
Programa
Processamento de imagens em Python
12 h
A extração manual de texto de imagens e documentos pode ser muito tediosa e demorada. Felizmente, o OCR (Optical Character Recognition, reconhecimento óptico de caracteres) pode automatizar esse processo, permitindo que você converta essas imagens em arquivos de texto editáveis e pesquisáveis.
As técnicas que você está prestes a aprender podem ser aplicadas em muitos aplicativos:
O tutorial se concentrará no mecanismo de OCR do Tesseract e em sua API Python - PyTesseract. Antes de começarmos a escrever o código, vamos analisar brevemente algumas das bibliotecas populares dedicadas ao OCR.
Como o OCR é um problema popular e contínuo, muitas bibliotecas de código aberto tentam resolvê-lo. Nesta seção, abordaremos os que ganharam mais popularidade devido ao seu alto desempenho e precisão.
O Tesseract OCR é um mecanismo de reconhecimento óptico de caracteres de código aberto que é o mais popular entre os desenvolvedores. Como as outras ferramentas desta lista, o Tesseract pode pegar imagens de texto e convertê-las em texto editável.
O EasyOCR é uma biblioteca Python projetada para o reconhecimento óptico de caracteres (OCR) sem esforço. Ele faz jus ao seu nome, oferecendo uma abordagem fácil de usar para a extração de texto de imagens.
O Keras-OCR é uma biblioteca Python criada com base no Keras, uma estrutura popular de aprendizagem profunda. Ele fornece modelos de OCR prontos para uso e um pipeline de treinamento de ponta a ponta para criar novos modelos de OCR.
Aqui está uma tabela que resume suas diferenças, vantagens e desvantagens:
|
Nome do pacote |
Vantagem |
Desvantagens |
|
Tesseract (pytesseract) |
Maduro, amplamente utilizado, com amplo suporte |
Mais lento e com menor precisão em layouts complexos |
|
EasyOCR |
Simples de usar, vários modelos |
Menor precisão, personalização limitada |
|
Keras-OCR |
Maior precisão, personalizável |
Requer GPU, curva de aprendizado mais acentuada |
Neste tutorial, vamos nos concentrar em PyTesseract, que é a API Python do Tesseract. Aprenderemos a extrair texto de imagens simples, a desenhar caixas delimitadoras ao redor do texto e a realizar um estudo de caso com um documento digitalizado.
O PyTesseract funciona com base no mecanismo oficial do Tesseract, que é um software CLI separado. Antes de instalar o pytesseract, você deve ter o mecanismo instalado. Abaixo estão as instruções de instalação para diferentes plataformas.
Para Ubuntu ou WSL2 (minha escolha):
$ sudo apt update && sudo apt upgrade
$ sudo apt install tesseract-ocr
$ sudo apt install libtesseract-dev
Para Mac usando o Homebrew:
$ brew install tesseract
Para Windows, siga as instruções desta página do GitHub.
Em seguida, crie um novo ambiente virtual. Usarei o Conda:
$ conda create -n ocr python==3.9 -y
$ conda activate ocr
Em seguida, você deve instalar o pytesseract para fazer OCR e o opencv para manipulação de imagens:
$ pip install pytesseract
$ pip install opencv-python
Se você estiver seguindo este tutorial no Jupyter, execute esses comandos na mesma sessão de terminal para que seu novo ambiente virtual seja adicionado como um kernel:
$ pip install ipykernel
$ ipython kernel install --user --name=ocr
Agora, podemos começar a escrever o código.
Começamos importando as bibliotecas necessárias:
import cv2
import pytesseract
Nossa tarefa é ler o texto da imagem a seguir:

Primeiro, definimos o caminho da imagem e o alimentamos com a função cv2.imread:
# Read image
easy_text_path = "images/easy_text.png"
easy_img = cv2.imread(easy_text_path)
Em seguida, passamos a imagem carregada para a função image_to_string de pytesseract para extrair o texto:
# Convert to text
text = pytesseract.image_to_string(easy_img)
print(text)
This text is
easy to extract.
É tão fácil quanto isso! Vamos converter o que acabamos de fazer em uma função:
def image_to_text(input_path):
"""
A function to read text from images.
"""
img = cv2.imread(input_path)
text = pytesseract.image_to_string(img)
return text.strip()
Vamos usar a função em uma imagem mais difícil:

A imagem oferece um desafio maior, pois há mais símbolos de pontuação e texto em fontes diferentes.
