
Curso
Creación de agentes de IA con Google ADK
1 h
6.5K
GLM 4.7 Flash es una recién lanzado que ha suscitado un gran interés porque puede ejecutarse localmente y, al mismo tiempo, ofrece un gran rendimiento para la codificación, el razonamiento y los flujos de trabajo de tipo agente.
A diferencia de muchos modelos modernos que dependen de API de pago o de infraestructuras alojadas en la nube, GLM 4.7 Flash se puede ejecutar íntegramente en hardware local utilizando marcos de inferencia ligeros. Esto lo convierte en una opción atractiva para los programadores que desean tener un control total sobre sus modelos, uso sin conexión, costes predecibles y una rápida iteración durante el desarrollo.
Con la configuración y cuantificación adecuadas, el modelo puede alcanzar altas velocidades de generación de tokens en GPU de consumo, al tiempo que mantiene una calidad de razonamiento útil.
En este tutorial, te explicaré cómo configurar el entorno del sistema necesario para ejecutar GLM 4.7 Flash localmente utilizando llama.cpp. El objetivo es mantener una configuración sencilla, limpia y reproducible. Descargaremos el modelo, compilaremos y configuraremos llama.cpp, y luego probaremos el modelo utilizando tanto una aplicación web como un servidor de inferencia basado en API.
Más adelante en el tutorial, integraremos el servidor local llama.cpp con un agente de codificación de IA, lo que permitirá la generación automática de código, la ejecución y los flujos de trabajo de prueba.
Antes de ejecutar GLM 4.7 Flash localmente, asegúrate de que tu sistema cumple los siguientes requisitos.
Para una precisión total o una cuantificación de bits superior:
Para el modelo cuantificado de 4 bits
La cuantificación « Q4_K_XL » reduce significativamente el uso de memoria al tiempo que conserva un alto rendimiento de razonamiento y codificación, lo que la hace adecuada para GPU como RTX 3090, RTX 4080 y RTX 4090. Esta variante es ideal para usuarios que desean un alto rendimiento de tokens sin ejecutar pesos de precisión completa.
Antes de compilar llama.cpp y ejecutar GLM 4.7 Flash, comprueba que la GPU y los controladores NVIDIA estén correctamente instalados. Esto garantiza que CUDA esté disponible y que el sistema pueda ejecutar inferencias aceleradas por GPU.
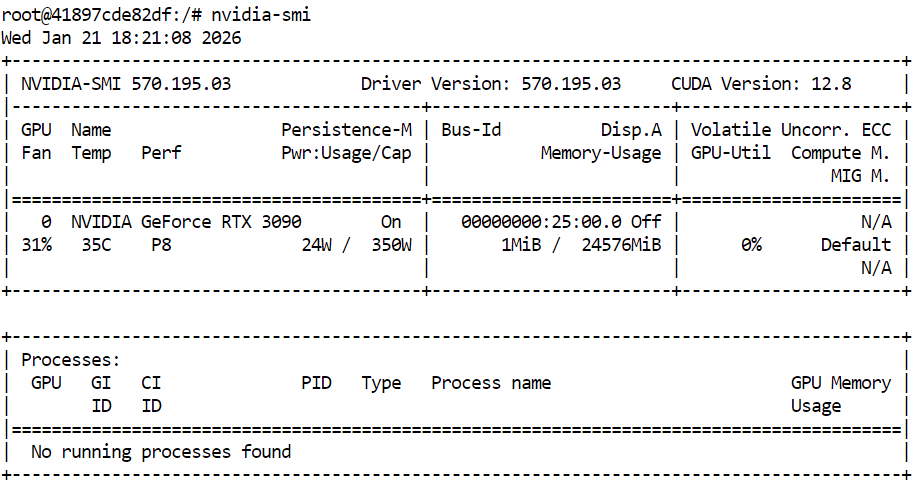
nvidia-smiEl resultado muestra una RTX 3090 con la versión 12.8 de CUDA y 24 GB de memoria GPU disponible, lo cual es suficiente para ejecutar GLM 4.7 Flash y sus variantes cuantificadas.
