
Cours
Créer des agents IA avec Google ADK
1 h
6.5K
GLM 4.7 Flash est une nouveau modèle linguistique ouvert de grande taille qui a suscité un intérêt considérable, car il peut être exécuté localement tout en offrant des performances élevées pour le codage, le raisonnement et les workflows de type agent.
Contrairement à de nombreux modèles modernes qui dépendent d'API payantes ou d'une infrastructure hébergée dans le cloud, GLM 4.7 Flash peut être exécuté entièrement sur du matériel local à l'aide de cadres d'inférence légers. Cela en fait une option intéressante pour les développeurs qui souhaitent bénéficier d'un contrôle total sur leurs modèles, d'une utilisation hors ligne, de coûts prévisibles et d'itérations rapides pendant le développement.
Avec une configuration et une quantification appropriées, le modèle peut atteindre des vitesses de génération de jetons élevées sur les processeurs graphiques grand public tout en conservant une qualité de raisonnement utile.
Dans ce tutoriel, je vais vous expliquer comment configurer l'environnement système nécessaire pour exécuter GLM 4.7 Flash localement à l'aide de llama.cpp. L'accent est mis sur la simplicité, la clarté et la reproductibilité de la configuration. Nous procéderons au téléchargement du modèle, à la compilation et à la configuration de llama.cpp, puis nous testerons le modèle à l'aide d'une application web et d'un serveur d'inférence basé sur une API.
Plus loin dans ce tutoriel, nous intégrerons le serveur local llama.cpp à un agent de codage IA, ce qui permettra d'automatiser les workflows de génération, d'exécution et de test de code.
Avant d'exécuter GLM 4.7 Flash localement, veuillez vous assurer que votre système répond aux exigences suivantes.
Pour une précision totale ou une quantification binaire supérieure :
Pour un modèle quantifié à 4 bits
La quantification de l'Q4_K_XL réduit considérablement l'utilisation de la mémoire tout en conservant des performances de raisonnement et de codage élevées, ce qui la rend adaptée aux GPU tels que RTX 3090, RTX 4080 et RTX 4090. Cette variante est idéale pour les utilisateurs qui souhaitent bénéficier d'un débit élevé sans utiliser des poids de précision maximale.
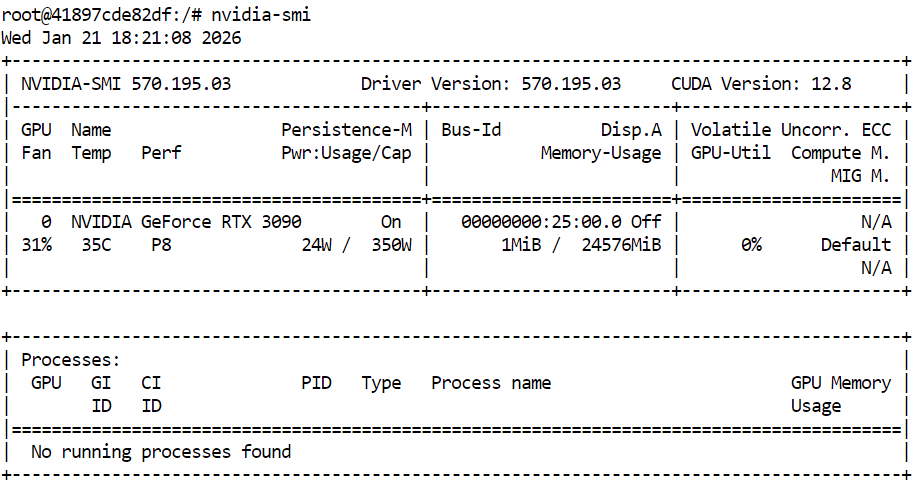
Avant de compiler llama.cpp et d'exécuter GLM 4.7 Flash, veuillez vous assurer que votre GPU NVIDIA et vos pilotes sont correctement installés. Cela garantit que CUDA est disponible et que le système peut exécuter une inférence accélérée par GPU.
nvidia-smiLa sortie affiche une RTX 3090 avec la version CUDA 12.8 et une mémoire GPU de 24 Go disponible, ce qui est suffisant pour exécuter GLM 4.7 Flash et ses variantes quantifiées.
