
Curso
Preparação de dados no Excel
3 h
85.3K
Se você costuma trabalhar com probabilidades e estatísticas no Excel, é bem provável que, mais cedo ou mais tarde, você encontre a função NORM.DIST(). Essa ferramenta essencial é fundamental para quem analisa distribuições normais, seja pra fazer controle de qualidade, avaliar notas de testes ou analisar dados comerciais. Com NORM.DIST(), você pode facilmente calcular a probabilidade de um valor específico aparecer em uma distribuição normal.
Neste guia, vamos começar entendendo o que o comando ` NORM.DIST() ` realmente faz, depois vamos explicar a sintaxe dele, esclarecer opções importantes e ver exemplos práticos. No final, você vai saber exatamente como usar essa função e onde ela se encaixa no seu kit de ferramentas do Excel.
Antes de entrarmos em detalhes sobre como usar NORM.DIST(), vamos esclarecer sua finalidade. NORM.DIST() calcula a probabilidade de um valor extraído de uma distribuição normal ser menor ou igual a um número especificado. Dependendo do que você precisa, dá pra usar isso pra ver a densidade de probabilidade (a altura da curva num ponto específico) ou a probabilidade acumulada até esse valor.
Então, se você quer saber qual é a chance de tirar uma nota abaixo de um certo número ou só precisa do valor da curva normal em um ponto, essa função é perfeita pra você. Agora, vamos ver o que tem nessa função e como você pode configurá-la na sua planilha.
Agora que você já tem uma ideia do que é o NORM.DIST(), vamos ver como usá-lo no Excel. Aqui tá a sintaxe da função:
=NORM.DIST(x, mean, standard_dev, cumulative)Analisando cada argumento:
x: O valor que você quer distribuir.
mean: A média (média) da distribuição.
standard_dev: O desvio padrão da distribuição.
cumulative: Um valor lógico — use TRUE se quiser a função de distribuição cumulativa (CDF) ou FALSE se quiser a função de densidade de probabilidade (PDF).
Pra entender melhor, imagina que você quer saber a chance de um valor ser menor ou igual a 80 numa distribuição normal com média de 70 e desvio padrão de 10. A fórmula ficaria assim:
=NORM.DIST(80, 70, 10, TRUE)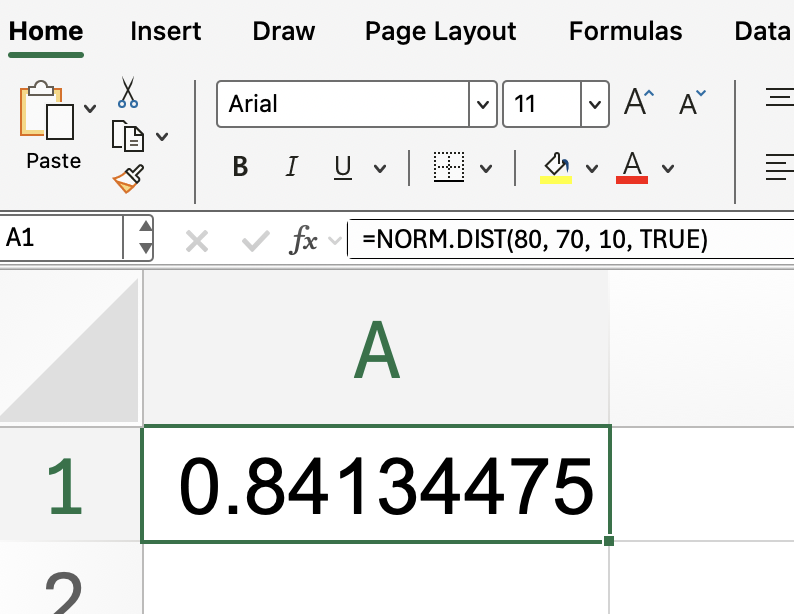
Essa configuração mostra a probabilidade acumulada até 80.
Agora que você já sabe como configurar a função, talvez esteja se perguntando sobre as duas principais opções para o argumento final: cumulativa e densidade de probabilidade. Entender a diferença é essencial pra conseguir os resultados que você quer.
Acumulativo (VERDADEIRO): Quando você define o último argumento como “ TRUE ”, “ NORM.DIST() ” mostra a chance de um valor ser menor ou igual a x. Essa é a opção mais comum para análise estatística, pois responde a perguntas como “Qual porcentagem dos alunos tirou nota 85 ou menos?”
Densidade de probabilidade (FALSO): Quando você escolhe FALSE, a função mostra a altura da curva normal em x. Isso não é uma probabilidade, mas sim o valor da curva nesse ponto — útil principalmente em modelagem estatística ou teoria da probabilidade.
Saber quando usar cada opção vai te ajudar a entender o resultado da função direitinho. Agora, vamos ver as duas opções em ação com exemplos práticos.
Para consolidar essas ideias, vamos analisar dois cenários práticos — um usando a probabilidade cumulativa e outro usando a densidade de probabilidade.
Lembre-se do nosso exemplo anterior. Não custa nada praticar de novo. Digamos que você queira saber a chance de algo como uma nota em um teste ser menor ou igual a 85, supondo que as notas sejam distribuídas normalmente com média de 75 e desvio padrão de 8:
=NORM.DIST(85, 75, 8, TRUE)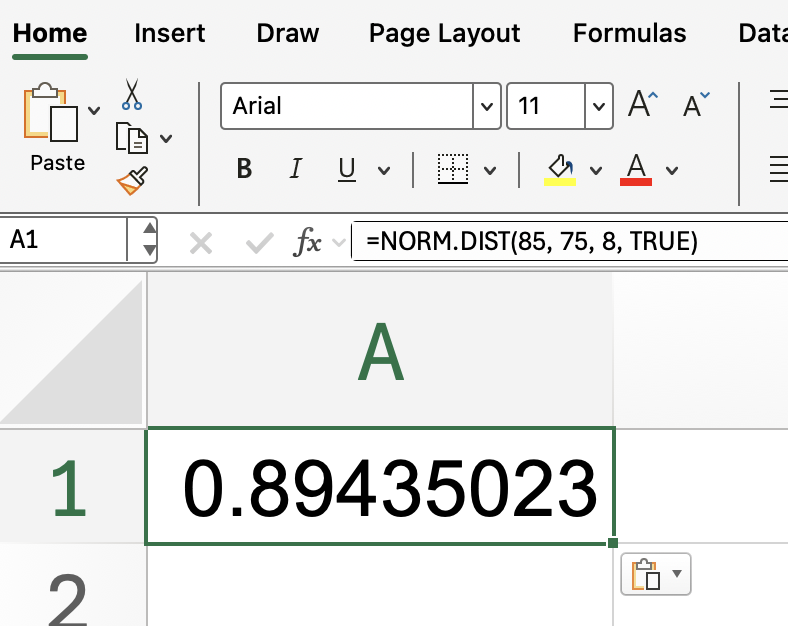
O Excel vai mostrar um valor perto de 0,894, o que quer dizer que cerca de 89,4% dos alunos tiraram nota 85 ou menos. Essa é uma maneira simples de ver como uma determinada pontuação é comum nos seus dados.
Mas e se você estiver interessado na altura da curva em um valor específico, em vez da probabilidade cumulativa? Nesse caso, defina cumulativo como FALSE:
=NORM.DIST(85, 75, 8, FALSE)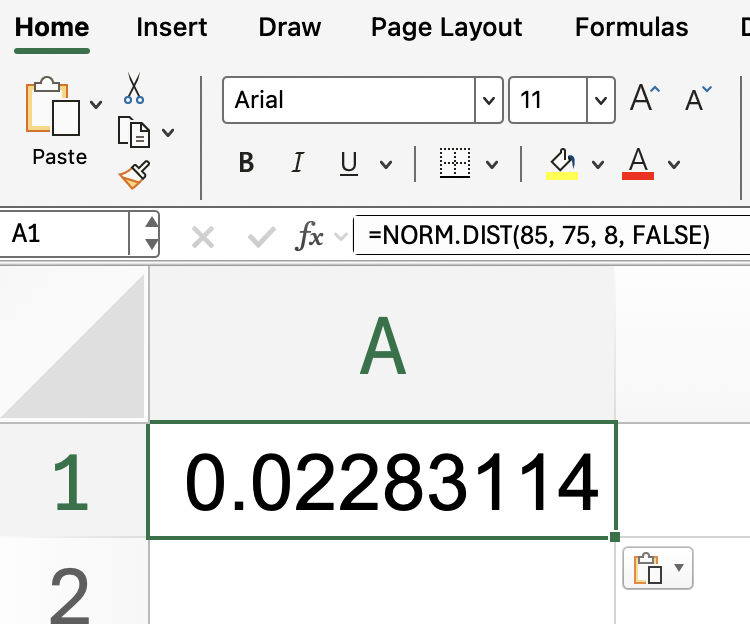
Isso te dá a densidade de probabilidade em 85. Lembre-se, isso não é uma probabilidade, mas o valor da curva normal nesse ponto.
Então agora você sabe que NORM.DIST() pode ser usado tanto para encontrar a probabilidade cumulativa para um determinado valor quanto para encontrar a altura da curva nesse valor. Vou mostrar uma última tabela que junta todas essas ideias.
A tabela abaixo mostra como o NORM.DIST() funciona quando você alterna entre os modos cumulativo e densidade de probabilidade. Você vai ver como as entradas afetam a saída e o que cada resultado realmente quer dizer.
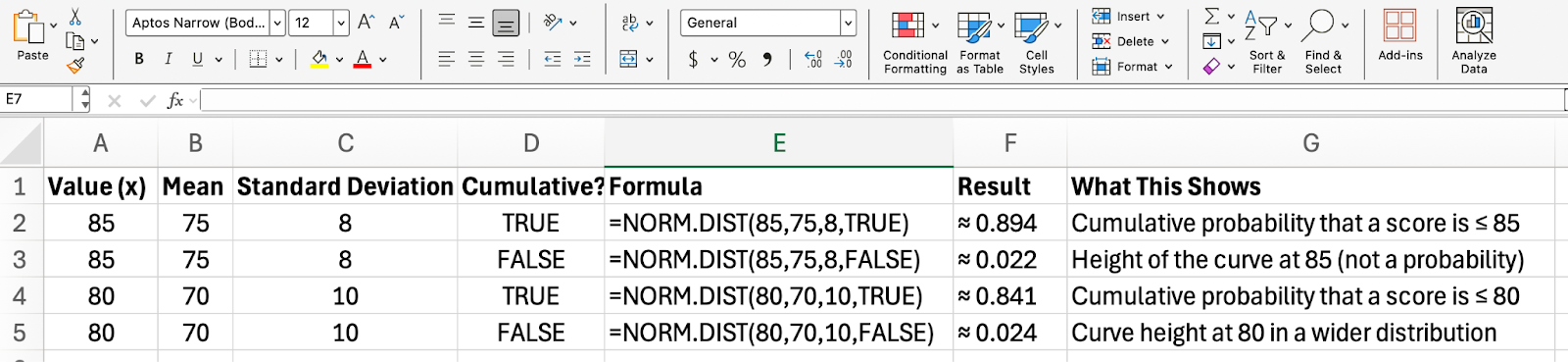
Quando você começar a aplicar o algoritmo de classificação por divisão ( NORM.DIST() ) a dados reais, é bom ficar de olho em algumas armadilhas comuns:
O desvio padrão precisa ser positivo. Se você colocar zero ou um número negativo no desvio padrão, vai aparecer um erro.
Flexibilidade da média e do desvio padrão. Enquanto a média pode ser qualquer número real, o desvio padrão precisa ser sempre positivo — nunca zero ou negativo.
Está indo na direção errada? Se você precisa encontrar o valor que corresponde a uma probabilidade dada (em vez da probabilidade para um valor dado), use NORM.INV() em vez disso.
Com essas dicas em mente, você vai evitar os erros mais comuns e fazer seus cálculos com mais tranquilidade. A seguir, vamos ver como funciona o “ NORM.DIST() ” numa curva em forma de sino pra entender melhor.
Agora que você já viu as fórmulas em ação, é legal visualizar o que está rolando nos bastidores. Dá uma olhada nessa ilustração:
Coloque uma tabela direto na sua planilha do Excel. Em uma nova planilha ou abaixo da tabela, crie três colunas:
Um com a etiqueta x. No meu exemplo, eu fiz os valores de 60 a 90 em passos de 1.
