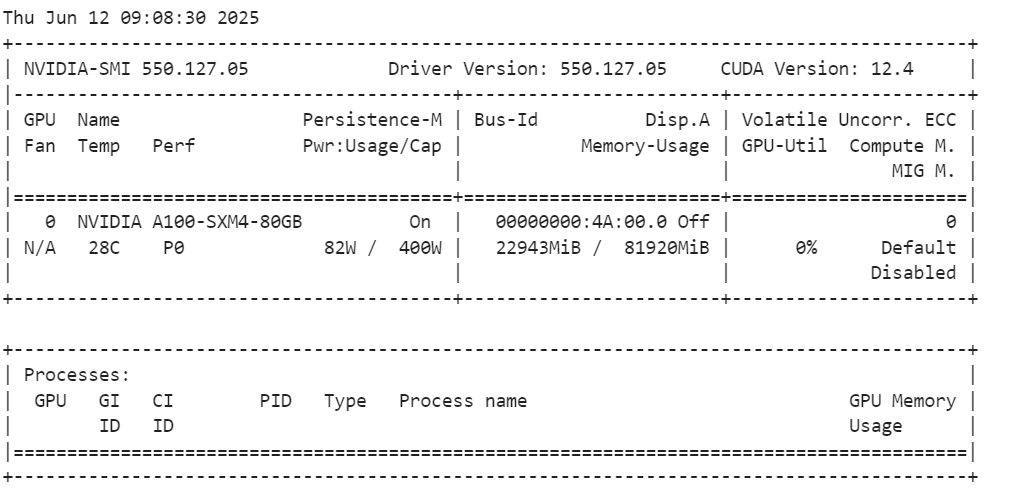
Après avoir chargé le modèle, vérifiez l'utilisation de la mémoire de votre GPU.
!nvidia-smiComme nous pouvons le voir, il n'utilise que 23 Go de VRam.
Définissez un modèle d'invite qui demande au modèle de répondre par l'une des options proposées, d'inclure le raisonnement dans les balises <analysis></analysis> et la réponse finale dans les balises <answer></answer>.
train_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
{}"""
Créez une fonction Python pour formater chaque exemple selon le style de l'invite et ajoutez le jeton EOS s'il manque.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["input"]
outputs = examples["output"]
texts = []
for question, response in zip(inputs, outputs):
# Remove the "Q:" prefix from the question
question = question.replace("Q:", "")
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, response)
texts.append(text)
return {"text": texts}Ensuite, téléchargez et chargez l'ensemble de données mamachang/medical-reasoning de Hugging Face. Appliquez la fonction de formatage pour créer une nouvelle colonne "texte" avec l'invite structurée.
from datasets import load_dataset
dataset = load_dataset(
"mamachang/medical-reasoning",
split="train",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
print(dataset["text"][10])La colonne "texte" contient l'invite du système, la question, l'analyse et la réponse, le tout dans le format requis.

Puisque le nouveau SFTTrainer n'accepte pas directement un tokenizer, convertissez le tokenizer en un collecteur de données pour la modélisation du langage.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Avant d'affiner les réglages, il est important d'évaluer les performances du modèle de base sur votre ensemble de données. Cette base de référence vous permettra de comparer objectivement les résultats obtenus après la mise au point et de mesurer les améliorations.
Définissez un modèle d'invite pour la déduction qui comprend une invite système, une section de question (avec un espace réservé) et une section de réponse.
inference_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
<analysis>
"""Sélectionnez la 11e question de votre ensemble de données, supprimez tous les préfixes inutiles et tokenisez-la pour l'entrée du modèle.
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Dans ce test de base, l'analyse générée par le modèle était excessivement longue et ne produisait souvent pas de réponse correcte ou concise.

Dans cette partie, nous allons mettre en place le modèle pour le réglage fin.
