
Lernpfad
Bildbearbeitung mit Python
12 Std.
Das manuelle Extrahieren von Text aus Bildern und Dokumenten kann sehr mühsam und zeitaufwändig sein. Zum Glück kann OCR (Optical Character Recognition) diesen Prozess automatisieren, so dass du diese Bilder in bearbeitbare und durchsuchbare Textdateien umwandeln kannst.
Die Techniken, die du lernen wirst, können in vielen Bereichen angewendet werden:
Das Tutorial konzentriert sich auf die Tesseract OCR Engine und ihre Python API - PyTesseract. Bevor wir mit dem Schreiben von Code beginnen, wollen wir uns kurz einige der beliebten Bibliotheken für OCR ansehen.
Da OCR ein beliebtes Dauerproblem ist, versuchen viele Open-Source-Bibliotheken, es zu lösen. In diesem Abschnitt gehen wir auf die Modelle ein, die sich aufgrund ihrer hohen Leistung und Genauigkeit am meisten durchgesetzt haben.
Tesseract OCR ist eine Open-Source-Engine zur optischen Zeichenerkennung, die unter Entwicklern am beliebtesten ist. Wie andere Tools in dieser Liste kann auch Tesseract Bilder von Text in bearbeitbaren Text umwandeln.
EasyOCR ist eine Python-Bibliothek, die für die mühelose optische Zeichenerkennung (Optical Character Recognition, OCR) entwickelt wurde. Es macht seinem Namen alle Ehre und bietet einen benutzerfreundlichen Ansatz zur Textextraktion aus Bildern.
Keras-OCR ist eine Python-Bibliothek, die auf Keras aufbaut, einem beliebten Deep Learning Framework. Sie bietet sofort einsatzbereite OCR-Modelle und eine durchgängige Trainingspipeline zur Erstellung neuer OCR-Modelle.
Hier ist eine Tabelle, die ihre Unterschiede, Vor- und Nachteile zusammenfasst:
|
Paket Name |
Advantage |
Benachteiligungen |
|
Tesserakt (pytesseract) |
Ausgereift, weit verbreitet, umfangreiche Unterstützung |
Langsamer, geringere Genauigkeit bei komplexen Layouts |
|
EasyOCR |
Einfach zu bedienen, mehrere Modelle |
Geringere Genauigkeit, begrenzte Anpassungsmöglichkeiten |
|
Keras-OCR |
Höhere Genauigkeit, anpassbar |
Erfordert GPU, steilere Lernkurve |
In diesem Lernprogramm konzentrieren wir uns auf PyTesseract, die Python-API von Tesseract. Wir lernen, wie man Text aus einfachen Bildern extrahiert, wie man Begrenzungsrahmen um Text zeichnet und führen eine Fallstudie mit einem gescannten Dokument durch.
PyTesseract setzt auf der offiziellen Tesseract-Engine auf, die eine separate CLI-Software ist. Bevor du pytesseract installierst, musst du die Engine installiert haben. Im Folgenden findest du Installationsanweisungen für verschiedene Plattformen.
Für Ubuntu oder WSL2 (meine Wahl):
$ sudo apt update && sudo apt upgrade
$ sudo apt install tesseract-ocr
$ sudo apt install libtesseract-dev
Für Mac mit Homebrew:
$ brew install tesseract
Für Windows folgst du den Anweisungen auf dieser GitHub-Seite.
Als nächstes erstellst du eine neue virtuelle Umgebung. Ich werde Conda verwenden:
$ conda create -n ocr python==3.9 -y
$ conda activate ocr
Dann musst du pytesseract für die OCR und opencv für die Bildbearbeitung installieren:
$ pip install pytesseract
$ pip install opencv-python
Wenn du dieses Tutorial in Jupyter verfolgst, führe diese Befehle in der gleichen Terminalsitzung aus, damit deine neue virtuelle Umgebung als Kernel hinzugefügt wird:
$ pip install ipykernel
$ ipython kernel install --user --name=ocr
Jetzt können wir anfangen, Code zu schreiben.