# Define image path
medium_text_path = "images/medium_text.png"
# Extract text
extracted_text = image_to_text(medium_text_path)
print(extracted_text)
Home > Tutorials » Data Engineering
Snowflake Tutorial For Beginners:
From Architecture to Running
Databases
Learn the fundamentals of cloud data warehouse management using
Snowflake. Snowflake is a cloud-based platform that offers significant
benefits for companies wanting to extract as much insight from their data as
quickly and efficiently as possible.
Jan 2024 - 12 min read
Nossa função funcionou quase perfeitamente. Você confundiu um dos pontos e os sinais ">", mas o resultado é aceitável.
Uma operação comum no OCR é desenhar caixas delimitadoras ao redor do texto. Essa operação é compatível com o PyTesseract.
Primeiro, passamos uma imagem carregada para a função image_to_data:
from pytesseract import Output
# Extract recognized data from easy text
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
A parte Output.DICT garante que os detalhes da imagem sejam retornados como um dicionário. Vamos dar uma olhada no interior:
data{'level': [1, 2, 3, 4, 5, 5, 5, 4, 5, 5, 5],
'page_num': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'block_num': [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'par_num': [0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'line_num': [0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
'word_num': [0, 0, 0, 0, 1, 2, 3, 0, 1, 2, 3],
'left': [0, 41, 41, 236, 236, 734, 1242, 41, 41, 534, 841],
'top': [0, 68, 68, 68, 68, 80, 68, 284, 309, 284, 284],
'width': [1658, 1550, 1550, 1179, 380, 383, 173, 1550, 381, 184, 750],
'height': [469, 371, 371, 128, 128, 116, 128, 155, 130, 117, 117],
'conf': [-1, -1, -1, -1, 96, 95, 95, -1, 96, 96, 96],
'text': ['', '', '', '', 'This', 'text', 'is', '', 'easy', 'to', 'extract.']}
O dicionário contém muitas informações sobre a imagem. Primeiro, observe as teclas conf e text. Ambos têm um comprimento de 11:
len(data["text"])11Isso significa que pytesseract desenhou 11 caixas. O conf significa confiança. Se for igual a -1, a caixa correspondente será desenhada em torno de blocos de texto em vez de palavras individuais.
Por exemplo, se você observar os quatro primeiros valores de width e height, eles são grandes em comparação com o restante porque essas caixas são desenhadas ao redor de todo o texto no meio, depois para cada linha de texto e para a própria imagem geral.
Also:
left é a distância do canto superior esquerdo da caixa delimitadora até a borda esquerda da imagem.top é a distância do canto superior esquerdo da caixa delimitadora até a borda superior da imagem.width e height são a largura e a altura da caixa delimitadora.Usando essas informações, vamos desenhar as caixas na parte superior da imagem no OpenCV.
Primeiro, extraímos os dados novamente e seu comprimento:
from pytesseract import Output
# Extract recognized data
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
n_boxes = len(data["text"])
Em seguida, criamos um loop para o número de caixas encontradas:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
Dentro do loop, criamos uma condição que ignora a iteração do loop atual se conf for igual a -1. Ignorar caixas delimitadoras maiores manterá nossa imagem limpa.
Em seguida, definimos as coordenadas da caixa atual, especificamente os locais dos cantos superior esquerdo e inferior direito:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
Depois de definir alguns parâmetros da caixa, como a cor e a espessura da caixa em pixels, passamos todas as informações para a função cv2.rectangle:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 3 # pixels
cv2.rectangle(
img=easy_img, pt1=top_left, pt2=bottom_right, color=green, thickness=thickness
)
A função desenhará as caixas em cima das imagens originais. Vamos salvar a imagem e dar uma olhada:
# Save the image
output_image_path = "images/text_with_boxes.jpg"
cv2.imwrite(output_image_path, easy_img)
True
O resultado é exatamente o que você queria!
Agora, vamos colocar tudo o que fizemos em uma função novamente:
def draw_bounding_boxes(input_img_path, output_path):
img = cv2.imread(input_img_path)
# Extract data
data = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(data["text"])
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 1 # The function-version uses thinner lines
cv2.rectangle(img, top_left, bottom_right, green, thickness)
# Save the image with boxes
cv2.imwrite(output_path, img)
E use a função no texto de dureza média:
output_path = "images/medium_text_with_boxes.png"
draw_bounding_boxes(medium_text_path, output_path)

Mesmo com a imagem mais difícil, o resultado é perfeito!
Vamos fazer um estudo de caso em um exemplo de arquivo PDF digitalizado. Na prática, é muito provável que você trabalhe com PDFs digitalizados em vez de imagens, como esta:
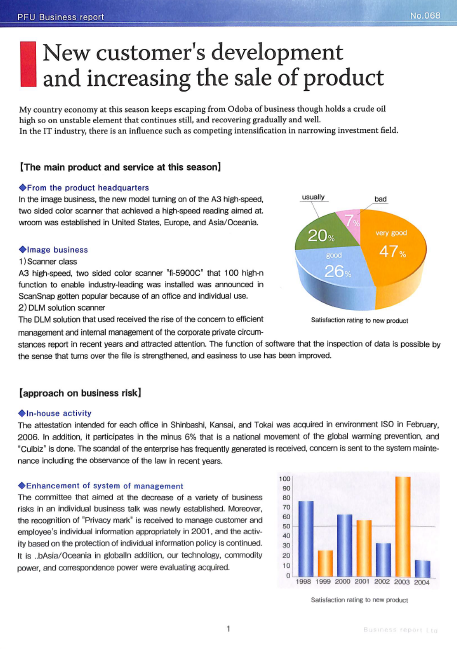
Você pode baixar o PDF nesta página do meu GitHub.
A próxima etapa é instalar a biblioteca pdf2image, que requer um software de processamento de PDF chamado Poppler. Aqui estão as instruções específicas para cada plataforma:
Para Mac:
$ brew install poppler
$ pip install pdf2image
Para Linux e WSL2:
$ sudo apt-get install -y poppler-utils
$ pip install pdf2image
No Windows, você pode seguir as instruções dos documentos do PDF2Image.
Após a instalação, importamos os módulos relevantes:
import pathlib
from pathlib import Path
from pdf2image import convert_from_path
A função convert_from_path converte um determinado PDF em uma série de imagens. Aqui está uma função que salva cada página de um arquivo PDF como uma imagem em um determinado diretório:
def pdf_to_image(pdf_path, output_folder: str = "."):
"""
A function to convert PDF files to images
"""
# Create the output folder if it doesn't exist
if not Path(output_folder).exists():
Path(output_folder).mkdir()
pages = convert_from_path(pdf_path, output_folder=output_folder, fmt="png")
return pages
Vamos executá-lo em nosso documento:
pdf_path = "scanned_document.pdf"
pdf_to_image(pdf_path, output_folder="documents")
[<PIL.PngImagePlugin.PngImageFile image mode=RGB size=1662x2341>]
A saída é uma lista que contém uma única imagem do objeto PngImageFile. Vamos dar uma olhada no diretório documents:
$ ls documents
2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png
A imagem está lá, então vamos alimentá-la com a função image_to_text que criamos no início e imprimir as primeiras centenas de caracteres do texto extraído:
scanned_img_path = "documents/2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png"
print(image_to_text(scanned_img_path)[:377])
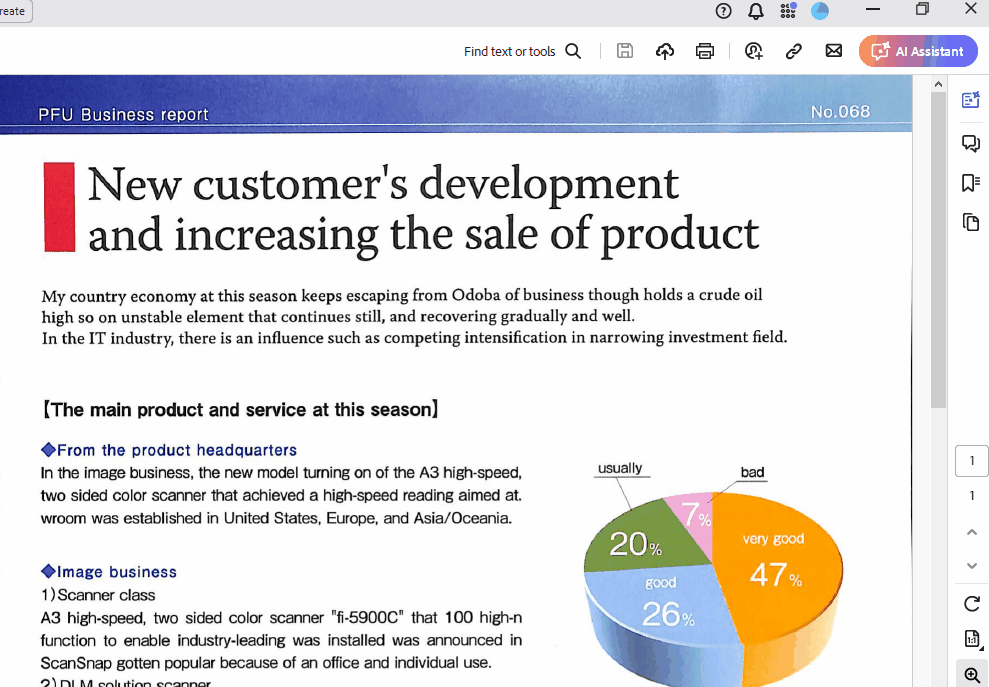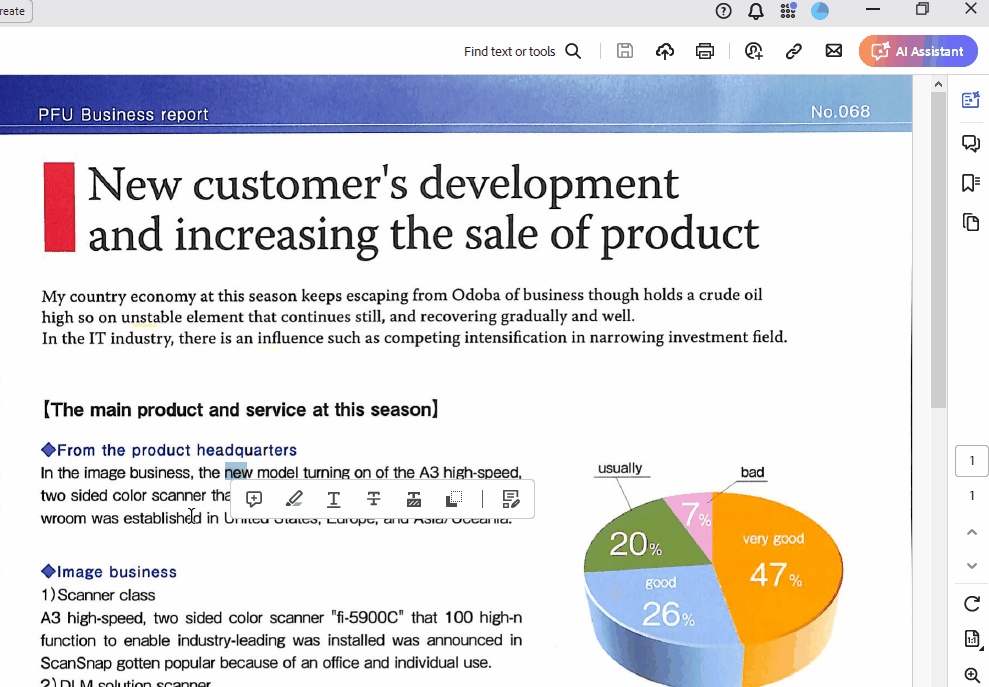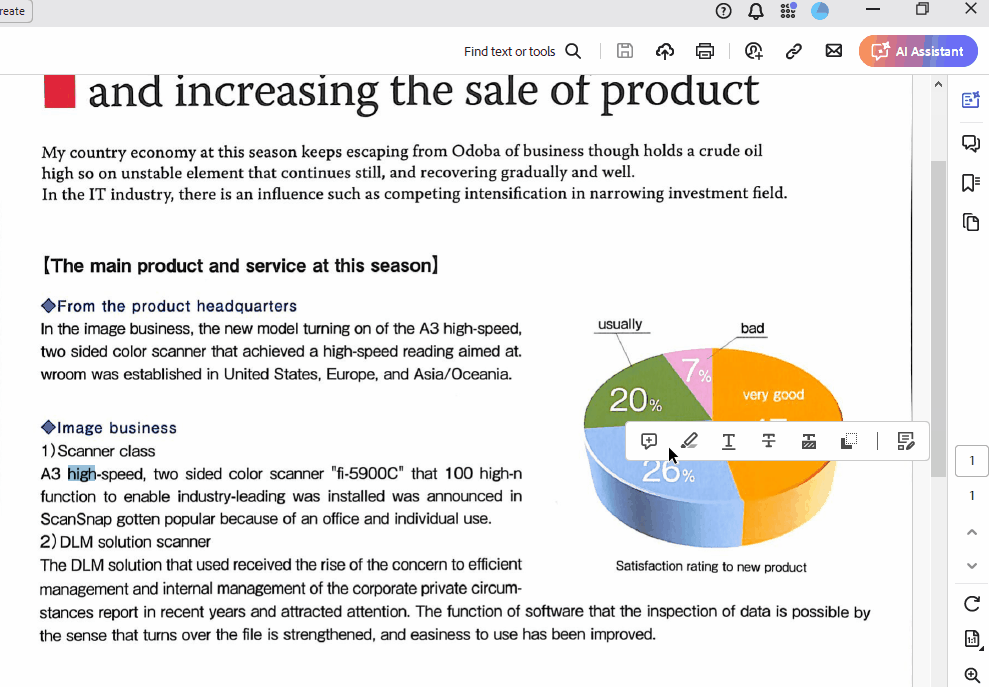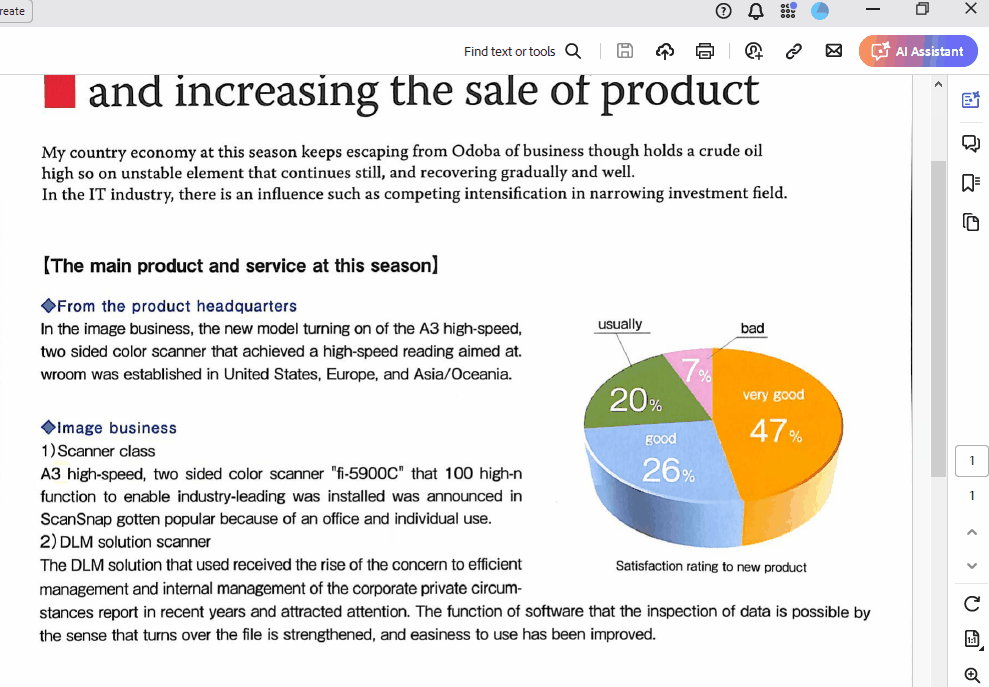
PEU Business report
New customer's development
and increasing the sale of product
My country economy at this season keeps escaping from Odoba of business though holds a crude oil
high so on unstable element that continues still, and recovering gradually and well.
In the IT industry, there is an influence such as competing intensification in narrowing investment field.
Se compararmos o texto com o arquivo, tudo está funcionando bem: a formatação e o espaçamento são preservados e o texto é preciso. Então, como compartilhamos o texto extraído?
