
Curso
Building AI Agents with Google ADK
1 h
6.5K
O GLM 4.7 Flash é um recém-lançado modelo de linguagem grande de peso aberto que chamou bastante atenção porque pode ser executado localmente e ainda assim oferecer um ótimo desempenho para codificação, raciocínio e fluxos de trabalho do tipo agente.
Diferente de muitos modelos modernos que dependem de APIs pagas ou infraestrutura hospedada na nuvem, o GLM 4.7 Flash pode ser executado inteiramente em hardware local usando estruturas de inferência leves. Isso torna essa opção atraente para desenvolvedores que desejam controle total sobre seus modelos, uso offline, custos previsíveis e iteração rápida durante o desenvolvimento.
Com a configuração e quantização certas, o modelo consegue atingir altas velocidades de geração de tokens em GPUs de consumo, mantendo uma qualidade de raciocínio útil.
Neste tutorial, vou te mostrar como configurar o ambiente do sistema necessário para rodar o GLM 4.7 Flash localmente usando o llama.cpp. O foco é manter a configuração simples, limpa e fácil de reproduzir. Vamos baixar o modelo, compilar e configurar o llama.cpp e, em seguida, testar o modelo usando um aplicativo web e um servidor de inferência baseado em API.
Mais adiante no tutorial, vamos juntar o servidor local llama.cpp com um agente de codificação de IA, permitindo a geração automática de código, execução e fluxos de trabalho de teste.
Antes de rodar o GLM 4.7 Flash localmente, certifique-se de que seu sistema atenda aos seguintes requisitos.
Para precisão total ou quantização de bits superior:
Para 4 modelos quantizados de 4 bits
A quantização do modelo de rede neural de base ( Q4_K_XL ) reduz bastante o uso de memória, mantendo um bom desempenho de raciocínio e codificação, o que o torna ideal para GPUs como RTX 3090, RTX 4080 e RTX 4090. Essa variante é ideal para quem quer um alto rendimento de tokens sem usar pesos de precisão total.
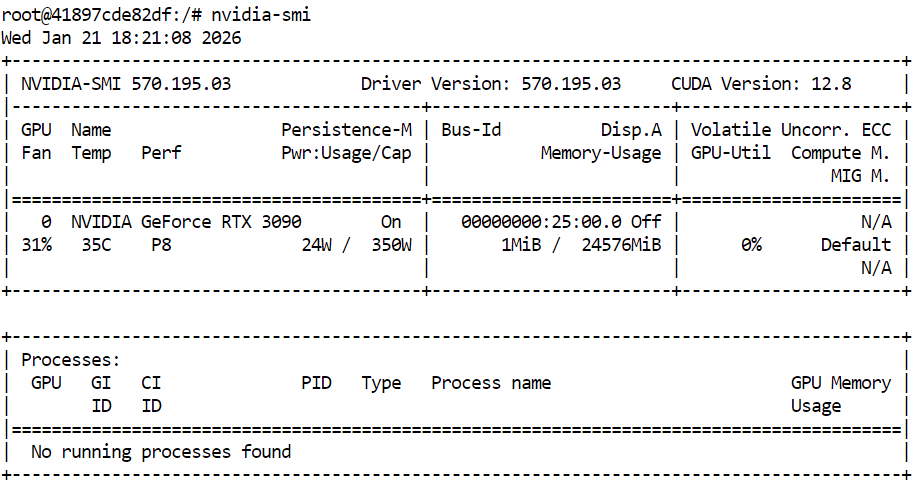
Antes de compilar o llama.cpp e rodar o GLM 4.7 Flash, dá uma olhada se a sua GPU NVIDIA e os drivers estão instalados direitinho. Isso garante que o CUDA esteja disponível e que o sistema possa executar inferências aceleradas por GPU.
nvidia-smiA saída mostra uma RTX 3090 com CUDA versão 12.8 e 24 GB de memória GPU disponível, o que é suficiente para rodar o GLM 4.7 Flash e suas variantes quantizadas.
