
Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.3K
A Mistral lançou seu primeiro modelo de raciocínio, o Magistral, disponível em duas variantes: Magistral Small (peso aberto) e Magistral Medium (modelo fechado).
Meu foco neste blog será o Magistral Small, um modelo de raciocínio de peso aberto projetado para tarefas que exigem lógica estruturada, compreensão multilíngue e capacidade de fornecer explicações rastreáveis. Quando combinado com mecanismos de inferência de alto rendimento, como o vLLM, ou com ferramentas fáceis de usar, como o Ollama, ele se torna uma excelente ferramenta para depurar tarefas de lógica e raciocínio com falhas.
Neste tutorial, explicarei passo a passo como você pode fazer isso:
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O Magistral é o primeiro modelo de raciocínio dedicado da Mistral AI, desenvolvido para lógica passo a passo, precisão multilíngue e resultados rastreáveis. É um modelo de liberação dupla que vem em duas variantes:
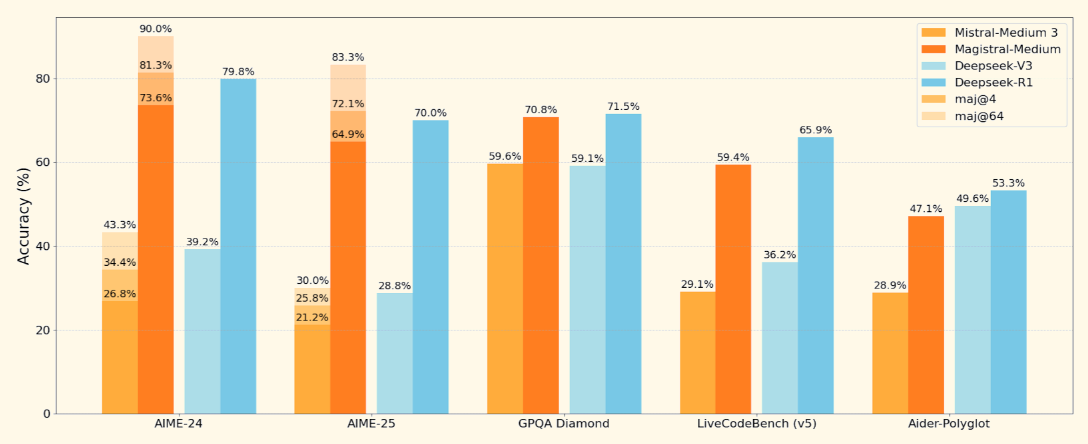
Fonte: Mistral
O Magistral Small, o modelo aberto no qual vamos nos concentrar, é compatível com uma janela de contexto de 128K (recomenda-se 40K para um desempenho estável). Ele é treinado com o uso de supervisionado em traços Magistral Medium e aprendizado por reforço.
Nesta seção, faremos a inferência no modelo Magistral da Mistral localmente usando o Ollama. Observe que esse modelo requer aproximadamente 14 GB de espaço e pode ser instalado em uma única RTX 4090 ou em um MacBook com 32 GB de RAM, uma vez que você tenha quantizado. Executei essa demonstração em um MacBook Pro M3.
Faça o download do Ollama para macOS, Windows ou Linux em: https://ollama.com/download.
Siga as instruções do instalador e, após a instalação, verifique executando isso no terminal:
ollama --versionEm seguida, extraia o modelo Magistral executando o seguinte código:
ollama pull magistral
Isso puxará o modelo Magistral para sua máquina local. Observação: Isso levará algum tempo, pois o modelo tem cerca de 14 GB.
Vamos começar instalando todas as dependências necessárias.
pip install ollama
pip install requestsCom as dependências instaladas, estamos prontos para executar a inferência.
Agora, configuramos uma estrutura de modelo pronta (conforme mencionado no artigo original do Magistral) que orienta o pensamento do modelo.
import gradio as gr
import requests
import json
def build_prompt(flawed_logic):
return f"""<s>[SYSTEM_PROMPT]
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
Your thinking process must follow the template below:
<think>
Your thoughts or/and draft, like working through an exercise on scratch paper. Be as casual and detailed as needed until you're confident.
</think>
Do not mention that you're debugging — just present your thought process and conclusion naturally.
[/SYSTEM_PROMPT][INST]
Here is a flawed solution. Can you debug it and correct it step by step?
\"\"\"{flawed_logic}\"\"\"
[/INST]
"""A função acima retorna um prompt formatado que orienta o Magistral:
Essa estrutura é importante para modelos como o Magistral, que foram treinados com prompts aumentados por ferramentas. A mesma estrutura de prompt do sistema também pode ser utilizada para problemas matemáticos e de codificação.
