
Cursus
Traitement des images en Python
12 h
L'extraction manuelle de texte à partir d'images et de documents peut être très fastidieuse et prendre beaucoup de temps. Heureusement, l'OCR (reconnaissance optique de caractères) peut automatiser ce processus, en vous permettant de convertir ces images en fichiers texte éditables et consultables.
Les techniques que vous allez apprendre peuvent être utilisées dans de nombreuses applications :
Le tutoriel se concentrera sur le moteur d'OCR Tesseract et son API Python - PyTesseract. Avant de commencer à écrire le code, passons brièvement en revue quelques-unes des bibliothèques populaires dédiées à l'OCR.
L'OCR étant un problème récurrent et populaire, de nombreuses bibliothèques open-source tentent de le résoudre. Dans cette section, nous aborderons ceux qui ont gagné le plus de popularité en raison de leurs performances et de leur précision élevées.
Tesseract OCR est un moteur de reconnaissance optique de caractères open-source qui est le plus populaire parmi les développeurs. Comme d'autres outils de cette liste, Tesseract peut prendre des images de texte et les convertir en texte éditable.
EasyOCR est une bibliothèque Python conçue pour la reconnaissance optique de caractères (OCR) sans effort. Il porte bien son nom en offrant une approche conviviale de l'extraction de texte à partir d'images.
Keras-OCR est une bibliothèque Python construite au-dessus de Keras, un framework d'apprentissage profond populaire. Il fournit des modèles d'OCR prêts à l'emploi et un pipeline de formation de bout en bout pour construire de nouveaux modèles d'OCR.
Voici un tableau résumant leurs différences, leurs avantages et leurs inconvénients :
|
Nom du paquet |
Avantage |
Inconvénients |
|
Tesseract (pytesseract) |
Mature, largement utilisé, soutien important |
Plus lent, moins précis sur les tracés complexes |
|
EasyOCR |
Simplicité d'utilisation, nombreux modèles |
Précision moindre, personnalisation limitée |
|
Keras-OCR |
Plus grande précision, personnalisable |
Requiert un GPU, courbe d'apprentissage plus raide |
Dans ce tutoriel, nous nous concentrerons sur PyTesseract, qui est l'API Python de Tesseract. Nous apprendrons à extraire du texte à partir d'images simples, à dessiner des cadres autour du texte et à réaliser une étude de cas avec un document numérisé.
PyTesseract fonctionne au-dessus du moteur officiel de Tesseract, qui est un logiciel CLI séparé. Avant d'installer pytesseract, vous devez avoir installé le moteur. Vous trouverez ci-dessous les instructions d'installation pour les différentes plateformes.
Pour Ubuntu ou WSL2 (mon choix) :
$ sudo apt update && sudo apt upgrade
$ sudo apt install tesseract-ocr
$ sudo apt install libtesseract-dev
Pour Mac utilisant Homebrew :
$ brew install tesseract
Pour Windows, suivez les instructions de cette page GitHub.
Créez ensuite un nouvel environnement virtuel. Je vais utiliser Conda :
$ conda create -n ocr python==3.9 -y
$ conda activate ocr
Ensuite, vous devez installer pytesseract pour l'OCR et opencv pour la manipulation d'images :
$ pip install pytesseract
$ pip install opencv-python
Si vous suivez ce tutoriel dans Jupyter, exécutez ces commandes dans la même session de terminal afin que votre nouvel environnement virtuel soit ajouté en tant que noyau :
$ pip install ipykernel
$ ipython kernel install --user --name=ocr
Nous pouvons maintenant commencer à écrire du code.
Nous commençons par importer les bibliothèques nécessaires :
import cv2
import pytesseract
Notre tâche consiste à lire le texte de l'image suivante :

Tout d'abord, nous définissons le chemin de l'image et l'envoyons à la fonction cv2.imread:
# Read image
easy_text_path = "images/easy_text.png"
easy_img = cv2.imread(easy_text_path)
Ensuite, nous transmettons l'image chargée à la fonction image_to_string de pytesseract pour extraire le texte :
# Convert to text
text = pytesseract.image_to_string(easy_img)
print(text)
This text is
easy to extract.
C'est aussi simple que cela ! Transformons ce que nous venons de faire en une fonction :
def image_to_text(input_path):
"""
A function to read text from images.
"""
img = cv2.imread(input_path)
text = pytesseract.image_to_string(img)
return text.strip()
Utilisons la fonction sur une image plus difficile :

L'image représente un plus grand défi, car elle contient plus de symboles de ponctuation et du texte dans des polices différentes.