Nous utiliserons LoRA (Low-Rank Adaptation) pour affiner le modèle, ce qui réduira considérablement notre empreinte mémoire et accélérera le processus d'apprentissage puisque nous n'affinons qu'un petit sous-ensemble des paramètres du modèle.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)La classeTrainingArguments vous permet de configurer la taille du lot, l'optimiseur, le taux d'apprentissage et d'autres hyperparamètres d'apprentissage. Le site SFTTrainer de la bibliothèque TRL rationalise la mise au point supervisée en intégrant le modèle, l'ensemble de données, le collecteur de données, les arguments d'entraînement et la configuration LoRA dans un flux de travail unique.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="Magistral-Medical-Reasoning",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)
Pour éviter les erreurs de type Out of Memory (OOM), il est important d'effacer le garbage collector de Python et de vider le cache CUDA avant de commencer l'entraînement. Cela permet de s'assurer que toute la mémoire inutilisée des opérations précédentes est libérée.
Lancez ensuite le processus de formation à l'aide de la commande SFTTrainer.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
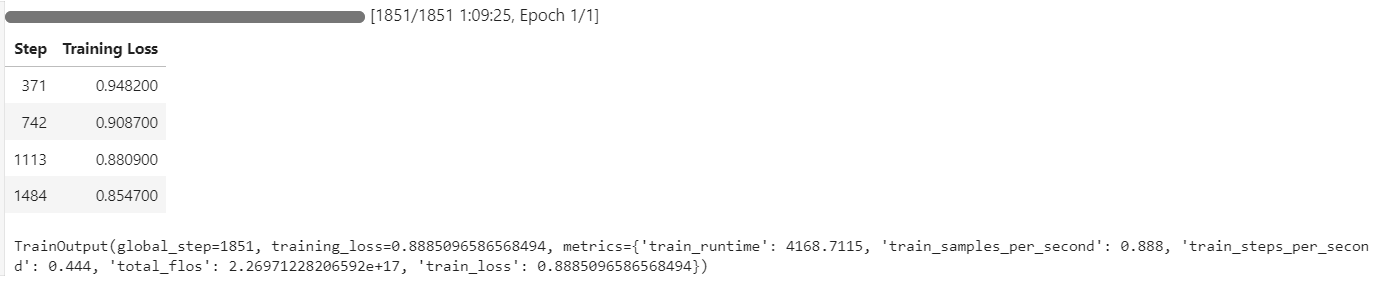
trainer.train()Pendant l'entraînement, l'utilisation du GPU a atteint 100 %, et il y avait suffisamment de VRAM disponible pour charger potentiellement un autre modèle en parallèle.
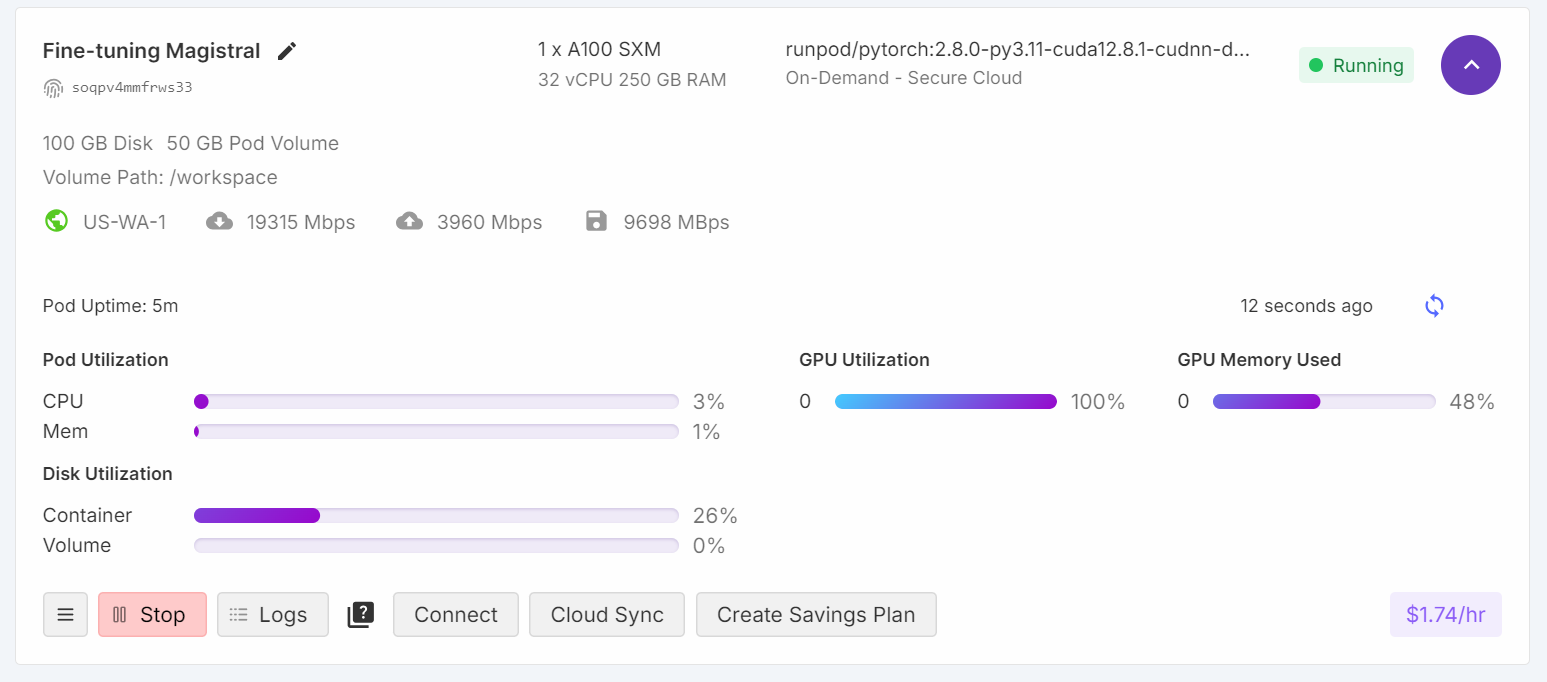
Le processus de formation a duré environ 1 heure et 10 minutes, la perte de formation diminuant régulièrement à chaque étape, ce qui indique un apprentissage efficace.
Nous évaluerons les performances du modèle affiné en utilisant la même 11e question de l'échantillon de l'ensemble de données. Cette approche nous permet de comparer les résultats avec le modèle de base et d'évaluer les améliorations obtenues grâce à un réglage fin.
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question,) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Le modèle génère maintenant une analyse concise et précise, et la réponse est correcte.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key issue with the validity of this study is confounding. The researchers did not account for other factors that could influence cardiovascular disease risk in adulthood besides childhood diet.
