Curso
Introdução ao R
4 h
3M

Fazer um currículo legal não é o suficiente pra entrar no mercado de trabalho de ciência de dados. Se você quer começar uma carreira em ciência de dados, é super importante criar um portfólio de projetos relevantes que mostrem suas habilidades com dados na entrevista.
A boa notícia é que nunca é cedo ou tarde demais para começar a criar esse portfólio. Seja você um novato total ou já esteja na metade do caminho para aprender ciência de dados, pode começar a trabalhar em seus projetos R agora mesmo.
Tudo bem se seus primeiros projetos parecerem amadores. Você sempre pode voltar a eles mais tarde, elaborá-los, refiná-los ou até mesmo excluí-los quando fizer projetos mais avançados. O mais importante aqui é começar o processo.
Neste artigo, vamos apresentar algumas ideias úteis para seus projetos de ciência de dados usando R e ver alguns exemplos para você começar. Também vamos falar sobre a linguagem de programação R e como ela é usada para análise de dados e ciência de dados.
R é uma linguagem de programação usada para análise de dados, ciência de dados e machine learning, e também inclui um ambiente para computação estatística e gráficos. O R foi feito especialmente para fazer cálculos estatísticos avançados e rápidos, modelar dados e criar visualizações que chamam a atenção. É aqui que essa linguagem mostra seu verdadeiro poder.
Além disso, R:
Você vai encontrar mais informações sobre a linguagem de programação R e como aprender a usá-la nos nossos artigos O que é R? - A potência da computação estatística e Como começar a usar R. Você também pode fazer o curso Introdução ao R do DataCamp.
Para começar a aprender R do zero ou dominar habilidades técnicas específicas, confira nossos diversos recursos de aprendizagem, incluindo cursos, programas de habilidades e programas de carreira. Especialmente, se você quer um caminho equilibrado e completo para aprender R, dá uma olhada nos programas de Cientista de Dados com R e Cientista de Machine Learning com R.
Fazer a análise de dados é o primeiro passo de qualquer projeto de ciência de dados. É lógico: antes de mergulhar na previsão de cenários futuros usando técnicas de machine learning e aprendizado profundo, precisamos revelar o estado atual (e passado) das coisas.
Por outro lado, a análise de dados pode ser uma tarefa independente. Nos dois casos, o R oferece um monte de bibliotecas úteis, feitas especialmente para fins analíticos.
Com o R, a gente pode analisar os dados de sites, limpá-los e organizá-los, visualizá-los, explorar suas estatísticas, criar e testar hipóteses e extrair insights e padrões significativos dos dados iniciais. Entre essas tarefas, a análise estatística e as visualizações incríveis são um verdadeiro trunfo do R, e é aí que essa linguagem de programação geralmente supera seu principal rival, o Python.
Além dos pacotes multifuncionais comuns do R, tem vários módulos feitos pra resolver diferentes problemas analíticos. Por exemplo:
fAssets: Esse pacote foi feito pra analisar e modelar ativos financeiros.
mdapack: Este é um pacote de análise de dados médicos.
GEOmap: Esse pacote é usado para fazer mapas topográficos e geológicos.
AeRobiology: Essa ferramenta computacional é para dados aerobiológicos.
galigor: Essa é uma coleção de pacotes para marketing na Internet.
lingtypology: Esse pacote é usado para tipologia linguística e mapeamento.
Além disso, o R inclui até mesmo bibliotecas hiperfocadas, como:
Como falamos antes, R é uma linguagem de programação voltada para ciência de dados que oferece mais de 19.000 pacotes de ciência de dados. Além das tarefas puramente analíticas listadas na seção anterior, podemos usar o R para problemas mais avançados com o objetivo de prever e modelar dados desconhecidos. Usar o R nos permite:
Mais uma vez, além dos pacotes de ciência de dados mais usados (caret para treinamento de classificação e regressão, naivebayes para implementar o algoritmo Naive Bayes, randomForest para construir modelos de floresta aleatória, deepNN para aprendizado profundo, etc.), tem várias bibliotecas superespecializadas, até mesmo bem específicas. Pra citar alguns deles:
OenoKPM: Esse pacote é usado para modelar a cinética da produção de CO2 na fermentação alcoólica.
fHMM: Esse pacote foi feito pra encaixar modelos ocultos de Markov em dados financeiros.
paleopop: Essa é uma estrutura de modelagem orientada por padrões para modelos paleoclimáticos acoplados de nicho-população.
ibdsim2: Esse pacote é usado pra simular regiões cromossômicas que os membros da família têm em comum.
rSHAPE: Esse pacote foi feito pra simular a evolução da população assexuada haplóide.