# Define image path
medium_text_path = "images/medium_text.png"
# Extract text
extracted_text = image_to_text(medium_text_path)
print(extracted_text)
Home > Tutorials » Data Engineering
Snowflake Tutorial For Beginners:
From Architecture to Running
Databases
Learn the fundamentals of cloud data warehouse management using
Snowflake. Snowflake is a cloud-based platform that offers significant
benefits for companies wanting to extract as much insight from their data as
quickly and efficiently as possible.
Jan 2024 - 12 min read
Notre fonction a fonctionné presque parfaitement. Il a confondu l'un des points et le signe ">", mais le résultat est acceptable par ailleurs.
Une opération courante de l'OCR consiste à tracer des boîtes de délimitation autour du texte. Cette opération est prise en charge par PyTesseract.
Tout d'abord, nous transmettons une image chargée à la fonction image_to_data:
from pytesseract import Output
# Extract recognized data from easy text
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
La partie Output.DICT garantit que les détails de l'image sont renvoyés sous forme de dictionnaire. Jetons un coup d'œil à l'intérieur :
data{'level': [1, 2, 3, 4, 5, 5, 5, 4, 5, 5, 5],
'page_num': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'block_num': [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'par_num': [0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'line_num': [0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2],
'word_num': [0, 0, 0, 0, 1, 2, 3, 0, 1, 2, 3],
'left': [0, 41, 41, 236, 236, 734, 1242, 41, 41, 534, 841],
'top': [0, 68, 68, 68, 68, 80, 68, 284, 309, 284, 284],
'width': [1658, 1550, 1550, 1179, 380, 383, 173, 1550, 381, 184, 750],
'height': [469, 371, 371, 128, 128, 116, 128, 155, 130, 117, 117],
'conf': [-1, -1, -1, -1, 96, 95, 95, -1, 96, 96, 96],
'text': ['', '', '', '', 'This', 'text', 'is', '', 'easy', 'to', 'extract.']}
Le dictionnaire contient de nombreuses informations sur l'image. Remarquez tout d'abord les touches conf et text. Ils ont tous deux une longueur de 11 :
len(data["text"])11Cela signifie que pytesseract a tiré 11 boîtes. Le site conf est synonyme de confiance. S'il est égal à -1, le cadre correspondant est dessiné autour de blocs de texte plutôt que de mots individuels.
Par exemple, si vous regardez les quatre premières valeurs width et height, elles sont grandes par rapport aux autres parce que ces boîtes sont dessinées autour du texte entier au milieu, puis pour chaque ligne de texte et pour l'image globale elle-même.
En outre :
left est la distance entre le coin supérieur gauche de la boîte englobante et le bord gauche de l'image.top est la distance entre le coin supérieur gauche de la boîte englobante et le bord supérieur de l'image.width et height sont la largeur et la hauteur de la boîte de délimitation.À l'aide de ces informations, dessinons les boîtes sur l'image dans OpenCV.
Tout d'abord, nous extrayons à nouveau les données et leur longueur :
from pytesseract import Output
# Extract recognized data
data = pytesseract.image_to_data(easy_img, output_type=Output.DICT)
n_boxes = len(data["text"])
Ensuite, nous créons une boucle pour le nombre de boîtes trouvées :
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
À l'intérieur de la boucle, nous créons une condition qui permet d'ignorer l'itération actuelle de la boucle si conf est égal à -1. Le fait de ne pas prendre en compte les boîtes de délimitation plus grandes permet de conserver une image propre.
Ensuite, nous définissons les coordonnées de la boîte actuelle, en particulier les emplacements des coins supérieur gauche et inférieur droit :
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
Après avoir défini certains paramètres de la boîte, tels que sa couleur et son épaisseur en pixels, nous transmettons toutes les informations à la fonction cv2.rectangle:
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 3 # pixels
cv2.rectangle(
img=easy_img, pt1=top_left, pt2=bottom_right, color=green, thickness=thickness
)
La fonction dessine les cases sur les images originales. Sauvegardons l'image et jetons un coup d'œil :
# Save the image
output_image_path = "images/text_with_boxes.jpg"
cv2.imwrite(output_image_path, easy_img)
True
Le résultat est exactement ce que nous voulions !