To address confounding, the researchers should have stratified the analysis by potential confounders like family history, physical activity levels, and smoking status. This would allow them to see if the relationship between diet and disease persists even when accounting for these other variables.
Blinding, crossover, matching, and randomization do not address the main validity concern in this study design.
</analysis>
<answer>
D: Stratification
</answer>Pour valider davantage les performances, essayez l'inférence sur un autre échantillon.
question = dataset[100]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Le modèle continue de fournir des réponses précises et une analyse bien structurée, démontrant des améliorations constantes même après une seule période de mise au point.
<analysis>
This is a clinical vignette describing a 55-year-old man with burning and shooting pain in his feet and lower legs that worsens at night. He has a history of type 2 diabetes mellitus and hypertension.
The key findings are:
- Burning and shooting pain in feet and lower legs
- Pain worsens at night
- History of type 2 diabetes mellitus
This presentation is most consistent with diabetic peripheral neuropathy. The pain distribution, timing, and history of diabetes point towards a distal symmetric sensorimotor polyneuropathy as the etiology. The other options can be ruled out based on the clinical presentation.
</analysis>
<answer>
D: Distal symmetric sensorimotor polyneuropathy
</answer>Après l'avoir peaufiné, vous pouvez facilement partager votre modèle en le poussant vers le Hub de Hugging Face. Cela permet à d'autres personnes de l'utiliser ou de l'affiner.
new_model_name = "kingabzpro/Magistral-Small-Medical-QA"
trainer.model.push_to_hub(new_model_name)
trainer.processing_class.push_to_hub(new_model_name)
Le modèle affiné est désormais disponible à l'adresse suivante : kingabzpro/Magistral-Small-Medical-QA
Source : kingabzpro/Magistral-Small-Medical-QA
Après avoir peaufiné et enregistré votre LoRA dans le Hugging Face Hub, vous pouvez facilement le recharger pour une analyse plus approfondie, une inférence ou un déploiement en tant que serveur d'inférence. Ce processus consiste à effacer votre session actuelle, à charger le modèle de base et l'adaptateur LoRA, et à exécuter l'inférence sur de nouvelles données. Vous pouvez en savoir plus sur le travail avec le Hugging Face Hub dans notre cours.