Wir beginnen damit, die notwendigen Bibliotheken zu importieren:
import cv2
import pytesseract
Unsere Aufgabe ist es, den Text auf dem folgenden Bild zu lesen:

Zuerst definieren wir den Bildpfad und geben ihn an die Funktion cv2.imread weiter:
# Read image
easy_text_path = "images/easy_text.png"
easy_img = cv2.imread(easy_text_path)
Dann übergeben wir das geladene Bild an die Funktion image_to_string von pytesseract, um den Text zu extrahieren:
# Convert to text
text = pytesseract.image_to_string(easy_img)
print(text)
This text is
easy to extract.
So einfach ist das! Lass uns das, was wir gerade gemacht haben, in eine Funktion umwandeln:
def image_to_text(input_path):
"""
A function to read text from images.
"""
img = cv2.imread(input_path)
text = pytesseract.image_to_string(img)
return text.strip()
Lass uns die Funktion auf ein schwierigeres Bild anwenden:

Das Bild bietet eine größere Herausforderung, da es mehr Satzzeichen und Text in verschiedenen Schriftarten gibt.
# Define image path
medium_text_path = "images/medium_text.png"
# Extract text
extracted_text = image_to_text(medium_text_path)
print(extracted_text)
Home > Tutorials » Data Engineering
Snowflake Tutorial For Beginners:
From Architecture to Running
Databases
Learn the fundamentals of cloud data warehouse management using
Snowflake. Snowflake is a cloud-based platform that offers significant
benefits for companies wanting to extract as much insight from their data as
quickly and efficiently as possible.
Jan 2024 - 12 min read
Unsere Funktion hat fast perfekt funktioniert. Er hat einen der Punkte und das ">"-Zeichen verwechselt, aber sonst ist das Ergebnis akzeptabel.
Ein gängiger Vorgang bei der OCR ist das Zeichnen von Begrenzungsrahmen um Text. Dieser Vorgang wird in PyTesseract unterstützt.
Zuerst übergeben wir ein geladenes Bild an die Funktion image_to_data:
from pytesseract import Output
# Extract recognized data from easy text
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
Der Output.DICT Teil sorgt dafür, dass die Bilddetails als Wörterbuch zurückgegeben werden. Lass uns einen Blick hineinwerfen:
data{'level': [1, 2, 3, 4, 5, 5, 5, 4, 5, 5, 5],
'page_num': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'block_num': [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'par_num': [0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'line_num': [0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
'word_num': [0, 0, 0, 0, 1, 2, 3, 0, 1, 2, 3],
'left': [0, 41, 41, 236, 236, 734, 1242, 41, 41, 534, 841],
'top': [0, 68, 68, 68, 68, 80, 68, 284, 309, 284, 284],
'width': [1658, 1550, 1550, 1179, 380, 383, 173, 1550, 381, 184, 750],
'height': [469, 371, 371, 128, 128, 116, 128, 155, 130, 117, 117],
'conf': [-1, -1, -1, -1, 96, 95, 95, -1, 96, 96, 96],
'text': ['', '', '', '', 'This', 'text', 'is', '', 'easy', 'to', 'extract.']}
Das Wörterbuch enthält eine Menge Informationen über das Bild. Beachte zuerst die Tasten conf und text. Sie haben beide eine Länge von 11:
len(data["text"])11Das bedeutet, dass pytesseract 11 Kisten gezogen hat. Die conf steht für Vertrauen. Wenn sie gleich -1 ist, wird der entsprechende Rahmen um Textblöcke und nicht um einzelne Wörter gezeichnet.
Wenn du dir zum Beispiel die ersten vier Werte von width und height ansiehst, sind sie im Vergleich zum Rest sehr groß, weil diese Rahmen um den gesamten Text in der Mitte, dann für jede Textzeile und das gesamte Bild selbst gezeichnet werden.
Also:
left ist der Abstand von der linken oberen Ecke des Begrenzungsrahmens zum linken Rand des Bildes.top ist der Abstand von der linken oberen Ecke des Begrenzungsrahmens zum oberen Rand des Bildes.width und height sind die Breite und Höhe des Begrenzungsrahmens.Mit diesen Informationen können wir in OpenCV die Kästchen auf dem Bild zeichnen.
Zuerst extrahieren wir wieder die Daten und ihre Länge:
from pytesseract import Output
# Extract recognized data
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
n_boxes = len(data["text"])
Dann erstellen wir eine Schleife für die Anzahl der gefundenen Kisten:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
Innerhalb der Schleife erstellen wir eine Bedingung, die die aktuelle Schleifeniteration überspringt, wenn conf gleich -1 ist. Das Überspringen größerer Boundingboxen hält unser Bild sauber.
Dann legen wir die Koordinaten der aktuellen Box fest, insbesondere die Positionen der oberen linken und unteren rechten Ecke:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
Nachdem wir einige Parameter für die Box festgelegt haben, z. B. die Farbe und die Dicke der Box in Pixeln, übergeben wir alle Informationen an die Funktion cv2.rectangle:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 3 # pixels
cv2.rectangle(
img=easy_img, pt1=top_left, pt2=bottom_right, color=green, thickness=thickness
)
Die Funktion zeichnet die Kästchen über die Originalbilder. Speichern wir das Bild und schauen wir es uns an:
# Save the image
output_image_path = "images/text_with_boxes.jpg"
cv2.imwrite(output_image_path, easy_img)
True
Das Ergebnis ist genau das, was wir wollten!
Jetzt lass uns alles, was wir gemacht haben, wieder in eine Funktion packen:
def draw_bounding_boxes(input_img_path, output_path):
img = cv2.imread(input_img_path)
# Extract data
data = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(data["text"])
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 1 # The function-version uses thinner lines
cv2.rectangle(img, top_left, bottom_right, green, thickness)
# Save the image with boxes
cv2.imwrite(output_path, img)
Und benutze die Funktion für den mittelschweren Text:
output_path = "images/medium_text_with_boxes.png"
draw_bounding_boxes(medium_text_path, output_path)

Selbst für das schwierigste Bild ist das Ergebnis perfekt!
Machen wir eine Fallstudie mit einer gescannten PDF-Datei. In der Praxis ist es sehr wahrscheinlich, dass du mit gescannten PDFs statt mit Bildern wie diesem hier arbeiten wirst:
Du kannst das PDF von dieser Seite meines GitHub herunterladen.
Der nächste Schritt ist die Installation der pdf2image Bibliothek, die eine PDF-Verarbeitungssoftware namens Poppler erfordert. Hier sind plattformspezifische Anweisungen:
Für Mac:
$ brew install poppler
$ pip install pdf2image
Für Linux und WSL2:
$ sudo apt-get install -y poppler-utils
$ pip install pdf2image
Unter Windows kannst du den Anweisungen in den PDF2Image-Dokumenten folgen.