Um para os valores acumulados: =NORM.DIST(x_cell,75,8,TRUE)
Um para o Probabilidade : : =NORM.DIST(x_cell,75,8,FALSE)
Depois, faz o gráfico:
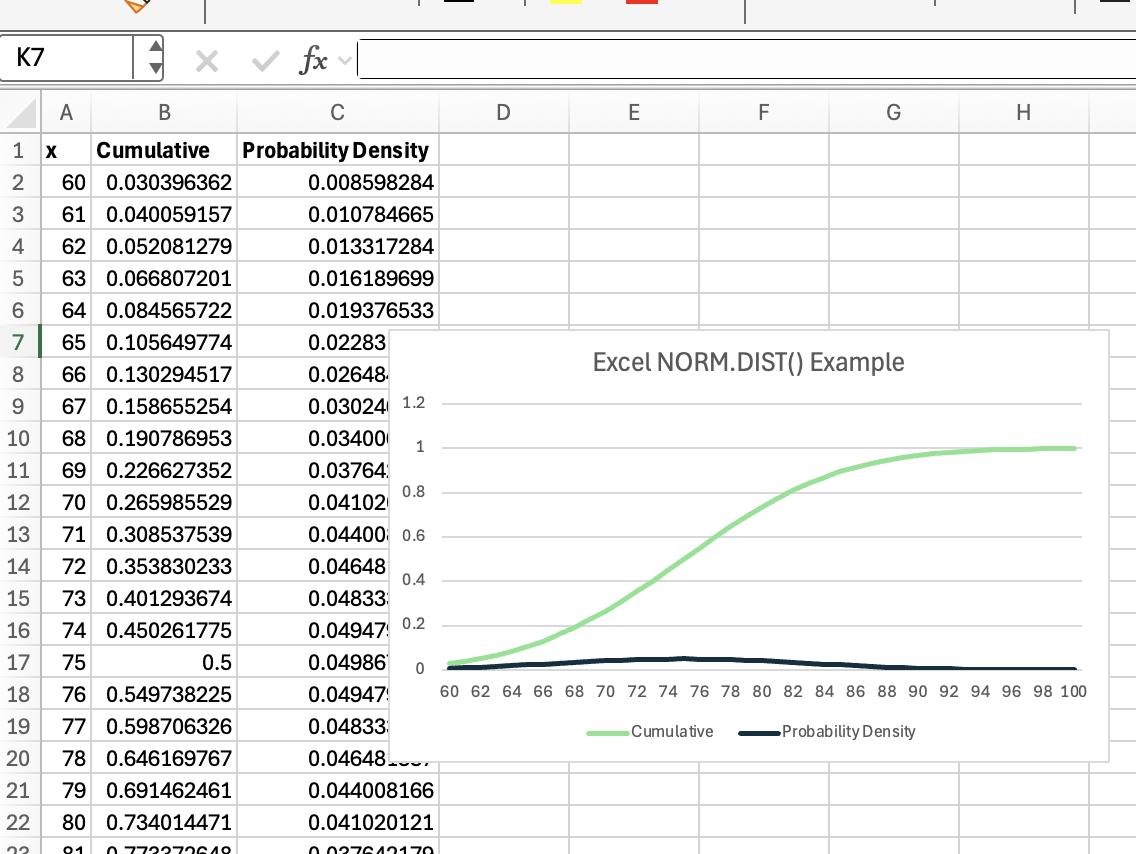
Nessa curva em forma de sino, a área sombreada sob a curva até x representa a probabilidade acumulada que você obtém ao usar cumulative = TRUE. Enquanto isso, a altura da curva em x mostra a densidade de probabilidade que você recebe quando cumulative = FALSE.
A gente já praticou o NORM.DIST(), mas talvez você precise de outras ferramentas relacionadas:
NORM.INV(): Retorna o valor para uma determinada probabilidade cumulativa (o inverso de NORM.DIST()).
NORM.S.DIST(): Calcula as probabilidades usando a distribuição normal padrão (média 0, desvio padrão 1).
NORM.S.INV(): Retorna o valor para uma determinada probabilidade i ee n na distribuição normal padrão.
Essas funções são super úteis quando você tá trabalhando com dados padronizados ou precisa alternar entre probabilidades e valores. Se você estiver lidando com tarefas estatísticas mais complexas, considere explorar estas opções relacionadas.
Agora você já viu como a regressão linear ( NORM.DIST() ) se encaixa em qualquer análise de dados que envolva a distribuição normal. Se você está calculando a chance de um valor ficar abaixo de um certo limite ou analisando o formato da distribuição, essa função deixa seu trabalho mais preciso.
Depois, dá uma olhada no nossocurso Análise de Dados no Excel pra continuar aprimorando suas habilidades.
Aprenda Excel com o DataCamp
Curso
Curso
Curso
Tutorial
Joleen Bothma
Tutorial
Abid Ali Awan
Tutorial
Avinash Navlani
Tutorial
Travis Tang
Tutorial
Chloe Lubin