Maintenant, mettons à nouveau tout ce que nous avons fait dans une fonction :
def draw_bounding_boxes(input_img_path, output_path):
img = cv2.imread(input_img_path)
# Extract data
data = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(data["text"])
for i in range(n_boxes):
if data["conf"][i] == -1:
continue
# Coordinates
x, y = data["left"][i], data["top"][i]
w, h = data["width"][i], data["height"][i]
# Corners
top_left = (x, y)
bottom_right = (x + w, y + h)
# Box params
green = (0, 255, 0)
thickness = 1 # The function-version uses thinner lines
cv2.rectangle(img, top_left, bottom_right, green, thickness)
# Save the image with boxes
cv2.imwrite(output_path, img)
Et utilisez la fonction sur le texte moyennement dur :
output_path = "images/medium_text_with_boxes.png"
draw_bounding_boxes(medium_text_path, output_path)

Même pour l'image la plus difficile, le résultat est parfait !
Faisons une étude de cas sur un exemple de fichier PDF numérisé. Dans la pratique, il est très probable que vous travailliez avec des PDF numérisés plutôt qu'avec des images, comme celle-ci :
Vous pouvez télécharger le PDF depuis cette page de mon GitHub.
L'étape suivante consiste à installer la bibliothèque pdf2image, qui nécessite un logiciel de traitement des PDF appelé Poppler. Voici les instructions spécifiques à chaque plate-forme :
Pour Mac :
$ brew install poppler
$ pip install pdf2image
Pour Linux et WSL2 :
$ sudo apt-get install -y poppler-utils
$ pip install pdf2image
Pour Windows, vous pouvez suivre les instructions de la documentation de PDF2Image.
Après l'installation, nous importons les modules appropriés :
import pathlib
from pathlib import Path
from pdf2image import convert_from_path
La fonction convert_from_path convertit un PDF donné en une série d'images. Voici une fonction qui enregistre chaque page d'un fichier PDF sous forme d'image dans un répertoire donné :
def pdf_to_image(pdf_path, output_folder: str = "."):
"""
A function to convert PDF files to images
"""
# Create the output folder if it doesn't exist
if not Path(output_folder).exists():
Path(output_folder).mkdir()
pages = convert_from_path(pdf_path, output_folder=output_folder, fmt="png")
return pages
Exécutons-le sur notre document :
pdf_path = "scanned_document.pdf"
pdf_to_image(pdf_path, output_folder="documents")
[<PIL.PngImagePlugin.PngImageFile image mode=RGB size=1662x2341>]
Le résultat est une liste contenant un seul objet image PngImageFile. Jetons un coup d'œil au répertoire documents:
$ ls documents
2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png
L'image est là, alors envoyons-la à la fonction image_to_text que nous avons créée au début et imprimons les quelques centaines de caractères du texte extrait :
scanned_img_path = "documents/2d8f6922-99c4-4ef4-a475-ef81effe65a3-1.png"
print(image_to_text(scanned_img_path)[:377])
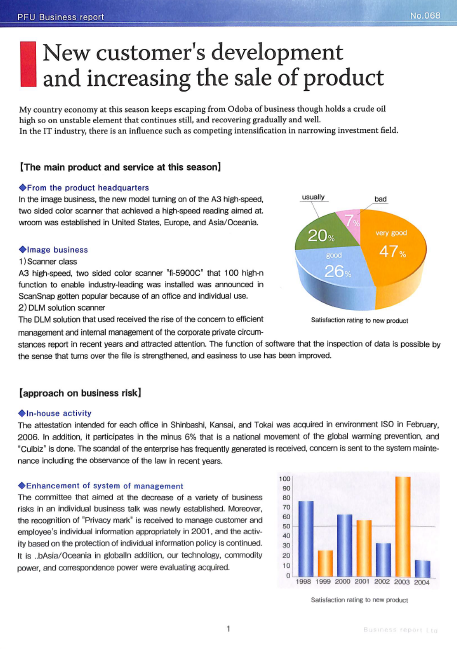
PEU Business report
New customer's development
and increasing the sale of product
My country economy at this season keeps escaping from Odoba of business though holds a crude oil
high so on unstable element that continues still, and recovering gradually and well.
In the IT industry, there is an influence such as competing intensification in narrowing investment field.
Si nous comparons le texte au fichier, tout fonctionne bien - le formatage et l'espacement sont préservés et le texte est exact. Comment partager le texte extrait ?
