Kurs
Unsupervised Learning in Python
4 Std.
179.7K
Bist du es leid, deinen Python-Code jedes Mal neu auszuführen, wenn du auf einen zuvor erstellten Datenrahmen, eine Variable oder ein Machine-Learning-Modell zugreifen musst?
Die Objektserialisierung könnte die Lösung sein, nach der du suchst.
Dabei wird eine Datenstruktur im Speicher gespeichert, damit du sie bei Bedarf laden oder übertragen kannst, ohne ihren aktuellen Zustand zu verlieren.
Hier ist ein einfaches Diagramm, das erklärt, wie die Serialisierung funktioniert:
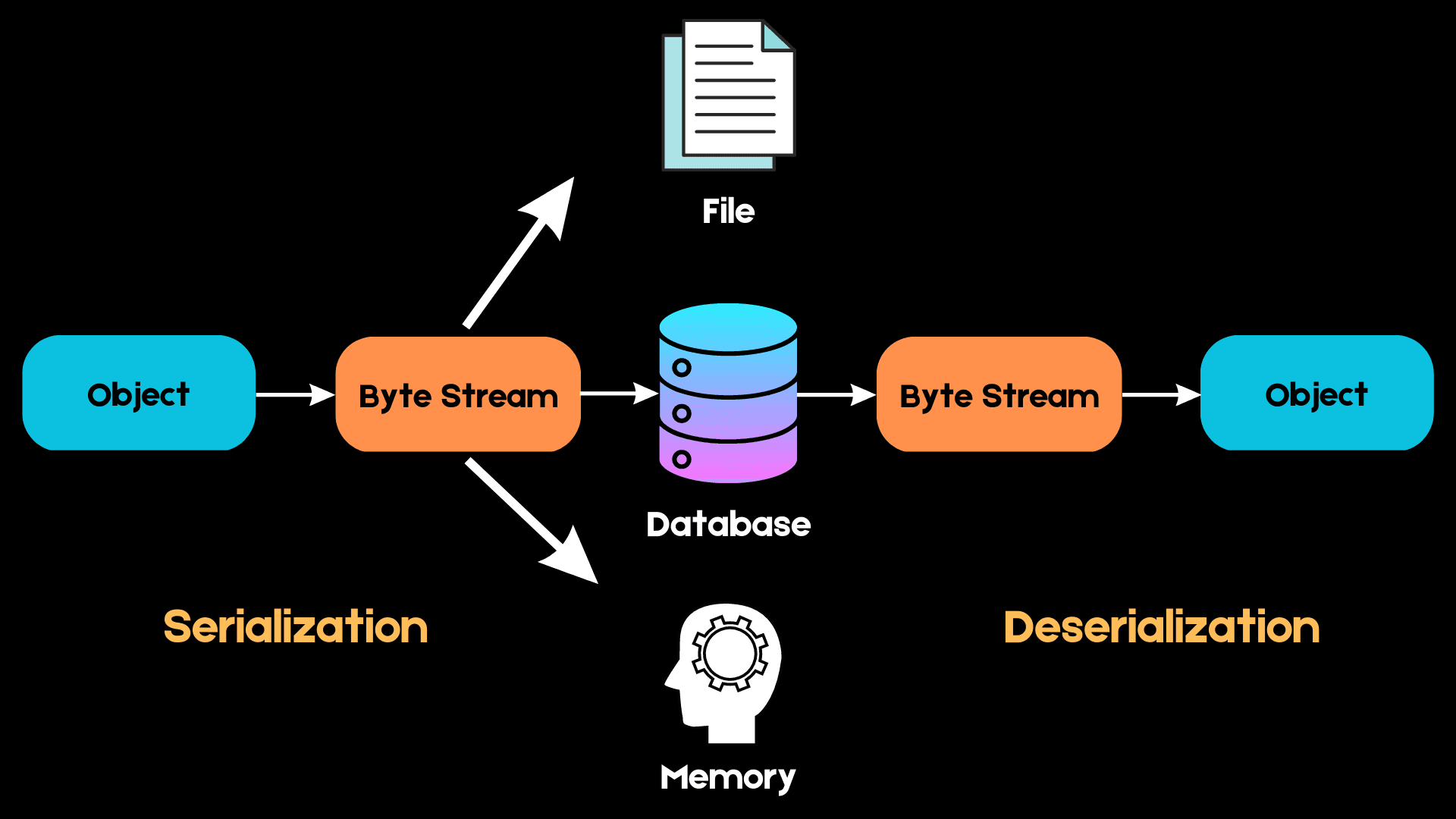
Bild vom Autor
In Python arbeiten wir mit High-Level-Datenstrukturen wie Listen, Tupeln und Mengen. Wenn wir diese Objekte jedoch im Speicher ablegen wollen, müssen sie in eine Folge von Bytes umgewandelt werden, die der Computer verstehen kann. Dieser Prozess wird Serialisierung genannt.
Wenn wir das nächste Mal auf dieselbe Datenstruktur zugreifen wollen, muss diese Bytefolge in einem Prozess, der als Deserialisierung bezeichnet wird, wieder in das High-Level-Objekt umgewandelt werden.
Wir können Formate wie JSON, XML, HDF5 und Pickle für die Serialisierung verwenden. In diesem Tutorium lernen wir die Python Pickle-Bibliothek zur Serialisierung kennen. Wir werden uns mit seinen Einsatzmöglichkeiten beschäftigen und erklären, wann du Pickle anderen Serialisierungsformaten vorziehen solltest.
Schließlich werden wir lernen, wie man die Pickle Python-Bibliothek verwendet, um Listen, Wörterbücher, Pandas-Datenrahmen, Modelle für maschinelles Lernen und mehr zu serialisieren.
Um den Beispielcode in diesem Lernprogramm ganz einfach selbst auszuführen, kannst du eine kostenlose DataLab-Arbeitsmappe erstellen, auf der Python vorinstalliert ist und die alle Codebeispiele enthält. Wenn du mehr über das Laden von Python-Pickled-Dateien erfahren möchtest, schau dir diese praktische DataCamp-Übung an.
Erfahre mehr über Python und maschinelles Lernen
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.