Com o surgimento dos modelos de linguagem grande (LLMs) e seus aplicativos, observamos um aumento na popularidade de ferramentas de integração, estruturas LLMOps e bancos de dados vetoriais. Isso ocorre porque trabalhar com LLMs requer uma abordagem diferente dos modelos tradicionais de aprendizado de máquina.
Uma das principais tecnologias de capacitação para LLMs é a incorporação de vetores. Embora os computadores não consigam entender diretamente o texto, os embeddings representam o texto numericamente. Todo o texto fornecido pelo usuário é convertido em embeddings, que são usados para gerar respostas.
A conversão de texto em incorporação é um processo demorado. Para evitar isso, temos bancos de dados de vetores projetados explicitamente para o armazenamento e a recuperação eficientes de embeddings de vetores.
Neste tutorial, aprenderemos sobre armazenamentos de vetores e o Chroma DB, um banco de dados de código aberto para armazenar e gerenciar embeddings. Além disso, aprenderemos a adicionar e remover documentos, realizar pesquisas de similaridade e converter nosso texto em embeddings.

Imagem do autor
O que são lojas de vetores?
Os armazenamentos de vetores são bancos de dados projetados explicitamente para armazenar e recuperar incorporação de vetores de forma eficiente. Eles são necessários porque os bancos de dados tradicionais, como o SQL, não são otimizados para armazenar e consultar dados vetoriais grandes.
Os embeddings representam dados (geralmente dados não estruturados, como texto) em formatos de vetores numéricos em um espaço de alta dimensão. Os bancos de dados relacionais tradicionais não são adequados para armazenar e pesquisar essas representações vetoriais.
Os armazenamentos de vetores podem indexar e pesquisar rapidamente vetores semelhantes usando algoritmos de similaridade. Ele permite que os aplicativos encontrem vetores relacionados a partir de uma consulta de vetor de destino.
No caso de um chatbot personalizado, o usuário insere um prompt para o modelo de IA generativo. Em seguida, o modelo procura textos semelhantes em uma coleção de documentos usando um algoritmo de pesquisa de similaridade. As informações resultantes são então usadas para gerar uma resposta altamente personalizada e precisa. Isso é possível por meio da incorporação e da indexação de vetores em armazenamentos de vetores.
O que é o Chroma DB?
O Chroma DB é um armazenamento de vetores de código aberto usado para armazenar e recuperar embeddings de vetores. Seu principal uso é salvar embeddings junto com metadados para serem usados posteriormente por grandes modelos de linguagem. Além disso, ele também pode ser usado para mecanismos de pesquisa semântica em dados de texto.
Principais recursos do Chroma DB:
- Oferece suporte a diferentes opções de armazenamento subjacente, como DuckDB para autônomo ou ClickHouse para escalabilidade.
- Fornece SDKs para Python e JavaScript/TypeScript.
- Concentra-se na simplicidade, na velocidade e na análise de habilitação.
O Chroma DB oferece uma opção de servidor auto-hospedado. Se você precisar de uma plataforma de banco de dados vetorial gerenciada, consulte o Pinecone Guide for Mastering Vector Databases.
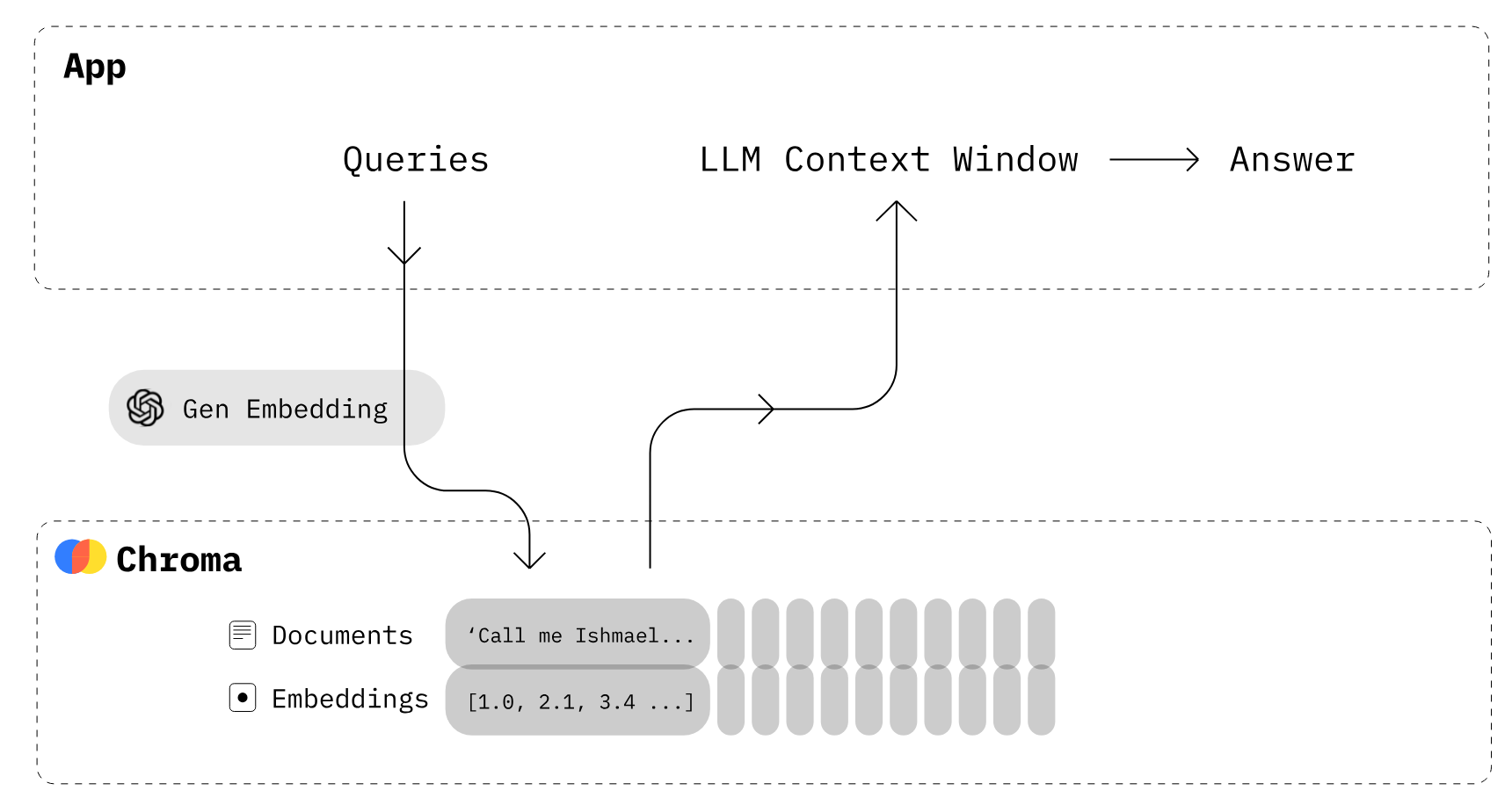
Imagem do Chroma
Como o Chroma DB funciona?
- Primeiro, você precisa criar uma coleção semelhante às tabelas no banco de dados de relações. Por padrão, o Chroma converte o texto em embeddings usando