Nesta etapa, transmitimos a saída do modelo Magistral em tempo real usando a API local do Ollama. Como estamos concentrados na depuração da lógica defeituosa com raciocínio rastreável e passo a passo, é importante que o usuário possa ver como o modelo chega às suas conclusões. Por fim, exibimos a explicação por meio de um arquivo Gradio limpa.
def call_ollama_stream(flawed_logic):
prompt = build_prompt(flawed_logic)
response_text = ""
with requests.post(
"http://localhost:11434/api/generate",
json={"model": "magistral", "prompt": prompt, "stream": True},
stream=True,
) as r:
for line in r.iter_lines():
if line:
content = json.loads(line).get("response", "")
response_text += content
return response_text
with gr.Blocks(theme=gr.themes.Base()) as demo:
gr.Markdown("## Chain-of-Logic Debugger (Magistral + Ollama)")
gr.Markdown("Paste a flawed logical argument or math proof, and Magistral will debug it with step-by-step reasoning.")
with gr.Row():
input_box = gr.Textbox(lines=8, label="Flawed Logic / Proof")
output_box = gr.Textbox(lines=15, label="Debugged Explanation")
debug_button = gr.Button("Run Debugger")
debug_button.click(fn=call_ollama_stream, inputs=input_box, outputs=output_box)
demo.launch(debug = True, share=True)Aqui está um resumo do que está acontecendo aqui:
build_prompt() reutilizável para agrupar a entrada do usuário em um prompt estruturado que orienta o modelo com tags de raciocínio call_ollama_stream() envia o prompt para a API HTTP da Ollama em localhost:11434 usando uma solicitação POST de fluxo contínuo.requests.iter_lines(). Para cada linha recebida, ele extrai o campo de resposta do payload JSON e o anexa a um buffer de texto em execução.Aqui está a entrada que tentei:
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.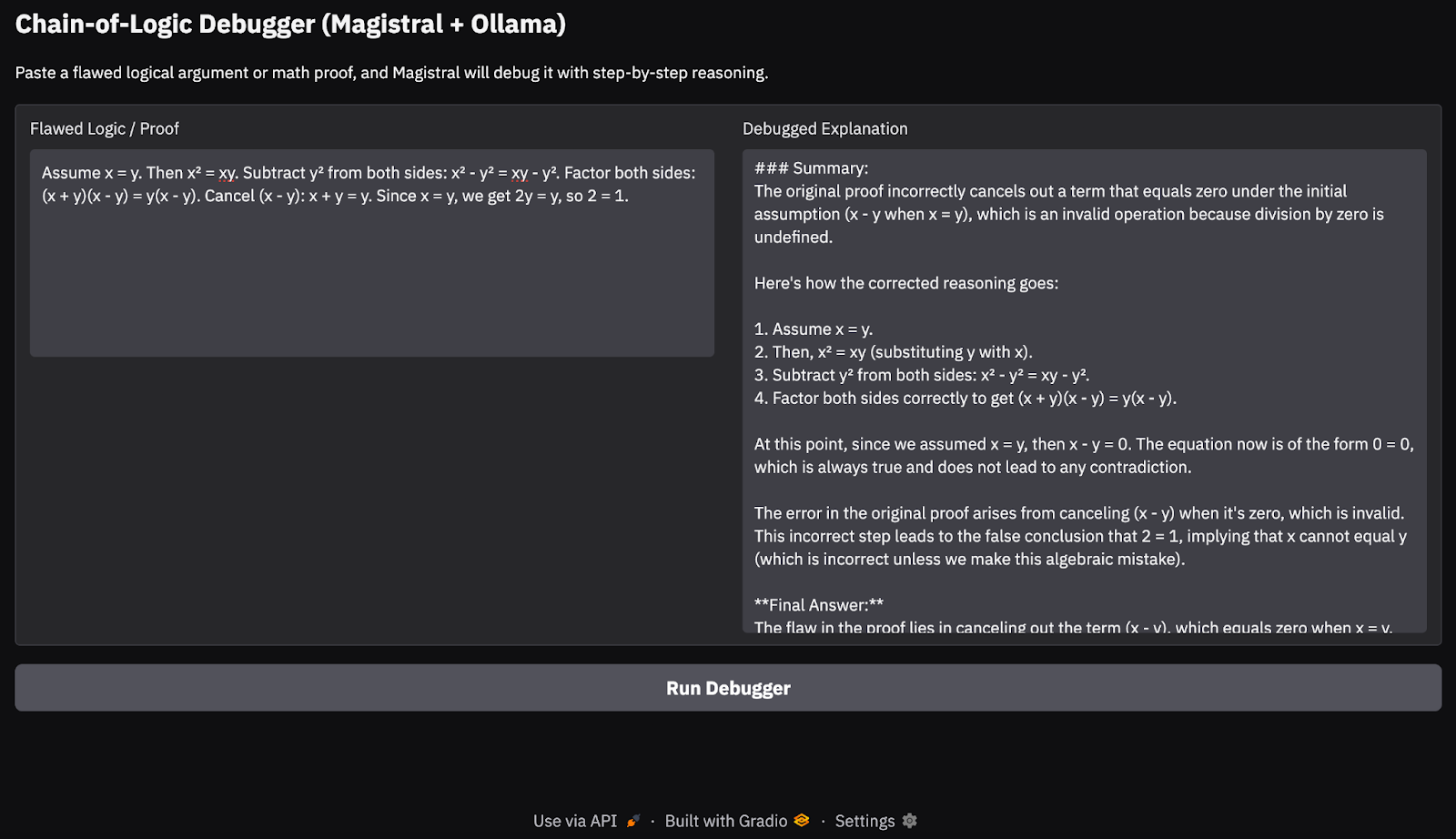
Em meus testes em um MacBook Pro M3, o modelo lidou muito bem com cadeias lógicas simples e provas matemáticas. No entanto, para tarefas de raciocínio mais profundas ou cadeias de pensamento mais longas, ele ocasionalmente deixava passar casos extremos, algo que se espera de um modelo aberto 24B. Essa abordagem é ideal para demonstrações de raciocínio leves ou no dispositivo aplicativos de cadeia de raciocínio no dispositivo, sem depender de APIs de nuvem.
