Cours
Apprentissage non supervisé en Python
4 h
179.6K
Êtes-vous fatigué de réexécuter votre code Python à chaque fois que vous avez besoin d'accéder à une base de données, à une variable ou à un modèle d'apprentissage automatique créé précédemment ?
La sérialisation d'objets est peut-être la solution que vous recherchez.
Il s'agit du processus de stockage d'une structure de données en mémoire, de sorte que vous puissiez la charger ou la transmettre en cas de besoin sans perdre son état actuel.
Voici un schéma simple expliquant le fonctionnement de la sérialisation :
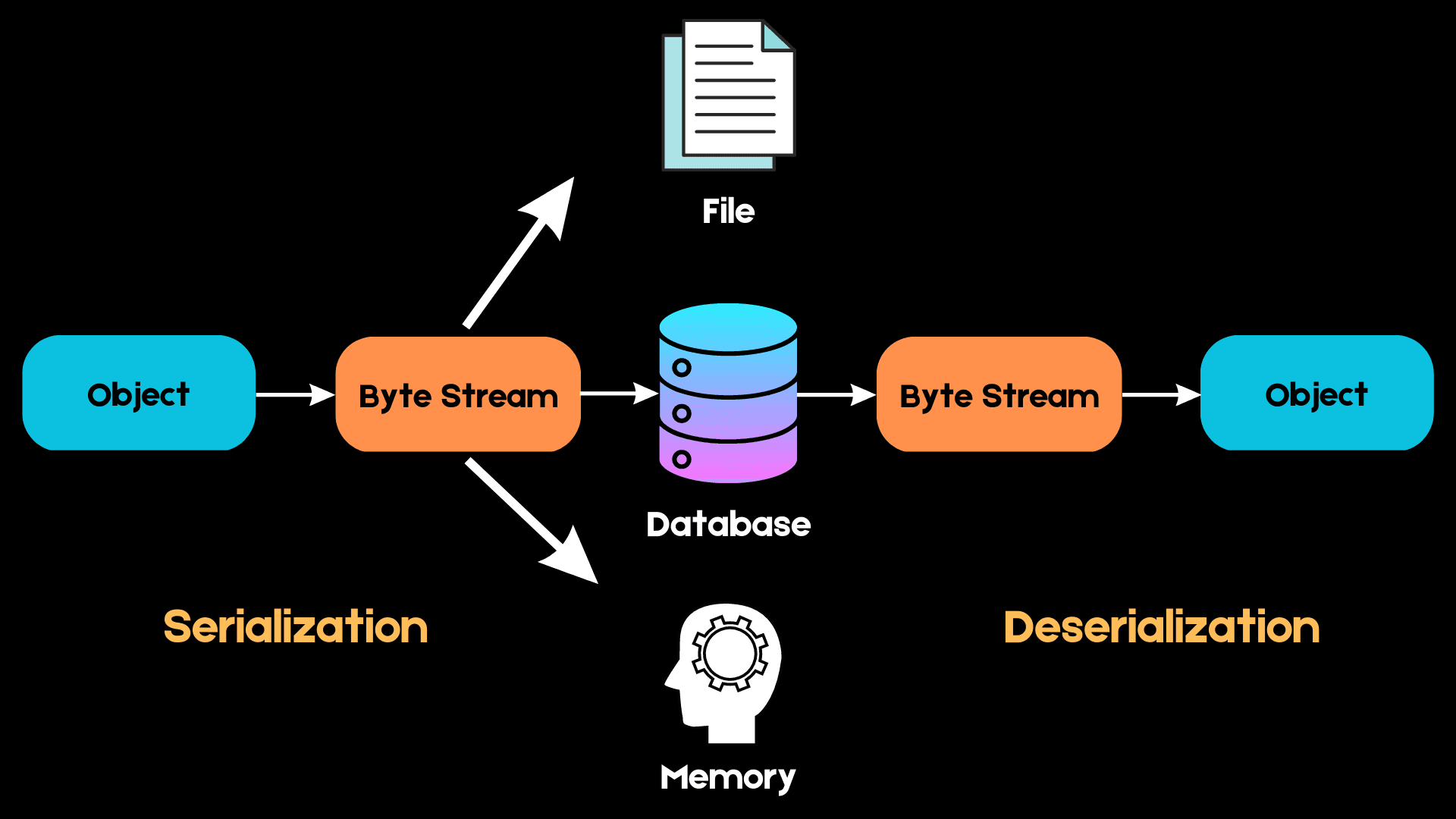
Image de l'auteur
En Python, nous travaillons avec des structures de données de haut niveau telles que les listes, les tuples et les ensembles. Cependant, lorsque nous voulons stocker ces objets en mémoire, ils doivent être convertis en une séquence d'octets que l'ordinateur peut comprendre. Ce processus est appelé sérialisation.
La prochaine fois que nous voudrons accéder à la même structure de données, cette séquence d'octets devra être reconvertie en objet de haut niveau dans le cadre d'un processus connu sous le nom de désérialisation.
Nous pouvons utiliser des formats tels que JSON, XML, HDF5 et Pickle pour la sérialisation. Dans ce tutoriel, nous allons découvrir la bibliothèque Pickle de Python pour la sérialisation. Nous allons couvrir ses utilisations et comprendre quand vous devriez choisir Pickle plutôt que d'autres formats de sérialisation.
Enfin, nous apprendrons à utiliser la bibliothèque Pickle Python pour sérialiser des listes, des dictionnaires, des cadres de données Pandas, des modèles d'apprentissage automatique, etc.
Pour exécuter facilement vous-même tous les exemples de code de ce tutoriel, vous pouvez créer gratuitement un classeur DataLab dans lequel Python est préinstallé et qui contient tous les exemples de code. Pour plus de pratique sur le chargement de fichiers Python, consultez cet exercice pratique de DataCamp.
En savoir plus sur Python et l'apprentissage automatique
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach