
Kurs
KI-Agenten mit dem Google ADK entwickeln
1 Std.
6.5K
GLM 4.7 Flash ist eine neu veröffentlichtes offenes, großes Sprachmodell, das viel Aufmerksamkeit bekommen hat, weil es lokal laufen kann und trotzdem super bei Codierung, Schlussfolgerungen und agentenartigen Arbeitsabläufen ist.
Im Gegensatz zu vielen modernen Modellen, die auf kostenpflichtige APIs oder Cloud-basierte Infrastruktur angewiesen sind, kann GLM 4.7 Flash komplett auf lokaler Hardware mit schlanken Inferenz-Frameworks laufen. Das macht es zu einer coolen Option für Entwickler, die die volle Kontrolle über ihre Modelle, Offline-Nutzung, vorhersehbare Kosten und schnelle Iterationen während der Entwicklung wollen.
Mit der richtigen Konfiguration und Quantisierung kann das Modell auf handelsüblichen GPUs hohe Token-Generierungsgeschwindigkeiten erreichen und dabei eine gute Qualität der Schlussfolgerungen beibehalten.
In diesem Tutorial zeige ich dir, wie du die Systemumgebung einrichtest, die du brauchst, um GLM 4.7 Flash lokal mit llama.cpp laufen zu lassen. Der Fokus liegt darauf, das Setup einfach, übersichtlich und reproduzierbar zu halten. Wir laden das Modell runter, bauen und konfigurieren llama.cpp und testen dann das Modell mit einer Web-App und einem API-basierten Inferenzserver.
Später im Tutorial werden wir den lokalen Server llama.cpp mit einem KI-Codierungsagenten verbinden, um automatisierte Workflows für die Codegenerierung, -ausführung und -prüfung zu ermöglichen.
Bevor du GLM 4.7 Flash lokal startest, check bitte, ob dein System die folgenden Anforderungen erfüllt.
Für volle Präzision oder höhere Bitquantisierung:
Für ein 4-Bit-quantisiertes Modell
Die Quantisierung „ Q4_K_XL “ spart ordentlich Speicherplatz, ohne dass die Leistung beim Schlussfolgern und Codieren darunter leidet. Deshalb passt sie super zu GPUs wie RTX 3090, RTX 4080 und RTX 4090. Diese Variante ist super für Leute, die einen hohen Token-Durchsatz wollen, ohne mit voller Genauigkeit zu arbeiten.
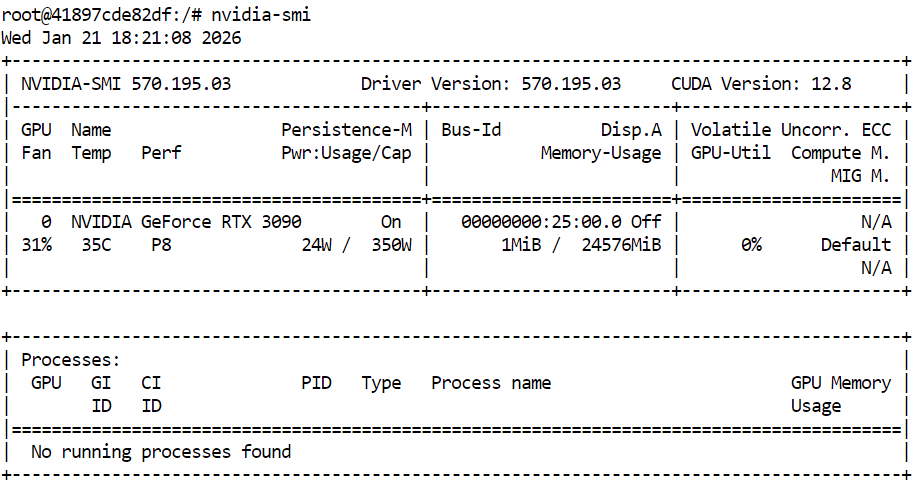
Bevor du llama.cpp baust und GLM 4.7 Flash startest, check bitte, ob deine NVIDIA-GPU und die Treiber richtig installiert sind. Dadurch wird sichergestellt, dass CUDA verfügbar ist und das System GPU-beschleunigte Inferenz ausführen kann.
nvidia-smiDie Ausgabe zeigt eine RTX 3090 mit CUDA-Version 12.8 und 24 GB GPU-Speicher, was für GLM 4.7 Flash und seine quantisierten Varianten total ausreicht.
Öffne dann ein Terminal und richte einen sauberen Arbeitsbereich und eine saubere Verzeichnisstruktur ein. So bleiben Quellcode, Modelldateien und Cache-Daten ordentlich, man vermeidet Probleme mit Berechtigungen und die Einrichtung lässt sich leicht wiederholen.
export WORKDIR="/workspace"
export LLAMA_DIR="$WORKDIR/llama.cpp"
export MODEL_DIR="$WORKDIR/models/unsloth/GLM-4.7-Flash-GGUF"Erstell das Verzeichnis, wo die Modelldateien gespeichert werden sollen, und richt den Cache von Hugging Face im Arbeitsbereich statt im Home-Verzeichnis ein. Das macht das Herunterladen schneller und vermeidet unnötige Warnungen.
mkdir -p "$MODEL_DIR"
export HF_HOME="$WORKDIR/.cache/huggingface"
export HUGGINGFACE_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"
export HF_HUB_CACHE="$WORKDIR/.cache/huggingface/hub"Leg ein paar zusätzliche Umgebungsvariablen fest, um Warnungen wegen Symlinks zu unterdrücken und schnelle Downloads zu ermöglichen.
export HF_HUB_DISABLE_SYMLINKS_WARNING=1
export HF_XET_HIGH_PERFORMANCE=1Zum Schluss installierst du die nötigen Systemabhängigkeiten, um llama.cpp zu erstellen und Downloads zu verwalten.
sudo apt-get update
sudo apt-get install -y \
build-essential cmake git curl libcurl4-openssl-devJetzt ist die Systemumgebung fertig. Der nächste Abschnitt beschäftigt sich mit dem Klonen und Erstellen von llama.cpp mit aktivierter CUDA-Unterstützung.
Nachdem die Umgebung vorbereitet ist, musst du als Nächstes llama.cpp und es mit aktivierter CUDA-Unterstützung zu erstellen. Dadurch läuft GLM 4.7 Flash super auf der GPU.
Geh im Terminal zu deinem Arbeitsbereich. Dann mach mal den folgenden Befehl, um das offizielle Repository llama.cpp zu klonen.
git clone https://github.com/ggml-org/llama.cpp "$LLAMA_DIR"Nachdem das Repository geklont wurde, werden die Quelldateien ins Arbeitsverzeichnis runtergeladen.
Cloning into '/workspace/llama.cpp'...
remote: Enumerating objects: 76714, done.
remote: Counting objects: 100% (238/238), done.
remote: Compressing objects: 100% (157/157), done.
remote: Total 76714 (delta 172), reused 81 (delta 81), pack-reused 76476 (from 3)
Receiving objects: 100% (76714/76714), 282.23 MiB | 13.11 MiB/s, done.
Resolving deltas: 100% (55422/55422), done.
Updating files: 100% (2145/2145), done.Als Nächstes stellst du den Build mit CMake ein und schaltest explizit die CUDA-Unterstützung ein. Dieser Schritt bereitet das Build-System darauf vor, GPU-beschleunigte Binärdateien zu kompilieren.
cmake "$LLAMA_DIR" -B "$LLAMA_DIR/build" \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ONSobald die Konfiguration fertig ist, baue die benötigten llama.cpp-Binärdateien. Dieser Befehl kompiliert die wichtigsten Inferenz-Tools, wie die Befehlszeilenschnittstelle und den Inferenzserver.
cmake --build "$LLAMA_DIR/build" --config Release -j --clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-splitWenn der Build fertig ist, kopier die kompilierten Binärdateien einfach ins Hauptverzeichnis llama.cpp, damit du leichter draufzugreifen kannst.
cp "$LLAMA_DIR/build/bin/llama-"* "$LLAMA_DIR/"Überprüfe zum Schluss, ob llama.cpp richtig erstellt wurde und ob CUDA erkannt wird, indem du den Befehl „inference server help“ ausführst.
"$LLAMA_DIR/llama-server" --help >/dev/null && echo "✔ llama.cpp built"Wenn die CUDA-Unterstützung richtig aktiviert ist, zeigt die Ausgabe, dass ein CUDA-Gerät erkannt wurde, einschließlich des GPU-Modells und der Rechenleistung.
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
✔ llama.cpp builtNachdem lama.cpp erstellt und die CUDA-Unterstützung überprüft wurde, musst du als Nächstes das GLM 4.7 Flash-Modell runterladen. In diesem Tutorial nutzen wir den Hugging Face Hub mit Xet-Unterstützung, um große Modelldateien schnell und zuverlässig runterzuladen.
Gib im selben Terminal die folgenden Befehle ein, um die Python-Pakete zu installieren, die du für schnelle Modell-Downloads brauchst.
pip -q install -U "huggingface_hub[hf_xet]" hf-xet
pip -q install -U hf_transferAls Nächstes fährst du das folgende Python-Skript im Terminal ab, um die 4-Bit-quantisierte Modellvariante runterzuladen. Dieses Skript nutzt die zuvor festgelegten Arbeitsbereichspfade und lädt nur die benötigte GGUF-Datei runter.
python - <<'PY'
import os
from huggingface_hub import snapshot_download
model_dir = os.environ["MODEL_DIR"]
snapshot_download(
repo_id="unsloth/GLM-4.7-Flash-GGUF",
local_dir=model_dir,
allow_patterns=["*UD-Q4_K_XL*"],
)
print("✔ Download complete:", model_dir)
PYSobald der Download fertig ist, solltest du eine Meldung sehen, die bestätigt, dass die Modelldatei erfolgreich runtergeladen wurde, mit einer Gesamtgröße von ungefähr 17,5 GB.
Fetching 1 files: 100%|███████████████████████████████████████████████████████████████████████████████████| 1/1 [00:52<00:00, 52.80s/it]
Download complete: 100%|████████████████████████████████████████████████████████████████████████████| 17.5G/17.5G [00:52<00:00, 480MB/s]✔ Download complete: /workspace/models/unsloth/GLM-4.7-Flash-GGUFÜberprüfe zum Schluss, ob die Modelldatei im Zielverzeichnis da ist.
ls -lh "$MODEL_DIR"Du solltest die Datei „ GLM-4.7-Flash-UD-Q4_K_XL.gguf “ sehen, die bestätigt, dass das Modell für die Inferenz bereit ist.
total 17G
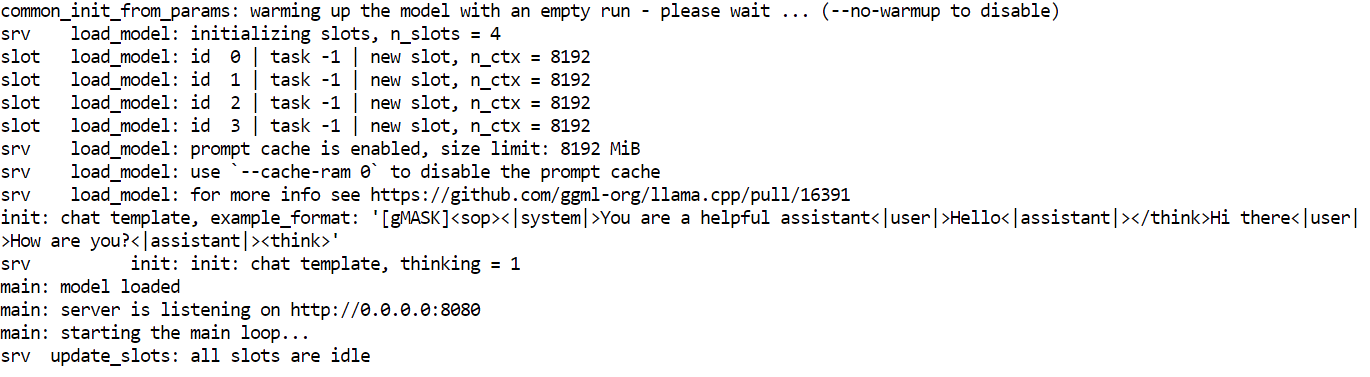
-rw-rw-rw- 1 root root 17G Jan 21 18:46 GLM-4.7-Flash-UD-Q4_K_XL.ggufNachdem du das Modell runtergeladen und llama.cpp mit CUDA-Unterstützung erstellt hast, musst du als Nächstes den Inferenzserver starten. Dadurch wird GLM 4.7 Flash als lokale API verfügbar gemacht, die von Benutzeroberflächen, Skripten und KI-Codierungsagenten genutzt werden kann.
Benutz bitte dieselbe Terminal-Sitzung und denselben Arbeitsbereich, die du in den vorherigen Abschnitten eingerichtet hast.
Such zuerst die heruntergeladene GGUF-Modelldatei und speicher den Pfad dazu in einer Umgebungsvariablen.
export MODEL_FILE="$(ls "$MODEL_DIR"/*.gguf | grep -i UD-Q4_K_XL | head -n 1)"Starte dann den Inferenzserver llama.cpp mit dem folgenden Befehl. Diese Konfiguration ist für eine RTX 3090 optimiert und sorgt für einen guten Ausgleich zwischen Durchsatz, Latenz und Kontextlänge.
$LLAMA_DIR/llama-server \
--model "$MODEL_FILE" \
--alias "GLM-4.7-Flash" \
--threads 32 \
--host 0.0.0.0 \
--ctx-size 16384 \
--temp 0.7 \
--top-p 1 \
--port 8080 \
--fit on \
--prio 3 \
--jinja \
--flash-attn auto \
--batch-size 1024 \
--ubatch-size 256--model Lädt die ausgewählte GLM 4.7 Flash GGUF-Modelldatei für die Inferenz.--alias Weist einen lesbaren Modellnamen zu, der in API-Antworten und Protokollen angezeigt wird.--threads nutzt 32 CPU-Threads, um die Tokenisierung, die Planung und die Bearbeitung von Anfragen auf einem High-Core-System zu unterstützen.--host Bindet den Server an alle Netzwerkschnittstellen, sodass man lokal oder von anderen Rechnern im Netzwerk drauf zugreifen kann.--ctx-size stellt ein großes Kontextfenster ein, das die Unterstützung für lange Eingabeaufforderungen mit der GPU-Speichernutzung ausgleicht.--temp wendet moderate Zufälligkeit an, um die Antwortqualität zu verbessern, ohne die Stabilität der Argumentation zu beeinträchtigen.--top-p Deaktiviert die Kernfilterung, damit die Token während der Generierung komplett verteilt werden können.--port 8080 macht den Inferenzserver auf einem normalen lokalen Entwicklungsport verfügbar.--fit ermöglicht automatische Speicheranpassung, um die GPU-Auslastung zu maximieren, ohne die VRAM-Grenzen zu überschreiten.--prio legt eine ausgewogene Prioritätsstufe für Inferenz-Workloads bei gleichzeitigen Anfragen fest.--jinja macht Jinja-Templating für strukturierte Eingabeaufforderungen und Agent-Style-Workflows möglich.--flash-attn Aktiviert automatisch Flash Attention, wenn die GPU das unterstützt, um den Durchsatz zu erhöhen.--batch-size ermöglicht die Verarbeitung großer Datenmengen, um den Token-Durchsatz auf der RTX 3090 zu verbessern.--ubatch-size Teilt große Stapel in kleinere Mikrostapel auf, um den Speicherbedarf und die Latenz zu kontrollieren.Sobald der Server loslegt, lädt er das Modell in den GPU-Speicher und wartet auf Anfragen über Port 8080. Im Moment läuft GLM 4.7 Flash lokal und kann über HTTP-Endpunkte für Chat, Fertigstellung und agentenbasierte Workflows genutzt werden.
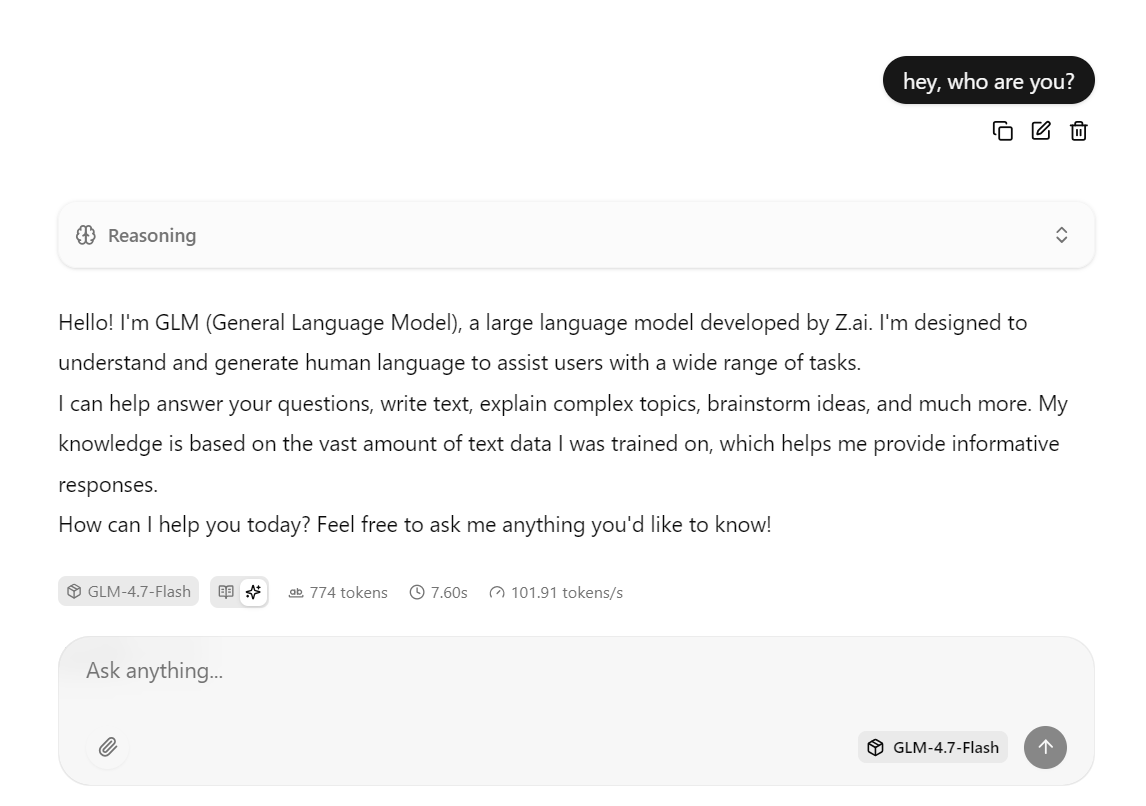
Wenn der Inferenzserver läuft, kannst du jetzt GLM 4.7 Flash über verschiedene Schnittstellen testen, wie die eingebaute Web-Benutzeroberfläche, direkte HTTP-Anfragen und das OpenAI-kompatible Python SDK.
Die Webschnittstelle llama.cpp findest du unter: http://0.0.0.0:8080
Kopier diese URL und öffne sie in deinem Webbrowser, um eine einfache Chat-Oberfläche ähnlich wie chatGPT zu nutzen.

Gib einfach eine Eingabe ein, und das Modell fängt sofort an, eine Antwort zu generieren.
Diese Konfiguration ist auf Geschwindigkeit optimiert, indem das Modell auf der RTX 3090 mit aktiviertem CUDA ausgeführt wird, Flash Attention verwendet wird, wenn verfügbar, und Batch-Einstellungen für hohen Durchsatz verwendet werden.
In der Praxis kann diese Konfiguration bei kurzen bis mittleren Antworten etwa 100 Token pro Sekunde schaffen.