Nesta seção, explicarei como provisionar uma instância de GPU avançada no RunPod, implantar o modelo Magistral do Mistral usando o vLLMe expor uma API compatível com OpenAI para inferência local e remota.
Antes de iniciar o modelo, certifique-se de que sua conta RunPod esteja configurada:
Agora, vamos provisionar um pod capaz de hospedar o modelo. Para configurar um pod, siga estas etapas:
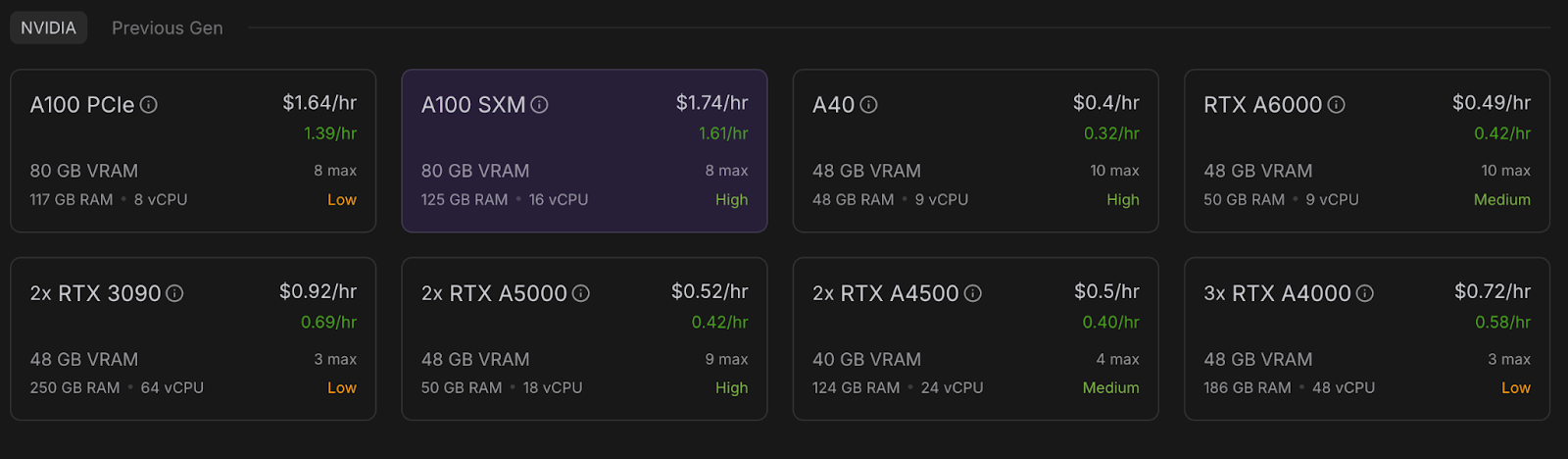
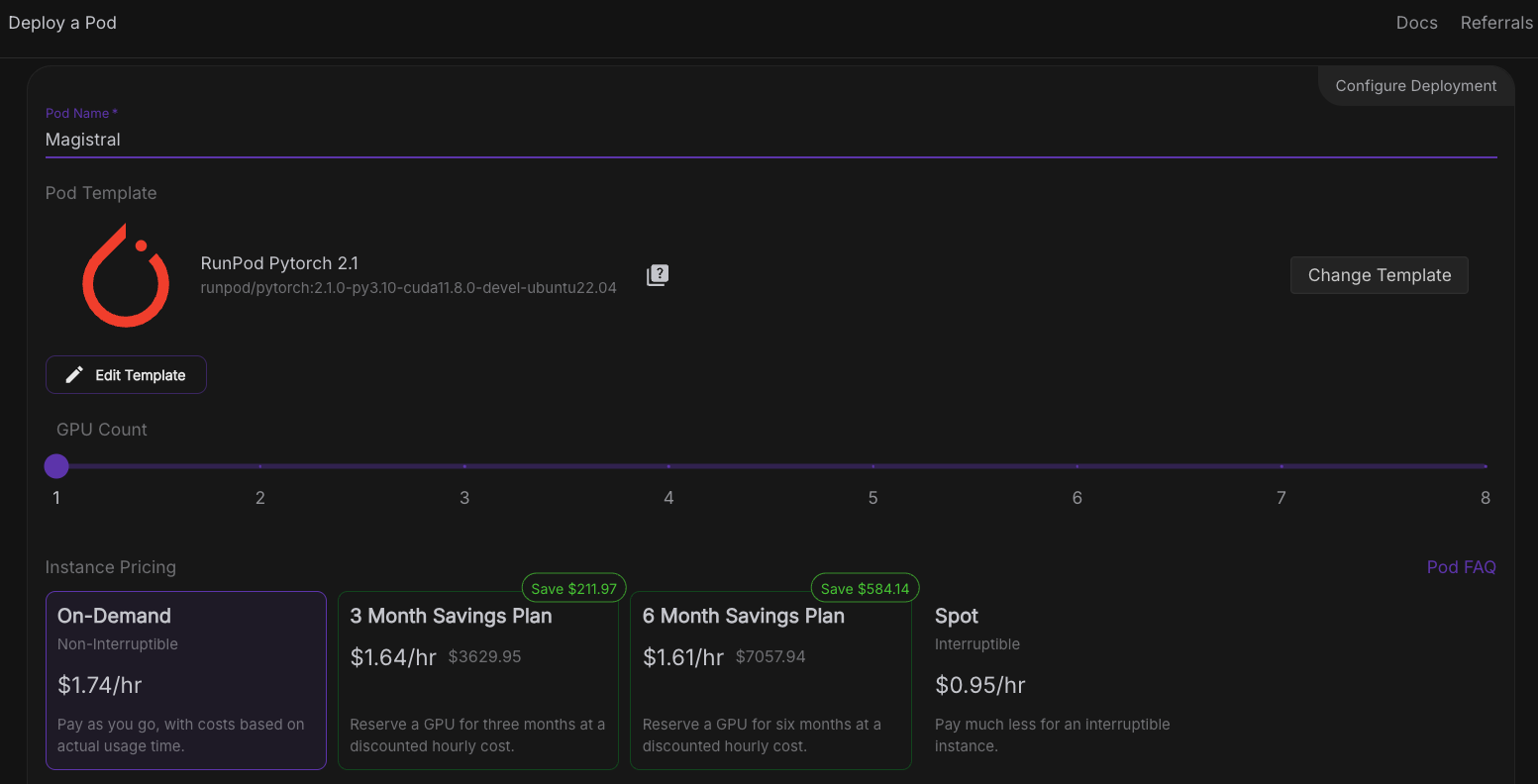
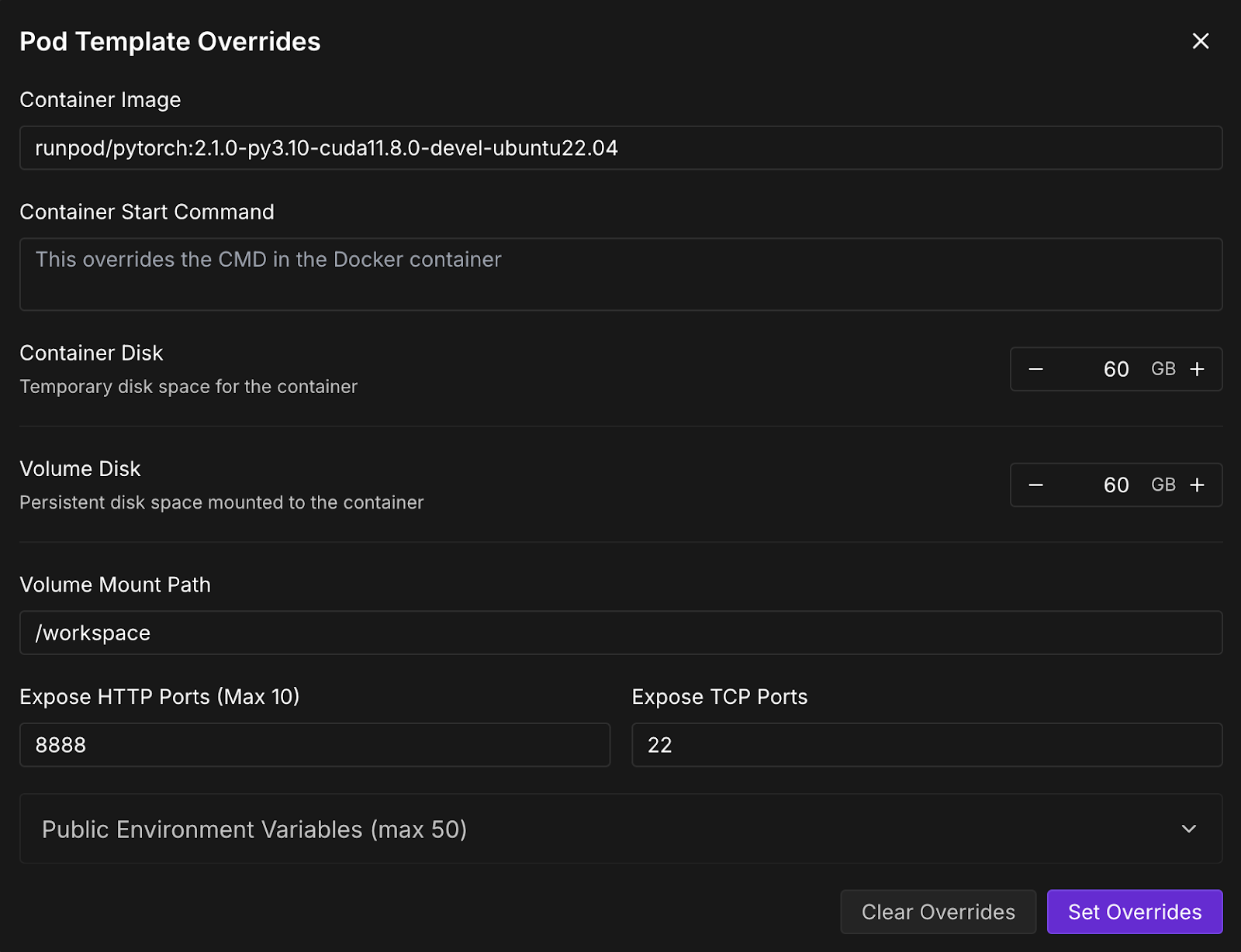
