
Curso
Introducción a los LLMs en Python
3 h
33.6K
Mistral AI ha lanzado recientemente una nueva familia de modelos de razonamiento llamada Magistral. Estos modelos están diseñados para sobresalir en dominios específicos, proporcionar un razonamiento transparente y soportar múltiples lenguajes.
En este tutorial, nos centraremos en el ajuste fino de Magistral Small en el conjunto de datos de razonamiento MCQs de Medicina. El Magistral Pequeño es una variante de código abierto de la familia Magistral con 24.000 millones de parámetros. Se basa en la versión 3.1 (2503) y tiene capacidades de razonamiento mejoradas.
Estos son los pasos que vamos a seguir en este tutorial:
Inicialmente intenté ejecutar el script de ajuste fino en Kaggle, pero incluso con la cuantización de 4 bits, las GPUs libres eran insuficientes para esta tarea. Debido a estas limitaciones, cambié a RunPod y seleccioné una instancia de GPU A100 SXM, que ofrece un rendimiento más rápido y mayor VRAM.
1. Ve a "Pods" en RunPod, elige la última imagen de PyTorch, selecciona la máquina A100 SXM y despliega tu pod.
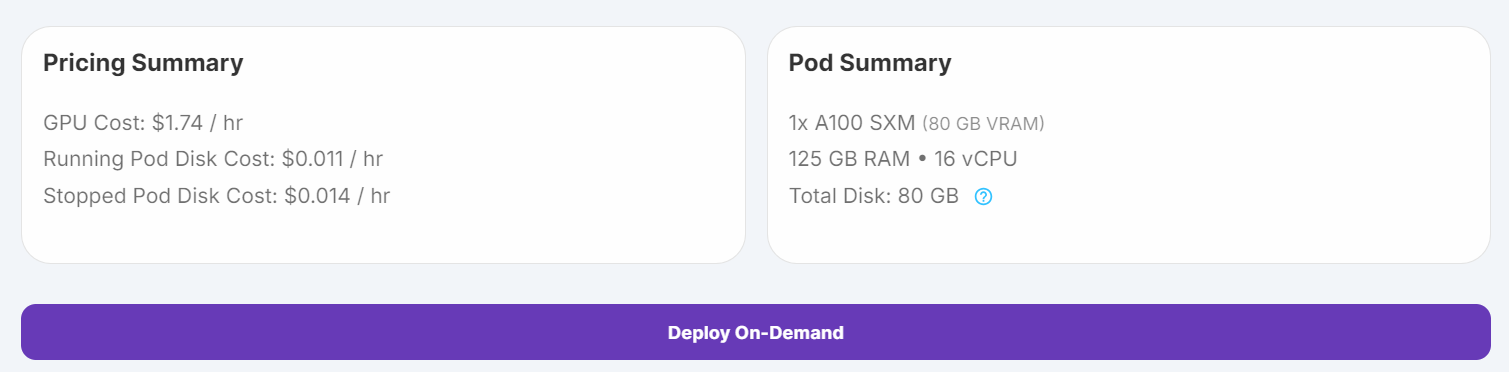
Fuente: Mis vainas
2. Edita la configuración del Pod para aumentar el tamaño del disco contenedor y añade tu token de acceso Hugging Face para la autenticación.