A continuación, abre un terminal y define un espacio de trabajo limpio y una estructura de directorios. Esto mantiene organizados el código fuente, los archivos de modelo y los datos de caché, ayuda a evitar problemas de permisos y facilita la reproducción de la configuración.
export WORKDIR="/workspace"
export LLAMA_DIR="$WORKDIR/llama.cpp"
export MODEL_DIR="$WORKDIR/models/unsloth/GLM-4.7-Flash-GGUF"Crea el directorio donde se almacenarán los archivos del modelo y configura las ubicaciones de la caché de Hugging Face dentro del espacio de trabajo en lugar del directorio de inicio. Esto mejora el rendimiento de la descarga y evita advertencias innecesarias.
mkdir -p "$MODEL_DIR"
export HF_HOME="$WORKDIR/.cache/huggingface"
export HUGGINGFACE_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"
export HF_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"Establece variables de entorno adicionales para suprimir las advertencias de enlaces simbólicos y habilitar descargas de alto rendimiento.
export HF_HUB_DISABLE_SYMLINKS_WARNING=1
export HF_XET_HIGH_PERFORMANCE=1Por último, instala las dependencias del sistema necesarias para compilar llama.cpp y gestionar las descargas.
sudo apt-get update
sudo apt-get install -y \
build-essential cmake git curl libcurl4-openssl-devEn este punto, el entorno del sistema está listo. La siguiente sección se centrará en clonar y compilar llama.cpp con el soporte CUDA habilitado.
Una vez preparado el entorno, el siguiente paso es instalar llama.cpp y compilarlo con el soporte CUDA habilitado. Esto permite que GLM 4.7 Flash se ejecute de manera eficiente en la GPU.
En la terminal, navega hasta tu espacio de trabajo. A continuación, ejecuta el siguiente comando para clonar el repositorio oficial llama.cpp.
git clone https://github.com/ggml-org/llama.cpp "$LLAMA_DIR"Una vez clonado el repositorio, los archivos fuente se descargarán en el directorio del espacio de trabajo.
Cloning into '/workspace/llama.cpp'...
remote: Enumerating objects: 76714, done.
remote: Counting objects: 100% (238/238), done.
remote: Compressing objects: 100% (157/157), done.
remote: Total 76714 (delta 172), reused 81 (delta 81), pack-reused 76476 (from 3)
Receiving objects: 100% (76714/76714), 282.23 MiB | 13.11 MiB/s, done.
Resolving deltas: 100% (55422/55422), done.
Updating files: 100% (2145/2145), done.A continuación, configura la compilación con CMake y habilita explícitamente la compatibilidad con CUDA. Este paso prepara el sistema de compilación para compilar binarios acelerados por GPU.
cmake "$LLAMA_DIR" -B "$LLAMA_DIR/build" \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ONUna vez completada la configuración, compila los binarios llama.cpp necesarios. Este comando compila las herramientas de inferencia principales, incluida la interfaz de línea de comandos y el servidor de inferencia.
cmake --build "$LLAMA_DIR/build" --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-splitUna vez finalizada la compilación, copia los binarios compilados en el directorio principal llama.cpp para facilitar el acceso.
cp "$LLAMA_DIR/build/bin/llama-"* "$LLAMA_DIR/"Por último, comprueba que llama.cpp se ha compilado correctamente y que CUDA se detecta ejecutando el comando de ayuda del servidor de inferencia.
"$LLAMA_DIR/llama-server" --help >/dev/null && echo "✔ llama.cpp built"Si la compatibilidad con CUDA está correctamente habilitada, la salida confirmará que se ha detectado un dispositivo CUDA, incluyendo el modelo de GPU y la capacidad de cálculo.
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
✔ llama.cpp builtUna vez compilado llama.cpp y verificada la compatibilidad con CUDA, el siguiente paso es descargar el modelo Flash GLM 4.7. En este tutorial, utilizamos Hugging Face Hub con soporte Xet para permitir descargas rápidas y fiables de archivos de modelos de gran tamaño.
En la misma terminal, escribe los siguientes comandos para instalar los paquetes Python necesarios para descargas de modelos de alto rendimiento.
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferA continuación, ejecuta el siguiente script de Python en la terminal para descargar la variante del modelo cuantificado de 4 bits. Este script utiliza las rutas del espacio de trabajo definidas anteriormente y descarga solo el archivo GGUF necesario.
python - <<'PY'
import os
from huggingface_hub import snapshot_download
model_dir = os.environ["MODEL_DIR"]
snapshot_download(
repo_id="unsloth/GLM-4.7-Flash-GGUF",
local_dir=model_dir,
allow_patterns=["*UD-Q4_K_XL*"],
)
print("✔ Download complete:", model_dir)
PYUna vez completada la descarga, deberías ver un mensaje que confirma que el archivo del modelo se ha descargado correctamente, con un tamaño total de aproximadamente 17,5 GB.