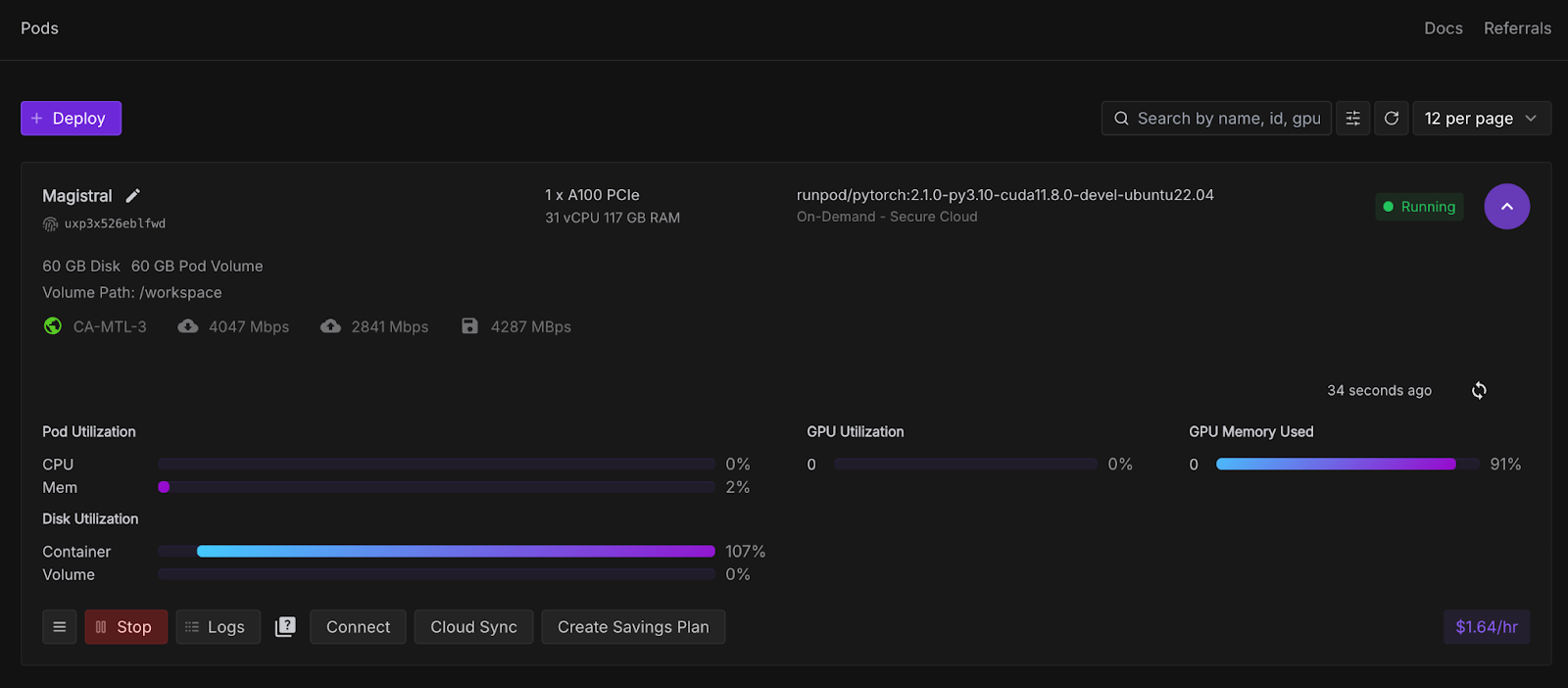
Quando o botãoConnect se tornar clicável, clique nele. Você verá várias opções de conexão - você pode:
Observação: Espere até que você veja um ponto verde 🟢 com um sinal Ready abaixo do Jupyter Lab.