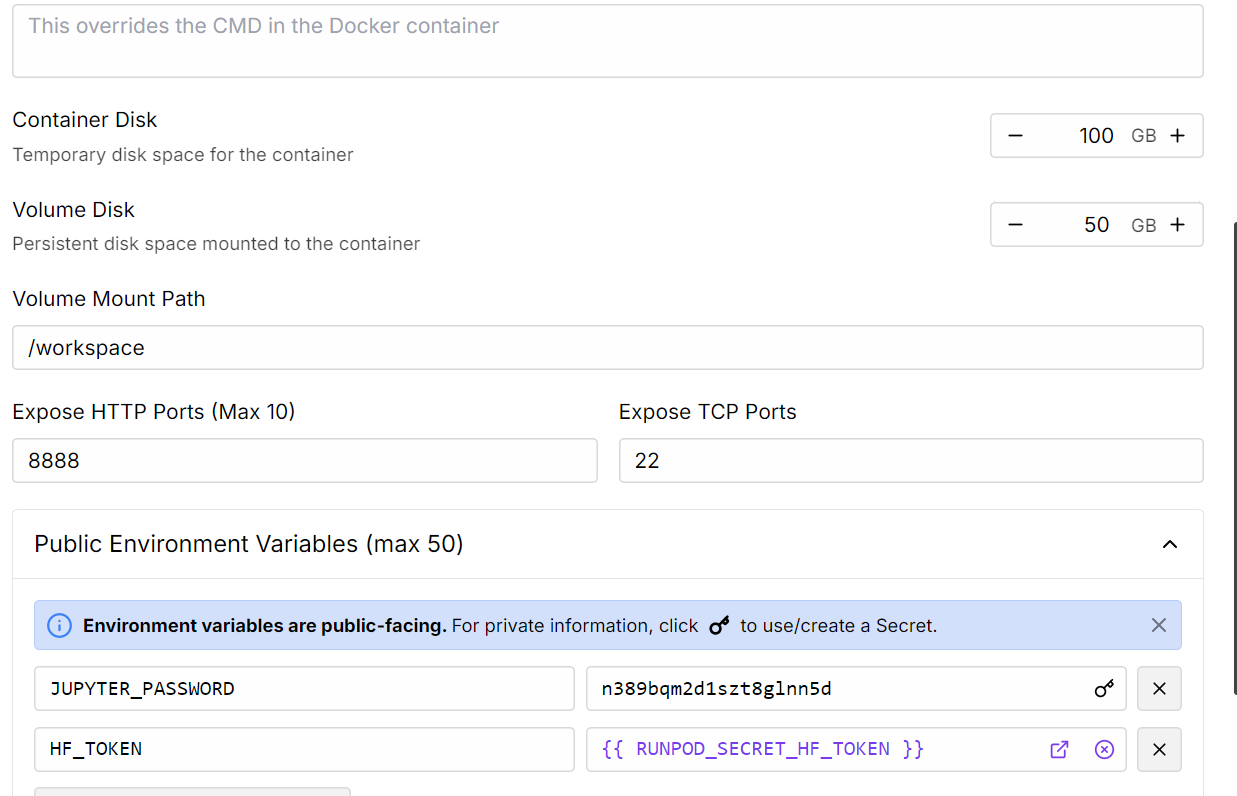
Fuente: Mis vainas
3. Una vez que el pod se esté ejecutando, haz clic en el botón Connect e inicia una instancia de JupyterLab para el desarrollo interactivo.
4. Instala todos los paquetes de Python necesarios
%%capture
%pip install -U transformers==4.52.1
%pip install -U datasets
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes5. Inicia sesión en Hugging Face utilizando tu código de acceso (que guardaste anteriormente). Esto te permite cargar modelos cerrados y, más tarde, cargar tu modelo y tokenizador ajustados:
from huggingface_hub import login
import os
hf_token = os.environ.get("HF_TOKEN")
login(hf_token)Utilizaremos la versión Unsloth cuantificada en 4 bits de Magistral-Pequeño para ahorrar espacio de almacenamiento y VRAM. Este método es mucho más rápido y eficaz que descargar el modelo de precisión completa y cuantizarlo manualmente.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load tokenizer & model
model_dir = "unsloth/Magistral-Small-2506-bnb-4bit"
tokenizer = AutoTokenizer.from_pretrained(model_dir, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
torch_dtype=torch.bfloat16,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
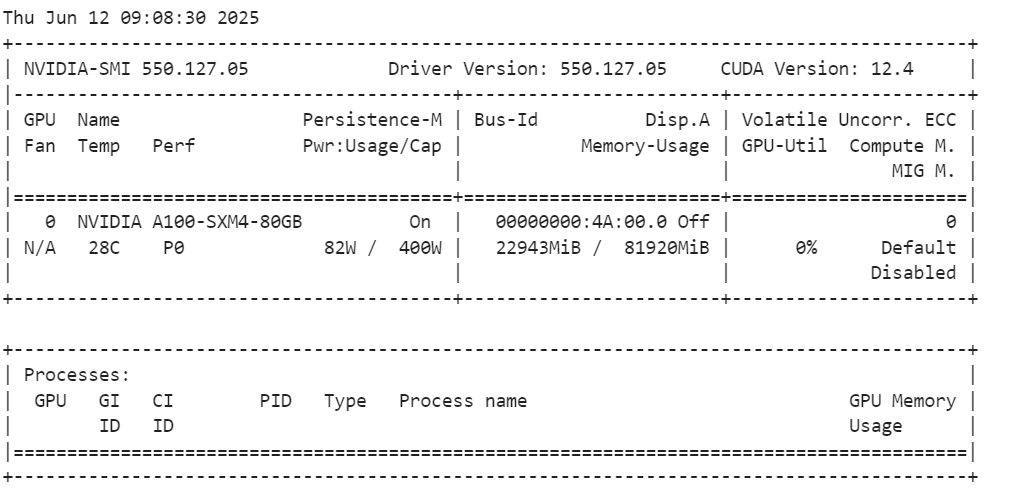
Después de cargar el modelo, comprueba el uso de memoria de tu GPU.
