
Kurs
Einführung in LLMs mit Python
3 Std.
33.6K
Mistral AI hat vor kurzem eine neue Familie von Argumentationsmodellen namens Magistral auf den Markt gebracht. Diese Modelle sind so konzipiert, dass sie sich in bestimmten Bereichen auszeichnen, eine transparente Argumentation ermöglichen und mehrere Sprachen unterstützen.
In diesem Tutorial konzentrieren wir uns auf die Feinabstimmung von Magistral Small anhand des MCQs-Datensatzes für medizinische Fragen. Die Magistral Small ist eine Open-Source-Variante der Magistral-Familie mit 24 Milliarden Parametern. Sie basiert auf der Version 3.1 (2503) und hat erweiterte Argumentationsmöglichkeiten.
Hier sind die Schritte, die wir in diesem Tutorial befolgen werden:
Ich habe zunächst versucht, das Feintuning-Skript auf Kaggle laufen zu lassen, aber selbst mit 4-Bit-Quantisierung waren die freien GPUs für diese Aufgabe nicht ausreichend. Aufgrund dieser Einschränkungen bin ich zu RunPod gewechselt und habe eine A100 SXM GPU-Instanz ausgewählt, die eine schnellere Leistung und einen größeren VRAM bietet.
1. Gehe auf RunPod zu "Pods", wähle das neueste PyTorch-Image aus, wähle die A100 SXM-Maschine und setze deinen Pod ein.
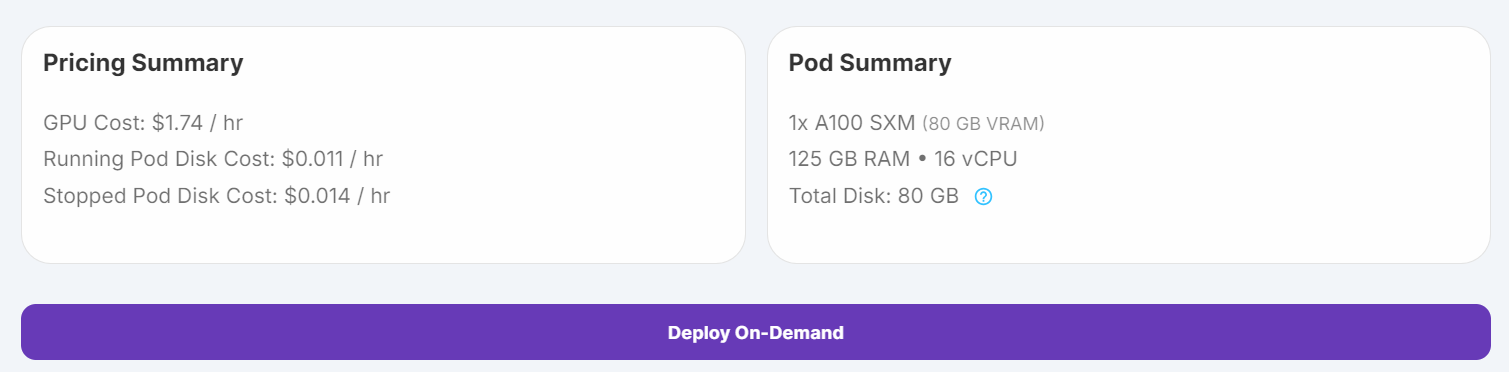
Quelle: Meine Schoten
2. Bearbeite die Pod-Einstellungen, um die Größe der Container-Festplatte zu erhöhen, und füge dein Hugging Face-Zugangs-Token zur Authentifizierung hinzu.