Depois, abra um terminal e defina um espaço de trabalho limpo e uma estrutura de diretórios. Isso mantém o código-fonte, os arquivos de modelo e os dados de cache organizados, ajuda a evitar problemas de permissão e facilita a reprodução da configuração.
export WORKDIR="/workspace"
export LLAMA_DIR="$WORKDIR/llama.cpp"
export MODEL_DIR="$WORKDIR/models/unsloth/GLM-4.7-Flash-GGUF"Crie o diretório onde os arquivos do modelo serão armazenados e configure os locais de cache do Hugging Face dentro do espaço de trabalho, em vez do diretório home. Isso melhora o desempenho do download e evita avisos desnecessários.
mkdir -p "$MODEL_DIR"
export HF_HOME="$WORKDIR/.cache/huggingface"
export HUGGINGFACE_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"
export HF_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"Defina variáveis de ambiente adicionais para suprimir avisos de links simbólicos e ativar downloads de alto desempenho.
export HF_HUB_DISABLE_SYMLINKS_WARNING=1
export HF_XET_HIGH_PERFORMANCE=1Por fim, instale as dependências de sistema necessárias para compilar o llama.cpp e gerenciar downloads.
sudo apt-get update
sudo apt-get install -y \
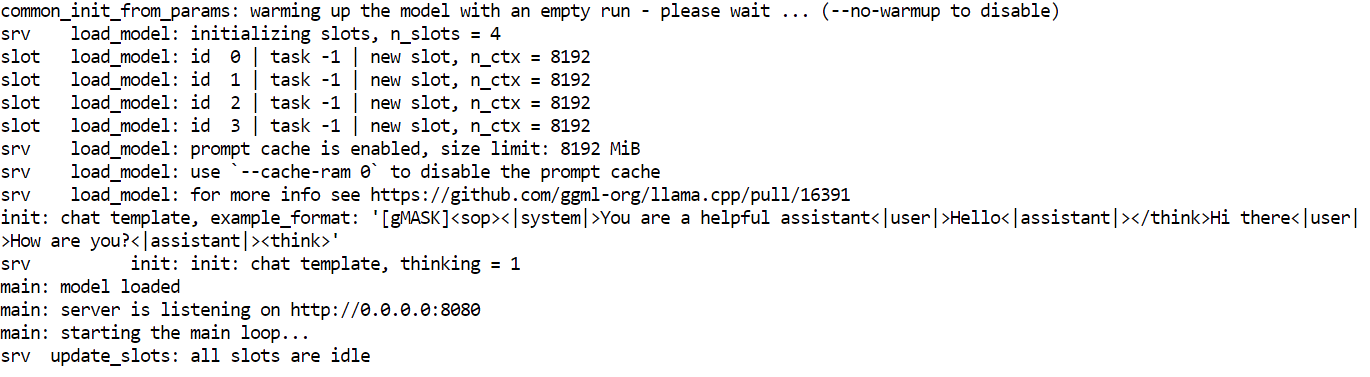
build-essential cmake git curl libcurl4-openssl-devNeste momento, o ambiente do sistema está pronto. A próxima seção vai focar em clonar e compilar o llama.cpp com o suporte CUDA ativado.
Com o ambiente pronto, o próximo passo é instalar o llama.cpp e compilá-lo com o suporte CUDA ativado. Isso permite que o GLM 4.7 Flash funcione bem na GPU.
No terminal, vá até o seu espaço de trabalho. Depois, execute o seguinte comando para clonar o repositório oficial llama.cpp.
git clone https://github.com/ggml-org/llama.cpp "$LLAMA_DIR"Depois que o repositório for clonado, os arquivos de origem serão baixados para o diretório da área de trabalho.
Cloning into '/workspace/llama.cpp'...
remote: Enumerating objects: 76714, done.
remote: Counting objects: 100% (238/238), done.
remote: Compressing objects: 100% (157/157), done.
remote: Total 76714 (delta 172), reused 81 (delta 81), pack-reused 76476 (from 3)
Receiving objects: 100% (76714/76714), 282.23 MiB | 13.11 MiB/s, done.
Resolving deltas: 100% (55422/55422), done.
Updating files: 100% (2145/2145), done.Depois, configura a compilação usando o CMake e ativa explicitamente o suporte a CUDA. Essa etapa prepara o sistema de compilação para compilar binários acelerados por GPU.
cmake "$LLAMA_DIR" -B "$LLAMA_DIR/build" \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ONDepois que a configuração estiver pronta, compile os binários necessários do llama.cpp. Esse comando compila as principais ferramentas de inferência, incluindo a interface de linha de comando e o servidor de inferência.
cmake --build "$LLAMA_DIR/build" --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-splitDepois que a compilação terminar, copie os binários compilados para o diretório principal llama.cpp para facilitar o acesso.
cp "$LLAMA_DIR/build/bin/llama-"* "$LLAMA_DIR/"Por fim, veja se o llama.cpp foi compilado direitinho e se o CUDA foi detectado, rodando o comando de ajuda do servidor de inferência.
