Curso
Google Sheets Intermediário
4 h
57.2K
Embora muitas organizações armazenem dados em bancos de dados e opções de armazenamento, como AWS, Azure e GCP, as planilhas do Microsoft Excel continuam a ser amplamente usadas para armazenar conjuntos de dados menores.
A funcionalidade de ciência de dados do Excel é mais limitada do que a do R, portanto, é útil poder importar dados de planilhas para o R.
Neste tutorial, abordaremos a leitura de planilhas do Excel (bem como de linhas e colunas específicas) no R usando o pacote readxl.
Para entender isso, você precisará de um conhecimento básico de R.
Para obter um guia mais geral sobre a importação de vários tipos diferentes de arquivos para o R, leia How to Import Data Into R (Como importar dados para o R): Um tutorial.
O conjunto de dados que leremos no R é pequeno, com apenas duas planilhas, para demonstrar como especificar a planilha a ser lida. Ele pode ser encontrado aqui.
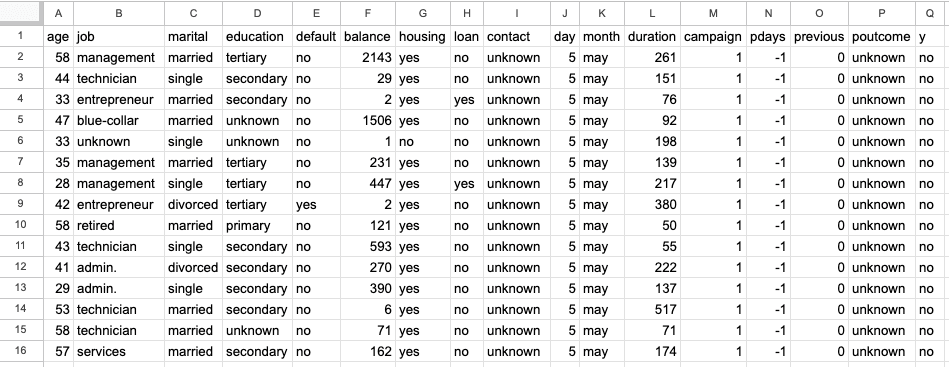
A primeira planilha é um conjunto de dados de marketing bancário com 45.211 linhas e 17 colunas. A captura de tela abaixo é do arquivo do Excel "sample.xlsx" e o nome da planilha é "bank-full".
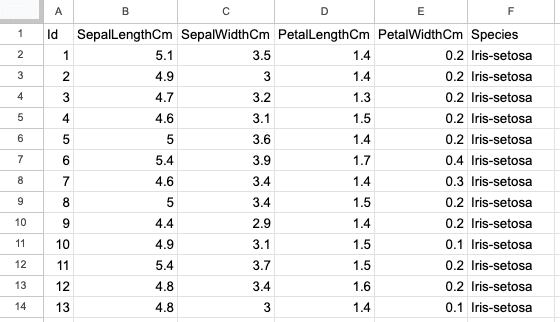
A segunda planilha é o conjunto de dados da Iris, com 150 linhas e 6 colunas, e contém informações sobre os tipos de flores da Iris, como o comprimento e a largura das sépalas e pétalas. A captura de tela abaixo é do mesmo arquivo do Excel, "sample.xlsx" e nome de planilha "iris".
Este tutorial usa o pacote readxl. O pacote openxlsx é uma alternativa decente que também inclui a capacidade de gravar em arquivos XLSX, mas tem uma integração menos forte com os pacotes do tidyverse, como o dplyr e o tidyr.
Para ler arquivos do Excel com o pacote readxl, precisamos instalar o pacote primeiro e depois importá-lo usando a função "library".
install.packages("readxl")Você verá a saída abaixo no console, indicando que a instalação foi bem-sucedida.
trying URL 'https://cran.rstudio.com/bin/macosx/big-sur-arm64/contrib/4.2/readxl_1.4.2.tgz'
Content type 'application/x-gzip' length 1545782 bytes (1.5 MB)
==================================================
downloaded 1.5 MB
The downloaded binary packages are in
/var/folders/mq/46mc_8tj06n0wh2xjkk08r140000gn/T//RtmpHIGYqM/downloaded_packagesPara usar os métodos "readxl", execute o comando abaixo no console do R.
library(readxl)Observe que o pacote openxlsx é outra boa alternativa para gravar em arquivos XLSX.