!nvidia-smiComo podemos ver, sólo utiliza 23 GB de VRam.
Define una plantilla de pregunta que indique al modelo que responda con una de las opciones proporcionadas, incluya el razonamiento dentro de las etiquetas <análisis></análisis> y la respuesta final dentro de las etiquetas <respuesta></respuesta>.
train_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
{}"""
Crea una función Python que formatee cada ejemplo según el estilo de consulta y añada el símbolo EOS si falta.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["input"]
outputs = examples["output"]
texts = []
for question, response in zip(inputs, outputs):
# Remove the "Q:" prefix from the question
question = question.replace("Q:", "")
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, response)
texts.append(text)
return {"text": texts}A continuación, descarga y carga el conjunto de datos mamachang/medical-reasoning de Hugging Face. Aplica la función de formato para crear una nueva columna "texto" con la consulta estructurada.
from datasets import load_dataset
dataset = load_dataset(
"mamachang/medical-reasoning",
split="train",
trust_remote_code=True,
)
dataset = dataset.map(
formatting_prompts_func,
batched=True,
)
print(dataset["text"][10])La columna "texto" contiene la indicación del sistema, la pregunta, el análisis y la respuesta, todo ello en el formato requerido.

Como el nuevo SFTTrainer no acepta un tokenizador directamente, convierte el tokenizador en un recopilador de datos para el modelado lingüístico.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)Antes de afinar, es importante evaluar el rendimiento del modelo base en tu conjunto de datos. Esta línea de base te ayudará a comparar objetivamente los resultados tras la puesta a punto y a medir las mejoras.
Define una plantilla de aviso para la inferencia que incluya un aviso del sistema, una sección de preguntas (con un marcador de posición) y una sección de respuestas.
inference_prompt_style = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
{}
### Response:
<analysis>
"""Selecciona la undécima pregunta de tu conjunto de datos, elimina los prefijos innecesarios y tokenízala para la entrada del modelo
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])En esta prueba de referencia, el análisis generado por el modelo era excesivamente largo y a menudo no producía una respuesta correcta o concisa.

En esta parte, configuraremos el modelo para el ajuste fino.
Utilizaremos LoRA (Adaptación de bajo rango) para afinar el modelo, lo que reducirá significativamente nuestra huella de memoria y acelerará el proceso de entrenamiento, ya que sólo estamos afinando un pequeño subconjunto de los parámetros del modelo.
from peft import LoraConfig, get_peft_model
# LoRA config
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
model = get_peft_model(model, peft_config)La claseTrainingArguments te permite configurar el tamaño del lote, el optimizador, la tasa de aprendizaje y otros hiperparámetros de entrenamiento. El SFTTrainer de la biblioteca TRL agiliza el ajuste fino supervisado integrando el modelo, el conjunto de datos, el cotejador de datos, los argumentos de entrenamiento y la configuración LoRA en un único flujo de trabajo.
from trl import SFTTrainer
from transformers import TrainingArguments
# Training Arguments
training_arguments = TrainingArguments(
output_dir="Magistral-Medical-Reasoning",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)
Para evitar errores por falta de memoria (OOM), es importante borrar el recolector de basura de Python y vaciar la caché CUDA antes de empezar el entrenamiento. Esto garantiza que se libere toda la memoria no utilizada de operaciones anteriores.