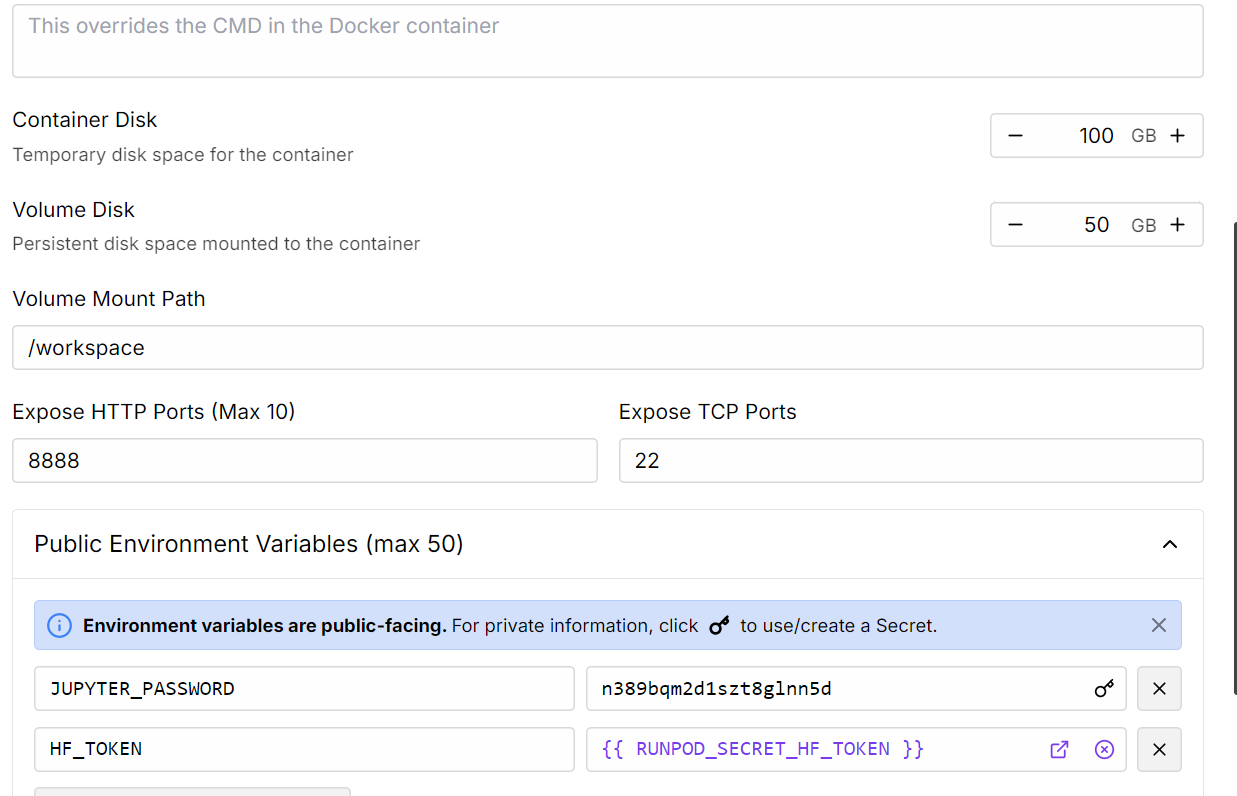
Quelle: Meine Schoten
3. Sobald der Pod läuft, klicke auf die Schaltfläche Connect und starte eine JupyterLab-Instanz für die interaktive Entwicklung.
4. Installiere alle notwendigen Python-Pakete
%%capture
%pip install -U transformers==4.52.1
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes5. Melde dich bei Hugging Face mit deinem Zugangstoken an (den du zuvor gespeichert hast). So kannst du Gated Models laden und später dein fein abgestimmtes Modell und deinen Tokenizer hochladen:
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Wir werden die unsloth 4-Bit quantisierte Version von Magistral-Small verwenden, um Speicherplatz und VRAM zu sparen. Dieser Ansatz ist viel schneller und effizienter als das Herunterladen des hochpräzisen Modells und die manuelle Quantisierung.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "unsloth/Magistral-Small-2506-bnb-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
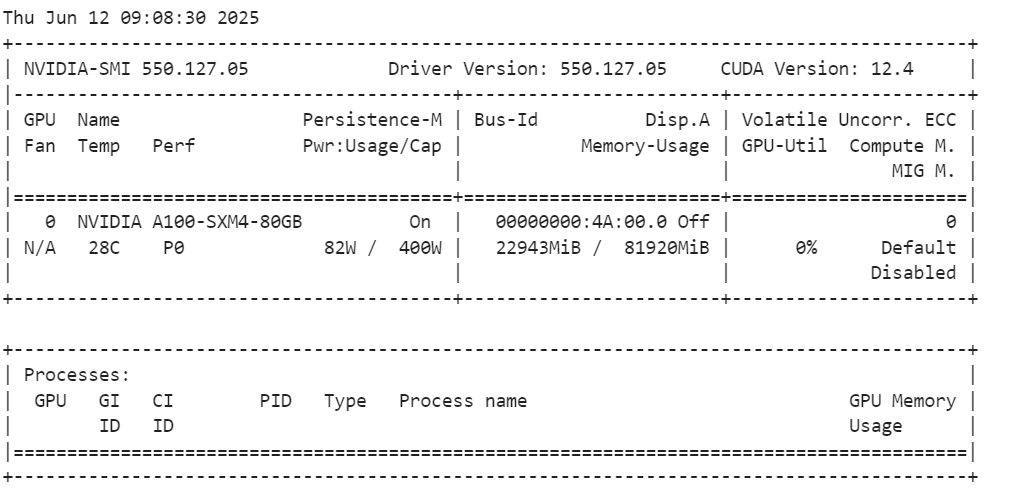
Nachdem du das Modell geladen hast, überprüfe die Nutzung des GPU-Speichers.