Ensuite, veuillez ouvrir un terminal et définir un espace de travail et une structure de répertoires propres. Cela permet de maintenir l'organisation du code source, des fichiers modèles et des données de cache, contribue à éviter les problèmes d'autorisation et facilite la reproduction de la configuration.
export WORKDIR="/workspace"
export LLAMA_DIR="$WORKDIR/llama.cpp"
export MODEL_DIR="$WORKDIR/models/unsloth/GLM-4.7-Flash-GGUF"Veuillez créer le répertoire dans lequel les fichiers du modèle seront stockés et configurer les emplacements du cache Hugging Face à l'intérieur de l'espace de travail plutôt que dans le répertoire d'accueil. Cela améliore les performances de téléchargement et évite les avertissements inutiles.
mkdir -p "$MODEL_DIR"
export HF_HOME="$WORKDIR/.cache/huggingface"
export HUGGINGFACE_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"
export HF_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"Définissez des variables d'environnement supplémentaires pour supprimer les avertissements relatifs aux liens symboliques et activer les téléchargements haute performance.
export HF_HUB_DISABLE_SYMLINKS_WARNING=1
export HF_XET_HIGH_PERFORMANCE=1Enfin, veuillez installer les dépendances système requises pour compiler llama.cpp et gérer les téléchargements.
sudo apt-get update
sudo apt-get install -y \
build-essential cmake git curl libcurl4-openssl-devÀ ce stade, l'environnement système est prêt. La section suivante se concentrera sur le clonage et la compilation de llama.cpp avec la prise en charge CUDA activée.
Une fois l'environnement préparé, l'étape suivante consiste à installer llama.cpp et de le compiler avec le support CUDA activé. Cela permet à GLM 4.7 Flash de fonctionner efficacement sur le GPU.
Dans le terminal, veuillez accéder à votre espace de travail. Veuillez ensuite exécuter la commande suivante pour cloner le référentiel officiel llama.cpp.
git clone https://github.com/ggml-org/llama.cpp "$LLAMA_DIR"Une fois le référentiel cloné, les fichiers source seront téléchargés dans le répertoire de l'espace de travail.
Cloning into '/workspace/llama.cpp'...
remote: Enumerating objects: 76714, done.
remote: Counting objects: 100% (238/238), done.
remote: Compressing objects: 100% (157/157), done.
remote: Total 76714 (delta 172), reused 81 (delta 81), pack-reused 76476 (from 3)
Receiving objects: 100% (76714/76714), 282.23 MiB | 13.11 MiB/s, done.
Resolving deltas: 100% (55422/55422), done.
Updating files: 100% (2145/2145), done.Ensuite, veuillez configurer la compilation à l'aide de CMake et activer explicitement la prise en charge CUDA. Cette étape prépare le système de compilation à compiler des binaires accélérés par GPU.
cmake "$LLAMA_DIR" -B "$LLAMA_DIR/build" \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ONUne fois la configuration terminée, veuillez compiler les binaires llama.cpp requis. Cette commande compile les principaux outils d'inférence, y compris l'interface de ligne de commande et le serveur d'inférence.
cmake --build "$LLAMA_DIR/build" --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-splitUne fois la compilation terminée, veuillez copier les fichiers binaires compilés dans le répertoire principal llama.cpp afin de faciliter leur accès.
cp "$LLAMA_DIR/build/bin/llama-"* "$LLAMA_DIR/"Enfin, veuillez vérifier que llama.cpp a été correctement compilé et que CUDA est détecté en exécutant la commande d'aide du serveur d'inférence.
"$LLAMA_DIR/llama-server" --help >/dev/null && echo "✔ llama.cpp built"Si la prise en charge CUDA est correctement activée, la sortie confirmera qu'un périphérique CUDA a été détecté, y compris le modèle de GPU et la capacité de calcul.
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
✔ llama.cpp builtUne fois llama.cpp compilé et la prise en charge CUDA vérifiée, l'étape suivante consiste à télécharger le modèle Flash GLM 4.7. Dans ce tutoriel, nous utilisons le Hugging Face Hub avec prise en charge Xet pour permettre des téléchargements rapides et fiables de fichiers de modèles volumineux.
Dans le même terminal, veuillez saisir les commandes suivantes pour installer les paquets Python requis pour les téléchargements de modèles haute performance.
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferEnsuite, veuillez exécuter le script Python suivant dans le terminal pour télécharger la variante du modèle quantifié en 4 bits. Ce script utilise les chemins d'accès à l'espace de travail définis précédemment et télécharge uniquement le fichier GGUF requis.
python - <<'PY'
import os
from huggingface_hub import snapshot_download
model_dir = os.environ["MODEL_DIR"]
snapshot_download(
repo_id="unsloth/GLM-4.7-Flash-GGUF",
local_dir=model_dir,
allow_patterns=["*UD-Q4_K_XL*"],
)
print("✔ Download complete:", model_dir)
PYUne fois le téléchargement terminé, vous devriez voir s'afficher un message confirmant que le fichier du modèle a été récupéré avec succès, avec une taille totale d'environ 17,5 Go.
