Curso
Python intermediário
4 h
1.4M
A grande contribuição dos pesquisadores em PNL, abreviação de Processamento de Linguagem Natural, nas últimas décadas tem gerado resultados inovadores em diferentes domínios. Abaixo estão alguns exemplos de processamento de linguagem natural na prática:
Este blog conceitual tem como objetivo abordar os Transformers, um dos modelos mais poderosos já criados no Processamento de Linguagem Natural. Depois de explicar seus benefícios em comparação com as redes neurais recorrentes, você entenderá melhor os Transformers. Em seguida, orientaremos você em alguns cenários de casos do mundo real usando transformadores Huggingface.
Você também pode saber mais sobre a criação de aplicativos de PNL com o Hugging Face com nosso code-along.
Antes de mergulhar no conceito central dos transformadores, vamos entender brevemente o que são modelos recorrentes e suas limitações.
As redes recorrentes empregam a arquitetura codificador-decodificador, e nós as usamos principalmente quando lidamos com tarefas em que tanto a entrada quanto as saídas são sequências em alguma ordem definida. Algumas das maiores aplicações das redes recorrentes são a tradução automática e a modelagem de dados de séries temporais.
Vamos considerar a tradução da seguinte frase em francês para o inglês. A entrada transmitida ao codificador é a frase original em francês, e a saída traduzida é gerada pelo decodificador.
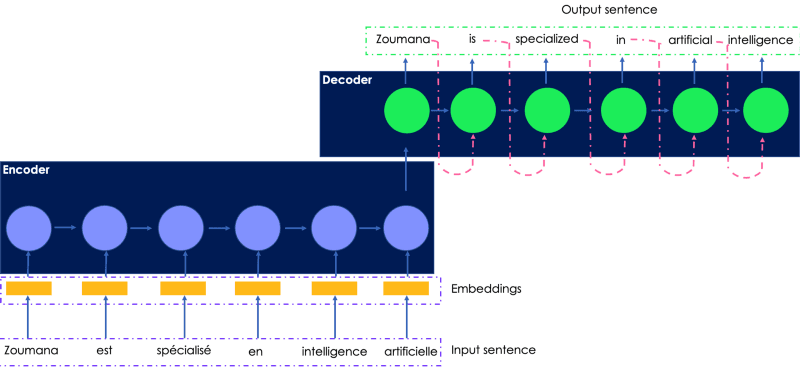
Uma ilustração simples da rede recorrente para tradução de idiomas
Não seria ótimo ter um modelo que combinasse os benefícios das redes recorrentes e possibilitasse a computação paralela?
É aqui que os transformadores são úteis.
Transformers é a nova arquitetura de rede neural simples, porém poderosa, introduzida pelo Google Brain em 2017 com seu famoso trabalho de pesquisa "Attention is all you need". Ele se baseia no mecanismo de atenção em vez da computação sequencial, como podemos observar nas redes recorrentes.
Semelhante às redes recorrentes, os transformadores também têm dois blocos principais: codificador e decodificador, cada um com um mecanismo de autoatenção. A primeira versão dos transformadores tinha arquitetura de codificador-decodificador RNN e LSTM, que foi alterada posteriormente para redes de autoatenção e feed-forward.
A seção a seguir apresenta uma visão geral dos principais componentes de cada bloco de transformadores.
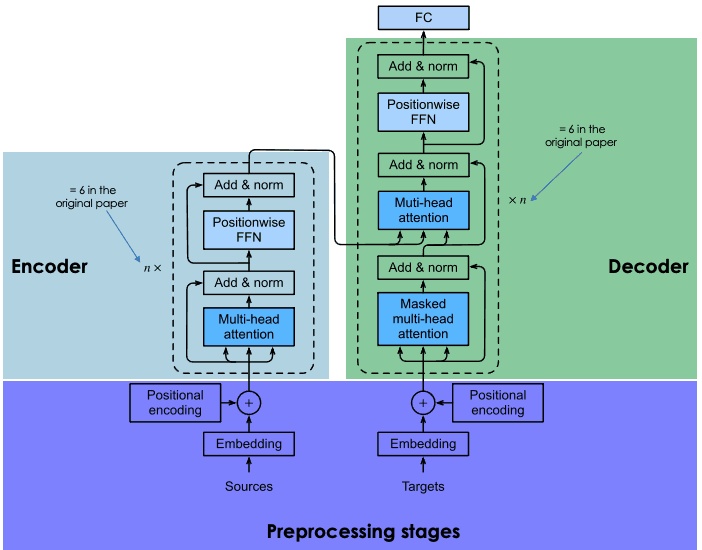
Arquitetura geral de transformadores (adaptado pelo autor)
Esta seção contém duas etapas principais: (1) a geração dos embeddings da sentença de entrada e (2) o cálculo do vetor posicional de cada palavra na sentença de entrada. Todos os cálculos são realizados da mesma forma para a frase de origem (antes do bloco do codificador) e para a frase de destino (antes do bloco do decodificador).