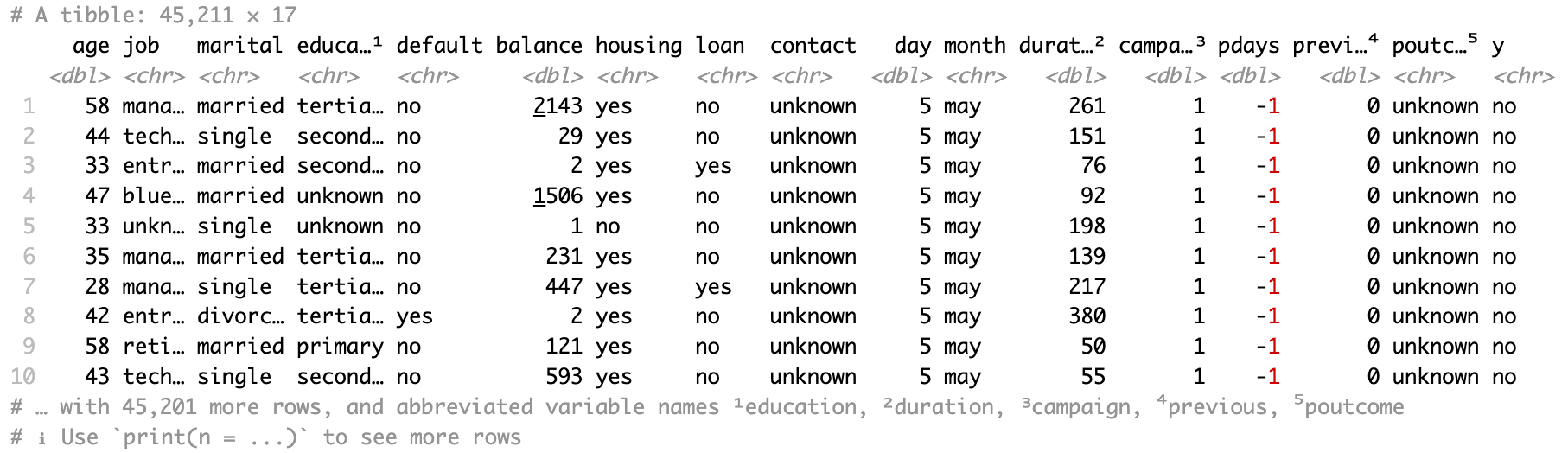
Vamos ler todos os dados da primeira planilha, "bank-full", com read_xlsx() e somente o argumento path.
bank_df <- read_xlsx(path = "sample.xlsx")Os dados resultantes são um tibble.
Você também pode usar read_excel() da mesma forma que read_xlsx(), e todos os argumentos que você verá nas próximas seções funcionam de forma semelhante com essa função. read_excel() tentará adivinhar se você tem uma planilha XLSX ou o tipo de planilha XLS mais antigo.
bank_df <- read_excel(path = "sample.xlsx")
Agora vamos ler todos os dados da segunda pasta de trabalho, ou seja, "iris", com a função read_xlsx() e o argumento sheet.