Fetching 1 files: 100%|███████████████████████████████████████████████████████████████████████████████████| 1/1 [00:52<00:00, 52.80s/it]
Download complete: 100%|████████████████████████████████████████████████████████████████████████████| 17.5G/17.5G [00:52<00:00, 480MB/s]✔ Download complete: /workspace/models/unsloth/GLM-4.7-Flash-GGUFPor último, comprueba que el archivo del modelo se encuentra en el directorio de destino.
ls -lh "$MODEL_DIR"Deberías ver el archivo GLM-4.7-Flash-UD-Q4_K_XL.gguf en la lista, lo que confirma que el modelo está listo para la inferencia.
total 17G
-rw-rw-rw- 1 root root 17G Jan 21 18:46 GLM-4.7-Flash-UD-Q4_K_XL.ggufUna vez descargado el modelo y compilado llama.cpp con compatibilidad con CUDA, el siguiente paso es iniciar el servidor de inferencia. Esto expondrá GLM 4.7 Flash como una API local que puede ser utilizada por interfaces de usuario, scripts y agentes de codificación de IA.
Utiliza la misma sesión de terminal y el mismo espacio de trabajo que has configurado en las secciones anteriores.
En primer lugar, localiza el archivo del modelo GGUF descargado y guarda su ruta en una variable de entorno.
export MODEL_FILE="$(ls "$MODEL_DIR"/*.gguf | grep -i UD-Q4_K_XL | head -n 1)"A continuación, inicia el servidor de inferencia llama.cpp con el siguiente comando. Esta configuración está optimizada para una RTX 3090 y equilibra el rendimiento, la latencia y la longitud del contexto.
$LLAMA_DIR/llama-server \
--model "$MODEL_FILE" \
--alias "GLM-4.7-Flash" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 16384 \
--temp 0.7 \
--top-p 1 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256--model Carga el archivo de modelo GLM 4.7 Flash GGUF seleccionado para la inferencia.--alias asigna un nombre de modelo legible que aparece en las respuestas y registros de la API.--threads Utiliza 32 subprocesos de CPU para admitir la tokenización, la programación y el manejo de solicitudes en un sistema de núcleo alto.--host vincula el servidor a todas las interfaces de red para que se pueda acceder a él localmente o desde otras máquinas de la red.--ctx-size Establece una ventana de contexto grande que equilibra la compatibilidad con indicaciones largas con el uso de memoria de la GPU.--temp aplica una aleatoriedad moderada para mejorar la calidad de la respuesta sin perjudicar la estabilidad del razonamiento.--top-p Desactiva el filtrado del núcleo para permitir la distribución completa de tokens durante la generación.--port 8080 expone el servidor de inferencia en un puerto de desarrollo local estándar.--fit permite el ajuste automático de la memoria para maximizar la utilización de la GPU sin exceder los límites de la VRAM.--prio establece un nivel de prioridad equilibrado para las cargas de trabajo de inferencia en solicitudes simultáneas.--jinja Permite el uso de plantillas Jinja para indicaciones estructuradas y flujos de trabajo de estilo agente.--flash-attn Activa automáticamente Flash Attention cuando es compatible con la GPU para aumentar el rendimiento.--batch-size permite el procesamiento de lotes grandes para mejorar el rendimiento de tokens en la RTX 3090.--ubatch-size Divide los lotes grandes en micro lotes más pequeños para controlar la presión de la memoria y la latencia.Una vez que se inicia el servidor, cargará el modelo en la memoria de la GPU y comenzará a escuchar las solicitudes en el puerto 8080. En este momento, GLM 4.7 Flash se está ejecutando localmente y se puede acceder a él a través de puntos finales HTTP para chat, finalización y flujos de trabajo basados en agentes.