Agora, vamos dar uma olhada em alguns exemplos de projetos R e identificar ideias interessantes para desenvolvimento futuro, tanto para iniciantes quanto para usuários experientes.
Uma das maneiras mais legais de procurar projetos em R é criar esses exemplos você mesmo!
Não se preocupe, não é tão assustador quanto parece. Mesmo se você for iniciante em ciência de dados em R, pode escolher projetos “sandbox” que já vêm com os dados prontos para serem analisados ou modelados, apresentam o contexto de um problema e dão dicas úteis sobre o que fazer e por quê.
Se você é um aluno mais avançado, pode explorar os dados mais a fundo, de diferentes ângulos, e ir muito além das instruções sugeridas para satisfazer sua curiosidade sobre os dados. De qualquer jeito, aprender na prática é melhor do que só ficar lendo os projetos dos outros.
O DataCamp tem várias opções de projetos de ciência de dados em R que vão te ajudar a praticar várias habilidades técnicas. Esses exemplos incluem importação e limpeza de dados, manipulação de dados, visualização de dados, probabilidade e estatística, machine learning e muito mais.
Além dos temas populares (como Explorando o mercado Airbnb de Nova York, Visualizando a COVID-19, Agrupando dados de pacientes com doenças cardíacas ou Prevendo tarifas de táxi com Random Forests) que são tradicionalmente analisados em várias escolas de ciência de dados, aqui você também encontrará vários temas novos e curiosos. Fique à vontade para explorar mais a fundo:
Depois de dar uma olhada nos projetos R que já existem ou fazer alguns guiados por conta própria, você pode decidir começar a criar seus próprios projetos do zero. Isso é sempre uma boa ideia, não importa em que estágio você esteja no aprendizado do R.
Se você está fazendo um dos seus primeiros projetos sem orientação, a primeira coisa a pensar é onde encontrar os dados para trabalhar. Por sorte, tem vários repositórios online populares que oferecem um monte de coleções de conjuntos de dados grátis e bem documentados, tanto reais quanto sintéticos. Alguns exemplos legais desses recursos são DataLab, Kaggle, UCI Machine Learning Repository, Google Dataset Search, Google Cloud Platform, FiveThirtyEight e Quandl.
Agora que você tem uma grande variedade de dados, o que exatamente você pode fazer com eles como iniciante no R? Como esses serão seus primeiros projetos de ciência de dados em R, pense em fazer uma limpeza e manipulação básica dos dados, uma exploração simples dos dados e uma visualização dos dados.
O Spotify é um dos maiores serviços de música, vídeo e mídia digital, onde você pode encontrar milhões de músicas, vídeos e podcasts de todo o mundo.
Você pode pegar um conjunto de dados já pronto, o Spotify Music Data, que tem cerca de 600 músicas mais tocadas em um determinado período, e ver as estatísticas dele de vários ângulos. Por exemplo, pense em analisar os seguintes fatores e perguntas, complementando suas descobertas com gráficos significativos quando necessário:
Um exemplo do projeto Spotify Music Data R
A National Basketball Association (NBA) é uma liga profissional norte-americana de basquetebol masculino composta por 30 equipes, uma das maiores do mundo.
O conjunto de dados de arremessos da NBA tem os dados coletados de quatro jogadores diferentes nas eliminatórias da NBA de 2021. Você pode analisar e visualizar esses dados e tentar responder às seguintes perguntas:
Um exemplo do projeto R sobre estatísticas de arremessos da NBA
Outra ideia legal para um projeto R de ciência de dados para iniciantes é dar uma olhada nas tendências da população mundial.
O conjunto de dados World Population Data traz estatísticas da população total de cada país de 1960 a 2020, além de algumas informações extras por país, como região, faixa de renda e observações especiais (se houver). Tem várias questões que você pode explorar aqui:
Não esqueça de incluir argumentos convincentes sempre que for útil: eles vão ajudar seus leitores a entender melhor as principais conclusões da sua análise.
Se você está no meio do caminho para aprender ciência de dados em R, talvez queira criar projetos R mais sofisticados, onde você pode usar suas habilidades de análise de dados e alguns algoritmos de machine learning.
Que tópicos você pode escolher para eles? Vamos dar uma olhada em algumas ideias possíveis para seus projetos avançados de ciência de dados em R.
A rotatividade de clientes é quando as pessoas cancelam suas assinaturas de um serviço e, por isso, deixam de ser clientes desse serviço. É calculada como a porcentagem de clientes que cancelaram dentro de um determinado período.
Esse indicador depende de vários fatores e mostra como está a saúde geral dos negócios da empresa. Quando é muito alta, a taxa de rotatividade de clientes é um problema sério para qualquer empresa, porque faz com que a empresa perca receita e prejudica a reputação dela. Por isso, é super importante conseguir prever a taxa de rotatividade de clientes para evitar isso.
