
Curso
Unsupervised Learning em Python
4 h
180.7K
A serialização é uma ótima coisa para você saber. Ele permite que você preserve o estado dos seus dados ou modelos, evitando a necessidade de reprocessar ou treinar novamente do zero.
Aqui, explorarei o conhecido módulo Python Pickle. Ao final, você saberá como serializar e desserializar estruturas de dados comuns, como listas e dicionários, e saberá como usar diferentes técnicas de otimização de desempenho.
Também recomendo nosso curso Projetando fluxos de trabalho de aprendizado de máquina em Python como a próxima etapa, em que você pode aprender a serializar e conteinerizar modelos de ML para produção.
Você está cansado de executar novamente seu código Python toda vez que precisa acessar um quadro de dados, uma variável ou um modelo de aprendizado de máquina criado anteriormente?
A serialização de objetos pode ser a solução que você está procurando.
É o processo de armazenar uma estrutura de dados na memória para que você possa carregá-la ou transmiti-la quando necessário, sem perder seu estado atual.
Aqui está um diagrama simples que explica como a serialização funciona:
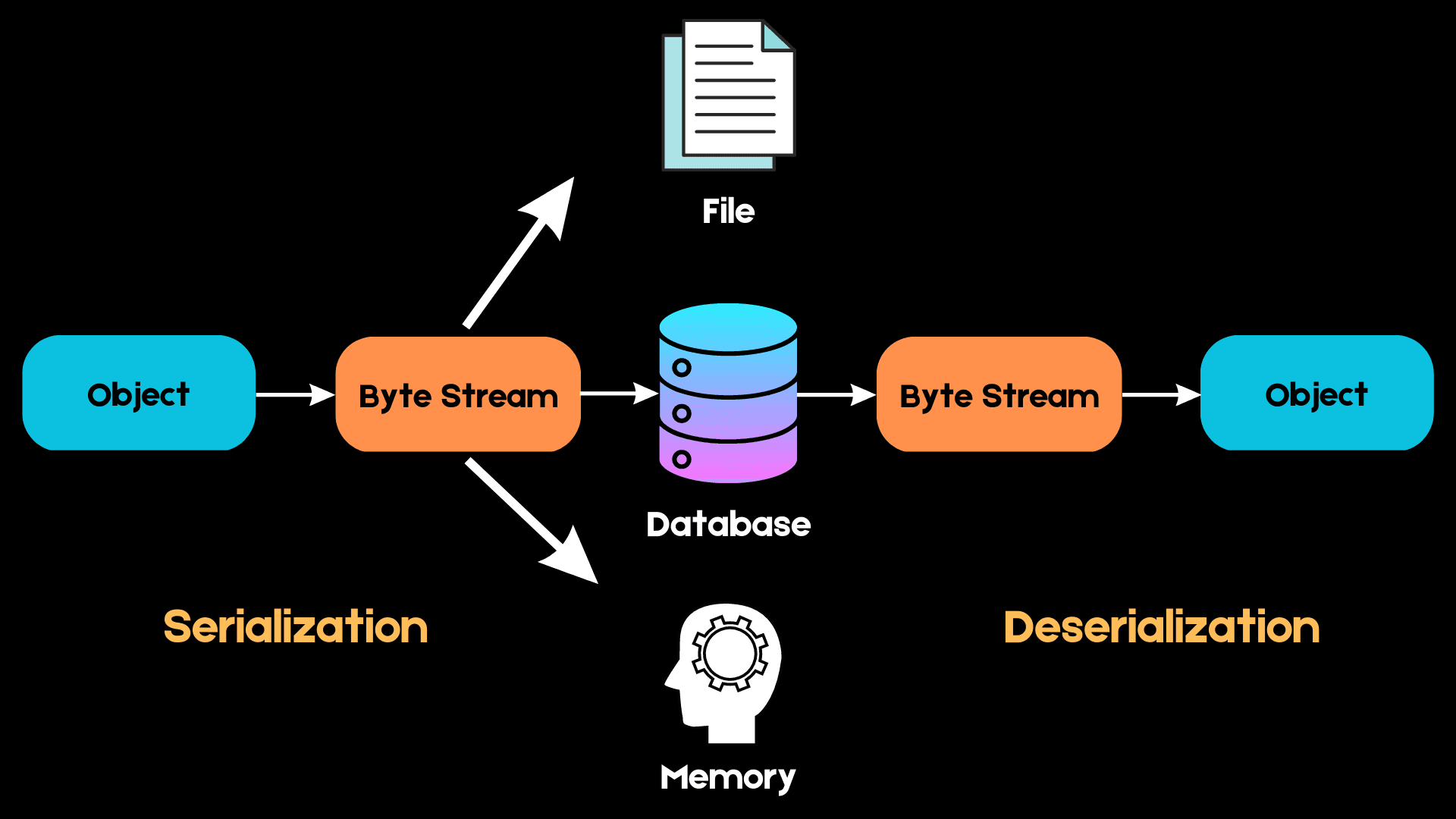
Imagem do autor
Em Python, trabalhamos com estruturas de dados de alto nível, como listas, tuplas e conjuntos. No entanto, quando queremos armazenar esses objetos na memória, eles precisam ser convertidos em uma sequência de bytes que o computador possa entender. Esse processo é chamado de serialização.
Na próxima vez que quisermos acessar a mesma estrutura de dados, essa sequência de bytes deverá ser convertida novamente no objeto de alto nível em um processo conhecido como desserialização.
Podemos usar formatos como JSON, XML, HDF5 e Pickle para serialização. Neste tutorial, aprenderemos sobre a biblioteca Python Pickle para serialização. Abordaremos seus usos e entenderemos quando você deve escolher o Pickle em vez de outros formatos de serialização.
Por fim, aprenderemos a usar a biblioteca Pickle Python para serializar listas, dicionários, quadros de dados do Pandas, modelos de aprendizado de máquina e muito mais.
Para executar facilmente todos os exemplos de código deste tutorial, você pode criar gratuitamente uma pasta de trabalho do DataLab que tenha o Python pré-instalado e contenha todos os exemplos de código. Para praticar mais o carregamento de arquivos em conserva do Python, confira este exercício prático do DataCamp.
Saiba mais sobre Python e aprendizado de máquina
Curso
Curso
Curso