A continuación, inicia el proceso de entrenamiento utilizando la función SFTTrainer.
import gc, torch
gc.collect()
torch.cuda.empty_cache()
model.config.use_cache = False
trainer.train()Durante el entrenamiento, la utilización de la GPU alcanzó el 100%, y había suficiente VRAM disponible para cargar potencialmente otro modelo en paralelo.
El proceso de entrenamiento duró aproximadamente 1 hora y 10 minutos, y la pérdida de entrenamiento disminuyó constantemente en cada paso, lo que indica un aprendizaje eficaz.
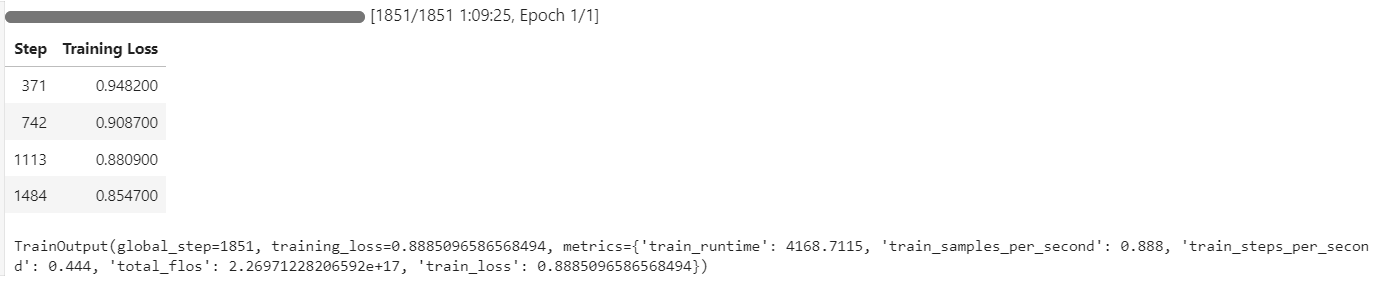
Evaluaremos el rendimiento del modelo afinado utilizando la misma 11ª pregunta de muestra del conjunto de datos. Este enfoque nos permite comparar los resultados con el modelo base y evaluar las mejoras conseguidas mediante el ajuste fino.
question = dataset[10]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question,) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])El modelo genera ahora un análisis conciso y preciso, y la respuesta es correcta.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key issue with the validity of this study is confounding. The researchers did not account for other factors that could influence cardiovascular disease risk in adulthood besides childhood diet.
To address confounding, the researchers should have stratified the analysis by potential confounders like family history, physical activity levels, and smoking status. This would allow them to see if the relationship between diet and disease persists even when accounting for these other variables.
Blinding, crossover, matching, and randomization do not address the main validity concern in this study design.
</analysis>
<answer>
D: Stratification
</answer>Para validar aún más el rendimiento, prueba la inferencia en otra muestra.
question = dataset[100]['input']
question = question.replace("Q:", "")
inputs = tokenizer(
[inference_prompt_style.format(question) + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=512,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])El modelo sigue proporcionando respuestas precisas y análisis bien estructurados, demostrando mejoras constantes incluso después de sólo una época de ajuste fino.
<analysis>
This is a clinical vignette describing a 55-year-old man with burning and shooting pain in his feet and lower legs that worsens at night. He has a history of type 2 diabetes mellitus and hypertension.
The key findings are:
- Burning and shooting pain in feet and lower legs
- Pain worsens at night
- History of type 2 diabetes mellitus
This presentation is most consistent with diabetic peripheral neuropathy. The pain distribution, timing, and history of diabetes point towards a distal symmetric sensorimotor polyneuropathy as the etiology. The other options can be ruled out based on the clinical presentation.
</analysis>
<answer>
D: Distal symmetric sensorimotor polyneuropathy
</answer>Después de ajustarlo, puedes compartir fácilmente tu modelo enviándolo al Hub de Hugging Face. Esto lo hace accesible para que otros lo utilicen o lo perfeccionen.
new_model_name = "kingabzpro/Magistral-Small-Medical-QA"
trainer.model.push_to_hub(new_model_name)
trainer.processing_class.push_to_hub(new_model_name)
El modelo perfeccionado ya está disponible en: kingabzpro/Magistral-Small-Medical-QA
Fuente: kingabzpro/Magistral-Small-Medical-QA
Después de ajustar y guardar tu LoRA en el Hub de Hugging Face, puedes recargarlo fácilmente para su posterior análisis, inferencia o despliegue como servidor de inferencia. Este proceso implica borrar la sesión actual, cargar el modelo base y el adaptador LoRA, y ejecutar la inferencia sobre los nuevos datos. Puedes obtener más información sobre Cómo trabajar con el Hub Hugging Face en nuestro curso.