"$LLAMA_DIR/llama-server" --help >/dev/null && echo "✔ llama.cpp built"Se o suporte CUDA estiver habilitado corretamente, a saída vai confirmar que um dispositivo CUDA foi detectado, incluindo o modelo da GPU e a capacidade de computação.
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
✔ llama.cpp builtCom o llama.cpp compilado e o suporte CUDA verificado, o próximo passo é baixar o modelo GLM 4.7 Flash. Neste tutorial, a gente usa o Hugging Face Hub com suporte Xet pra fazer downloads rápidos e confiáveis de arquivos de modelos grandes.
No mesmo terminal, digite os seguintes comandos para instalar os pacotes Python necessários para downloads de modelos de alto desempenho.
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferDepois, execute o seguinte script Python no terminal para baixar a variante do modelo quantizado de 4 bits. Esse script usa os caminhos do espaço de trabalho que definimos antes e baixa só o arquivo GGUF que precisamos.
python - <<'PY'
import os
from huggingface_hub import snapshot_download
model_dir = os.environ["MODEL_DIR"]
snapshot_download(
repo_id="unsloth/GLM-4.7-Flash-GGUF",
local_dir=model_dir,
allow_patterns=["*UD-Q4_K_XL*"],
)
print("✔ Download complete:", model_dir)
PYQuando o download terminar, você deve ver uma mensagem confirmando que o arquivo do modelo foi baixado com sucesso, com um tamanho total de aproximadamente 17,5 GB.
Fetching 1 files: 100%|███████████████████████████████████████████████████████████████████████████████████| 1/1 [00:52<00:00, 52.80s/it]
Download complete: 100%|████████████████████████████████████████████████████████████████████████████| 17.5G/17.5G [00:52<00:00, 480MB/s]✔ Download complete: /workspace/models/unsloth/GLM-4.7-Flash-GGUFPor fim, dá uma olhada se o arquivo do modelo tá no diretório de destino.
ls -lh "$MODEL_DIR"Você deve ver o arquivo GLM-4.7-Flash-UD-Q4_K_XL.gguf listado, confirmando que o modelo está pronto para inferência.
total 17G
-rw-rw-rw- 1 root root 17G Jan 21 18:46 GLM-4.7-Flash-UD-Q4_K_XL.ggufCom o modelo baixado e o llama.cpp compilado com suporte a CUDA, o próximo passo é iniciar o servidor de inferência. Isso vai expor o GLM 4.7 Flash como uma API local que pode ser usada por interfaces de usuário, scripts e agentes de codificação de IA.
Use a mesma sessão de terminal e área de trabalho que você configurou nas seções anteriores.
Primeiro, localize o arquivo do modelo GGUF baixado e salve seu caminho em uma variável de ambiente.
export MODEL_FILE="$(ls "$MODEL_DIR"/*.gguf | grep -i UD-Q4_K_XL | head -n 1)"Depois, dá o start no servidor de inferência llama.cpp usando o comando a seguir. Essa configuração é otimizada para uma RTX 3090 e equilibra a taxa de transferência, a latência e o comprimento do contexto.
$LLAMA_DIR/llama-server \
--model "$MODEL_FILE" \
--alias "GLM-4.7-Flash" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 16384 \
--temp 0.7 \
--top-p 1 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256--model carrega o arquivo do modelo GLM 4.7 Flash GGUF selecionado para inferência.--alias atribui um nome de modelo legível que aparece nas respostas da API e nos registros.--threads usa 32 threads da CPU para dar suporte à tokenização, programação e tratamento de solicitações em um sistema de núcleo alto.--host vincula o servidor a todas as interfaces de rede para que ele possa ser acessado localmente ou a partir de outras máquinas na rede.--ctx-size define uma janela de contexto grande que equilibra o suporte a prompts longos com o uso da memória da GPU.--temp usa um pouco de aleatoriedade pra melhorar a qualidade da resposta sem prejudicar a estabilidade do raciocínio.--top-p desativa a filtragem do núcleo para permitir a distribuição completa do token durante a geração.--port 8080 exibe o servidor de inferência em uma porta de desenvolvimento local padrão.--fit permite o ajuste automático da memória para maximizar a utilização da GPU sem ultrapassar os limites da VRAM.--prio define um nível de prioridade equilibrado para cargas de trabalho de inferência em solicitações simultâneas.--jinja Permite o suporte a modelos Jinja para prompts estruturados e fluxos de trabalho no estilo agente.--flash-attn ativa automaticamente o Flash Attention quando compatível com a GPU para aumentar a taxa de transferência.--batch-size permite o processamento de grandes lotes para melhorar o rendimento de tokens na RTX 3090.--ubatch-size divide grandes lotes em micro lotes menores para controlar a pressão da memória e a latência.Assim que o servidor começar, ele vai carregar o modelo na memória da GPU e começar a ficar de olho nas solicitações na porta 8080. Neste momento, o GLM 4.7 Flash está rodando localmente e pode ser acessado por meio de pontos finais HTTP para bate-papo, conclusão e fluxos de trabalho baseados em agentes.