Du kannst auch mit demselben Server über den Befehl „ curl “ interagieren. Öffne ein neues Terminalfenster und führe den folgenden Befehl aus, um eine Aufforderung zum Beenden des Chats zu senden.
curl -N http://127.0.0.1:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer local" \
-d '{
"model": "GLM-4.7-Flash",
"messages": [
{ "role": "user", "content": "Write a short bash script that prints numbers 1 to 5." }
]
}'Du kannst das Modell auch mit Python testen, indem du das OpenAI Python SDK installierst.
pip -q install openaiIn diesem Python-Beispiel ist der OpenAI-Client so eingerichtet, dass er Anfragen an den lokal laufenden Inferenzserver llama.cpp schickt.
Der Parameter „ base_url “ zeigt auf den lokalen API-Endpunkt, und das Feld „API key“ muss vom SDK verwendet werden, kann aber mit einem beliebigen Platzhalterwert gefüllt werden, weil die Authentifizierung lokal läuft.
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8080/v1",
api_key="local"
)Der Client schickt dann eine Anfrage zum Beenden des Chats an GLM 4.7 Flash und benutzt dabei den Modellalias, der beim Starten des Inferenzservers festgelegt wurde. Die Eingabeaufforderung kommt im normalen Chat-Format, und die Antwort wird als strukturiertes Objekt zurückgegeben.
r = client.chat.completions.create(
model="GLM-4.7-Flash",
messages=[{"role": "user", "content": "Build me a Simple API server using FastAPI"}]
)
print(r.choices[0].message.content)Innerhalb von ein paar Sekunden gibt das Modell eine komplette Antwort zurück, inklusive Beispielcode und Erklärungen.

OpenCode ist ein Open-Source-KI-Codierungsagent, der lokal läuft und agentenbasierte Arbeitsabläufe wie Codegenerierung, Dateibearbeitung, Befehlsausführung und iterative Problemlösung unterstützt.
Anders als Cloud-basierte Programmierhelfer kann OpenCode mit selbst gehosteten Inferenzservern verbunden werden, sodass du eine komplett lokale und kostenlose KI-Programmierumgebung aufbauen kannst.
In diesem Tutorial wird OpenCode so eingerichtet, dass es den lokalen Server llama.cpp nutzt, auf dem GLM 4.7 Flash über eine OpenAI-kompatible API läuft.
Zuerst nimmst du dieselbe Terminal-Sitzung und installierst OpenCode mit dem offiziellen Installationsskript.
curl -fsSL https://opencode.ai/install | bash Nach der Installation musst du deinen PATH anpassen, damit der Befehl „opencode“ im Terminal verfügbar ist.
Nach der Installation musst du deinen PATH anpassen, damit der Befehl „opencode“ im Terminal verfügbar ist.
export PATH="$HOME/.local/bin:$PATH"Öffne ein neues Terminalfenster und schau nach, ob OpenCode richtig installiert ist.
opencode --versionDu solltest eine Versionsnummer sehen, die ungefähr so aussieht.
1.1.29Als Nächstes machst du das OpenCode-Konfigurationsverzeichnis. Dann mach die OpenCode-Konfigurationsdatei und leg llama.cpp als Anbieter fest. Diese Konfiguration sagt OpenCode, dass es alle Anfragen an den lokal laufenden Inferenzserver schicken und das GLM 4.7 Flash-Modell verwenden soll.
mkdir -p ~/.config/opencode
cat > ~/.config/opencode/opencode.json <<'EOF'
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llamacpp": {
"npm": "@ai-sdk/openai-compatible",
"name": "llama.cpp (local)",
"options": {
"baseURL": "http://127.0.0.1:8080/v1"
},
"models": {
"GLM-4.7-Flash": {
"name": "GLM-4.7-Flash (UD-Q4_K_XL)"
}
}
}
},
"model": "GLM-4.7-Flash"
}
EOFZum Schluss musst du OpenCode authentifizieren. Dieser Schritt ist für das Tool wichtig, aber da der Inferenzserver lokal ist, kann der API-Schlüssel ein beliebiger Platzhalterwert sein.
opencode auth loginWenn du dazu aufgefordert wirst, gib einfach die folgenden Werte ein.
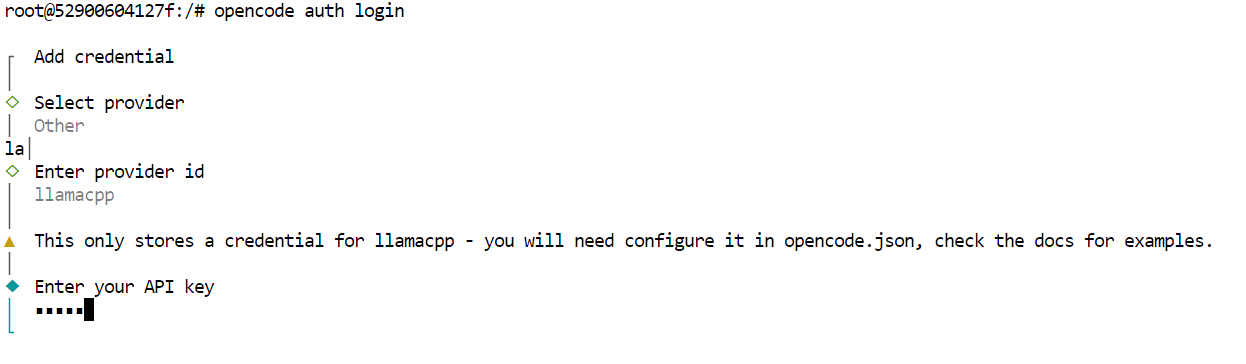
Jetzt ist OpenCode komplett eingerichtet, um GLM 4.7 Flash über den lokalen llama.cpp-Server zu nutzen.