iris <- read_xlsx("sample.xlsx", sheet = "iris")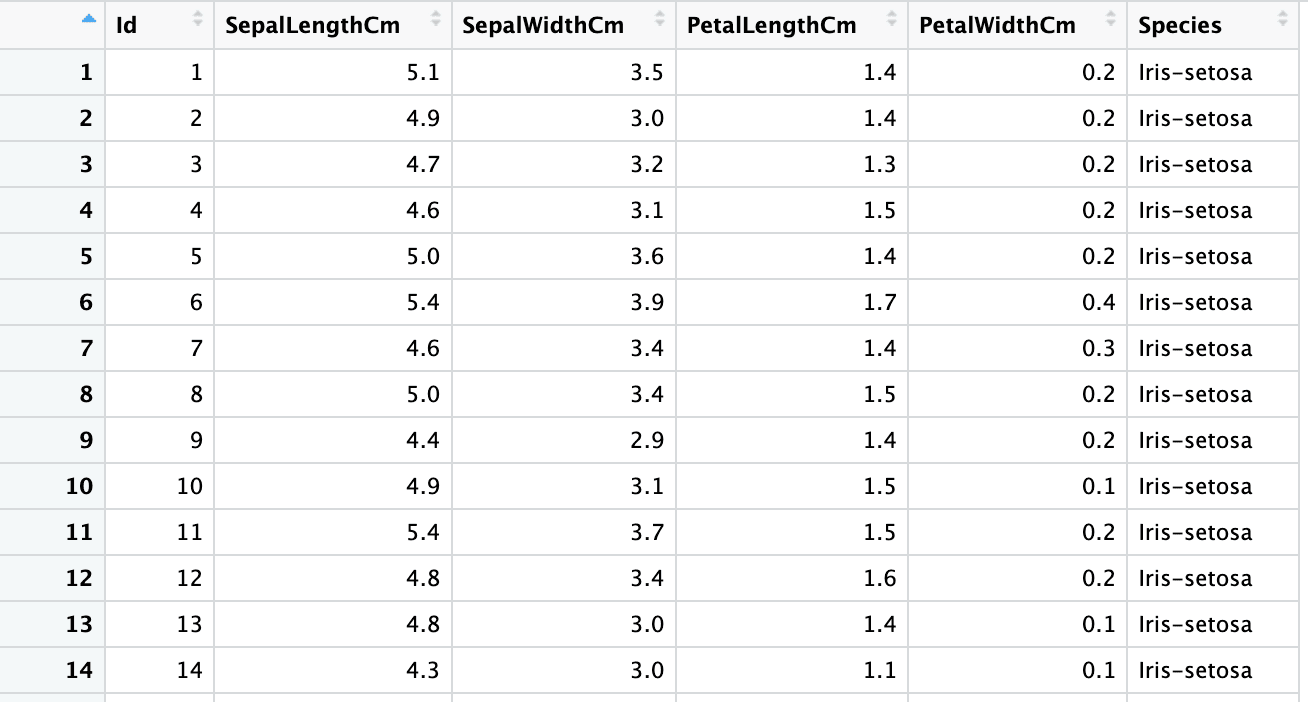
Você também pode especificar o número da planilha no argumento da planilha em vez do nome da planilha.
iris2 <- read_xlsx("sample.xlsx", sheet = 1)
Vamos ler linhas específicas de uma pasta de trabalho definindo os argumentos skip e n_max. Para ignorar as primeiras linhas, você pode usar o argumento skip com um valor igual ao número de linhas que deseja ignorar.
bank_df_s2 <- read_excel("sample.xlsx", sheet = "bank-full", skip = 2)Observe que o código acima também ignora os cabeçalhos. Nas seções seguintes, você aprenderá a especificar explicitamente os cabeçalhos na função read_xlsx().