Fetching 1 files: 100%|███████████████████████████████████████████████████████████████████████████████████| 1/1 [00:52<00:00, 52.80s/it]
Download complete: 100%|████████████████████████████████████████████████████████████████████████████| 17.5G/17.5G [00:52<00:00, 480MB/s]✔ Download complete: /workspace/models/unsloth/GLM-4.7-Flash-GGUFEnfin, veuillez vérifier que le fichier modèle se trouve bien dans le répertoire cible.
ls -lh "$MODEL_DIR"Vous devriez voir le fichier GLM-4.7-Flash-UD-Q4_K_XL.gguf apparaître, confirmant que le modèle est prêt pour l'inférence.
total 17G
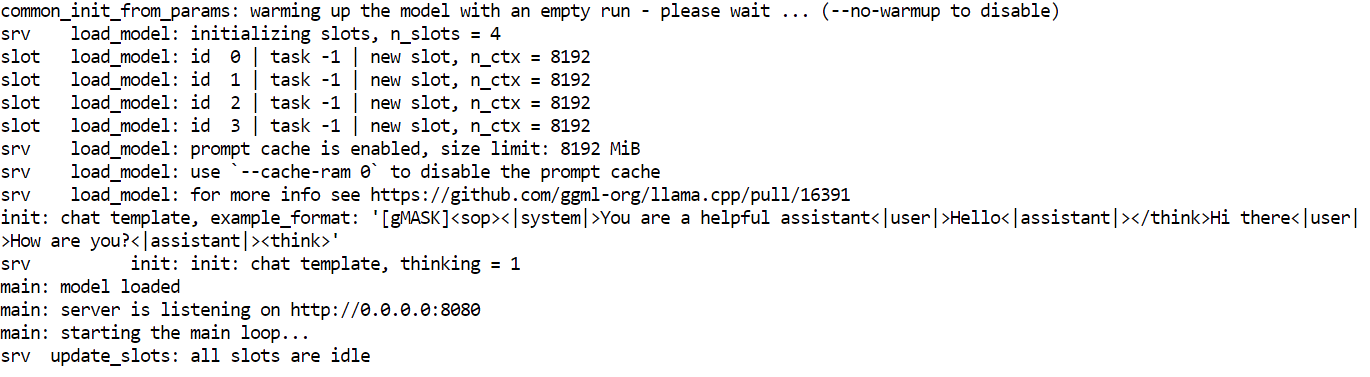
-rw-rw-rw- 1 root root 17G Jan 21 18:46 GLM-4.7-Flash-UD-Q4_K_XL.ggufUne fois le modèle téléchargé et llama.cpp compilé avec le support CUDA, l'étape suivante consiste à lancer le serveur d'inférence. Cela permettra d'exposer GLM 4.7 Flash en tant qu'API locale pouvant être utilisée par les interfaces utilisateur, les scripts et les agents de codage IA.
Veuillez utiliser la même session de terminal et le même espace de travail que ceux configurés dans les sections précédentes.
Tout d'abord, veuillez localiser le fichier de modèle GGUF téléchargé et enregistrer son chemin d'accès dans une variable d'environnement.
export MODEL_FILE="$(ls "$MODEL_DIR"/*.gguf | grep -i UD-Q4_K_XL | head -n 1)"Ensuite, veuillez démarrer le serveur d'inférence llama.cpp à l'aide de la commande suivante. Cette configuration est optimisée pour une RTX 3090 et équilibre le débit, la latence et la longueur du contexte.
$LLAMA_DIR/llama-server \
--model "$MODEL_FILE" \
--alias "GLM-4.7-Flash" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 16384 \
--temp 0.7 \
--top-p 1 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256--model charge le fichier de modèle GLM 4.7 Flash GGUF sélectionné pour l'inférence.--alias attribue un nom de modèle lisible qui apparaît dans les réponses API et les journaux.--threads utilise 32 threads CPU pour prendre en charge la tokenisation, la planification et le traitement des requêtes sur un système à cœur élevé.--host lie le serveur à toutes les interfaces réseau afin qu'il soit accessible localement ou depuis d'autres machines du réseau.--ctx-size définit une fenêtre contextuelle de grande taille qui équilibre la prise en charge des invites longues et l'utilisation de la mémoire GPU.--temp applique un caractère aléatoire modéré afin d'améliorer la qualité des réponses sans compromettre la stabilité du raisonnement.--top-p désactive le filtrage du noyau afin de permettre la distribution complète des jetons pendant la génération.--port 8080 expose le serveur d'inférence sur un port de développement local standard.--fit permet l'ajustement automatique de la mémoire afin d'optimiser l'utilisation du GPU sans dépasser les limites de la mémoire VRAM.--prio définit un niveau de priorité équilibré pour les charges de travail d'inférence dans le cadre de demandes simultanées.--jinja permet la prise en charge des modèles Jinja pour les invites structurées et les workflows de type agent.--flash-attn active automatiquement Flash Attention lorsque cela est pris en charge par le GPU afin d'augmenter le débit.--batch-size permet le traitement de lots volumineux afin d'améliorer le débit des jetons sur la RTX 3090.--ubatch-size Divise les lots volumineux en micro-lots plus petits afin de contrôler la pression sur la mémoire et la latence.Une fois que le serveur démarre, il chargera le modèle dans la mémoire du GPU et commencera à écouter les requêtes sur le port 8080. À ce stade, GLM 4.7 Flash fonctionne localement et est accessible via des points de terminaison HTTP pour le chat, la finalisation et les workflows basés sur les agents.