Antes de gerar os embeddings dos dados de entrada, começamos com a tokenização e, em seguida, criamos o embedding de cada palavra individual sem prestar atenção ao relacionamento entre elas na frase.
A tarefa de tokenização descarta qualquer noção de relações existentes na frase de entrada. A codificação posicional tenta criar a natureza cíclica original gerando um vetor de contexto para cada palavra.
No final da etapa anterior, obtemos dois vetores para cada palavra: (1) a incorporação e (2) seu vetor de contexto. Esses vetores são adicionados para criar um único vetor para cada palavra, que é então transmitido ao codificador.
Conforme mencionado anteriormente, perdemos toda a noção de um relacionamento. O objetivo da camada de atenção é capturar as relações contextuais existentes entre diferentes palavras na frase de entrada. Essa etapa acaba gerando um vetor de atenção para cada palavra.
Nesse estágio, uma rede neural feed-forward é aplicada a cada vetor de atenção para transformá-lo em um formato esperado pela próxima camada de atenção de várias cabeças no decodificador.
O bloco do decodificador é composto por três camadas principais: atenção multi-cabeça mascarada, atenção multi-cabeça e uma rede de alimentação por posição. Já entendemos as duas últimas camadas, que são as mesmas no codificador.
O decodificador entra na equação durante o treinamento da rede e recebe duas entradas principais: (1) os vetores de atenção da frase de entrada que queremos traduzir e (2) as frases-alvo traduzidas em inglês.
Durante a geração da próxima palavra em inglês, a rede tem permissão para usar todas as palavras da palavra em francês. No entanto, ao lidar com uma determinada palavra na sequência de destino (tradução para o inglês), a rede só precisa acessar as palavras anteriores, pois disponibilizar as próximas fará com que a rede "trapaceie" e não se esforce para aprender adequadamente. É aqui que a camada de atenção com várias cabeças mascaradas tem todos os seus benefícios. Ele mascara as próximas palavras, transformando-as em zeros para que não possam ser usadas pela rede de atenção.
O resultado da camada de atenção multicabeça mascarada passa pelo restante das camadas para prever a próxima palavra, gerando uma pontuação de probabilidade.
Essa arquitetura foi bem-sucedida pelos seguintes motivos:
Treinar redes neurais profundas, como transformadores, do zero não é uma tarefa fácil e pode apresentar os seguintes desafios:
O uso da aprendizagem por transferência pode trazer muitos benefícios, como a redução do tempo de treinamento, a aceleração do processo de treinamento de novos modelos e a diminuição do tempo de entrega do projeto.
Imagine criar um modelo do zero para traduzir o idioma Mandingo para Wolof, que são idiomas com poucos recursos. A coleta de dados relacionados a esses idiomas é cara. Em vez de passar por todos esses desafios, você pode reutilizar redes neurais profundas pré-treinadas como ponto de partida para treinar o novo modelo.
Esses modelos foram treinados em um enorme corpus de dados, disponibilizados por outra pessoa (pessoa moral, organização etc.), e avaliados para funcionar muito bem em tarefas de tradução de idiomas, como francês para inglês.
Se você é novo em PNL, este curso de Introdução ao Processamento de Linguagem Natural em Python pode fornecer as habilidades fundamentais para executar e resolver problemas do mundo real.
Mas o que você quer dizer com reutilização de redes neurais profundas?
A reutilização do modelo envolve a escolha do modelo pré-treinado que seja semelhante ao seu caso de uso, o refinamento dos dados do par entrada-saída da tarefa de destino e o retreinamento da cabeça do modelo pré-treinado usando seus dados.
A introdução dos Transformers levou ao desenvolvimento de modelos de aprendizagem por transferência de última geração, como o Transformers:
A Hugging Face é uma comunidade de IA e uma plataforma de aprendizado de máquina criada em 2016 por Julien Chaumond, Clément Delangue e Thomas Wolf. Seu objetivo é democratizar a PNL, fornecendo aos cientistas de dados, profissionais de IA e engenheiros acesso imediato a mais de 20.000 modelos pré-treinados com base na arquitetura de transformador de última geração. Esses modelos podem ser aplicados a você:
O Hugging Face Transformers também oferece quase 2.000 conjuntos de dados e APIs em camadas, permitindo que os programadores interajam facilmente com esses modelos usando quase 31 bibliotecas. A maioria deles é de aprendizagem profunda, como Pytorch, Tensorflow, Jax, ONNX, Fastai, Stable-Baseline 3, etc.