Nach der Installation importieren wir die entsprechenden Module:
import pathlib
from pathlib import Path
from pdf2image import convert_from_path
Die Funktion convert_from_path konvertiert ein gegebenes PDF in eine Reihe von Bildern. Hier ist eine Funktion, die jede Seite einer PDF-Datei als Bild in einem bestimmten Verzeichnis speichert:
def pdf_to_image(pdf_path, output_folder: str = "."):
"""
A function to convert PDF files to images
"""
# Create the output folder if it doesn't exist
if not Path(output_folder).exists():
Path(output_folder).mkdir()
pages = convert_from_path(pdf_path, output_folder=output_folder, fmt="png")
return pages
Führen wir es auf unserem Dokument aus:
pdf_path = "scanned_document.pdf"
pdf_to_image(pdf_path, output_folder="documents")
[<PIL.PngImagePlugin.PngImageFile image mode=RGB size=1662x2341>]
Die Ausgabe ist eine Liste, die ein einzelnes Bild PngImageFile Objekt enthält. Werfen wir einen Blick auf das Verzeichnis documents:
$ ls documents
2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png
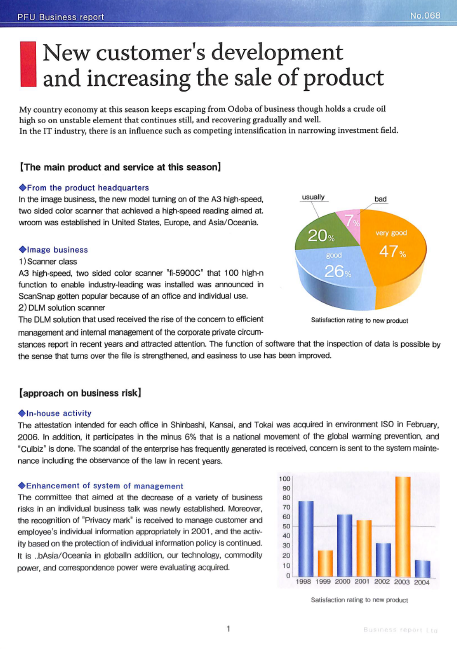
Das Bild ist da, also füttern wir es mit unserer image_to_text Funktion, die wir am Anfang erstellt haben, und drucken die ersten paar hundert Zeichen des extrahierten Textes:
scanned_img_path = "documents/2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png"
print(image_to_text(scanned_img_path)[:377])
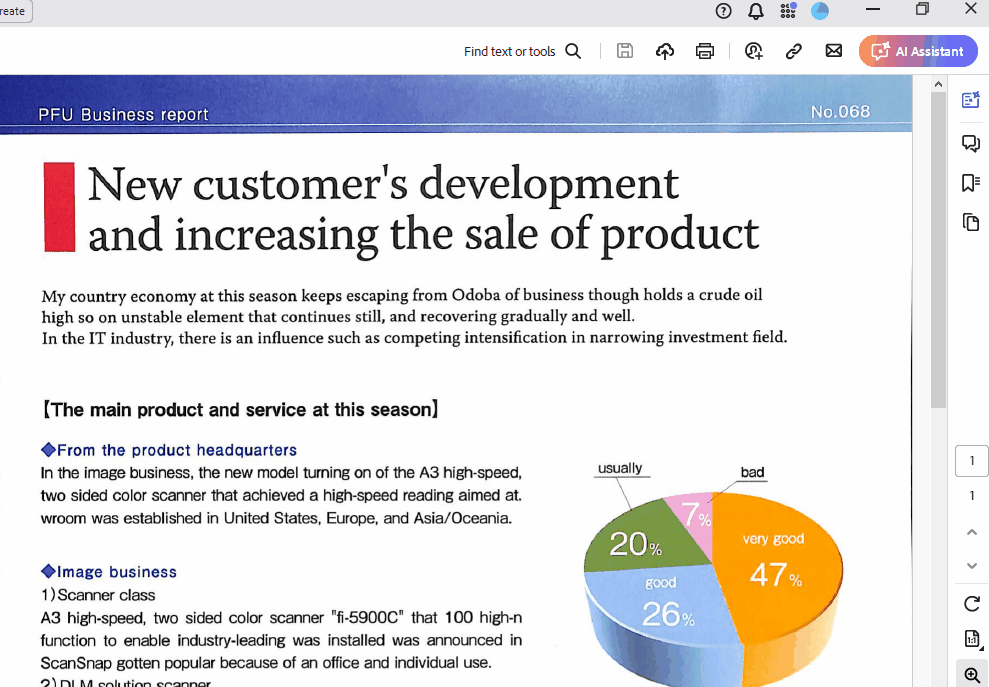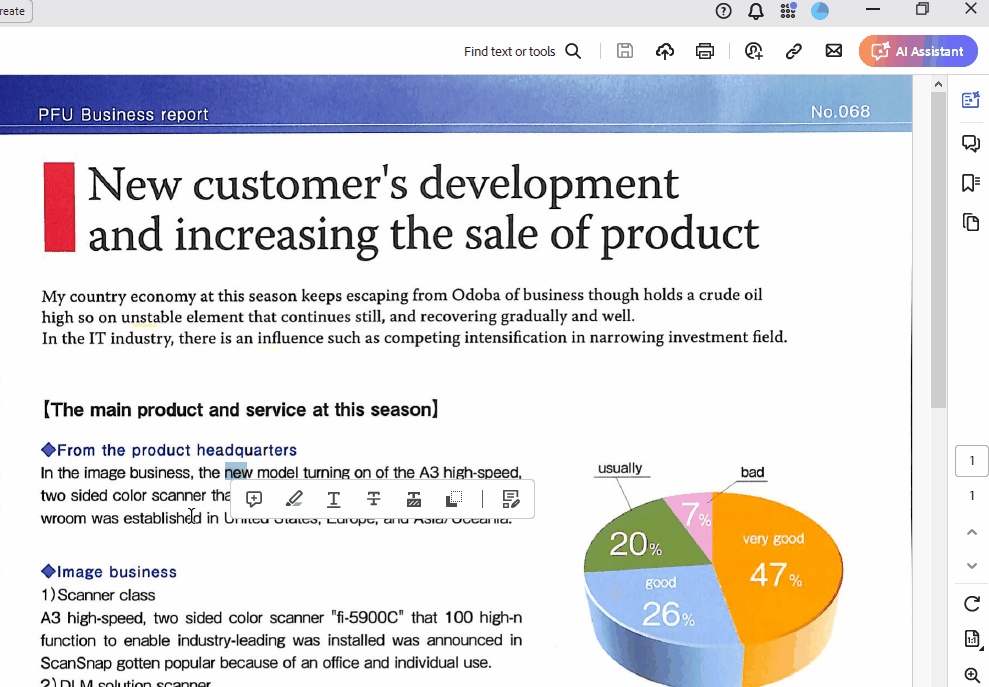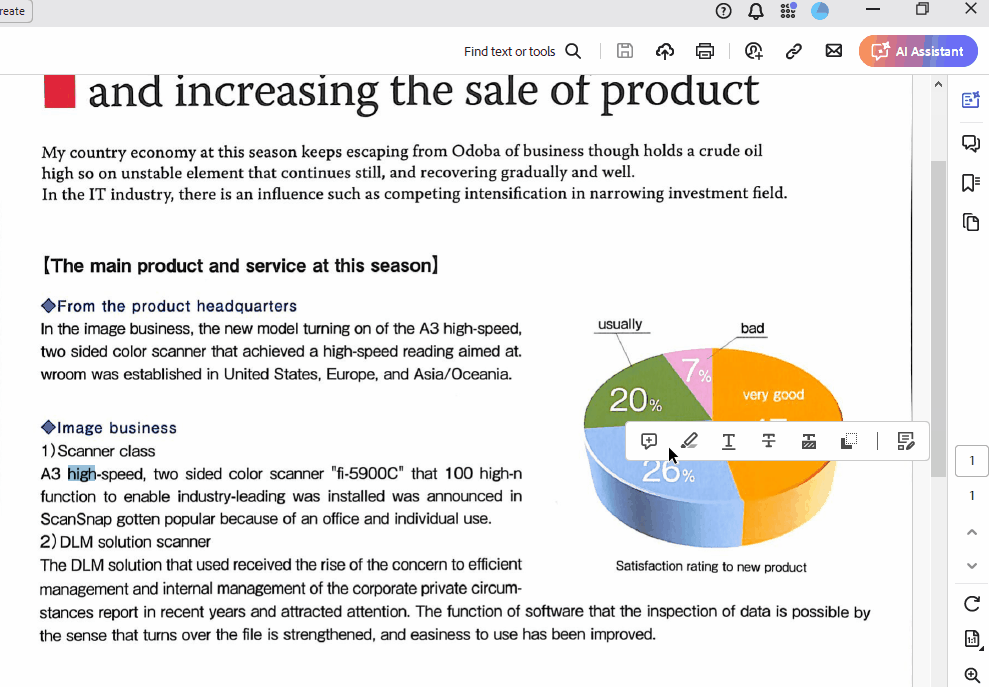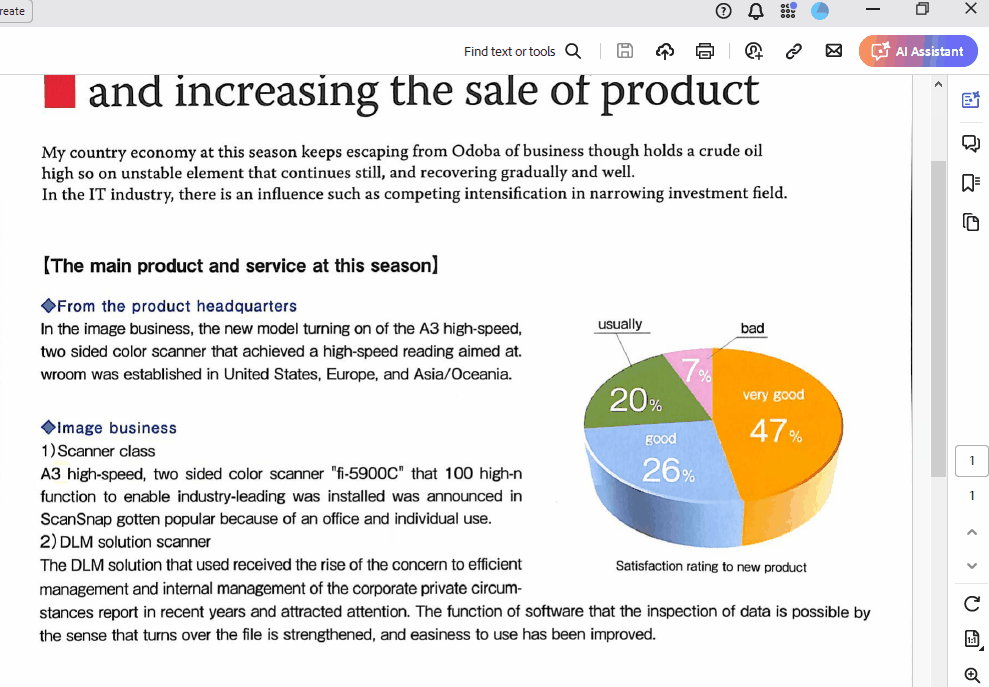
PEU Business report
New customer's development
and increasing the sale of product
My country economy at this season keeps escaping from Odoba of business though holds a crude oil
high so on unstable element that continues still, and recovering gradually and well.
In the IT industry, there is an influence such as competing intensification in narrowing investment field.