Une fois le serveur d'inférence opérationnel, vous pouvez tester GLM 4.7 Flash à l'aide de plusieurs interfaces, notamment l'interface utilisateur Web intégrée, les requêtes HTTP directes et le SDK Python compatible avec OpenAI.
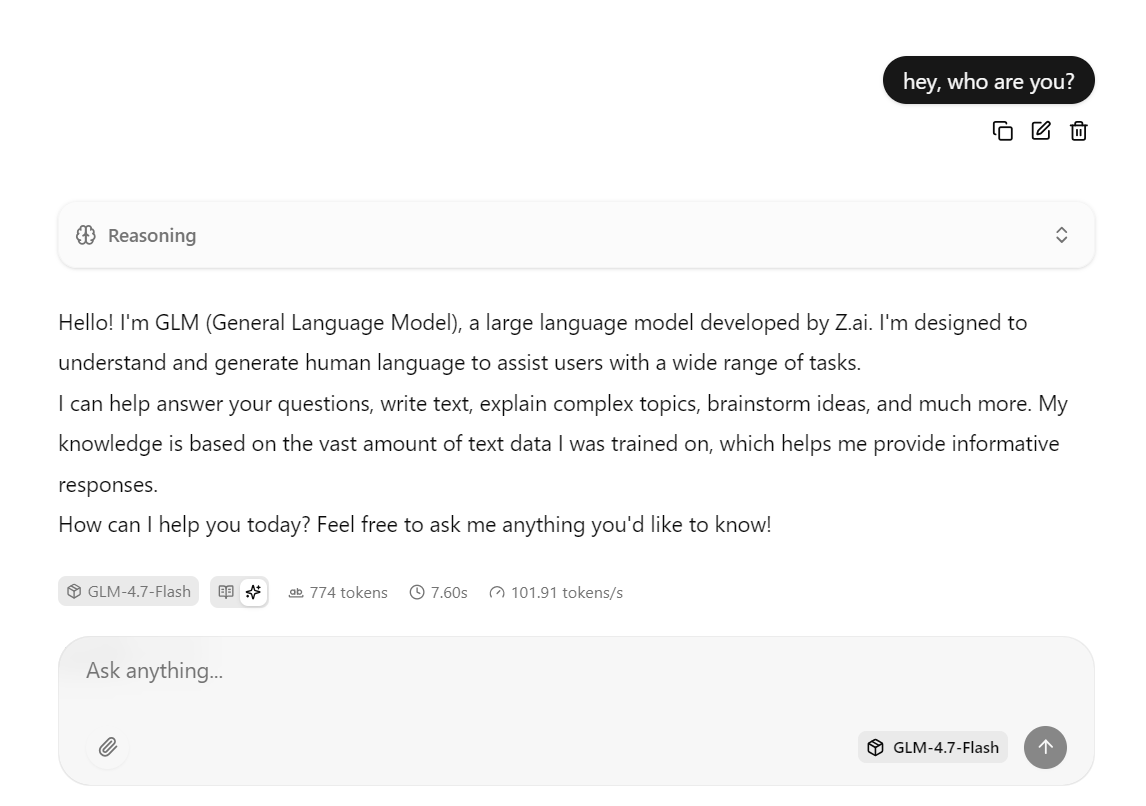
L'interface web llama.cpp est accessible à l'adresse suivante : http://0.0.0.0:8080
Veuillez copier cette URL et l'ouvrir dans votre navigateur Web pour accéder à une interface de chat simple similaire à chatGPT.

Veuillez saisir une invite, et le modèle commencera immédiatement à générer une réponse.
Cette configuration est optimisée pour la vitesse en exécutant le modèle sur la RTX 3090 avec CUDA activé, en utilisant Flash Attention lorsqu'il est disponible et en utilisant des paramètres de traitement par lots adaptés à un débit élevé.
En pratique, cette configuration peut atteindre environ 100 jetons par seconde pour des réponses courtes à moyennes.