1. Avant de charger un nouveau modèle, il est conseillé de supprimer tous les modèles et objets formateurs existants et de vider le cache du GPU pour éviter les problèmes de mémoire.
2. Téléchargez le modèle de base et votre adaptateur LoRA affiné à partir du Hugging Face Hub, puis fusionnez-les. Chargez également le tokenizer.
del model
del trainer
torch.cuda.empty_cache()
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
import torch
# Base model
base_model_id = "unsloth/Magistral-Small-2506-bnb-4bit"
# Your fine-tuned LoRA adapter repository
lora_adapter_id = "kingabzpro/Magistral-Small-Medical-QA"
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
# Attach the LoRA adapter
model = PeftModel.from_pretrained(
base_model,
lora_adapter_id,
device_map="auto",
trust_remote_code=True,
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)3. Préparez un exemple d'invite, tokenisez-le, générez une réponse et décodez le résultat.
# Inference example
prompt = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
A research group wants to assess the relationship between childhood diet and cardiovascular disease in adulthood.
A prospective cohort study of 500 children between 10 to 15 years of age is conducted in which the participants' diets are recorded for 1 year and then the patients are assessed 20 years later for the presence of cardiovascular disease.
A statistically significant association is found between childhood consumption of vegetables and decreased risk of hyperlipidemia and exercise tolerance.
When these findings are submitted to a scientific journal, a peer reviewer comments that the researchers did not discuss the study's validity.
Which of the following additional analyses would most likely address the concerns about this study's design?
{'A': 'Blinding', 'B': 'Crossover', 'C': 'Matching', 'D': 'Stratification', 'E': 'Randomization'},
### Response:
<analysis>
"""
inputs = tokenizer(
[prompt + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])4. La réponse générée est précise et correspond étroitement au style et à la structure de votre ensemble de données, ce qui prouve que le modèle affiné est prêt pour l'inférence et le déploiement dans le monde réel.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key concern from the peer reviewer is about the study's validity.
To address concerns about validity, the researchers could perform additional analyses to control for confounding. Matching and stratification would help control for known confounders like socioeconomic status or family history. Crossover and blinding are not applicable to this observational study design. Randomization would not be possible since the study is observational.
</analysis>
<answer>
D: Stratification
</answer>
Si vous rencontrez des problèmes lors de l'exécution du code ci-dessus, veuillez vous référer au carnet Jupyter fine-tuning-magistral.ipynb sur la Hugging Face.
Dans un autre guide de réglage fin, nous avons examiné les performances du mode distillé de DeepSeek-R1-0528. Alors que DeepSeek-R1-0528 a eu du mal à s'adapter au style spécifique de l'ensemble de données et à la précision, Magistral a fait preuve d'une adaptation transparente et a fourni de bons résultats avec un minimum d'efforts.
Cette expérience me conforte dans l'idée que Mistral AI est en train d'émerger rapidement comme un acteur de premier plan dans le domaine de l'IA, non seulement pour les modèles de langage, mais aussi pour un large éventail de solutions, y compris la vision par ordinateur.
Dans ce guide, nous avons affiné avec succès le dernier modèle de raisonnement de Mistral AI, Magistral, sur un ensemble de données de QCM médicaux.
Cependant, il est important de noter que le réglage fin de grands modèles comme Magistral nécessite un matériel substantiel, généralement des GPU avec au moins 40 Go de VRAM, car même la RTX 4090 peut ne pas suffire pour certaines configurations. J'ai également expérimenté le framework Unsloth et sa version 4 bits, mais j'ai encore rencontré des problèmes de mémoire GPU.
Si vous cherchez un cours pratique pour vous familiariser avec le réglage fin, ne manquez pas de jeter un coup d'œil à Fine-Tuning With Llama 3 (Réglage fin avec le lama 3).
Principaux cours de LLM
Cours
Cours