1. Antes de cargar un nuevo modelo, es una buena práctica borrar todos los objetos modelo y entrenador existentes y borrar la caché de la GPU para evitar problemas de memoria.
2. Descarga el modelo base y tu adaptador LoRA ajustado desde el Hub de Hugging Face, y luego fusiónalos. Carga también el tokenizador.
del model
del trainer
torch.cuda.empty_cache()
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
import torch
# Base model
base_model_id = "unsloth/Magistral-Small-2506-bnb-4bit"
# Your fine-tuned LoRA adapter repository
lora_adapter_id = "kingabzpro/Magistral-Small-Medical-QA"
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
# Attach the LoRA adapter
model = PeftModel.from_pretrained(
base_model,
lora_adapter_id,
device_map="auto",
trust_remote_code=True,
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)3. Prepara un ejemplo de pregunta, tokenízalo, genera una respuesta y descodifica la salida.
# Inference example
prompt = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
A research group wants to assess the relationship between childhood diet and cardiovascular disease in adulthood.
A prospective cohort study of 500 children between 10 to 15 years of age is conducted in which the participants' diets are recorded for 1 year and then the patients are assessed 20 years later for the presence of cardiovascular disease.
A statistically significant association is found between childhood consumption of vegetables and decreased risk of hyperlipidemia and exercise tolerance.
When these findings are submitted to a scientific journal, a peer reviewer comments that the researchers did not discuss the study's validity.
Which of the following additional analyses would most likely address the concerns about this study's design?
{'A': 'Blinding', 'B': 'Crossover', 'C': 'Matching', 'D': 'Stratification', 'E': 'Randomization'},
### Response:
<analysis>
"""
inputs = tokenizer(
[prompt + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])4. La respuesta generada es precisa y se ajusta al estilo y la estructura de tu conjunto de datos, lo que demuestra que el modelo afinado está listo para la inferencia y el despliegue en el mundo real.
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key concern from the peer reviewer is about the study's validity.
To address concerns about validity, the researchers could perform additional analyses to control for confounding. Matching and stratification would help control for known confounders like socioeconomic status or family history. Crossover and blinding are not applicable to this observational study design. Randomization would not be possible since the study is observational.
</analysis>
<answer>
D: Stratification
</answer>
Si tienes problemas al ejecutar el código anterior, consulta el cuaderno Jupyter fine-tuning-magistral.ipynb en el Hugging Face.
En otra guía de ajuste, analizamos el rendimiento del modo destilado DeepSeek-R1-0528. Mientras que DeepSeek-R1-0528 tuvo dificultades para adaptarse al estilo específico del conjunto de datos y a la precisión, Magistral demostró una adaptación perfecta y ofreció resultados sólidos con un esfuerzo mínimo.
Esta experiencia refuerza mi convicción de que Mistral AI está emergiendo rápidamente como un actor líder en el espacio de la IA, no sólo en modelos lingüísticos, sino también en un amplio espectro de soluciones, incluida la visión por ordenador.
En esta guía, hemos perfeccionado con éxito el último modelo de razonamiento de Mistral AI, Magistral, en un conjunto de datos de preguntas frecuentes de medicina.
Sin embargo, es importante tener en cuenta que el ajuste fino de modelos grandes como Magistral requiere un hardware considerable, normalmente GPUs con al menos 40 GB de VRAM, ya que incluso la RTX 4090 puede no ser suficiente para algunas configuraciones. También experimenté con el marco Unsloth y su versión de modelo de 4 bits, pero seguí encontrando problemas de memoria en la GPU.
Si buscas un curso práctico para familiarizarte con el ajuste fino, no dejes de consultar Ajuste fino con Llama 3.
Los mejores cursos LLM
Curso
Curso
blog
Ryan Ong
8 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Aashi Dutt