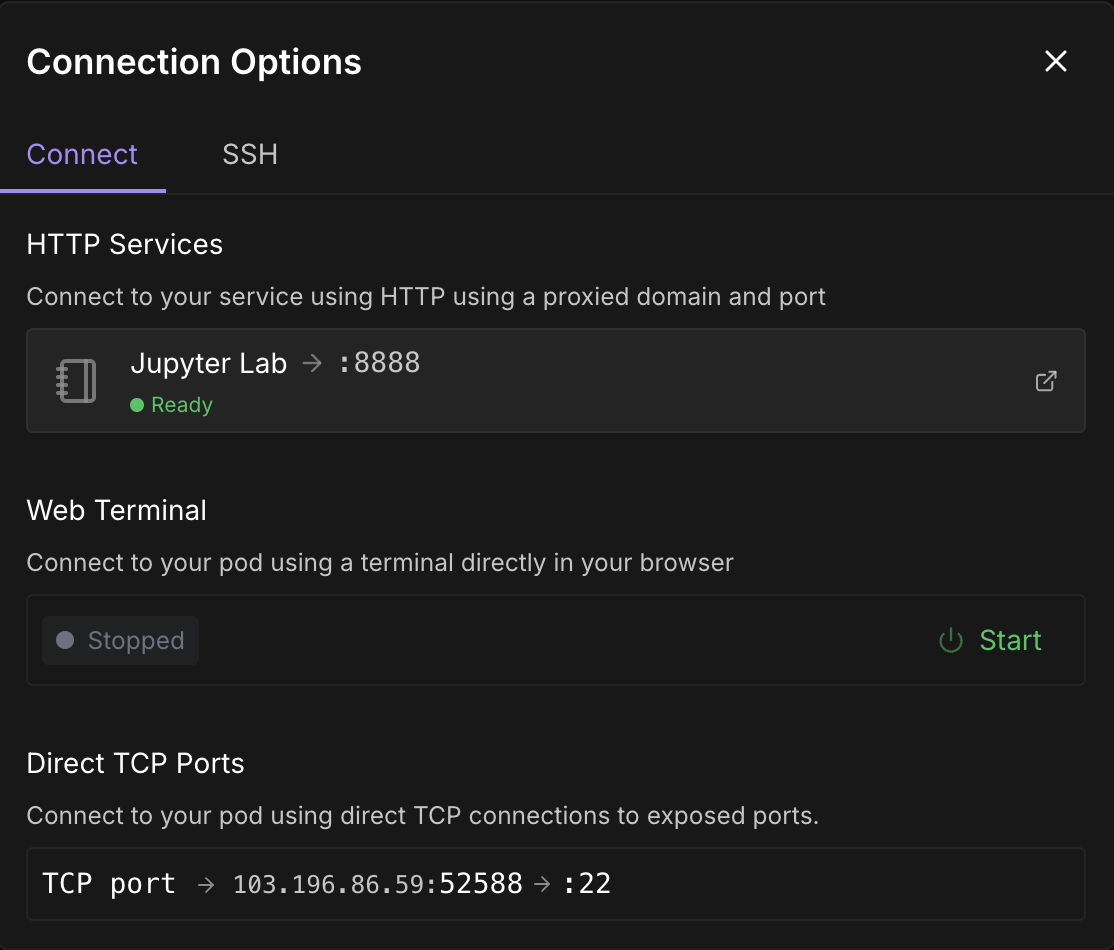
Clique em Jupyter Lab- isso levará você a outra janela com opções para criar um novo notebook Jupyter. Abra um novo terminal ou configure um novo arquivo Python.
No terminal ou no Jupyter Notebook dentro do seu pod, instale o vLLM e suas dependências.
pip install -U vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install gradioAlém disso, verifique se você está executando o mistral_common >= 1.6.0:
python -c "import mistral_common; print(mistral_common.__version__)"Agora, vamos servir o modelo. Clique no sinal de "+" no canto superior esquerdo e selecione terminal nas opções e, em seguida, execute o seguinte comando:
vllm serve mistralai/Magistral-Small-2506 \
--tokenizer_mode mistral \
--config_format mistral \
--load_format mistral \
--tool-call-parser mistral \
--enable-auto-tool-choiceMantenha esse terminal em execução, pois esse comando inicia omodeloMagistral Small usando vLLM e o disponibiliza em um endpoint de API rápido e compatível com OpenAI (http://localhost:8000/v1). Aqui está um resumo de cada bandeira:
|
Bandeira |
Descrição |
|
|
É um identificador de modelo Hugging Face. O vLLM faz o download automático desse modelo se você ainda não o tiver. |
|
|
Isso garante que o tokenizador seja interpretado usando a lógica específica do Mistral |
|
|
Isso indica que a configuração do modelo está no formato personalizado do Mistral, e não no padrão do Hugging Face. |
|
|
Isso carrega os pesos do modelo usando o layout esperado do Mistral (importante para a compatibilidade). |
|
|
Ele permite uma sintaxe de chamada de ferramenta de análise de acordo com a estrutura do Mistral. |
|
|
Seleciona automaticamente a melhor ferramenta com base na entrada se a chamada de ferramenta for usada. Isso é opcional, mas útil para modelos treinados com raciocínio de ferramentas. |
Agora, criaremos uma demonstração em que o Magistral é solicitado a depurar uma lógica falha ou uma prova matemática. O modelo produzirá um monólogo interno detalhado em tags<think> e um resumo final.
Começamos configurando as importações e inicializando o cliente OpenAI no Jupyter Notebook. Em seguida, configuramos o prompt do sistema do Magistral, conforme sugerido no documento original do Magistral.
import gradio as gr
from openai import OpenAI
import re
import time
client = OpenAI(api_key="EMPTY", base_url="http://localhost:8000/v1")
SYSTEM_PROMPT = """<s>[SYSTEM_PROMPT]system_prompt
A user will ask you to solve a task. You should first draft your thinking process (inner monologue) until you have derived the final answer. Afterwards, write a self-contained summary of your thoughts.
<think>
Your thoughts or draft, like working through an exercise on scratch paper.
</think>
Here, provide a concise summary that reflects your reasoning and presents a clear final answer to the user.
Problem:
[/SYSTEM_PROMPT]"""O site SYSTEM_PROMPT define o formato estruturado de como o modelo deve responder:
Em seguida, lidamos com o fluxo de saída do modelo definindo os requisitos temperature, top_p e max_tokens, conforme sugerido no blog original do Magistral.
# Streaming logic with stop control
def debug_faulty_logic_stream(faulty_proof, stop_signal):
stop_signal["stop"] = False
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Here is a flawed logic or math proof. Can you debug it step-by-step?\n\n{faulty_proof}"}
]
try:
response = client.chat.completions.create(
model="mistralai/Magistral-Small-2506",
messages=messages,
stream=True,
temperature=0.7,
top_p=0.95,
max_tokens=2048
)
buffer = ""
for chunk in response:
if stop_signal.get("stop"):
break
delta = chunk.choices[0].delta
if hasattr(delta, "content") and delta.content:
buffer += delta.content
filtered = re.sub(r"<think>.*?</think>", "", buffer, flags=re.DOTALL).strip()
yield filtered
time.sleep(0.02)
except Exception as e:
yield f"Error: {str(e)}"
# Set stop flag when stop button is clicked
def stop_streaming(stop_signal):
stop_signal["stop"] = True
return gr.Textbox.update(value="Stopped.")O trecho de código acima lida com a transmissão ao vivo de saída token a token do modelo. O site stop_signal permite que os usuários interrompam a transmissão clicando no botão "Stop".
Enquanto o buffer acumula todo o conteúdo, mas produz apenas o resumo (excluindo a tag<think> ) usando uma expressão regular. Se ocorrer algum erro (por exemplo, problema de rede), ele retornará a mensagem de erro.
Vamos juntar tudo isso com um aplicativo Gradio simples que permite que os usuários adicionem sua lógica ou prova com falhas e a enviem ao modelo para raciocínio.
with gr.Blocks() as demo:
gr.Markdown("## Chain-of-Logic Debugger (Streaming via Magistral + vLLM)")
input_box = gr.Textbox(
label="Paste Your Faulty Logic or Proof",
lines=8,
placeholder="e.g., Assume x = y, then x² = xy..."
)
output_box = gr.Textbox(label="Corrected Reasoning (Streaming Output)")
submit_btn = gr.Button("Submit")
stop_btn = gr.Button("Stop")
stop_flag = gr.State({"stop": False})