Vous pouvez également interagir avec le même serveur en utilisant la commande curl. Veuillez ouvrir une nouvelle fenêtre de terminal et exécuter la requête suivante pour envoyer une invite de fin de conversation.
curl -N http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer local" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{ "role": "user", "content": "Write a short bash script that prints numbers 1 to 5." }
]
}'Vous pouvez également tester le modèle à l'aide de Python en installant le SDK Python OpenAI.
pip -q install openaiDans cet exemple Python, le client OpenAI est configuré pour envoyer des requêtes au serveur d'inférence llama.cpp fonctionnant localement.
base_url pointe vers le point de terminaison API local, et le champ API key est requis par le SDK, mais peut être défini sur n'importe quelle valeur de remplacement, car l'authentification est gérée localement.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="local"
)Le client envoie ensuite une demande d'achèvement de conversation à GLM 4.7 Flash en utilisant l'alias du modèle défini lors du lancement du serveur d'inférence. La invite est fournie dans un format de chat standard, et la réponse est renvoyée sous la forme d'un objet structuré.
r = client.chat.completions.create(
model="GLM-4.7-Flash",
messages=[{"role": "user", "content": "Build me a Simple API server using FastAPI"}]
)
print(r.choices[0].message.content)En quelques secondes, le modèle fournira une réponse complète, comprenant des exemples de code et des explications.

OpenCode est un agent de codage IA open source conçu pour fonctionner localement tout en prenant en charge des flux de travail tels que la génération de code, l'édition de fichiers, l'exécution de commandes et la résolution itérative de problèmes.
Contrairement aux assistants de codage basés sur le cloud, OpenCode peut être connecté à des serveurs d'inférence auto-hébergés, ce qui vous permet de créer une configuration de codage IA entièrement locale et gratuite.
Dans ce tutoriel, OpenCode est configuré pour utiliser le serveur local llama.cpp exécutant GLM 4.7 Flash via une API compatible OpenAI.
Pour commencer, veuillez utiliser la même session de terminal et installer OpenCode à l'aide du script d'installation officiel.
curl -fsSL https://opencode.ai/install | bash Après l'installation, veuillez mettre à jour votre PATH afin que l' opencode soit disponible dans le terminal.
Après l'installation, veuillez mettre à jour votre PATH afin que l' opencode soit disponible dans le terminal.
export PATH="$HOME/.local/bin:$PATH"Veuillez ouvrir une nouvelle fenêtre de terminal et vérifier que OpenCode est correctement installé.
opencode --versionVous devriez voir un numéro de version similaire à celui-ci.
1.1.29Ensuite, veuillez créer le répertoire de configuration OpenCode. Ensuite, veuillez créer le fichier de configuration OpenCode et définir llama.cpp comme fournisseur. Cette configuration indique à OpenCode d'envoyer toutes les requêtes au serveur d'inférence fonctionnant localement et d'utiliser le modèle GLM 4.7 Flash.
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llamacpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama.cpp (local)",
"options": {
"baseURL": "http://127.0.0.1:8080/v1"
},
"models": {
"GLM-4.7-Flash": {
"name": "GLM-4.7-Flash (UD-Q4_K_XL)"
}
}
}
},
"model": "GLM-4.7-Flash"
}
EOFEnfin, veuillez authentifier OpenCode. Cette étape est requise par l'outil, mais comme le serveur d'inférence est local, la clé API peut être n'importe quelle valeur de remplacement.
opencode auth loginLorsque vous y êtes invité, veuillez utiliser les valeurs suivantes.
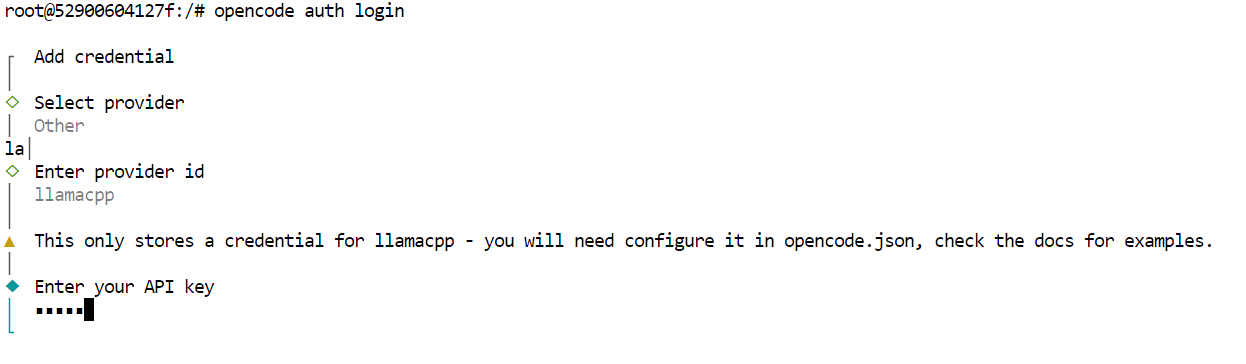
À ce stade, OpenCode est entièrement configuré pour utiliser GLM 4.7 Flash via le serveur local llama.cpp.