Nachdem du OpenCode eingerichtet und mit dem lokalen llama.cpp-Server verbunden hast, kannst du jetzt GLM 4.7 Flash als vollautomatischen KI-Codierungsagenten nutzen.
Mach zuerst ein neues Projektverzeichnis und geh da rein.
mkdir -p /workspace/project
cd /workspace/projectStarte dann OpenCode über dasselbe Terminal.
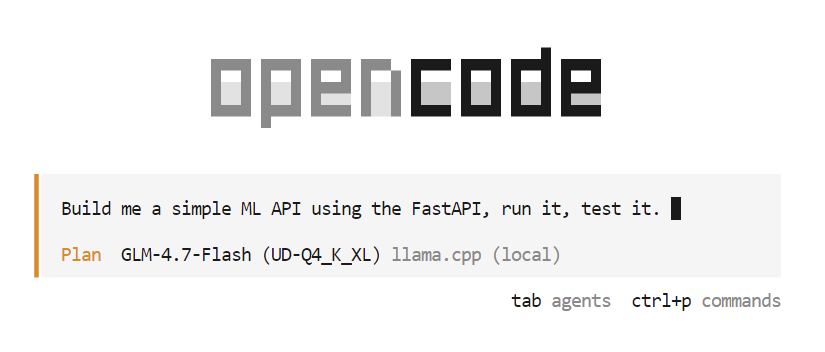
opencodeSobald OpenCode gestartet ist, drück die Tabulatortaste, um in den Planmodus zu wechseln . Beschreib in diesem Modus, was du bauen willst.
Gib zum Beispiel eine Eingabeaufforderung ein, in der du OpenCode bittest, eine einfache, auf maschinellem Lernen basierende API mit FastAPI zu erstellen. OpenCode plant das Projekt automatisch, schreibt den Code, startet den API-Server und testet die Umsetzung.
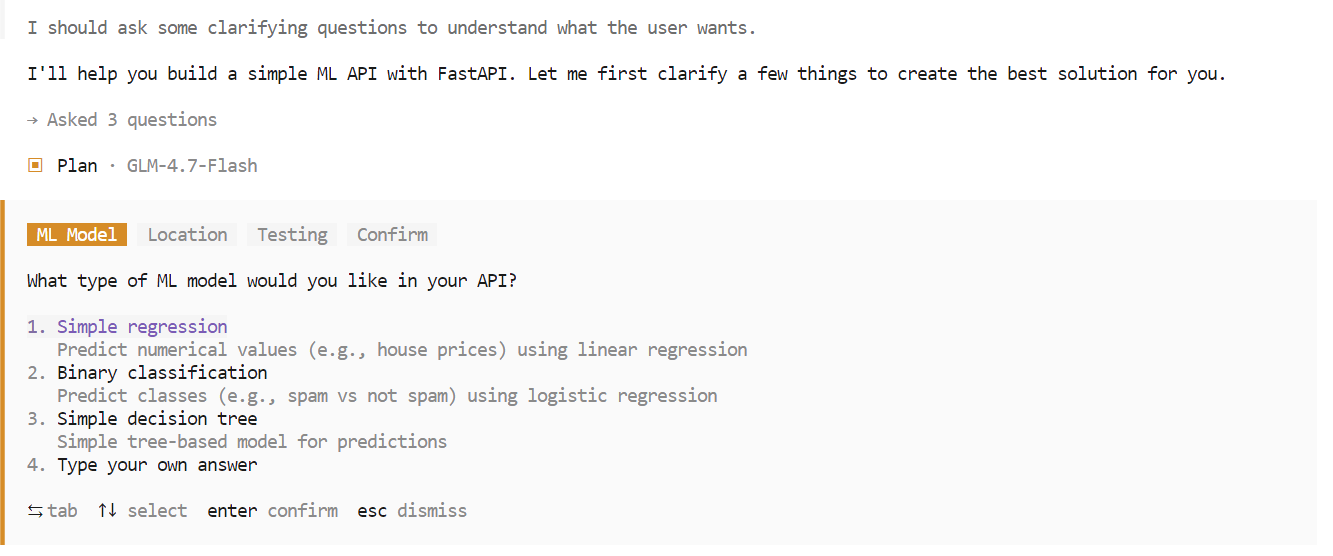
Während der Planungsphase kann OpenCode noch mal nachfragen, um Sachen wie die Wahl des Frameworks, Endpunkte oder die Projektstruktur zu klären. Wähl die Optionen aus, die du bevorzugst, und bestätige, um fortzufahren.