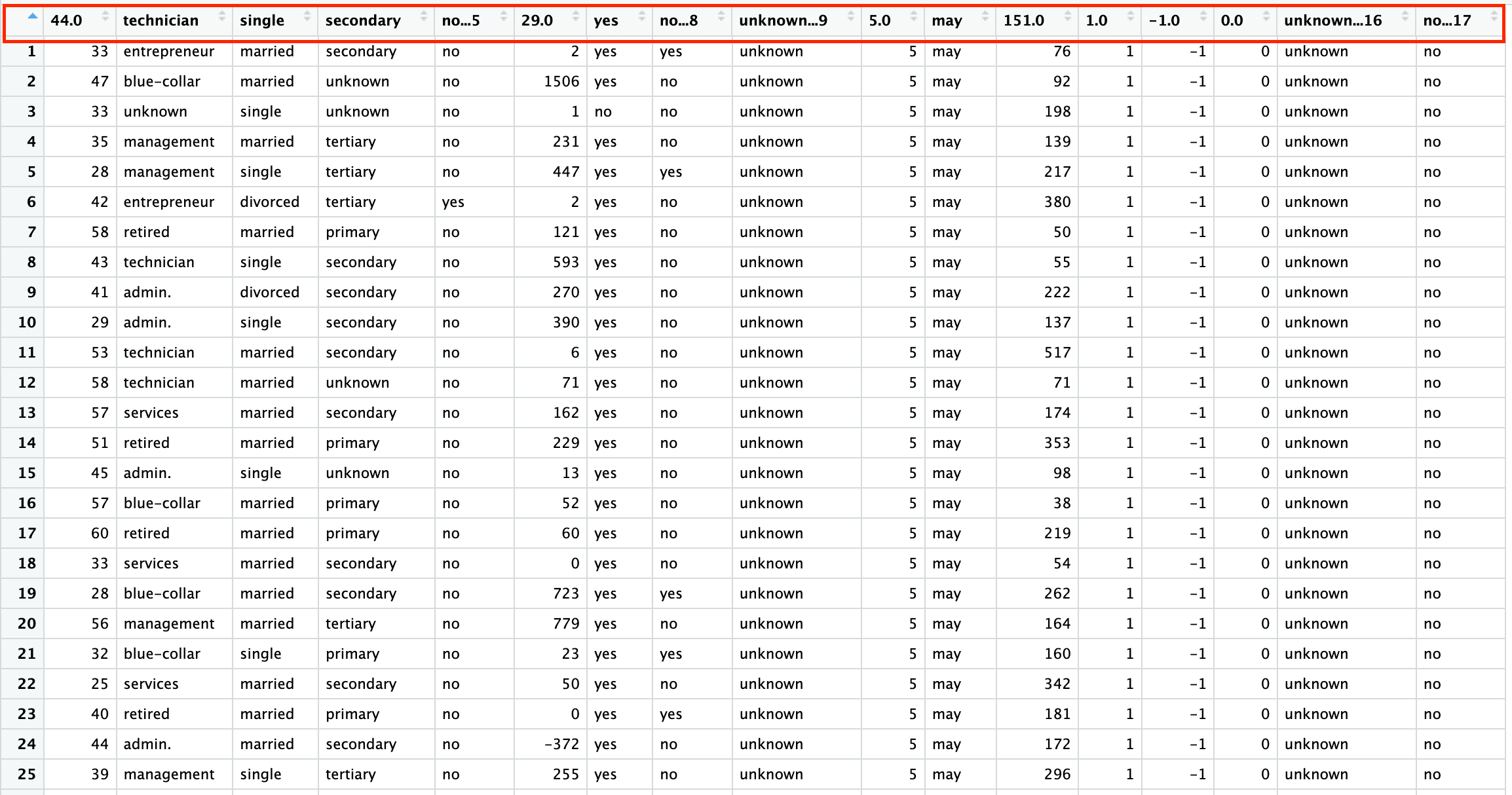
Da mesma forma, para ler as primeiras n linhas, especifique o argumento n_max na função read_xlsx(). O código abaixo lê as primeiras 1.000 linhas da planilha "bank-full".