!nvidia-smiWie wir sehen können, verbraucht er nur 23 GB VRam.
Definiere eine Aufforderungsvorlage, die das Modell anweist, mit einer der vorgegebenen Optionen zu antworten, die Argumentation in den <analysis></analysis>-Tags und die endgültige Antwort in den <answer></answer>-Tags einzuschließen.
train_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
{}"""
Erstelle eine Python-Funktion, die jedes Beispiel entsprechend dem Prompt-Stil formatiert und das EOS-Token anhängt, wenn es fehlt.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["input"]
outputs = examples["output"]
texts = []
for question, response in zip(inputs, outputs):
# Remove the "Q:" prefix from the question
question = question.replace("Q:", "")
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, response)
texts.append(text)
return {"text": texts}Lade dann den Datensatz mamachang/medical-reasoning von Hugging Face herunter und lade ihn. Wende die Formatierungsfunktion an, um eine neue "Text"-Spalte mit der strukturierten Eingabeaufforderung zu erstellen.
from datasets import load_dataset
dataset = load_dataset(
"mamachang/medical-reasoning",
split="train",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
print(dataset["text"][10])Die Spalte "Text" enthält die Systemaufforderung, die Frage, die Analyse und die Antwort im erforderlichen Format.

Da der neue SFTTrainer keinen Tokenizer direkt akzeptiert, konvertiere den Tokenizer in einen Datensammler für die Sprachmodellierung.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Bevor du die Feinabstimmung vornimmst, ist es wichtig, die Leistung des Basismodells für deinen Datensatz zu bewerten. Anhand dieser Grundlinie kannst du die Ergebnisse nach der Feinabstimmung objektiv vergleichen und Verbesserungen messen.
Definiere eine Prompt-Vorlage für Inferenzen, die einen Systemprompt, einen Frageabschnitt (mit einem Platzhalter) und einen Antwortabschnitt enthält.
inference_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
<analysis>
"""Wähle die 11. Frage aus deinem Datensatz, entferne alle unnötigen Präfixe und tokenisiere sie für die Modelleingabe
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])In diesem Basistest war die vom Modell erstellte Analyse übermäßig lang und führte oft nicht zu einer richtigen oder präzisen Antwort.

In diesem Teil werden wir das Modell für die Feinabstimmung einrichten.
Wir verwenden LoRA (Low-Rank Adaptation) zur Feinabstimmung des Modells verwenden, was unseren Speicherbedarf erheblich reduziert und den Trainingsprozess beschleunigt, da wir nur eine kleine Teilmenge der Modellparameter feinabstimmen.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)Mit der KlasseTrainingArguments kannst du die Stapelgröße, den Optimierer, die Lernrate und andere Trainingshyperparameter konfigurieren. Die SFTTrainer aus der TRL-Bibliothek rationalisiert die überwachte Feinabstimmung, indem sie das Modell, den Datensatz, den Datensammler, die Trainingsargumente und die LoRA-Konfiguration in einen einzigen Arbeitsablauf integriert.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="Magistral-Medical-Reasoning",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)
Um "Out of Memory"-Fehler (OOM) zu vermeiden, ist es wichtig, den Python Garbage Collector zu löschen und den CUDA Cache zu leeren, bevor du mit dem Training beginnst. Dadurch wird sichergestellt, dass ungenutzter Speicher aus früheren Operationen freigegeben wird.
Starten Sie dann den Trainingsprozess mit der Option SFTTrainer.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Während des Trainings erreichte die GPU-Auslastung 100 %, und es war genügend VRAM verfügbar, um möglicherweise ein weiteres Modell parallel zu laden.
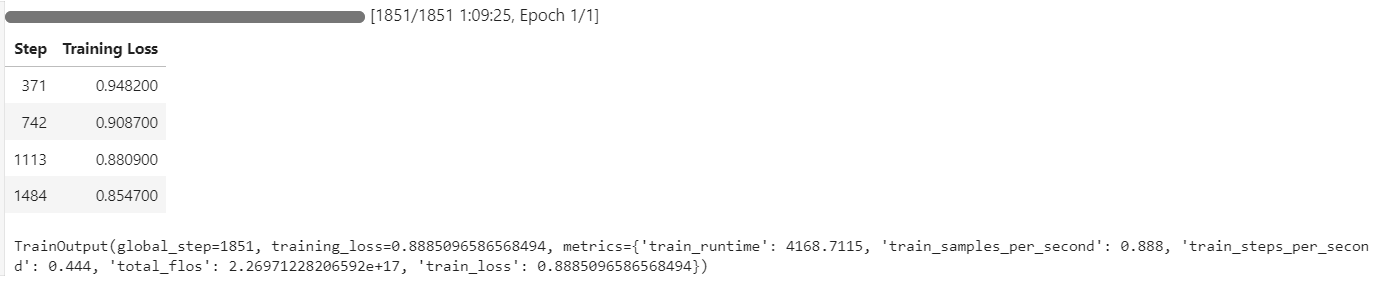
Der Trainingsprozess dauerte etwa 1 Stunde und 10 Minuten, wobei der Trainingsverlust bei jedem Schritt stetig abnahm, was auf ein effektives Lernen hindeutet.
Wir werden die Leistung des feinabgestimmten Modells anhand der gleichen 11. Mit diesem Ansatz können wir die Ergebnisse mit dem Basismodell vergleichen und die durch die Feinabstimmung erzielten Verbesserungen bewerten.
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question,) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Das Modell erstellt nun eine präzise und genaue Analyse, und die Antwort ist richtig.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key issue with the validity of this study is confounding. The researchers did not account for other factors that could influence cardiovascular disease risk in adulthood besides childhood diet.
To address confounding, the researchers should have stratified the analysis by potential confounders like family history, physical activity levels, and smoking status. This would allow them to see if the relationship between diet and disease persists even when accounting for these other variables.
Blinding, crossover, matching, and randomization do not address the main validity concern in this study design.
</analysis>
<answer>
D: Stratification
</answer>Um die Leistung weiter zu überprüfen, kannst du die Inferenz an einer anderen Stichprobe ausprobieren.
question = dataset[100]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Das Modell liefert weiterhin genaue Antworten und gut strukturierte Analysen und zeigt auch nach nur einer Epoche der Feinabstimmung konstante Verbesserungen.
<analysis>
This is a clinical vignette describing a 55-year-old man with burning and shooting pain in his feet and lower legs that worsens at night. He has a history of type 2 diabetes mellitus and hypertension.
The key findings are:
- Burning and shooting pain in feet and lower legs
- Pain worsens at night
- History of type 2 diabetes mellitus
This presentation is most consistent with diabetic peripheral neuropathy. The pain distribution, timing, and history of diabetes point towards a distal symmetric sensorimotor polyneuropathy as the etiology. The other options can be ruled out based on the clinical presentation.
</analysis>
<answer>
D: Distal symmetric sensorimotor polyneuropathy
</answer>Nach der Feinabstimmung kannst du dein Modell ganz einfach teilen, indem du es zum Hugging Face Hub schiebst. So können sie von anderen genutzt oder weiter verfeinert werden.
new_model_name = "kingabzpro/Magistral-Small-Medical-QA"
trainer.model.push_to_hub(new_model_name)
trainer.processing_class.push_to_hub(new_model_name)
Das abgestimmte Modell ist jetzt verfügbar unter: kingabzpro/Magistral-Small-Medical-QA
Quelle: kingabzpro/Magistral-Small-Medical-QA
Nach der Feinabstimmung und dem Speichern deiner LoRA im Hugging Face Hub kannst du sie für weitere Analysen, Inferenzen oder den Einsatz als Inferenzserver einfach wieder laden. Dazu musst du deine aktuelle Sitzung löschen, das Basismodell und den LoRA-Adapter laden und die Inferenz mit neuen Daten durchführen. Mehr über die Arbeit mit dem Hugging Face Hub kannst du in unserem Kurs erfahren.