Esses cursos são uma ótima introdução ao uso do Pytorch e do Tensorflow para a criação de redes neurais convolucionais profundas, respectivamente. Outros componentes dos transformadores Hugging Face são os dutos.
O método pipeline() tem a seguinte estrutura:
from transformers import pipeline
# To use a default model & tokenizer for a given task(e.g. question-answering)
pipeline("<task-name>")
# To use an existing model
pipeline("<task-name>", model="<model_name>")
# To use a custom model/tokenizer
pipeline('<task-name>', model='<model name>',tokenizer='<tokenizer_name>')Agora que você tem uma melhor compreensão dos Transformers e da plataforma Hugging Face, vamos orientá-lo nos seguintes cenários do mundo real: tradução de idiomas, classificação de sequências com classificação de zero-shot, análise de sentimentos e resposta a perguntas.
Esse conjunto de dados está disponível no Datacamp's O conjunto de dados é enriquecido pelo Facebook e foi criado para prever a popularidade de um artigo antes de sua publicação. A análise será baseada na coluna de descrição. Para ilustrar nossos exemplos, usaremos apenas três exemplos dos dados.
Abaixo você encontra uma breve descrição dos dados. Ele tem 14 colunas e 1428 linhas.
import pandas as pd
# Load the data from the path
data_path = "datacamp_workspace_export_2022-08-08 07_56_40.csv"
news_data = pd.read_csv(data_path, error_bad_lines=False)
# Show data information
news_data.info()
O MariamMT é uma estrutura eficiente de tradução automática. Ele usa o mecanismo MarianNMT, que é desenvolvido exclusivamente em C++ pela Microsoft e por várias instituições acadêmicas, como a Universidade de Edimburgo e a Universidade Adam Mickiewicz, em Poznań. O mesmo mecanismo está atualmente por trás do serviço Microsoft Translator.
O grupo de NLP da Universidade de Helsinque abriu vários modelos de tradução em Hugging Face Transformers e todos eles estão no seguinte formato: Helsinki-NLP/opus-mt-{src}-{tgt}, em que {src} e {tgt} correspondem, respectivamente, aos idiomas de origem e de destino.
Portanto, em nosso caso, o idioma de origem é o inglês (en) e o idioma de destino é o francês (fr)
O MarianMT é um desses modelos treinados anteriormente usando o Marian em dados paralelos coletados no Opus.
pip install transformers sentencepiece
from transformers import MarianTokenizer, MarianMTModel# Get the name of the model
model_name = 'Helsinki-NLP/opus-mt-en-fr'
# Get the tokenizer
tokenizer = MarianTokenizer.from_pretrained(model_name)
# Instantiate the model
model = MarianMTModel.from_pretrained(model_name)def format_batch_texts(language_code, batch_texts):
formated_bach = [">>{}<< {}".format(language_code, text) for text in
batch_texts]
return formated_bachdef perform_translation(batch_texts, model, tokenizer, language="fr"):
# Prepare the text data into appropriate format for the model
formated_batch_texts = format_batch_texts(language, batch_texts)
# Generate translation using model
translated = model.generate(**tokenizer(formated_batch_texts,
return_tensors="pt", padding=True))
# Convert the generated tokens indices back into text
translated_texts = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
return translated_texts# Check the model translation from the original language (English) to French
translated_texts = perform_translation(english_texts, trans_model, trans_model_tkn)
# Create wrapper to properly format the text
from textwrap import TextWrapper
# Wrap text to 80 characters.
wrapper = TextWrapper(width=80)
for text in translated_texts:
print("Original text: \n", text)
print("Translation : \n", text)
print(print(wrapper.fill(text)))
print("")
Na maioria das vezes, o treinamento de um modelo de aprendizado de máquina exige que todos os rótulos/alvos candidatos sejam conhecidos de antemão, o que significa que, se os rótulos de treinamento forem ciência, política ou educação, você não conseguirá prever o rótulo de saúde a menos que treine novamente o modelo, levando em consideração esse rótulo e os dados de entrada correspondentes.