bank_df_n1k <- read_excel("sample.xlsx", sheet = "bank-full", n_max = 1000)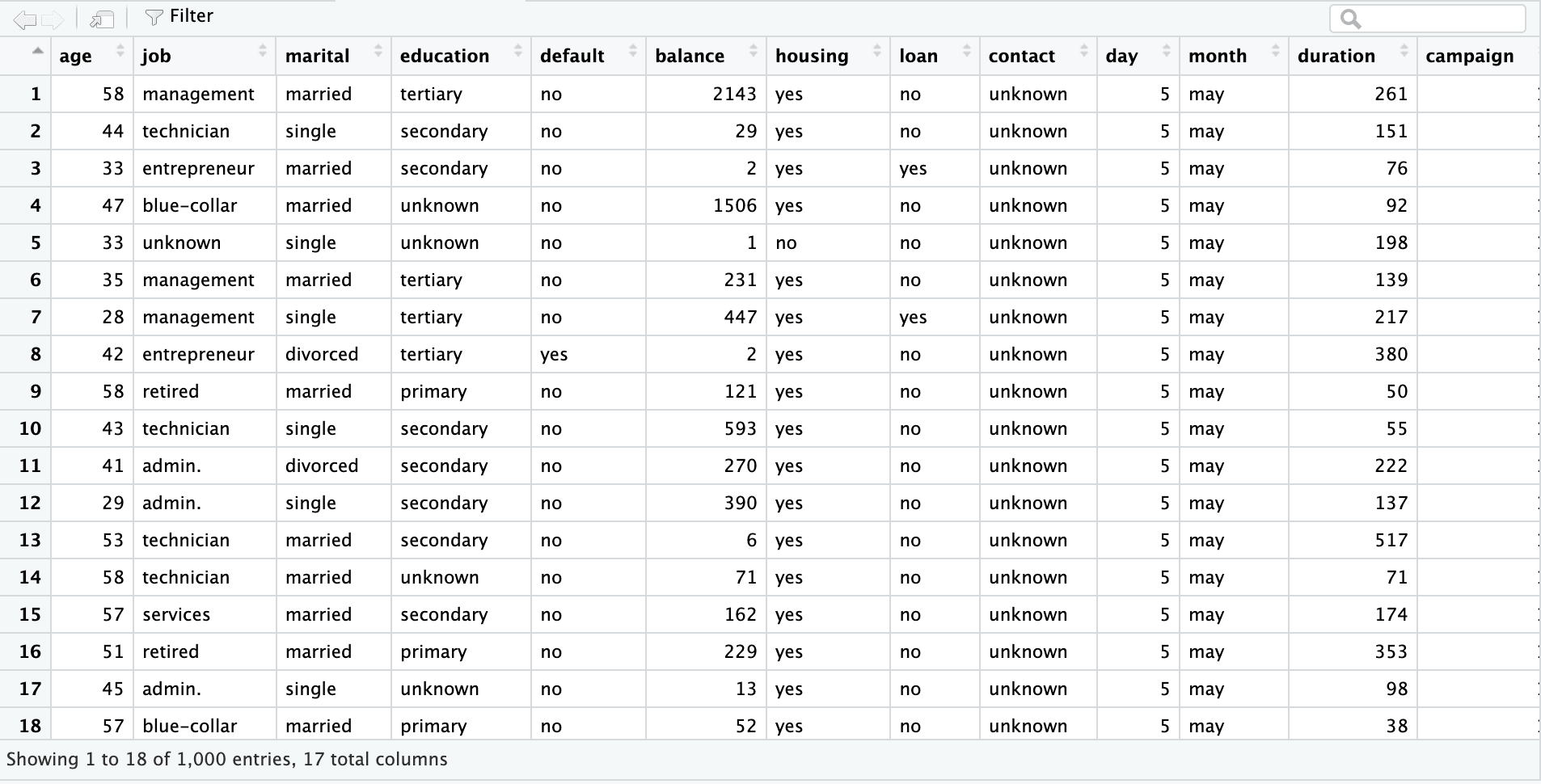
Você também pode combinar os dois argumentos para ignorar algumas linhas e ler um número específico de linhas do conjunto de dados restante.
Embora os argumentos "skip" e "n_max" permitam a leitura de um subconjunto das linhas dos dados, você pode ler células específicas de uma pasta de trabalho definindo o argumento range.
Há duas notações para especificar o subconjunto do conjunto de dados:
A ideia é especificar as coordenadas do retângulo que você deseja recortar do conjunto de dados.
Notação 1:
bank_df_range1 <- read_excel("sample.xlsx", sheet = "bank-full", range = "A3:E10")Notação 2:
bank_df_range2 <- read_excel("sample.xlsx", sheet = "bank-full",
range = "R3C1:R10C5")O intervalo também permite que você inclua o nome da planilha no argumento (exemplo: wbook!E4:G8).
bank_df_range3 <- read_excel("sample.xlsx", range = "bank-full!R3C1:R10C5")Vamos ler os dados que não têm linha de cabeçalho, definindo o argumento col_names como um vetor de caracteres.