Le meilleur format pour partager un texte PDF extrait est un autre fichier PDF ! PyTesseract dispose d'une fonction image_to_pdf_or_hocr qui prend n'importe quelle image avec du texte et la convertit en un fichier PDF brut, consultable par le texte. Utilisons-le sur notre image numérisée :
raw_pdf = pytesseract.image_to_pdf_or_hocr(scanned_img_path)
with open("searchable_pdf.pdf", "w+b") as f:
f.write(bytearray(raw_pdf))
Et voici à quoi ressemble le site searchable_pdf:
Comme vous pouvez le constater, je peux surligner et copier du texte à partir du fichier. En outre, tous les éléments du PDF original sont préservés.
Il n'existe pas d'approche unique pour l'OCR. Les techniques que nous avons abordées aujourd'hui peuvent ne pas fonctionner avec d'autres types d'images. Je vous recommande d'expérimenter différentes techniques de prétraitement d'images et configurations de Tesseract afin de trouver les paramètres optimaux pour des images spécifiques.
Le facteur le plus important de l'OCR est la qualité de l'image. Les images correctement numérisées, entièrement verticales et très contrastées (en noir et blanc) sont celles qui fonctionnent le mieux avec les logiciels d'OCR. N'oubliez pas que ce n'est pas parce que vous pouvez lire le texte que votre ordinateur le peut.
Si vos images ne satisfont pas aux normes de qualité élevées de Tesseract et que le résultat est un charabia, vous pouvez effectuer quelques étapes de prétraitement.
Commencez par convertir les images colorées en niveaux de gris. Cela permet d'améliorer la précision en supprimant les variations de couleur susceptibles de perturber le processus de reconnaissance. Dans OpenCV, cela ressemble à ceci :
def grayscale(image):
"""Converts an image to grayscale.
Args:
image: The input image in BGR format.
Returns:
The grayscale image.
"""
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Toutes les images, en particulier les documents numérisés, ne sont pas accompagnées d'un arrière-plan immaculé et uniforme. En outre, certaines images peuvent provenir de documents anciens dont les pages se sont détériorées en raison de l'âge. En voici un exemple :

Appliquez des techniques telles que des filtres de débruitage (par exemple, le flou médian) pour réduire les artefacts de bruit dans l'image qui peuvent conduire à des erreurs d'interprétation lors de l'OCR. Dans OpenCV, vous pouvez utiliser la fonction medianBlur:
def denoise(image):
"""Reduces noise in the image using a median blur filter.
Args:
image: The input grayscale image.
Returns:
The denoised image.
"""
return cv2.medianBlur(image, 5) # Adjust kernel size as needed
Dans certains cas, l'accentuation de la netteté de l'image peut renforcer les contours et améliorer la reconnaissance des caractères, en particulier pour les images floues ou à faible résolution. L'accentuation peut être réalisée en appliquant un filtre Laplacien dans OpenCV :
def sharpen(image):
"""Sharpens the image using a Laplacian filter.
Args:
image: The input grayscale image.
Returns:
The sharpened image (be cautious with sharpening).
"""
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
return cv2.filter2D(image, -1, kernel)
Pour certaines images, la binarisation (conversion de l'image en noir et blanc) peut être bénéfique. Expérimentez différentes techniques de seuillage pour trouver la séparation optimale entre le premier plan (texte) et l'arrière-plan.
Cependant, la binarisation peut être sensible aux variations d'éclairage et n'est pas toujours nécessaire. Voici un exemple d'image binarisée :

Pour effectuer une binarisation dans OpenCV, vous pouvez utiliser la fonction adaptiveThreshold:
def binarize(image):
"""Binarizes the image using adaptive thresholding.
Args:
image: The input grayscale image.
Returns:
The binary image.
"""
thresh = cv2.adaptiveThreshold(
image, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2
)
return thresh
Il existe de nombreuses autres techniques de prétraitement, telles que :
Vous pouvez en savoir plus sur les améliorations de la qualité de l'image en consultant cette page de la documentation de Tesseract.
Dans cet article, vous avez fait les premiers pas pour vous familiariser avec le problème dynamique qu'est l'OCR. Nous avons d'abord abordé la question de l'extraction de texte à partir d'images simples, puis nous sommes passés à des images plus difficiles avec un formatage complexe.
Nous avons également appris un processus de bout en bout pour extraire du texte à partir de PDF numérisés et comment enregistrer le texte extrait au format PDF pour qu'il puisse faire l'objet d'une recherche. Nous avons terminé l'article avec quelques conseils pour améliorer la qualité des images avec OpenCV avant de les envoyer à Tesseract.
Si vous souhaitez en savoir plus sur la résolution de problèmes liés à l'image, voici quelques ressources sur la vision par ordinateur :
Poursuivez votre apprentissage de Python !
Cursus
Cursus
Cours
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min