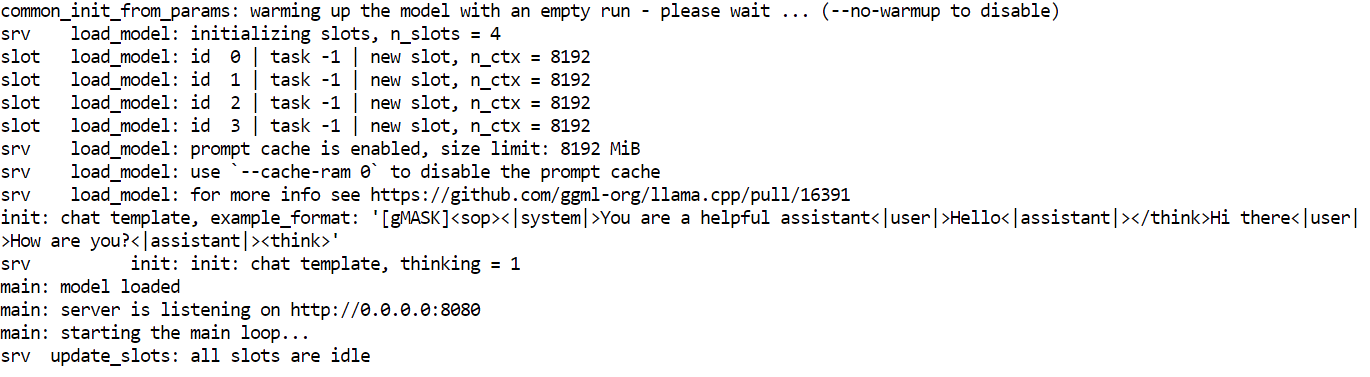
Con el servidor de inferencia en funcionamiento, ahora puedes probar GLM 4.7 Flash utilizando múltiples interfaces, incluyendo la interfaz de usuario web integrada, solicitudes HTTP directas y el SDK de Python compatible con OpenAI.
La interfaz web llama.cpp está disponible en: http://0.0.0.0:8080
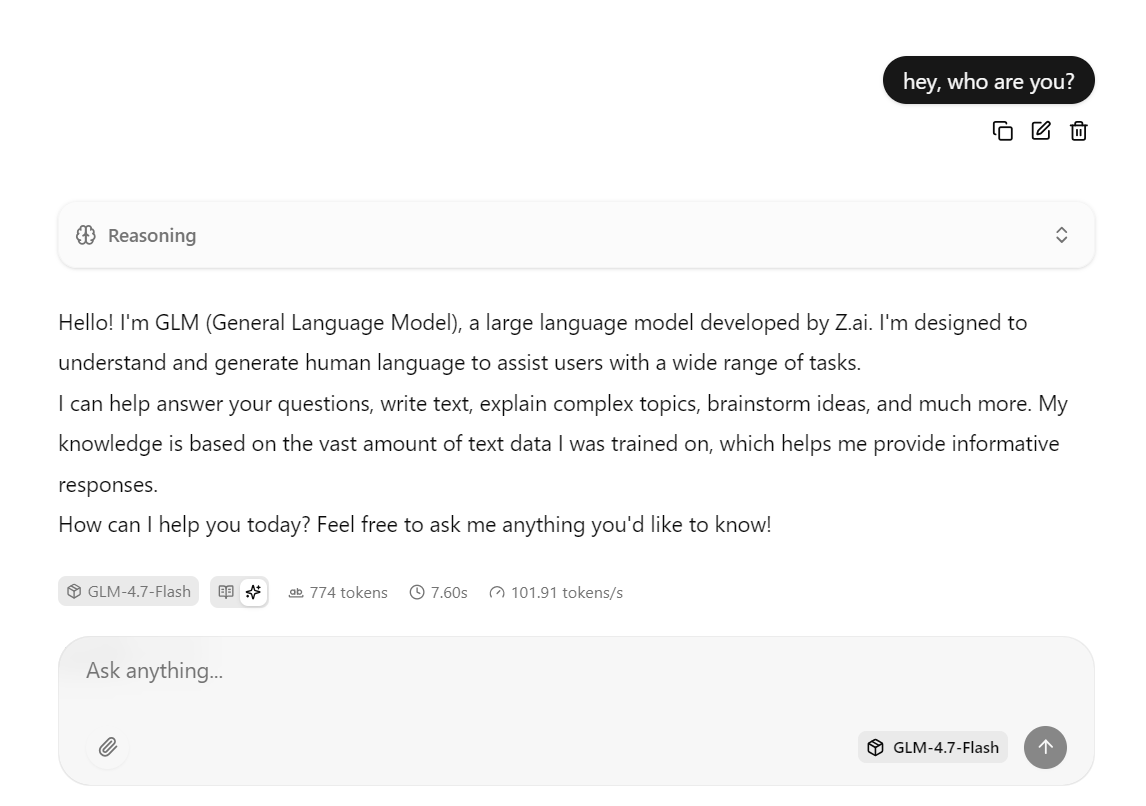
Copia esta URL y ábrela en tu navegador web para acceder a una interfaz de chat sencilla similar a chatGPT.

Introduce una indicación y el modelo comenzará a generar una respuesta inmediatamente.
Esta configuración está optimizada para la velocidad, ya que ejecuta el modelo en la RTX 3090 con CUDA habilitado, utiliza Flash Attention cuando está disponible y emplea ajustes de procesamiento por lotes optimizados para un alto rendimiento.
En la práctica, esta configuración puede alcanzar alrededor de 100 tokens por segundo para respuestas cortas y medianas.
También puedes interactuar con el mismo servidor utilizando el comando « curl ». Abre una nueva ventana de terminal y ejecuta la siguiente solicitud para enviar un mensaje de finalización de chat.
curl -N http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer local" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{ "role": "user", "content": "Write a short bash script that prints numbers 1 to 5." }
]
}'También puedes probar el modelo utilizando Python instalando el SDK de Python de OpenAI.
pip -q install openaiEn este ejemplo de Python, el cliente OpenAI está configurado para enviar solicitudes al servidor de inferencia llama.cpp que se ejecuta localmente.
base_url apunta al punto final de la API local, y el campo de la clave API es obligatorio para el SDK, pero se puede establecer cualquier valor de marcador de posición, ya que la autenticación se gestiona localmente.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="local"
)A continuación, el cliente envía una solicitud de finalización del chat a GLM 4.7 Flash utilizando el alias del modelo definido al iniciar el servidor de inferencia. La solicitud se proporciona en formato de chat estándar y la respuesta se devuelve como un objeto estructurado.
r = client.chat.completions.create(
model="GLM-4.7-Flash",
messages=[{"role": "user", "content": "Build me a Simple API server using FastAPI"}]
)
print(r.choices[0].message.content)En unos segundos, el modelo devolverá una respuesta completa, incluyendo código de ejemplo y explicaciones.

OpenCode es un agente de codificación de IA de código abierto diseñado para ejecutarse localmente y que admite flujos de trabajo de agentes, como la generación de código, la edición de archivos, la ejecución de comandos y la resolución iterativa de problemas.
A diferencia de los asistentes de codificación basados en la nube, OpenCode se puede conectar a servidores de inferencia autohospedados, lo que te permite crear una configuración de codificación de IA totalmente local y gratuita.
En este tutorial, OpenCode está configurado para utilizar el servidor local llama.cpp que ejecuta GLM 4.7 Flash a través de una API compatible con OpenAI.
Para empezar, utiliza la misma sesión de terminal e instala OpenCode con el script de instalación oficial.
curl -fsSL https://opencode.ai/install | bash Después de la instalación, actualiza tu PATH para que el opencode esté disponible en la terminal.
Después de la instalación, actualiza tu PATH para que el opencode esté disponible en la terminal.
export PATH="$HOME/.local/bin:$PATH"Abre una nueva ventana de terminal y comprueba que OpenCode está instalado correctamente.
opencode --versionDeberías ver un número de versión similar al siguiente.
1.1.29A continuación, crea el directorio de configuración de OpenCode. A continuación, crea el archivo de configuración OpenCode y define llama.cpp como proveedor. Esta configuración indica a OpenCode que envíe todas las solicitudes al servidor de inferencia que se ejecuta localmente y utilice el modelo GLM 4.7 Flash.
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llamacpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama.cpp (local)",
"options": {
"baseURL": "http://127.0.0.1:8080/v1"
},
"models": {
"GLM-4.7-Flash": {
"name": "GLM-4.7-Flash (UD-Q4_K_XL)"
}
}
}
},
"model": "GLM-4.7-Flash"
}
EOFPor último, autentica OpenCode. Este paso es necesario para la herramienta, pero dado que el servidor de inferencia es local, la clave API puede ser cualquier valor provisional.
opencode auth loginCuando se te solicite, utiliza los siguientes valores.
En este punto, OpenCode está completamente configurado para utilizar GLM 4.7 Flash a través del servidor local llama.cpp.
Con OpenCode configurado y conectado al servidor local llama.cpp, ahora puedes utilizar GLM 4.7 Flash como un agente de codificación de IA totalmente automatizado.
Comienza creando un nuevo directorio para el proyecto y accede a él.
mkdir -p /workspace/project
cd /workspace/projectA continuación, inicia OpenCode desde el mismo terminal.
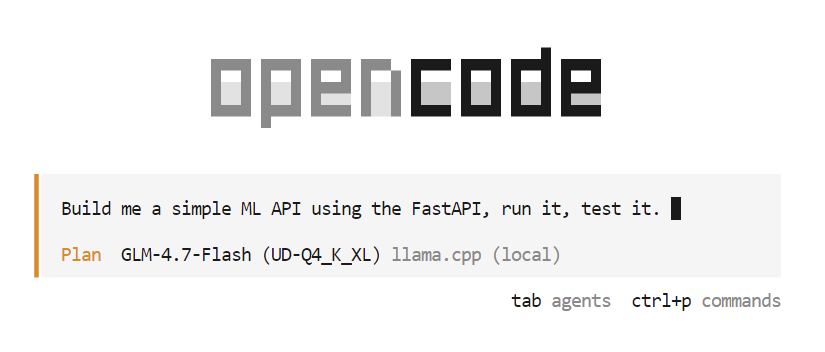
opencodeUna vez que se inicie OpenCode, pulsa la tecla Tab para cambiar al modo Planific. En este modo, describe lo que deseas construir.
Por ejemplo, introduce un comando que solicite a OpenCode que cree una API sencilla basada en machine learning utilizando FastAPI. OpenCode planificará automáticamente el proyecto, generará el código, ejecutará el servidor API y probará la implementación.
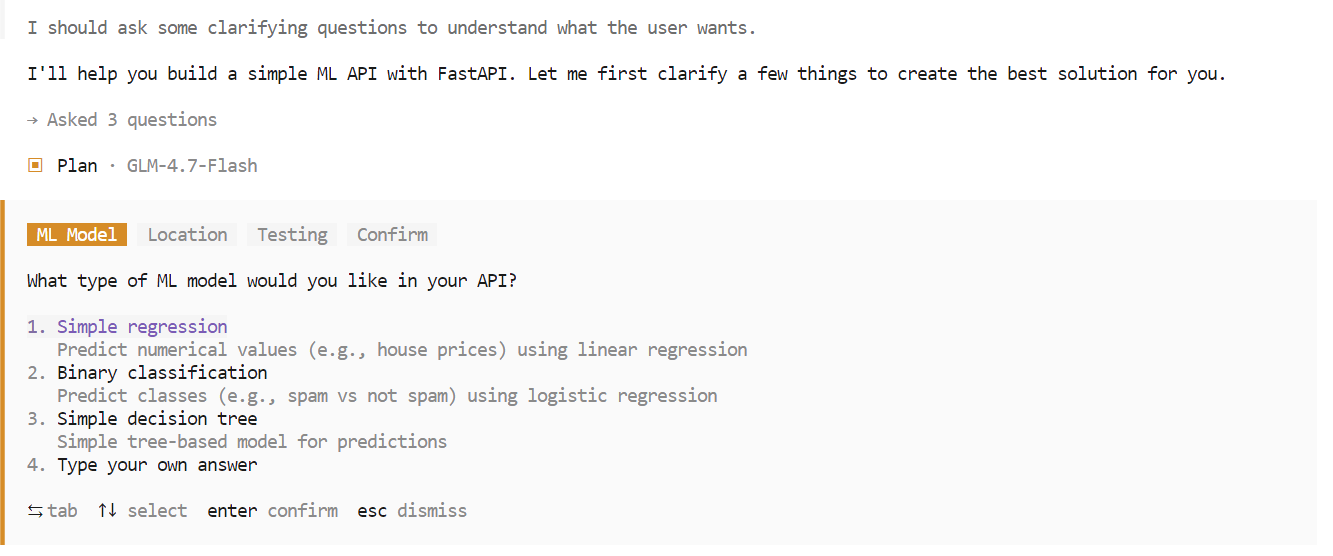
Durante la fase de planificación, OpenCode puede hacer preguntas de seguimiento para aclarar requisitos tales como la elección del marco de trabajo, los puntos finales o la estructura del proyecto. Selecciona las opciones que prefieras y confirma para continuar.