Com o servidor de inferência funcionando, agora você pode testar o GLM 4.7 Flash usando várias interfaces, incluindo a interface de usuário da web integrada, solicitações HTTP diretas e o SDK Python compatível com OpenAI.
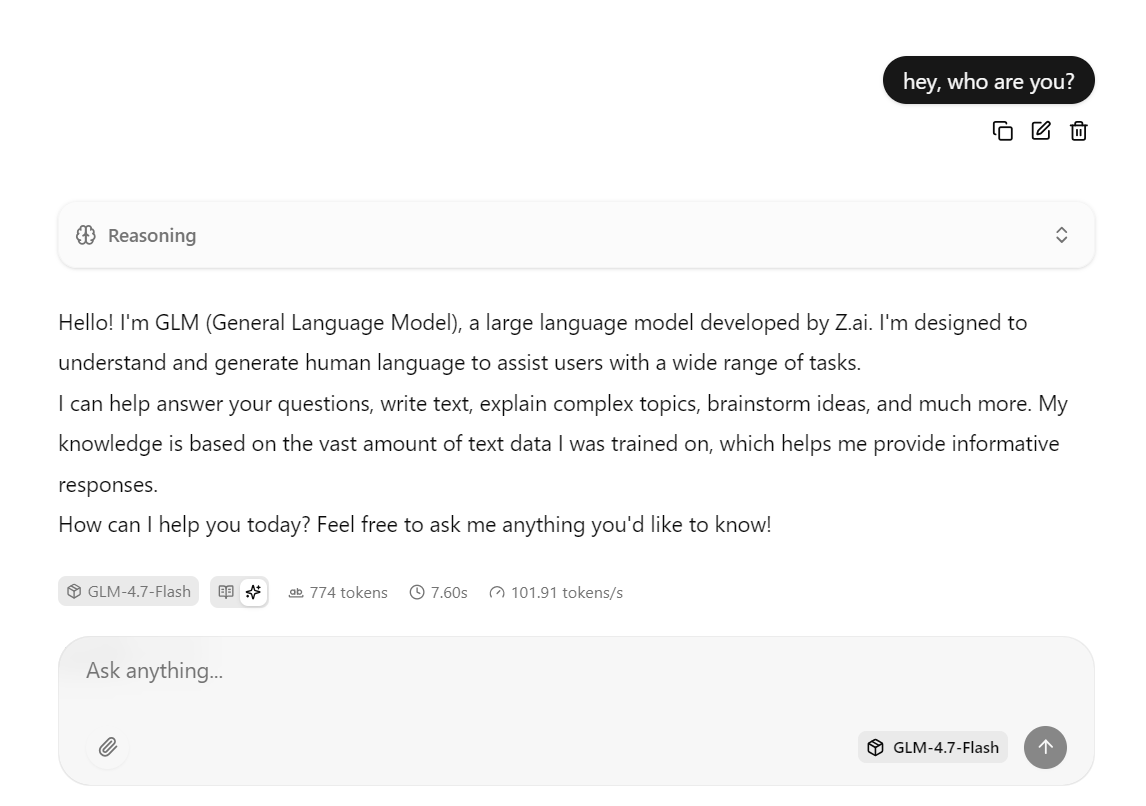
A interface web llama.cpp tá disponível em: http://0.0.0.0:8080
Copie este URL e abra-o no seu navegador da web para acessar uma interface de chat simples parecida com o chatGPT.

Digite uma solicitação e o modelo começará a gerar uma resposta imediatamente.