PS: Estamos usando o argumento skip primeiro para remover a linha do cabeçalho.
columns <- c("ID", "Sepal Length", "Sepal Width", "Petal Length", "Petal Width", "Species Name")
iris3 <- read_excel("sample.xlsx", sheet = 2, skip = 1, col_names = columns)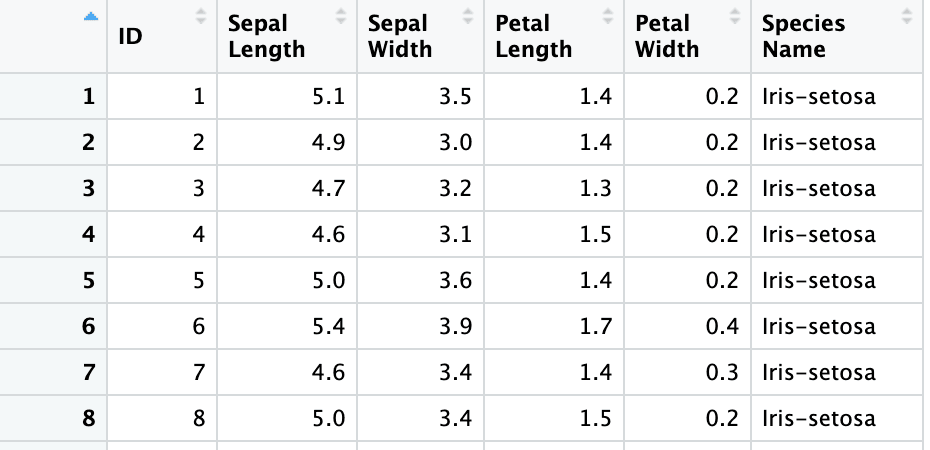
Na última seção, os cabeçalhos que especificamos foram separados por espaço. Você pode transformar os nomes de cabeçalho em variáveis sintáticas do R com o argumento .name_repair = "universal".
iris4 <- read_excel("sample.xlsx", sheet = 2, skip = 1,
col_names = columns, .name_repair = "universal")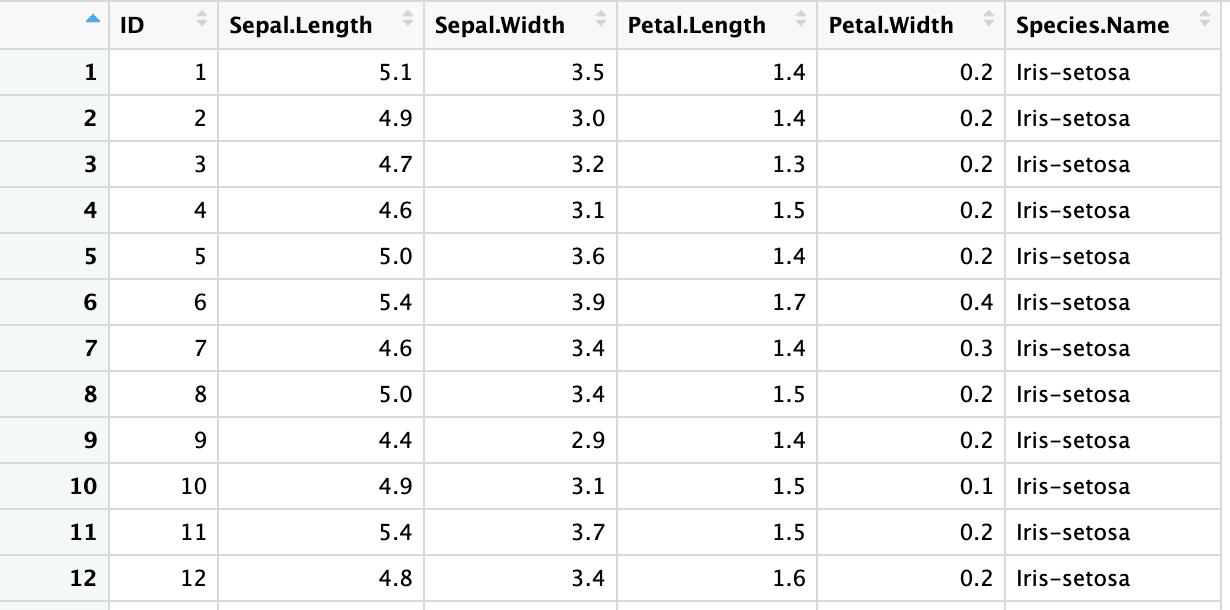
Por padrão, quando você lê um arquivo do Excel, o R adivinha o tipo de dados de cada variável. Vamos observar os tipos de coluna do conjunto de dados da íris lidos usando os argumentos padrão.