Wenn wir den Text mit der Datei vergleichen, funktioniert alles gut - die Formatierung und die Abstände bleiben erhalten, und der Text ist korrekt. Wie können wir also den extrahierten Text teilen?
Das beste Format, um extrahierten PDF-Text weiterzugeben, ist eine andere PDF-Datei! PyTesseract hat eine image_to_pdf_or_hocr Funktion, die jedes Bild mit Text in eine rohe, durchsuchbare PDF-Datei umwandelt. Wenden wir sie auf unser gescanntes Bild an:
raw_pdf = pytesseract.image_to_pdf_or_hocr(scanned_img_path)
with open("searchable_pdf.pdf", "w+b") as f:
f.write(bytearray(raw_pdf))
Und so sieht die searchable_pdf aus:
Wie du sehen kannst, kann ich Text in der Datei markieren und kopieren. Außerdem bleiben alle Elemente der ursprünglichen PDF-Datei erhalten.
Für OCR gibt es keine Einheitslösung. Die Techniken, die wir heute behandelt haben, funktionieren möglicherweise nicht mit anderen Arten von Bildern. Ich empfehle dir, mit verschiedenen Bildvorverarbeitungsmethoden und Tesseract-Konfigurationen zu experimentieren, um die optimalen Einstellungen für bestimmte Bilder zu finden.