Essa configuração é otimizada para velocidade, rodando o modelo na RTX 3090 com CUDA ativado, usando Flash Attention quando disponível e usando configurações de processamento em lote ajustadas para alto rendimento.
Na prática, essa configuração pode chegar a cerca de 100 tokens por segundo para respostas curtas a médias.
Você também pode interagir com o mesmo servidor usando o comando curl. Abra uma nova janela do terminal e execute a seguinte solicitação para enviar um aviso de conclusão do chat.
curl -N http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer local" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{ "role": "user", "content": "Write a short bash script that prints numbers 1 to 5." }
]
}'Você também pode testar o modelo usando Python instalando o OpenAI Python SDK.
pip -q install openaiNeste exemplo em Python, o cliente OpenAI está configurado para enviar solicitações ao servidor de inferência llama.cpp em execução localmente.
O base_url aponta para o endpoint da API local, e o campo da chave da API é necessário para o SDK, mas pode ser definido com qualquer valor de espaço reservado, já que a autenticação é feita localmente.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="local"
)O cliente então manda uma solicitação de conclusão do chat para o GLM 4.7 Flash usando o alias do modelo definido quando o servidor de inferência foi iniciado. A solicitação é fornecida no formato padrão de chat, e a resposta é retornada como um objeto estruturado.
r = client.chat.completions.create(
model="GLM-4.7-Flash",
messages=[{"role": "user", "content": "Build me a Simple API server using FastAPI"}]
)
print(r.choices[0].message.content)Em alguns segundos, o modelo vai te dar uma resposta completa, com exemplos de código e explicações.

OpenCode é um agente de codificação de IA de código aberto feito pra rodar localmente, dando suporte a fluxos de trabalho de agentes, como geração de código, edição de arquivos, execução de comandos e resolução iterativa de problemas.
Diferente dos assistentes de codificação baseados em nuvem, o OpenCode pode ser conectado a servidores de inferência auto-hospedados, permitindo que você crie uma configuração de codificação de IA totalmente local e gratuita.
Neste tutorial, o OpenCode está configurado para usar o servidor local llama.cpp executando o GLM 4.7 Flash por meio de uma API compatível com OpenAI.
Pra começar, usa a mesma sessão do terminal e instala o OpenCode usando o script de instalação oficial.
curl -fsSL https://opencode.ai/install | bash Depois de instalar, atualize seu PATH para que o opencode esteja disponível no terminal.
Depois de instalar, atualize seu PATH para que o opencode esteja disponível no terminal.
export PATH="$HOME/.local/bin:$PATH"Abra uma nova janela do terminal e veja se o OpenCode está instalado direitinho.
opencode --versionVocê deve ver um número de versão parecido com o seguinte.
1.1.29Depois, crie o diretório de configuração do OpenCode. Depois, crie o arquivo de configuração OpenCode e defina llama.cpp como o provedor. Essa configuração diz ao OpenCode para mandar todas as solicitações para o servidor de inferência que tá rodando localmente e usar o modelo GLM 4.7 Flash.
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llamacpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama.cpp (local)",
"options": {
"baseURL": "http://127.0.0.1:8080/v1"
},
"models": {
"GLM-4.7-Flash": {
"name": "GLM-4.7-Flash (UD-Q4_K_XL)"
}
}
}
},
"model": "GLM-4.7-Flash"
}
EOFPor fim, autentique o OpenCode. Essa etapa é necessária para a ferramenta, mas como o servidor de inferência é local, a chave da API pode ser qualquer valor provisório.
opencode auth loginQuando for solicitado, use os seguintes valores.
Neste ponto, o OpenCode está totalmente configurado para usar o GLM 4.7 Flash através do servidor local llama.cpp.
Com o OpenCode configurado e conectado ao servidor local llama.cpp, agora você pode usar o GLM 4.7 Flash como um agente de codificação de IA totalmente automatizado.
Comece criando um novo diretório de projeto e navegando até ele.
mkdir -p /workspace/project
cd /workspace/projectDepois, abra o OpenCode no mesmo terminal.
opencodeQuando o OpenCode começar, aperte a tecla Tab para mudar para o modo Plano. Nesse modo, descreva o que você quer construir.
Por exemplo, digite um prompt pedindo ao OpenCode para criar uma API simples com machine learning usando FastAPI. O OpenCode vai planejar automaticamente o projeto, gerar o código, rodar o servidor API e testar a implementação.