Bem, o melhor formato para compartilhar o texto extraído do PDF é outro arquivo PDF! O PyTesseract tem uma função image_to_pdf_or_hocr que pega qualquer imagem com texto e a converte em um arquivo PDF bruto, pesquisável por texto. Vamos usá-lo em nossa imagem digitalizada:
raw_pdf = pytesseract.image_to_pdf_or_hocr(scanned_img_path)
with open("searchable_pdf.pdf", "w+b") as f:
f.write(bytearray(raw_pdf))
E aqui está a aparência do site searchable_pdf:
Como você pode ver, posso destacar e copiar o texto do arquivo. Além disso, todos os elementos do PDF original são preservados.
Não existe uma abordagem única para o OCR. As técnicas que abordamos hoje podem não funcionar com outros tipos de imagens. Recomendo que você experimente diferentes técnicas de pré-processamento de imagens e configurações do Tesseract para encontrar as configurações ideais para imagens específicas.
O fator mais importante no OCR é a qualidade da imagem. Imagens adequadamente digitalizadas, totalmente verticais e de alto contraste (preto e branco) tendem a funcionar melhor com qualquer software de OCR. Lembre-se de que, só porque você consegue ler o texto, não significa que seu computador consiga.
Se suas imagens não satisfizerem os altos padrões de qualidade do Tesseract e a saída for sem sentido, há algumas etapas de pré-processamento que você pode executar.
Primeiro, comece com a conversão de imagens coloridas em escala de cinza. Isso pode melhorar a precisão ao remover variações de cores que podem confundir o processo de reconhecimento. No OpenCV, você terá a seguinte aparência:
def grayscale(image):
"""Converts an image to grayscale.
Args:
image: The input image in BGR format.
Returns:
The grayscale image.
"""
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Nem todas as imagens, especialmente os documentos digitalizados, vêm com fundos imaculados e uniformes. Além disso, algumas imagens podem ser de documentos antigos cujas páginas se deterioraram devido ao tempo. Aqui está um exemplo:

Aplique técnicas como filtros de redução de ruído (por exemplo, desfoque mediano) para reduzir os artefatos de ruído na imagem que podem levar a interpretações errôneas durante o OCR. No OpenCV, você pode usar a função medianBlur:
def denoise(image):
"""Reduces noise in the image using a median blur filter.
Args:
image: The input grayscale image.
Returns:
The denoised image.
"""
return cv2.medianBlur(image, 5) # Adjust kernel size as needed
Em alguns casos, a nitidez da imagem pode aprimorar as bordas e melhorar o reconhecimento de caracteres, especialmente em imagens borradas ou de baixa resolução. A nitidez pode ser realizada aplicando um filtro Laplaciano no OpenCV:
def sharpen(image):
"""Sharpens the image using a Laplacian filter.
Args:
image: The input grayscale image.
Returns:
The sharpened image (be cautious with sharpening).
"""
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
return cv2.filter2D(image, -1, kernel)
Para determinadas imagens, a binarização (conversão da imagem em preto e branco) pode ser benéfica. Faça experiências com diferentes técnicas de limiarização para encontrar a separação ideal entre o primeiro plano (texto) e o plano de fundo.
No entanto, a binarização pode ser sensível a variações na iluminação e nem sempre é necessária. Aqui está um exemplo da aparência de uma imagem binarizada:

Para realizar a binarização no OpenCV, você pode usar a função adaptiveThreshold:
def binarize(image):
"""Binarizes the image using adaptive thresholding.
Args:
image: The input grayscale image.
Returns:
The binary image.
"""
thresh = cv2.adaptiveThreshold(
image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2
)
return thresh
Há muitas outras técnicas de pré-processamento, como:
Você pode saber mais sobre melhorias na qualidade da imagem nesta página da documentação do Tesseract.
Neste artigo, você deu os primeiros passos para aprender sobre o problema dinâmico que é o OCR. Primeiro, abordamos como extrair texto de imagens simples e, em seguida, passamos para imagens mais difíceis com formatação complexa.
Também aprendemos um fluxo de trabalho de ponta a ponta para extrair texto de PDFs digitalizados e como salvar o texto extraído como PDF novamente para que ele se torne pesquisável. Encerramos o artigo com algumas dicas para você melhorar a qualidade da imagem com o OpenCV antes de alimentá-la no Tesseract.
Se você quiser saber mais sobre como resolver problemas relacionados a imagens, aqui estão alguns recursos de visão computacional que você pode consultar:
Continue sua jornada de aprendizado de Python!
Programa
Programa
Curso