Der wichtigste Faktor bei der OCR ist die Bildqualität. Ordnungsgemäß gescannte, vollständig vertikale und kontrastreiche (schwarz-weiße) Bilder funktionieren in der Regel am besten mit jeder OCR-Software. Denk daran: Nur weil du den Text lesen kannst, heißt das nicht, dass dein Computer es auch kann.
Wenn deine Bilder nicht den hohen Qualitätsstandards von Tesseract entsprechen und die Ausgabe Kauderwelsch ist, gibt es einige Vorverarbeitungsschritte, die du durchführen kannst.
Beginne damit, farbige Bilder in Graustufen zu konvertieren. Dies kann die Genauigkeit verbessern, indem Farbunterschiede entfernt werden, die den Erkennungsprozess verwirren könnten. In OpenCV sieht das dann so aus:
def grayscale(image):
"""Converts an image to grayscale.
Args:
image: The input image in BGR format.
Returns:
The grayscale image.
"""
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Nicht alle Bilder, insbesondere gescannte Dokumente, haben einen makellosen, einheitlichen Hintergrund. Außerdem können einige Bilder von alten Dokumenten stammen, bei denen die Seiten aufgrund des Alters beschädigt sind. Hier ist ein Beispiel:

Wende Techniken wie Entrauschungsfilter (z. B. Medianunschärfe) an, um Rauschartefakte im Bild zu reduzieren, die bei der OCR zu Fehlinterpretationen führen können. In OpenCV kannst du die Funktion medianBlur verwenden:
def denoise(image):
"""Reduces noise in the image using a median blur filter.
Args:
image: The input grayscale image.
Returns:
The denoised image.
"""
return cv2.medianBlur(image, 5) # Adjust kernel size as needed
In einigen Fällen kann das Schärfen des Bildes die Kanten verstärken und die Zeichenerkennung verbessern, insbesondere bei unscharfen oder niedrig aufgelösten Bildern. Die Schärfung kann durch Anwendung eines Laplacian-Filters in OpenCV erfolgen:
def sharpen(image):
"""Sharpens the image using a Laplacian filter.
Args:
image: The input grayscale image.
Returns:
The sharpened image (be cautious with sharpening).
"""
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
return cv2.filter2D(image, -1, kernel)
Bei bestimmten Bildern kann eine Binarisierung (Umwandlung des Bildes in Schwarz-Weiß) von Vorteil sein. Experimentiere mit verschiedenen Schwellenwerttechniken, um die optimale Trennung zwischen Vorder- (Text) und Hintergrund zu finden.
Die Binarisierung kann jedoch empfindlich auf Beleuchtungsschwankungen reagieren und ist nicht immer notwendig. Hier ist ein Beispiel dafür, wie ein binarisiertes Bild aussieht:

Um eine Binarisierung in OpenCV durchzuführen, kannst du die Funktion adaptiveThreshold verwenden:
def binarize(image):
"""Binarizes the image using adaptive thresholding.
Args:
image: The input grayscale image.
Returns:
The binary image.
"""
thresh = cv2.adaptiveThreshold(
image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2
)
return thresh
Es gibt viele andere Vorverarbeitungstechniken, wie z. B.:
Mehr über die Verbesserung der Bildqualität erfährst du auf dieser Seite der Tesseract-Dokumentation.
In diesem Artikel hast du die ersten Schritte unternommen, um etwas über das dynamische Problem der OCR zu erfahren. Wir haben zuerst behandelt, wie man Text aus einfachen Bildern extrahiert, und sind dann zu schwierigeren Bildern mit komplexer Formatierung übergegangen.
Wir haben auch gelernt, wie man Text aus gescannten PDFs extrahiert und wie man den extrahierten Text wieder als PDF speichert, damit er durchsuchbar wird. Wir haben den Artikel mit einigen Tipps abgerundet, wie du die Bildqualität mit OpenCV verbessern kannst, bevor du sie in Tesseract einspeist.
Wenn du mehr über das Lösen von Problemen im Zusammenhang mit Bildern erfahren möchtest, findest du hier einige Ressourcen zum Thema Computer Vision:
Setze deine Python-Lernreise fort!
Lernpfad
Lernpfad
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