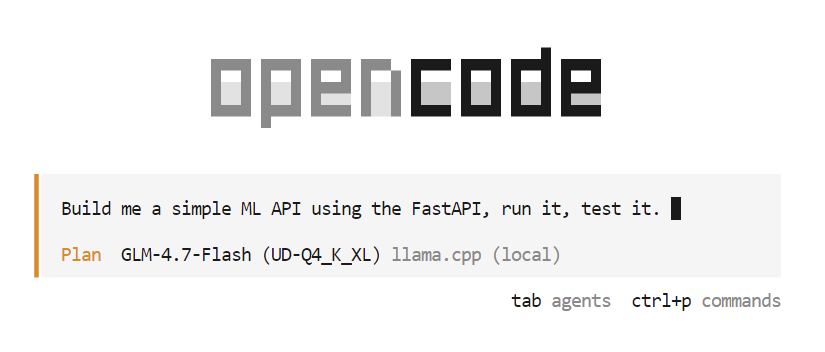
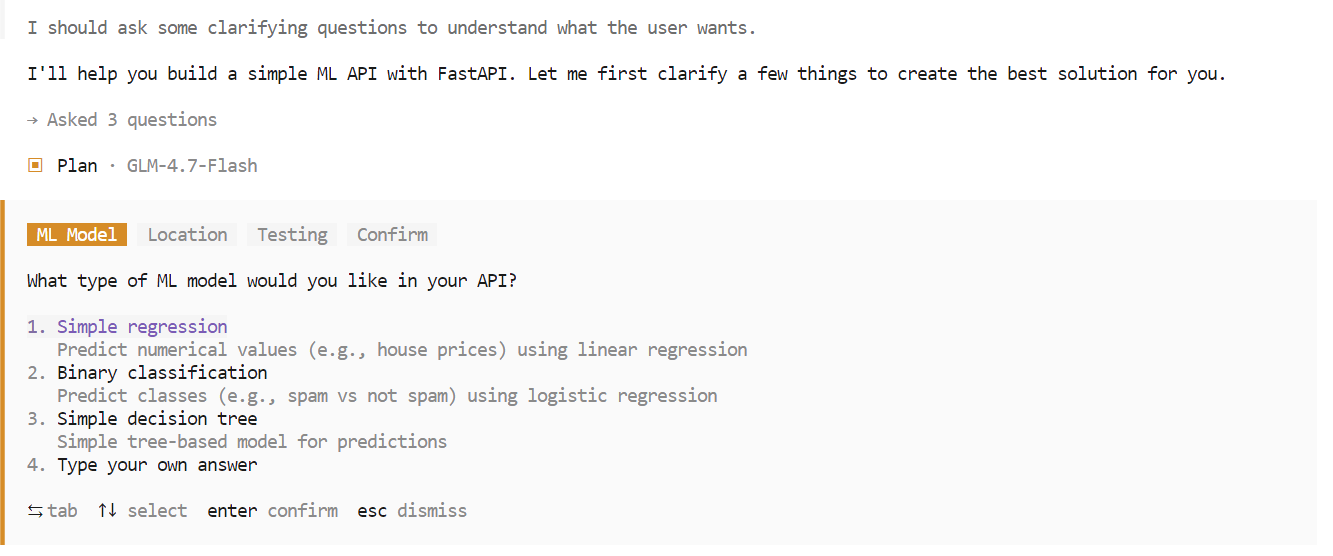
Durante a fase de planejamento, a OpenCode pode fazer perguntas adicionais para esclarecer requisitos como escolhas de estrutura, pontos finais ou estrutura do projeto. Escolha as opções que você preferir e confirme para continuar.