Essa abordagem avançada permite prever o destino de um texto em cerca de 15 idiomas sem ter visto nenhum dos rótulos candidatos. Você pode usar esse modelo simplesmente carregando-o do hub.
O objetivo aqui é tentar classificar a categoria de cada uma das descrições anteriores, seja ela tecnologia, política, segurança ou finanças.
from transformers import pipelinecandidate_labels = ["tech", "politics", "business", "finance"]my_classifier = pipeline("zero-shot-classification",
model='joeddav/xlm-roberta-large-xnli')#For the first description
prediction = my_classifier(english_texts[0], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)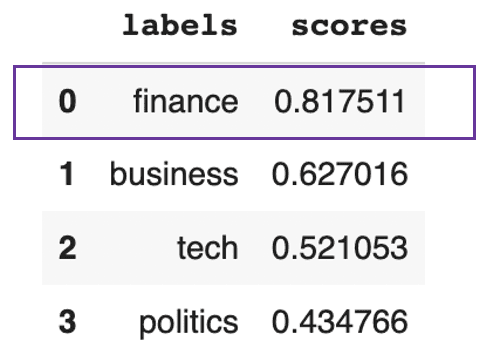
Texto previsto para ser principalmente sobre finanças
Esse resultado anterior mostra que o texto é, em geral, sobre finanças, com 81%.
Para a última descrição, obtemos o seguinte resultado:
#For the last description
prediction = my_classifier(english_texts[-1], candidate_labels, multi_class = True)
pd.DataFrame(prediction).drop(["sequence"], axis=1)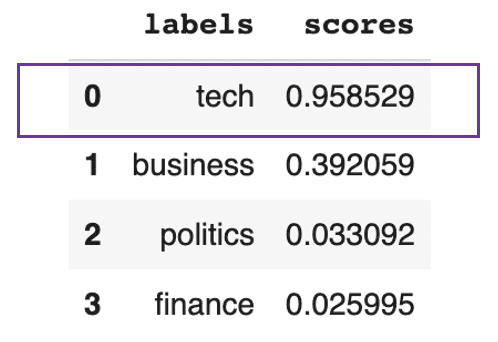
Texto previsto para ser principalmente sobre tecnologia
Esse resultado anterior mostra que o texto é, em geral, cerca de 95% técnico.
A maioria dos modelos que realizam a classificação de sentimentos exige treinamento adequado. O módulo de pipeline hugging Face facilita a execução de previsões de análise de sentimentos usando um modelo específico disponível no hub, especificando seu nome.
model_checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
distil_bert_model = pipeline(task="sentiment-analysis", model=model_checkpoint)# Run the predictions
distil_bert_model(english_texts[1:])
O modelo previu que o primeiro texto teria um sentimento negativo com 96% de confiança, e o segundo previu um sentimento positivo com 52% de confiança.
Se você quiser explorar mais as tarefas de análise de sentimentos, este curso de análise de sentimentos em Python ajudará você a adquirir as habilidades necessárias para criar seu próprio classificador de análise de sentimentos usando Python e entender os fundamentos da PNL.
Imagine você lidando com um relatório muito mais longo do que aquele sobre a Apple. E tudo o que você está interessado é na data do evento que está sendo mencionado. Em vez de ler todo o relatório para encontrar as principais informações, podemos usar um modelo de pergunta-resposta da Hugging Face que fornecerá a resposta na qual estamos interessados.
Isso pode ser feito fornecendo ao modelo o contexto adequado (relatório da Apple) e a pergunta para a qual estamos interessados em encontrar a resposta.
from transformers import AutoModelForQuestionAnswering, AutoTokenizermodel_checkpoint = "deepset/roberta-base-squad2"
task = 'question-answering'
QA_model = pipeline(task, model=model_checkpoint, tokenizer=model_checkpoint)QA_input = {
'question': 'when is Apple hosting an event?',
'context': english_texts[-1]
}model_response = QA_model(QA_input)
pd.DataFrame([model_response])
O modelo respondeu que o evento da Apple será em 10 de setembro com alta confiança de 97%.
Neste artigo, abordamos a evolução da tecnologia de linguagem natural, desde as redes recorrentes até os transformadores, e como a Hugging Face democratizou o uso da PNL por meio de sua plataforma.
Se você ainda hesita em usar transformadores, acreditamos que é hora de experimentá-los e agregar valor aos seus casos de negócios.
Cursos para Python
Curso
Curso
Curso
Tutorial
Bex Tuychiev
Tutorial
Tutorial
Natassha Selvaraj
Tutorial
Zoumana Keita
Tutorial
Moez Ali