Você pode usar o conjunto de dados Telecom Customer Churn para criar um projeto de ciência de dados sobre a previsão da taxa de rotatividade de clientes em uma empresa de telecomunicações.
Aqui, você precisa prever se um cliente vai cancelar ou não com base nos dados disponíveis e quais fatores aumentam a chance de um cliente cancelar. Tecnicamente, esse é um problema típico de classificação do machine learning, quando os clientes são rotulados como 1 (rotatividade) ou 0 (não rotatividade).
A fraude com cartão de crédito é um grande desafio no setor bancário, já que essa área costuma lidar com um monte de transações online. A detecção de fraudes com cartão de crédito é basicamente um problema de classificação supervisionada, onde a gente pode usar métodos como k-vizinhos mais próximos (KNN), regressão logística, máquinas de vetor de suporte (SVM) ou árvore de decisão.
Mas também dá pra resolver usando agrupamento, reconhecimento de anomalias ou redes neurais artificiais.
Esse problema é complicado para o setor bancário em geral, porque os padrões de fraude e as táticas dos fraudadores estão sempre mudando, então os sistemas de detecção de fraudes precisam se adaptar rapidinho a essas mudanças.
Para um cientista de dados ou cientista de machine learning, o desafio também está na natureza desses conjuntos de dados: eles sempre têm um desequilíbrio de classes, já que os casos de fraude são sempre minoria (felizmente) e ficam bem escondidos entre as transações reais (infelizmente).
O conjunto de dados sobre fraudes com cartões de crédito tem informações sobre transações com cartões de crédito no oeste dos Estados Unidos. Pense em usar isso pra detectar fraudes de cartão de crédito aplicando a abordagem de classificação.
Como uma dica extra, o modelo deve ser mais conservador, ou seja, por segurança, não é grande coisa rotular transações como fraudulentas quando elas não são. Você também pode querer dar uma olhada na distribuição geoespacial das taxas de fraude em diferentes estados.
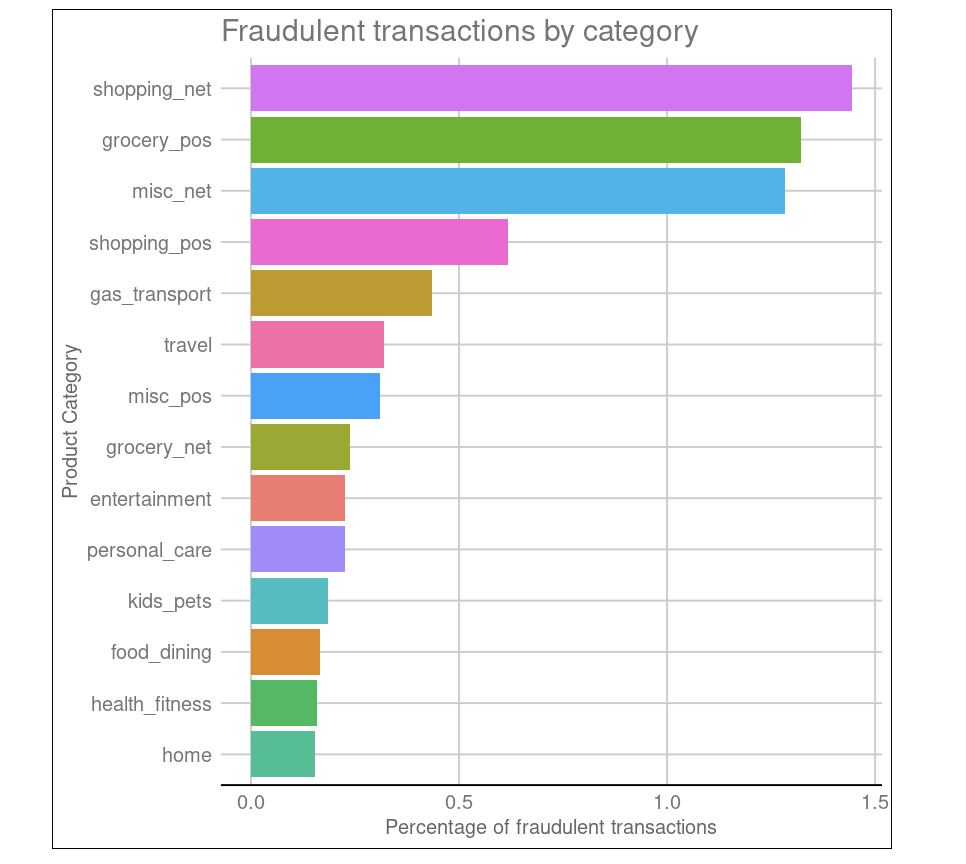
Outro exemplo de projeto R do DataCamp
Enquanto os dois projetos anteriores estavam relacionados à classificação de entradas de dados em categorias pré-definidas, aqui você deve prever resultados contínuos com base nos recursos de entrada. Em outras palavras, você precisa resolver um problema de regressão usando métodos como regressão linear, regressão ridge, regressão lasso, árvore de decisão ou máquinas de vetor de suporte (SVM).