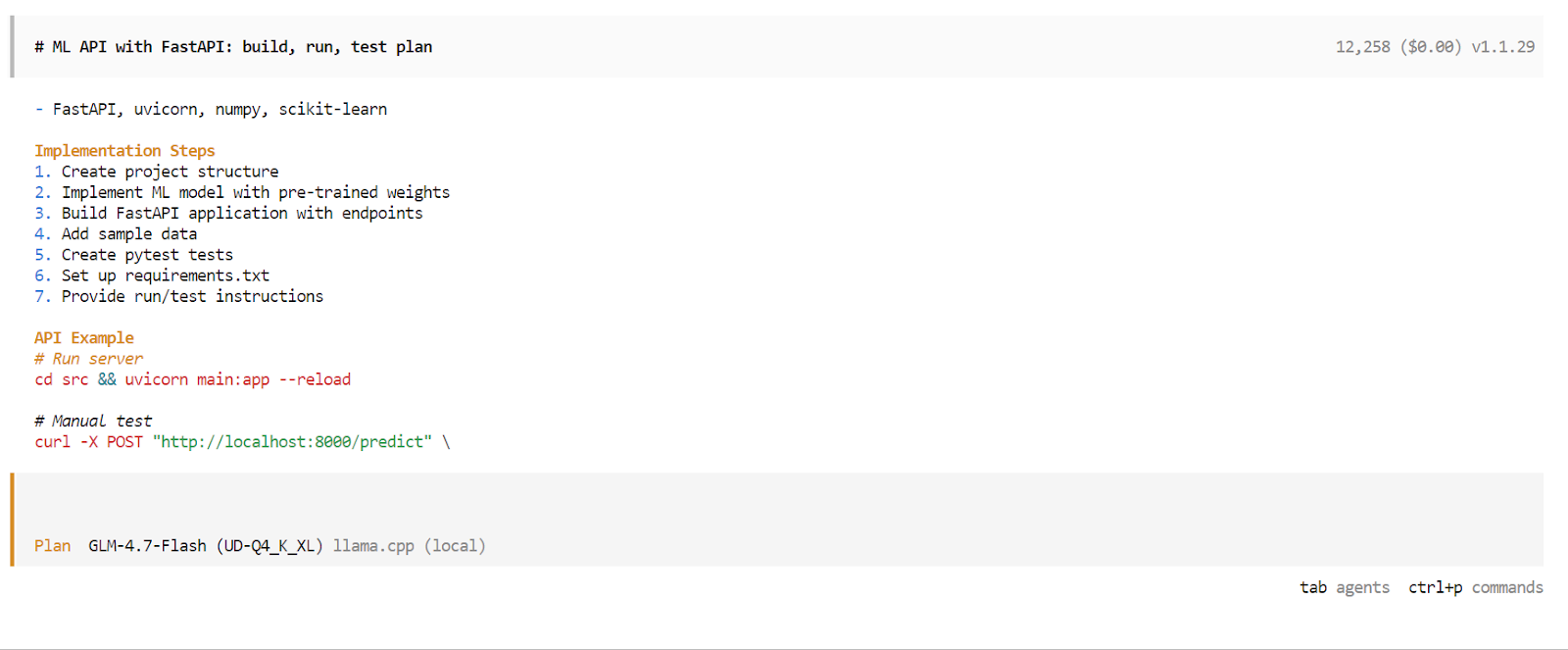
Depois que a fase de planejamento estiver pronta, a OpenCode vai apresentar um plano detalhado de execução. Dá uma olhada no plano e aprova se estiver de acordo com o que você esperava. Depois, apertea tecla Tab novamente para mudar do modo Plan para o modo Build.
No modo Build, o OpenCode cria uma lista de tarefas estruturada e faz cada etapa uma por uma. Isso inclui gerar arquivos, escrever código, instalar dependências, rodar o servidor e fazer testes. Você pode ver cada tarefa sendo concluída em tempo real.