Une fois OpenCode configuré et connecté au serveur local llama.cpp, vous pouvez désormais utiliser GLM 4.7 Flash comme un agent de codage IA entièrement automatisé.
Veuillez commencer par créer un nouveau répertoire de projet et y accéder.
mkdir -p /workspace/project
cd /workspace/projectEnsuite, veuillez lancer OpenCode à partir du même terminal.
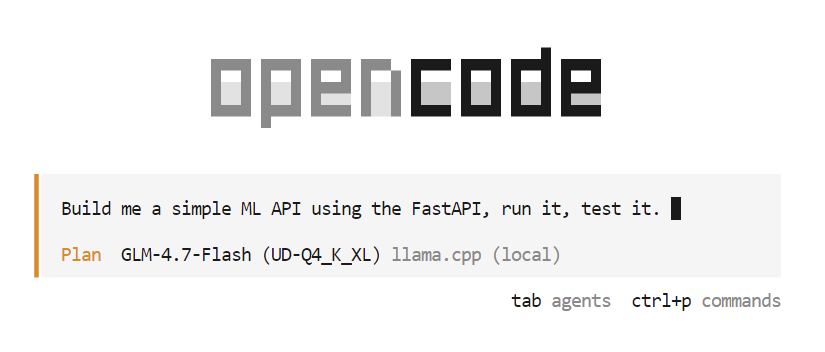
opencodeUne fois OpenCode lancé, veuillez appuyer sur la touche Tab pour passer en mode Planification. Dans ce mode, veuillez décrire ce que vous souhaitez construire.
Par exemple, veuillez saisir une invite demandant à OpenCode de créer une API simple basée sur l'apprentissage automatique à l'aide de FastAPI. OpenCode planifiera automatiquement le projet, générera le code, exécutera le serveur API et testera la mise en œuvre.
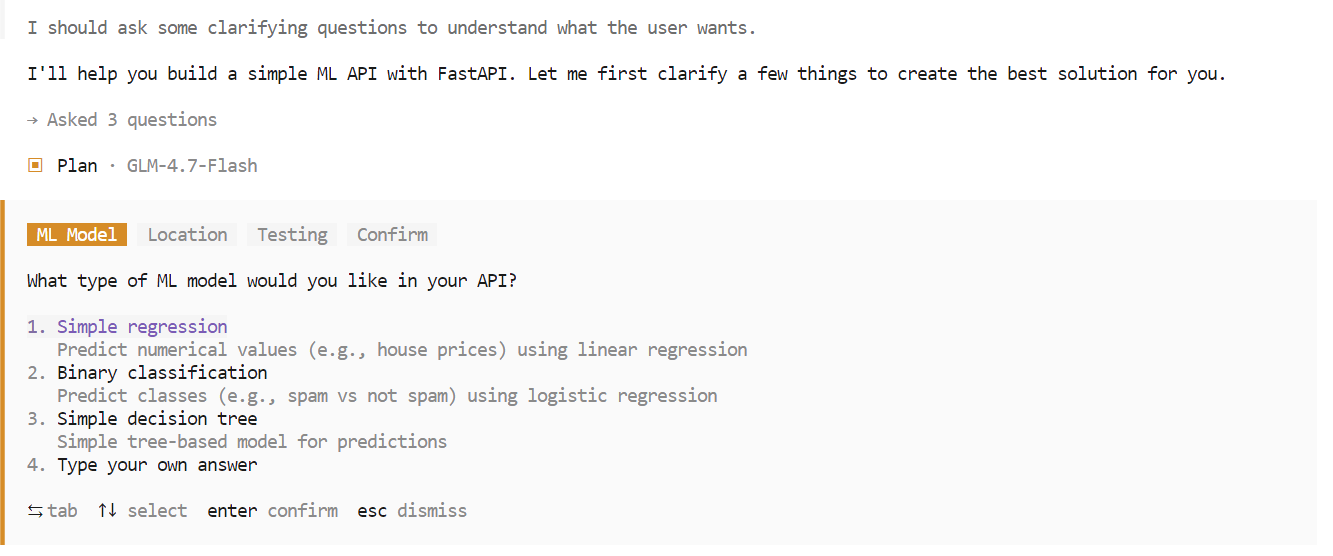
Au cours de la phase de planification, OpenCode peut poser des questions complémentaires afin de clarifier les exigences telles que le choix du cadre, les points finaux ou la structure du projet. Veuillez sélectionner les options de votre choix et confirmer pour continuer.