submit_btn.click(
fn=debug_faulty_logic_stream,
inputs=[input_box, stop_flag],
outputs=output_box
)
stop_btn.click(
fn=stop_streaming,
inputs=stop_flag,
outputs=output_box
)
if __name__ == "__main__":
demo.launch(share=True, inbrowser=True, debug=True)O código acima cria uma interface Gradio simples com:
Ele usa o programa gr.State para saber se o usuário deseja interromper o processo de streaming. Em seguida, o método launch() executa o aplicativo localmente e o abre em seu navegador. Aqui está a entrada que tentei:
Assume x = y. Then, x² = xy. Subtracting both sides gives x² - y² = xy - y². So, (x+y)(x−y) = y(x−y). Cancelling x−y gives x+y = y. But since x = y, this means 2y = y → 2 = 1.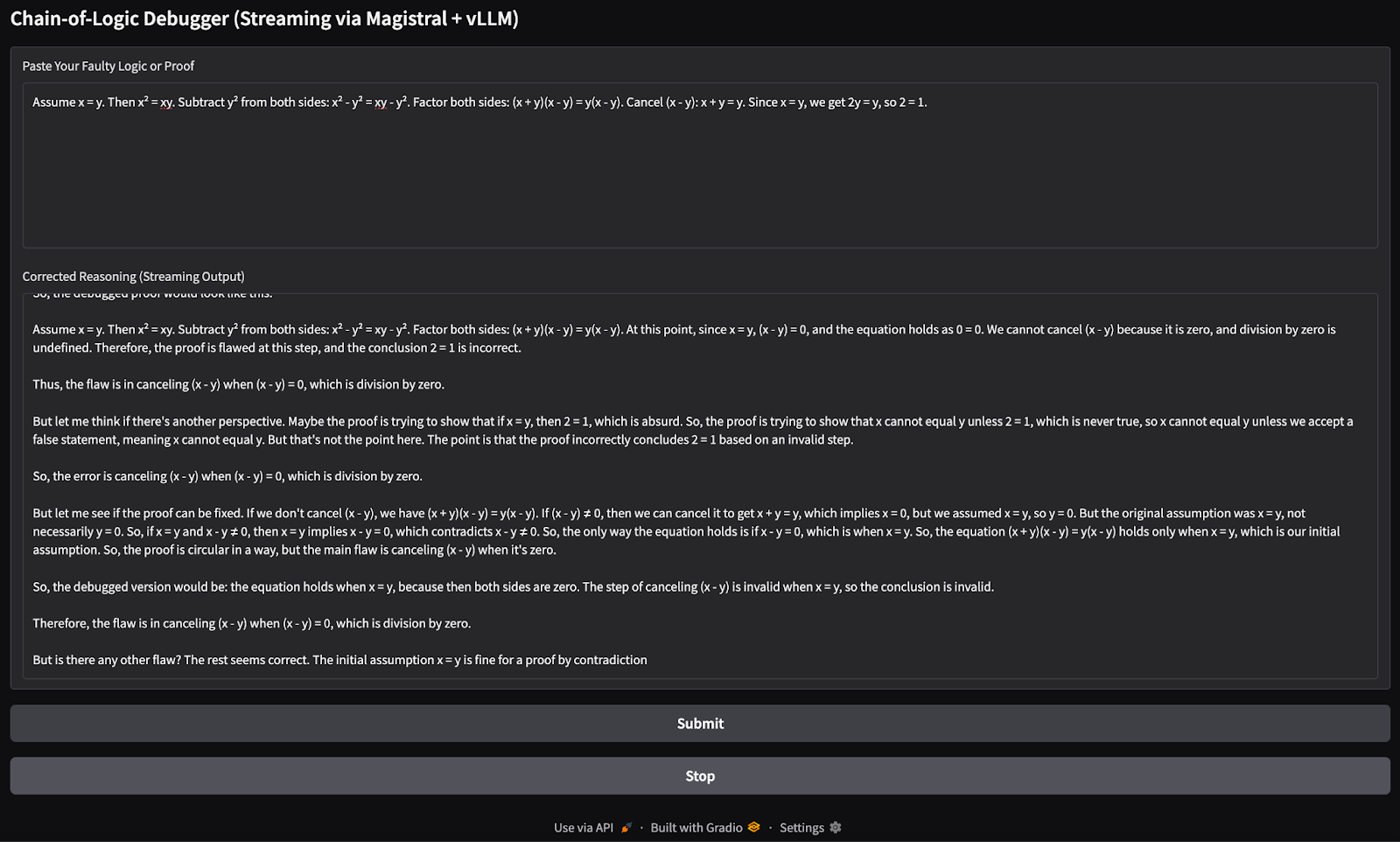
Você pode alternar para o terminal já em execução onde o vLLM está servindo para verificar os registros do uso do cache KV, bem como a taxa de acerto que aumenta quando o modelo está retornando qualquer saída.

Em comparação com o Ollama, o vLLM foi visivelmente mais rápido e mais estável durante a inferência. O fluxo foi suave e os resultados foram, em sua maioria, bem estruturados. Dito isso, o modelo às vezes repetia pensamentos nas seções <think >, provavelmente devido à natureza da decodificação autorregressiva sem penalidades de amostragem.
Embora o Ollama ofereça suporte a uma versão quantizada de 4 bits do modelo para inferência eficiente no dispositivo, o vLLM requer aceleração de GPU, o que torna sua execução um pouco mais cara (cerca de US$ 5 para este projeto). O modelo Magistral quantizado de 4 bits requer aproximadamente 14 GB de memória, que pode ser hospedada em uma única GPU RTX 4090 ou até mesmo em um MacBook com 32 GB de RAM. No entanto, a inferência pode ser lenta, até 4 minutos por resposta, devido à computação limitada.
Em contrapartida, o vLLM oferece inferência significativamente mais rápida (aproximadamente menos de um minuto por resposta) quando implantado em GPUs de alto desempenho, como a A100 SXM, o que o torna mais adequado para aplicativos responsivos ou implantações em escala.
Se você estiver apenas experimentando e tiver recursos locais, o Ollama é ideal devido ao seu baixo custo de configuração. Mas para desempenho de nível de produção ou cargas de trabalho maiores, o vLLM é a opção recomendada. Lembre-se de que, embora o vLLM possa ser executado localmente, ele ainda exige uma GPU capaz.
Neste tutorial, usamos o Magistral Small - um LLM de raciocínio primeiro da Mistral - para criar um depurador lógico passo a passo. Implantamos o modelo localmente usando o Ollama para testes rápidos no dispositivo e o vLLM para inferência de GPU de alto rendimento com APIs compatíveis com OpenAI. Também testamos os recursos de raciocínio do modelo com um aplicativo Gradio. Se você estiver depurando uma lógica falha ou criando ferramentas de IA de raciocínio, o Magistral Small pode ser uma boa solução.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