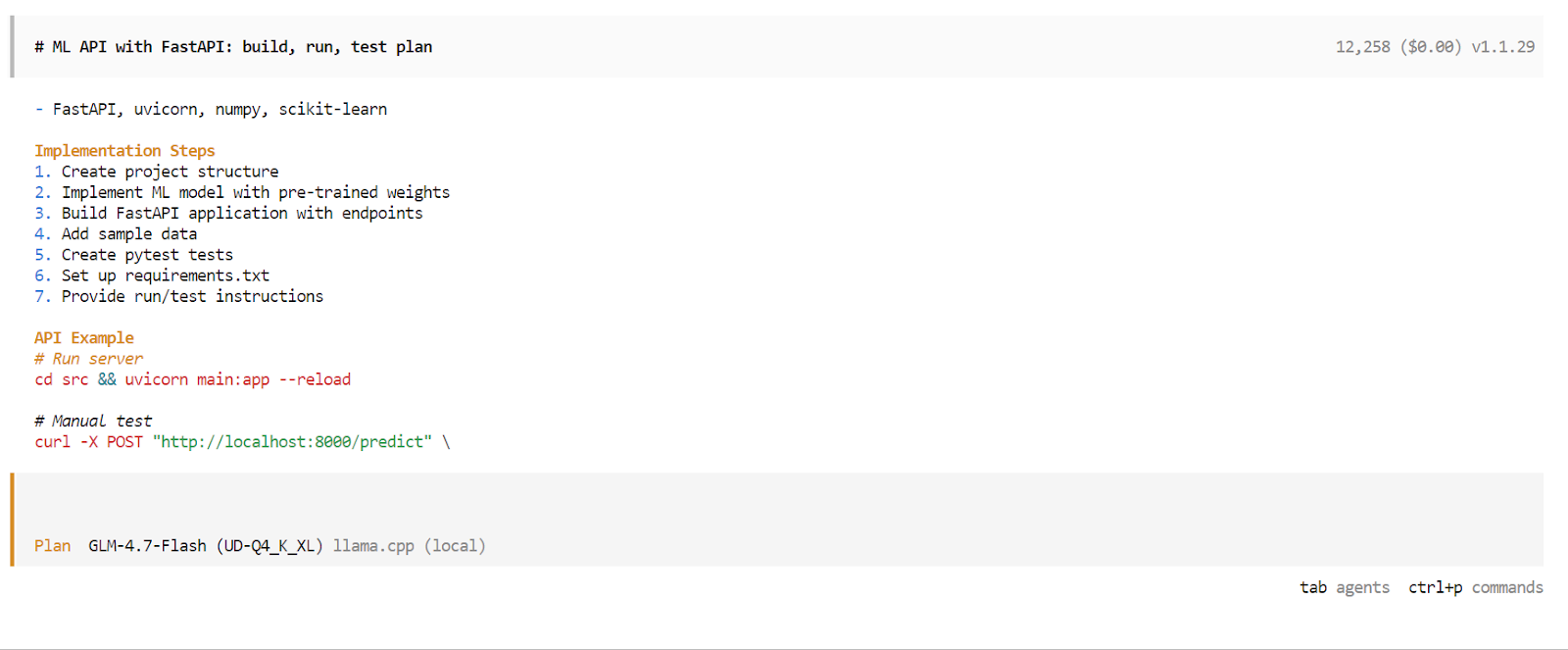
Sobald die Planungsphase fertig ist, wird OpenCode einen genauen Plan für die Umsetzung zeigen. Schau dir den Plan an und gib dein Okay, wenn er deinen Vorstellungen entspricht. Drück dann nochmal die Taste „ “, um vom Planmodus in den Build-Modus zu wechseln .
Im Build-Modus erstellt OpenCode eine strukturierte Aufgabenliste und macht jeden Schritt nacheinander. Dazu gehören das Erstellen von Dateien, das Schreiben von Code, das Installieren von Abhängigkeiten, das Starten des Servers und das Ausführen von Tests. Du kannst jede Aufgabe in Echtzeit verfolgen, während sie erledigt wird.