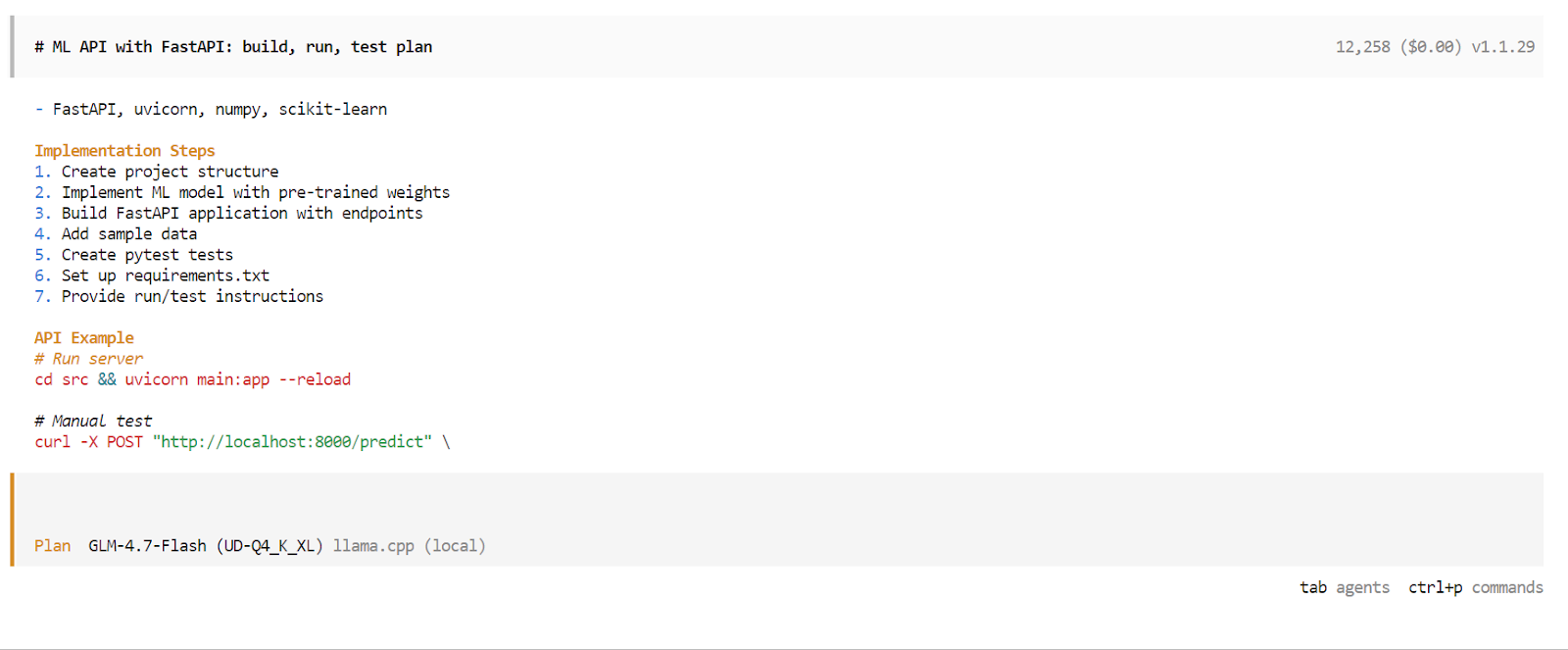
Una vez finalizada la fase de planificación, OpenCode presentará un plan de ejecución detallado. Revisa el plan y apruébalo si cumple con tus expectativas. A continuación, vuelve a pulsarla tecla Tab ( ) para pasar del modo Planificar al modo Crear.
En el modo Build, OpenCode crea una lista de tareas estructurada y ejecuta cada paso de forma secuencial. Esto incluye generar archivos, escribir código, instalar dependencias, ejecutar el servidor y realizar pruebas. Puedes observar cómo se completa cada tarea en tiempo real.