O conjunto de dados sobre a demanda por compartilhamento de bicicletas inclui informações sobre o número de bicicletas públicas alugadas no sistema de compartilhamento de bicicletas de Seul por hora, o clima, a data, a hora, se era feriado ou não e muito mais. Sua tarefa é prever o número de bicicletas que serão alugadas com base nessas informações.
Você também pode usar esse projeto para comparar a média de bicicletas alugadas por horário do dia (manhã, tarde e noite) nas quatro estações do ano, ver como a temperatura influencia o número de bicicletas alugadas e muito mais. Quando for o caso, coloque visualizações interessantes para apoiar suas descobertas.
É sempre uma boa ideia ter no seu portfólio pelo menos um projeto que mostre sua habilidade de aplicar abordagens de aprendizado não supervisionado.
Para isso, dá uma olhada no conjunto de dados de comércio eletrônico, que tem compras feitas em uma loja online do Reino Unido por clientes de vários países durante um certo tempo.
Um cenário especulativo aqui é que o varejista quer fazer um inventário dos itens disponíveis. Como um provável cientista de dados que trabalha nesta empresa, você precisa agrupar os produtos em um pequeno número de categorias de acordo com sua semelhança por algumas características comuns (preço, quantidade vendida, etc.). Esse é um problema de agrupamento de aprendizado não supervisionado, com o k-means como o algoritmo mais popular.
Você também pode analisar outras questões, como quais são os cinco países responsáveis pela maior parte do lucro ou se os tamanhos dos pedidos de países fora do Reino Unido são significativamente maiores do que os pedidos dentro do Reino Unido.
Por fim, pense em usar suas habilidades de processamento de linguagem natural (NLP) em R em um dos seus projetos.
O conjunto de dados SMS Spam Collection tem mais de 5.500 mensagens em inglês marcadas como spam ou não spam (“ham”).
Com base nesses dados, crie um filtro que consiga diferenciar com precisão entre spam e mensagens normais. Pra fazer isso, você vai precisar usar um pacote de PNL do R (por exemplo, koRpus) pra procurar padrões linguísticos e contextuais no texto das mensagens e descobrir o que faz uma mensagem ser spam ou ham, pra depois generalizar essas observações nos novos dados.
Se quiser, você pode descobrir quais são as palavras mais comuns em spam criando uma visualização em forma de nuvem de palavras.
Pra fechar, a gente falou sobre por que é importante montar um portfólio de projetos pra começar uma carreira em ciência de dados, por que e como usar o R pra análise de dados e ciência de dados, onde achar dados relevantes e exemplos de projetos em R, e quais tópicos você pode desenvolver nesses projetos, seja você um iniciante ou um aluno avançado em ciência de dados.
Claro, as ideias sugeridas para seus projetos são só a ponta do iceberg. Com o R, você pode fazer muito mais: criar sistemas de recomendação, fazer segmentação de clientes, prever taxas de câmbio, fazer análise de opinião dos clientes, identificar o melhor posicionamento dos táxis e muitas outras coisas.
Se você quer ser um cientista de dados com R, um analista de dados com R, um cientista de machine learning com R ou um estatístico com R, mostrar suas habilidades em projetos práticos é super importante. A biblioteca enorme e o suporte da comunidade do R fazem dele uma escolha ideal para análise de dados, machine learning e computação estatística avançada.
Começando com projetos simples e enfrentando desafios cada vez mais complexos, você pode construir um portfólio que não só mostra sua habilidade técnica, mas também sua capacidade de tirar conclusões significativas a partir dos dados. Essa experiência prática não só vai impressionar possíveis empregadores, mas também te preparar para os desafios variados e dinâmicos que você vai enfrentar na sua carreira em ciência de dados.
Para mais inspiração, dá uma olhada no DataLab, um IDE online com conjuntos de dados pré-carregados e modelos pré-definidos para escrever código e analisar dados, que te ajuda a passar do aprendizado para a prática da ciência de dados.
Cursos para R
Curso
Curso
Curso
blog
Bekhruz Tuychiev
15 min
blog
Summer Worsley
15 min
blog
Mark Graus
15 min
blog
Javier Canales Luna
13 min
Tutorial
Adel Nehme