sapply(iris, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" Para substituir as suposições de tipo de coluna, você pode usar o argumento col_types.
iris5 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris5, class) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 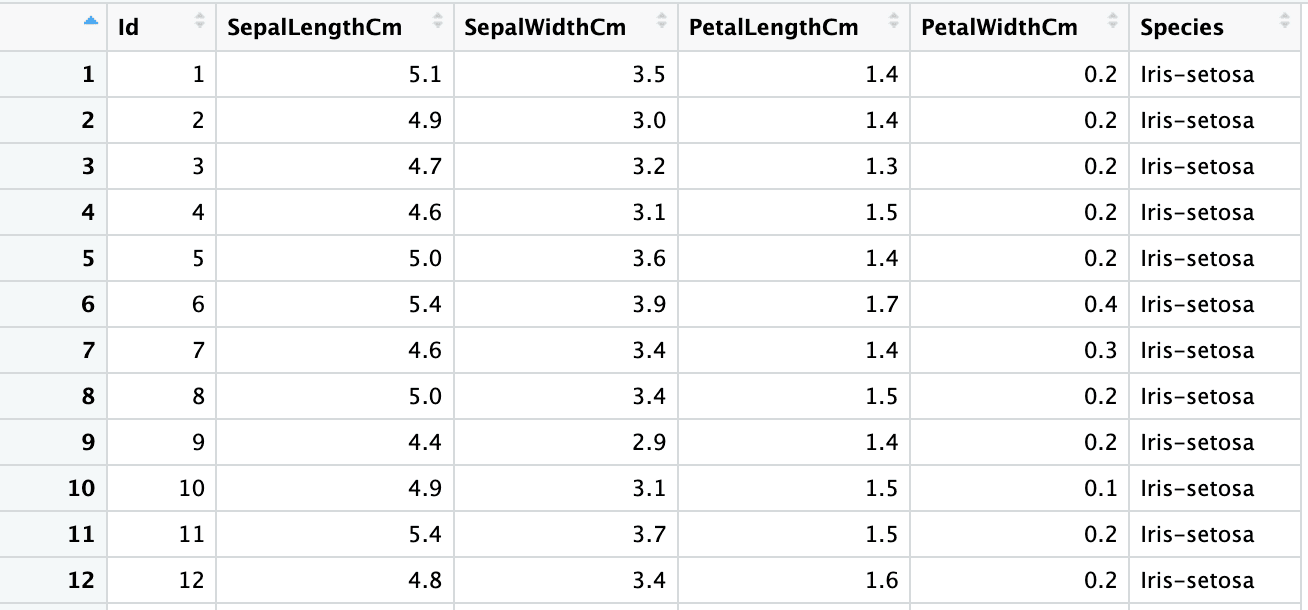
Você também pode permitir que o R adivinhe os tipos de coluna das variáveis selecionadas especificando o valor col_types como "guess" para uma determinada coluna.