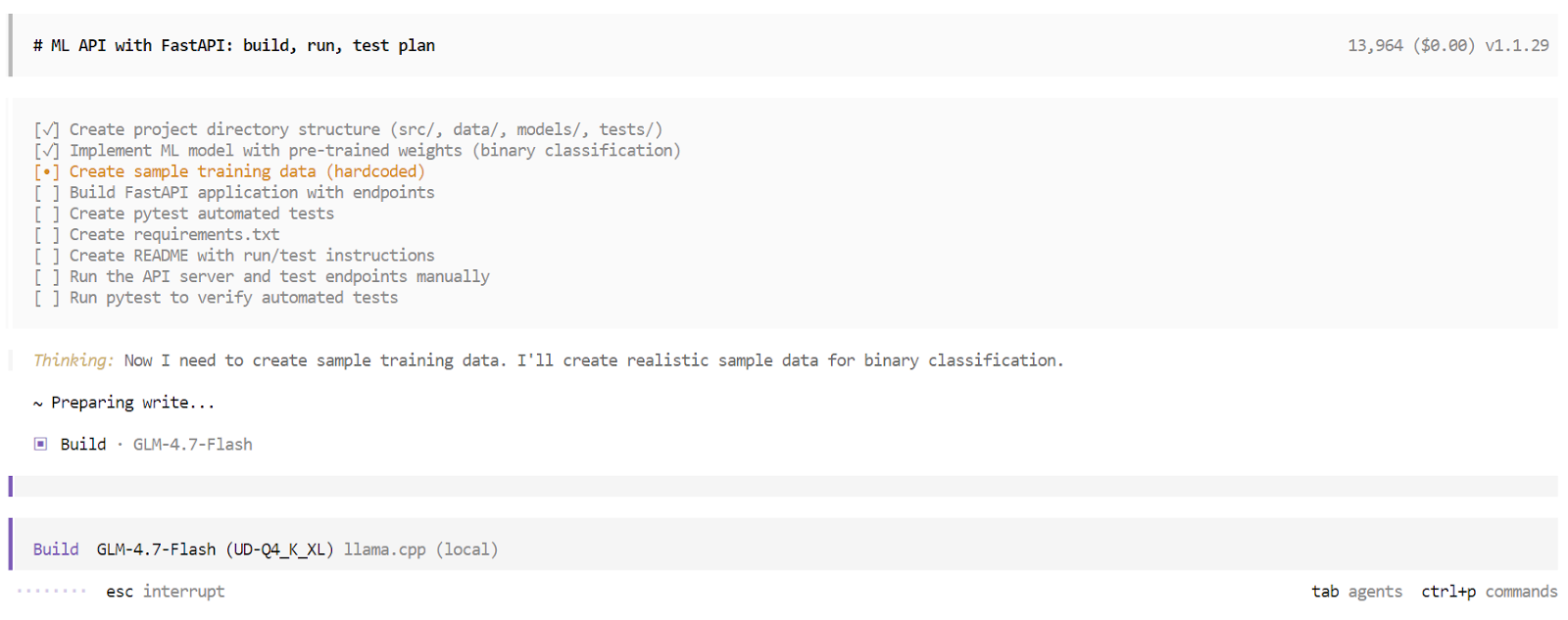
Una vez finalizado el proceso de compilación, OpenCode proporciona una descripción general completa de la aplicación. Esto incluye instrucciones de uso, ejemplos de solicitudes y los resultados de pruebas automatizadas. En este punto, tienes una aplicación totalmente funcional creada y validada por un agente de codificación de IA local que se ejecuta íntegramente en tu máquina.
GLM 4.7 Flash representa un gran paso hacia los agentes de codificación de IA totalmente locales. La capacidad de ejecutar un modelo de razonamiento rápido y eficaz íntegramente en hardware local e integrarlo con herramientas como OpenCode supone un cambio significativo con respecto a los flujos de trabajo dependientes de la nube.
Dicho esto, GLM 4.7 Flash todavía tiene limitaciones. Aunque funciona bien para tareas pequeñas y medianas, puede tener dificultades con flujos de trabajo de codificación más complejos y de varios pasos. El contexto puede llenarse rápidamente, la ejecución de la herramienta puede fallar ocasionalmente y, en algunos casos, el agente puede detenerse a mitad del proceso, lo que requiere una nueva sesión para continuar.
Estos problemas son previsibles en un modelo MoE ligero optimizado para la velocidad en lugar de para la máxima profundidad de razonamiento.
En términos de capacidad bruta, GLM 4.7 Flash no está al mismo nivel que el modelo GLM 4.7 completo, cuyo rendimiento se acerca más al de modelos como Claude 4.5 Sonnet. La compensación es clara. GLM 4.7 Flash prioriza la velocidad, la eficiencia y la usabilidad local por encima de la potencia máxima de razonamiento.
Trabajar en este tutorial y ajustar el servidor de inferencia ha sido una experiencia muy valiosa. Ejecutar variantes de mayor precisión y aumentar la ventana de contexto puede mejorar la fiabilidad de la codificación, pero para obtener los mejores resultados es necesario realizar experimentos minuciosos con parámetros como la temperatura, el top p, los tamaños de los lotes y la longitud del contexto. Alcanzar una configuración óptima es un proceso iterativo.
En general, GLM 4.7 Flash es una opción práctica y atractiva para los programadores que desean contar hoy en día con agentes de codificación de IA rápidos, locales y gratuitos, con un claro margen de mejora a medida que las herramientas y los modelos siguen evolucionando.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan
Tutorial
DataCamp Team
Tutorial
Moez Ali