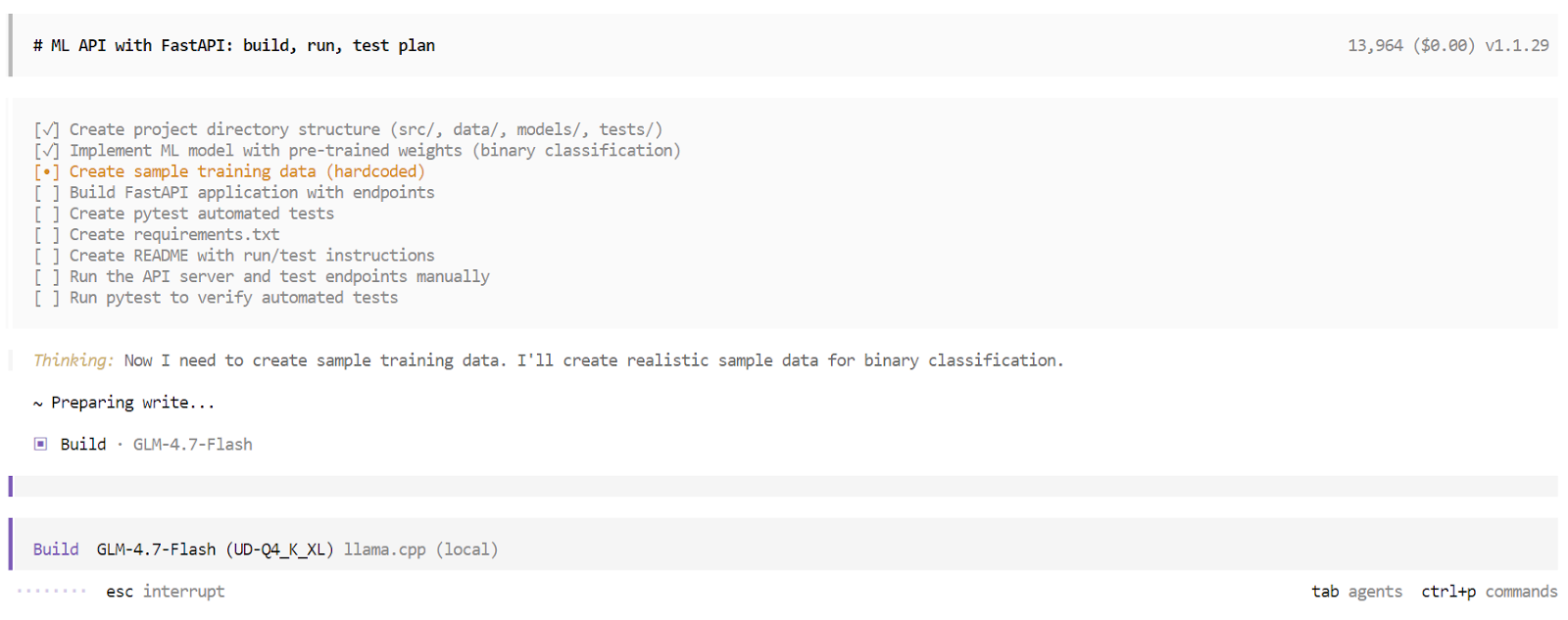
Sobald der Erstellungsprozess abgeschlossen ist, gibt OpenCode einen kompletten Überblick über die Anwendung. Das umfasst Anweisungen zur Nutzung, Beispielanfragen und die Ergebnisse automatisierter Tests. Jetzt hast du eine voll funktionsfähige App, die von einem lokalen KI-Codierungsagenten erstellt und überprüft wurde und komplett auf deinem Rechner läuft.
GLM 4.7 Flash ist ein großer Schritt in Richtung vollständig lokaler KI-Codierungsagenten. Die Möglichkeit, ein schnelles, leistungsfähiges Schlussfolgerungsmodell komplett auf lokaler Hardware laufen zu lassen und es mit Tools wie OpenCode zu verbinden, ist ein wichtiger Schritt weg von Cloud-abhängigen Arbeitsabläufen.
Trotzdem hat GLM 4.7 Flash immer noch ein paar Einschränkungen. Es macht seine Sache gut bei kleinen bis mittelgroßen Aufgaben, hat aber manchmal Probleme mit komplexeren, mehrstufigen Programmierabläufen. Der Speicherplatz kann schnell voll werden, die Ausführung von Tools kann manchmal hängen bleiben und manchmal kann der Agent mitten im Prozess stehen bleiben, sodass man eine neue Sitzung starten muss, um weiterzumachen.
Diese Probleme sind bei einem leichten MoE-Modell zu erwarten, das eher auf Geschwindigkeit als auf maximale Argumentationstiefe ausgelegt ist.
Was die reine Leistung angeht, ist GLM 4.7 Flash nicht ganz so stark wie das komplette GLM 4.7-Modell, das eher so Modellen wie Claude 4.5 Sonnetähnelt. Der Kompromiss ist klar. GLM 4.7 Flash legt mehr Wert auf Geschwindigkeit, Effizienz und lokale Benutzerfreundlichkeit als auf maximale Rechenleistung.
Das Durcharbeiten dieses Tutorials und das Optimieren des Inferenzservers war echt eine coole Erfahrung. Die Verwendung von Varianten mit höherer Präzision und die Vergrößerung des Kontextfensters können die Zuverlässigkeit der Codierung verbessern, aber um die besten Ergebnisse zu erzielen, muss man sorgfältig mit Parametern wie Temperatur, Top-p, Chargengrößen und Kontextlänge experimentieren. Das Finden der besten Einstellung ist ein Prozess, den man immer wieder machen muss.
Insgesamt ist GLM 4.7 Flash eine praktische und spannende Option für Entwickler, die schon heute schnelle, lokale und kostenlose KI-Codierungsagenten wollen, wobei es noch klaren Raum für Verbesserungen gibt, da sich die Tools und Modelle ständig weiterentwickeln.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
DataCamp Team