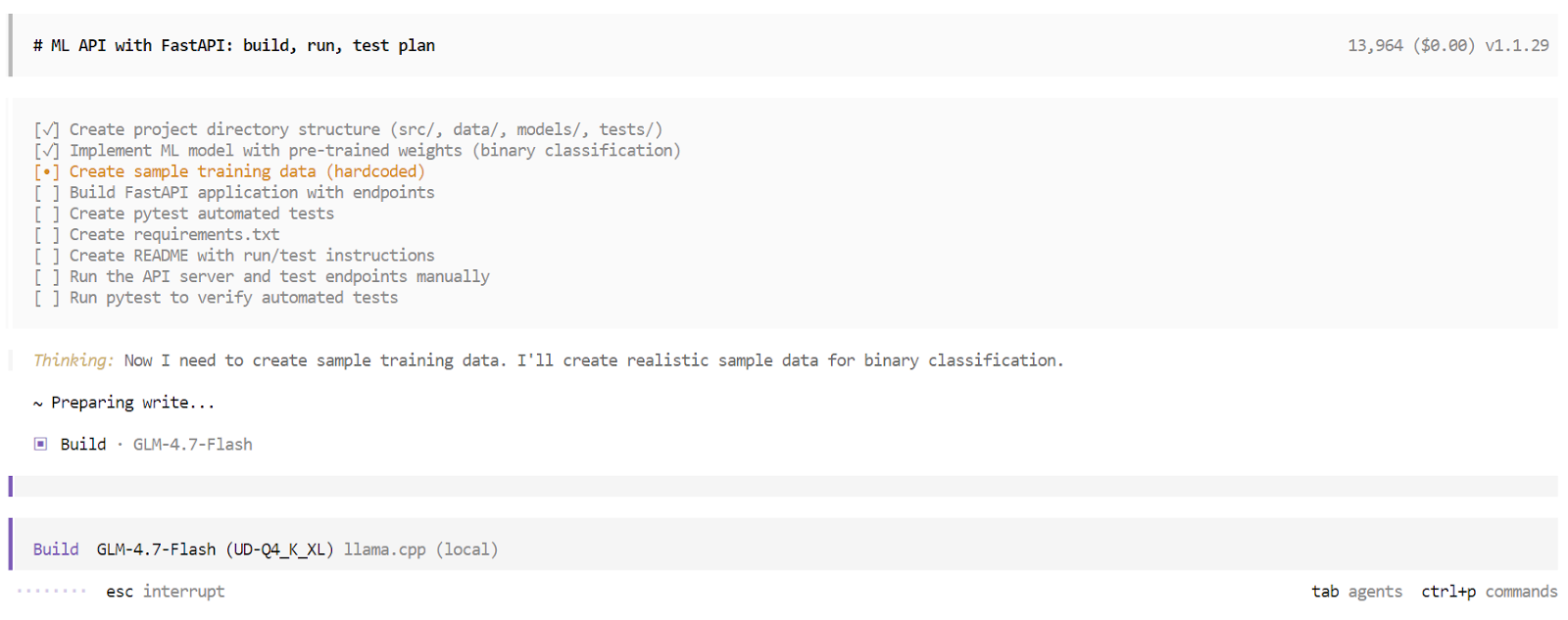
Quando o processo de compilação terminar, o OpenCode vai te dar uma visão geral completa do aplicativo. Isso inclui instruções de uso, exemplos de solicitações e os resultados de testes automáticos. Neste ponto, você tem um aplicativo totalmente funcional, criado e validado por um agente de codificação de IA local, rodando inteiramente na sua máquina.
O GLM 4.7 Flash é um grande passo em direção a agentes de codificação de IA totalmente locais. A capacidade de executar um modelo de raciocínio rápido e eficiente inteiramente em hardware local e integrá-lo a ferramentas como o OpenCode é uma mudança significativa em relação aos fluxos de trabalho dependentes da nuvem.
Dito isso, o GLM 4.7 Flash ainda tem algumas limitações. Embora tenha um bom desempenho em tarefas de pequeno a médio porte, ele pode ter dificuldades com fluxos de trabalho de codificação mais complexos e com várias etapas. O contexto pode ficar cheio rapidinho, a execução da ferramenta pode falhar de vez em quando e, em alguns casos, o agente pode parar no meio do processo, precisando de uma nova sessão para continuar.
Essas questões são esperadas para um modelo MoE leve, otimizado para velocidade em vez de profundidade máxima de raciocínio.
Em termos de capacidade bruta, o GLM 4.7 Flash não está no mesmo nível do modelo GLM 4.7 completo, que tem um desempenho mais próximo de modelos como o Claude 4.5 Sonnet. A troca é clara. O GLM 4.7 Flash prioriza a velocidade, a eficiência e a usabilidade local em detrimento da capacidade máxima de raciocínio.
Trabalhar neste tutorial e ajustar o servidor de inferência foi uma experiência valiosa. Usar variantes de maior precisão e aumentar a janela de contexto pode melhorar a confiabilidade da codificação, mas para conseguir os melhores resultados é preciso fazer testes cuidadosos com parâmetros como temperatura, top p, tamanhos de lote e comprimento do contexto. Chegar a uma configuração ideal é um processo que dá trabalho.
No geral, o GLM 4.7 Flash é uma opção prática e interessante para desenvolvedores que querem agentes de codificação de IA rápidos, locais e gratuitos hoje, com espaço claro para melhorias à medida que as ferramentas e os modelos continuam a evoluir.
Cursos mais populares do DataCamp
Curso
Curso
Curso