1. Bevor du ein neues Modell lädst, ist es ratsam, alle vorhandenen Modell- und Trainerobjekte zu löschen und den GPU-Cache zu leeren, um Speicherprobleme zu vermeiden.
2. Lade das Basismodell und deinen angepassten LoRA-Adapter vom Hugging Face Hub herunter und führe sie dann zusammen. Lade außerdem den Tokenizer.
del model
del trainer
torch.cuda.empty_cache()
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
import torch
# Base model
base_model_id = "unsloth/Magistral-Small-2506-bnb-4bit"
# Your fine-tuned LoRA adapter repository
lora_adapter_id = "kingabzpro/Magistral-Small-Medical-QA"
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
# Attach the LoRA adapter
model = PeftModel.from_pretrained(
base_model,
lora_adapter_id,
device_map="auto",
trust_remote_code=True,
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)3. Bereite eine Beispielaufforderung vor, tokenisiere sie, generiere eine Antwort und dekodiere die Ausgabe.
# Inference example
prompt = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
A research group wants to assess the relationship between childhood diet and cardiovascular disease in adulthood.
A prospective cohort study of 500 children between 10 to 15 years of age is conducted in which the participants' diets are recorded for 1 year and then the patients are assessed 20 years later for the presence of cardiovascular disease.
A statistically significant association is found between childhood consumption of vegetables and decreased risk of hyperlipidemia and exercise tolerance.
When these findings are submitted to a scientific journal, a peer reviewer comments that the researchers did not discuss the study's validity.
Which of the following additional analyses would most likely address the concerns about this study's design?
{'A': 'Blinding', 'B': 'Crossover', 'C': 'Matching', 'D': 'Stratification', 'E': 'Randomization'},
### Response:
<analysis>
"""
inputs = tokenizer(
[prompt + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])4. Die erzeugte Antwort ist genau und entspricht genau dem Stil und der Struktur deines Datensatzes, was zeigt, dass das fein abgestimmte Modell bereit ist für Schlussfolgerungen und den Einsatz in der realen Welt.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key concern from the peer reviewer is about the study's validity.
To address concerns about validity, the researchers could perform additional analyses to control for confounding. Matching and stratification would help control for known confounders like socioeconomic status or family history. Crossover and blinding are not applicable to this observational study design. Randomization would not be possible since the study is observational.
</analysis>
<answer>
D: Stratification
</answer>
Wenn du beim Ausführen des obigen Codes auf Probleme stößt, sieh dir bitte das Jupyter-Notizbuch fine-tuning-magistral.ipynb auf dem Hugging Face an.
In einem separaten Leitfaden zur Feinabstimmung haben wir uns angeschaut, wie der destillierte Modus von DeepSeek-R1-0528 funktioniert. Während DeepSeek-R1-0528 Schwierigkeiten hatte, sich an den spezifischen Stil des Datensatzes und die Genauigkeit anzupassen, zeigte Magistral eine nahtlose Anpassung und lieferte starke Ergebnisse mit minimalem Aufwand.
Diese Erfahrung bestärkt mich in meiner Überzeugung, dass Mistral AI sich schnell zu einem führenden Unternehmen im Bereich der KI entwickelt, nicht nur bei Sprachmodellen, sondern auch bei einem breiten Spektrum von Lösungen, einschließlich Computer Vision.
In diesem Leitfaden haben wir das neueste Reasoning-Modell von Mistral AI, Magistral, erfolgreich an einem medizinischen MCQ-Datensatz getestet.
Es ist jedoch wichtig zu wissen, dass für das Feintuning großer Modelle wie Magistral umfangreiche Hardware benötigt wird, in der Regel GPUs mit mindestens 40 GB VRAM, da selbst die RTX 4090 für einige Konfigurationen nicht ausreicht. Ich habe auch mit dem Unsloth-Framework und seiner 4-Bit-Modellversion experimentiert, hatte aber immer noch Probleme mit dem GPU-Speicher.
Wenn du nach einem praktischen Kurs suchst, um dich mit der Feinabstimmung vertraut zu machen, solltest du dir "Feinabstimmung mit Llama 3" ansehen.
Top LLM-Kurse
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