iris6 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("guess", "numeric", "numeric", "numeric", "numeric", "text"))
sapply(iris6, class)Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
"numeric" "numeric" "numeric" "numeric" "numeric" "character" 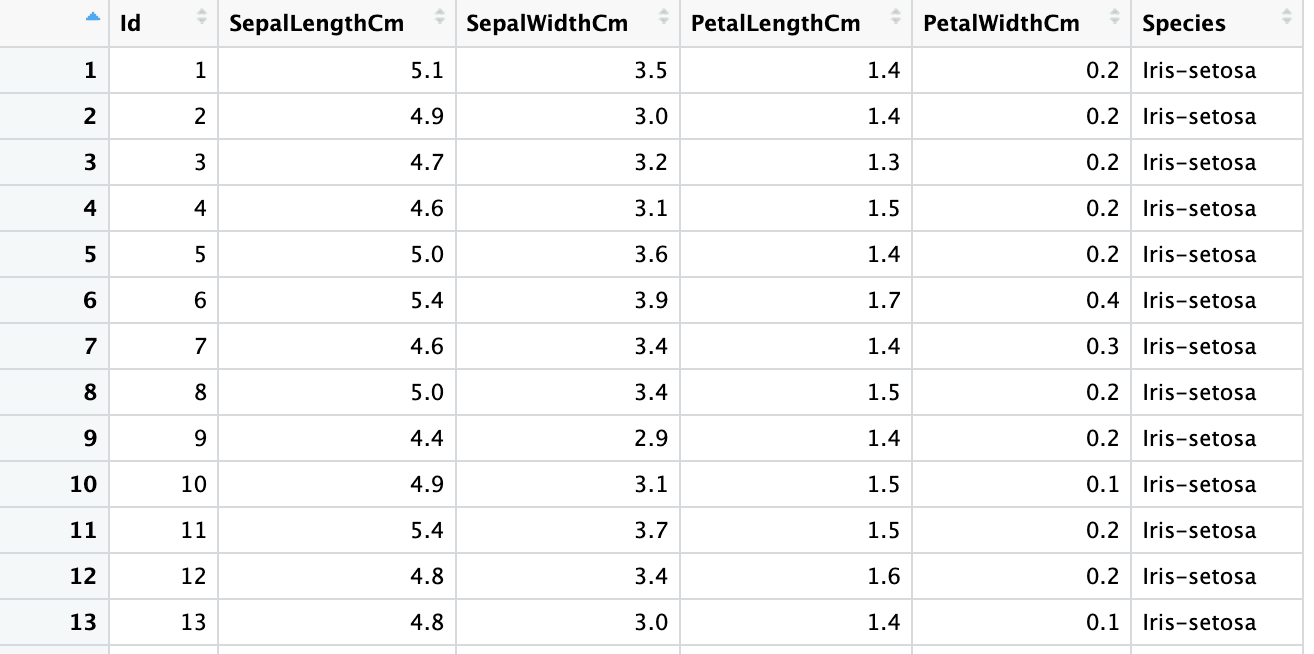
Embora muitas vezes você ouça as pessoas dizendo que quanto mais dados, melhor. Mas, em muitos casos de uso, você descobre que algumas das variáveis/colunas não contêm nenhum sinal, o que pode ser devido a qualquer um dos motivos abaixo.
Você pode ignorar a leitura de algumas colunas definindo col_types como "skip", conforme demonstrado abaixo.
iris7 <- read_excel("sample.xlsx", sheet = 2,
col_types = c("numeric", "skip", "skip", "numeric", "numeric", "text"))
sapply(iris7, class) Captura para o próximo nível
Captura para o próximo nívelEm um mundo em que os dados são gerados em um ritmo enorme e em formas variadas, sua linguagem de programação deve suportar a leitura desses tipos de dados. O R é uma das linguagens poderosas que dão suporte a esse esforço. Inscreva-se no curso "Introduction to Importing Data in R" para saber como o R oferece pacotes para importar conjuntos de dados variados. Este curso oferece tutoriais e testes para reforçar sua compreensão da importação de dados no R.
Saiba mais sobre o R e as planilhas
Curso
blog
Karlijn Willems
15 min
Tutorial
Natassha Selvaraj
Tutorial
Kurtis Pykes
Tutorial
Karlijn Willems
Tutorial
Ryan Sheehy