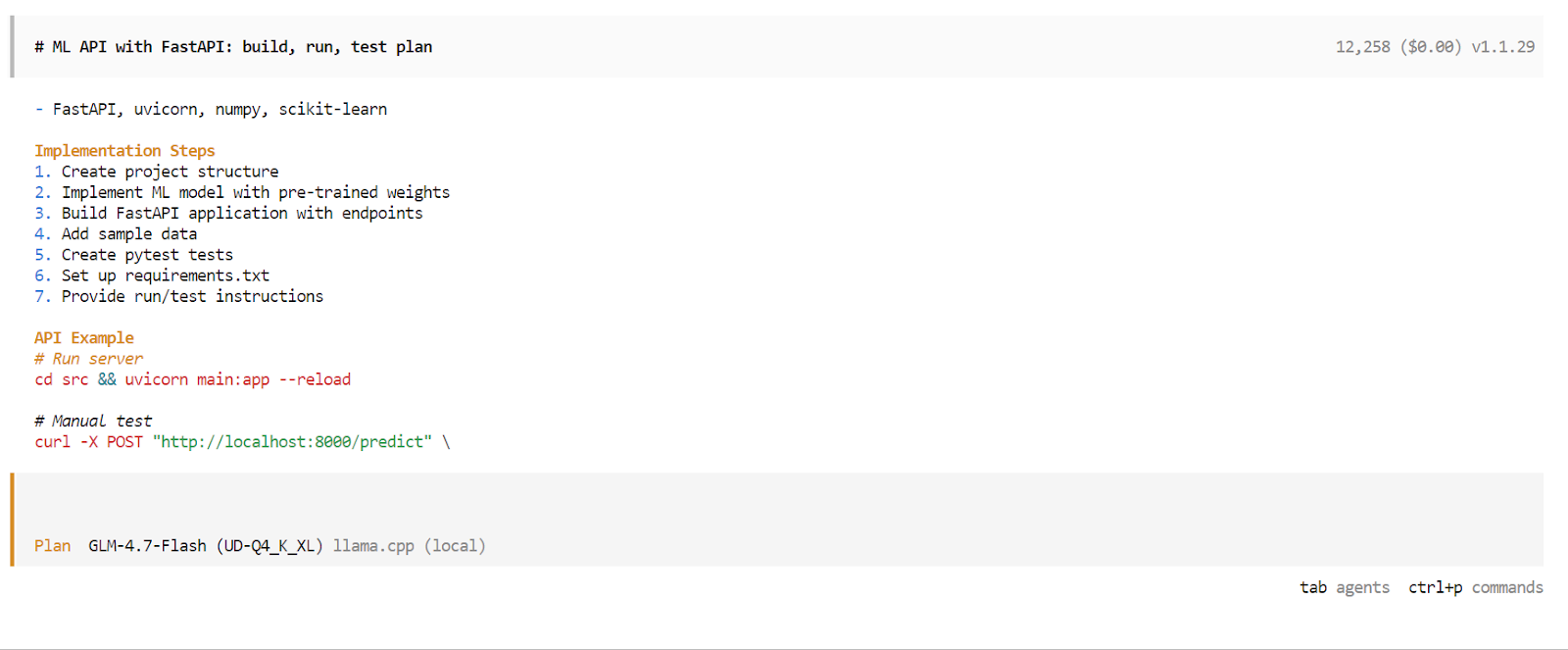
Une fois la phase de planification terminée, OpenCode présentera un plan d'exécution détaillé. Veuillez examiner le plan et l'approuver s'il correspond à vos attentes. Veuillez ensuite appuyer à nouveau surla touche Tab ( ) pour passer du mode Plan au mode Build.
En mode Build, OpenCode génère une liste de tâches structurée et exécute chaque étape de manière séquentielle. Cela comprend la génération de fichiers, l'écriture de code, l'installation de dépendances, le démarrage du serveur et l'exécution de tests. Vous pouvez observer chaque tâche être accomplie en temps réel.
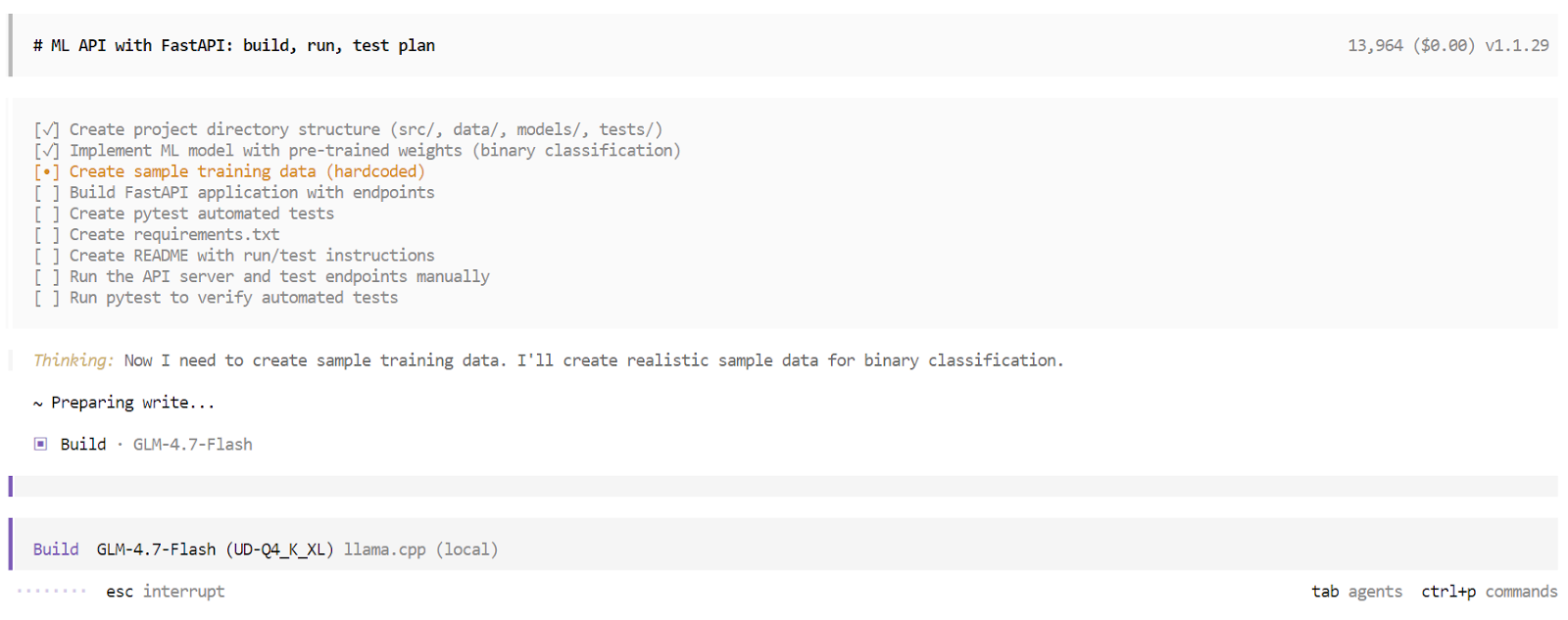
Une fois le processus de compilation terminé, OpenCode fournit une vue d'ensemble complète de l'application. Cela comprend les instructions d'utilisation, des exemples de demandes et les résultats des tests automatisés. À ce stade, vous disposez d'une application entièrement fonctionnelle, développée et validée par un agent de codage IA local fonctionnant entièrement sur votre machine.
GLM 4.7 Flash représente une avancée significative vers des agents de codage IA entièrement locaux. La possibilité d'exécuter un modèle de raisonnement rapide et performant entièrement sur du matériel local et de l'intégrer à des outils tels qu'OpenCode représente une évolution significative par rapport aux flux de travail dépendants du cloud.
Cela dit, GLM 4.7 Flash présente encore certaines limites. Bien qu'il soit performant pour les tâches de petite et moyenne envergure, il peut rencontrer des difficultés avec des workflows de codage plus complexes et comportant plusieurs étapes. Le contexte peut se remplir rapidement, l'exécution de l'outil peut parfois échouer et, dans certains cas, l'agent peut s'arrêter en cours de processus, ce qui nécessite une nouvelle session pour continuer.
Ces problèmes sont prévisibles pour un modèle MoE léger optimisé pour la vitesse plutôt que pour une profondeur de raisonnement maximale.
En termes de capacités brutes, GLM 4.7 Flash n'est pas au même niveau que le modèle GLM 4.7 complet, dont les performances sont plus proches de celles de modèles tels que Claude 4.5 Sonnet. Le compromis est évident. GLM 4.7 Flash privilégie la rapidité, l'efficacité et la facilité d'utilisation locale plutôt que la puissance de raisonnement maximale.
Travailler sur ce tutoriel et régler le serveur d'inférence a été une expérience enrichissante. L'utilisation de variantes plus précises et l'augmentation de la fenêtre contextuelle peuvent améliorer la fiabilité du codage, mais pour obtenir les meilleurs résultats, il est nécessaire de procéder à des essais minutieux avec des paramètres tels que la température, le top p, la taille des lots et la longueur du contexte. Atteindre une configuration optimale est un processus itératif.
Dans l'ensemble, GLM 4.7 Flash constitue une option pratique et intéressante pour les développeurs qui recherchent aujourd'hui des agents de codage IA rapides, locaux et gratuits, avec une marge d'amélioration évidente à mesure que les outils et les modèles continuent d'évoluer.
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
blog
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Stephen Gruppetta
Tutoriel
DataCamp Team