all-MiniLM-L6-v2, mas você pode modificar a coleção para usar outro modelo de embedding. - Adicione documentos de texto à coleção recém-criada com metadados e um ID exclusivo. Quando sua coleção recebe o texto, ela o converte automaticamente em incorporação.
- Consulte a coleção por texto ou incorporação para receber documentos semelhantes. Você também pode filtrar os resultados com base em metadados.
Na próxima parte, usaremos o Chroma e a API OpenAI para criar nosso próprio banco de dados vetorial.
Primeiros passos com o Chroma DB
Nesta seção, criaremos um banco de dados vetorial, adicionaremos coleções, adicionaremos texto à coleção e realizaremos uma pesquisa de consulta.
Primeiro, instalaremos o chromadb para o banco de dados de vetores e o openai para obter um modelo de incorporação melhor. Certifique-se de que você configurou a chave da API da OpenAI.
Observação: O Chroma requer o SQLite versão 3.35 ou superior. Se você tiver problemas, atualize para o Python 3.11 ou instale uma versão mais antiga do chromadb.
!pip install chromadb openai Você pode criar um banco de dados na memória para testes, criando um cliente Chroma DB sem configurações.
No nosso caso, criaremos um banco de dados persistente que será armazenado no diretório "db/" e usaremos o DuckDB no backend.
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="db/"
))Depois disso, criaremos um objeto de coleção usando o cliente. É semelhante à criação de uma tabela em um banco de dados tradicional.
collection = client.create_collection(name="Students")Para adicionar texto à nossa coleção, precisamos gerar um texto aleatório sobre um aluno, um clube e uma universidade. Você pode gerar texto aleatório usando o ChatGPT. É muito simples.
student_info = """
Alexandra Thompson, a 19-year-old computer science sophomore with a 3.7 GPA,
is a member of the programming and chess clubs who enjoys pizza, swimming, and hiking
in her free time in hopes of working at a tech company after graduating from the University of Washington.
"""
club_info = """
The university chess club provides an outlet for students to come together and enjoy playing
the classic strategy game of chess. Members of all skill levels are welcome, from beginners learning
the rules to experienced tournament players. The club typically meets a few times per week to play casual games,
participate in tournaments, analyze famous chess matches, and improve members' skills.
"""
university_info = """
The University of Washington, founded in 1861 in Seattle, is a public research university
with over 45,000 students across three campuses in Seattle, Tacoma, and Bothell.
As the flagship institution of the six public universities in Washington state,
UW encompasses over 500 buildings and 20 million square feet of space,
including one of the largest library systems in the world.Agora, usaremos a função add para adicionar dados de texto com metadados e IDs exclusivos. Depois disso, o Chroma fará o download automático do modelo all-MiniLM-L6-v2 para converter o texto em embeddings e armazená-lo na coleção "Students".
collection.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Para executar uma pesquisa de similaridade, você pode usar a função query e fazer perguntas em linguagem natural. Ele converterá a consulta em incorporação e usará algoritmos de similaridade para chegar a resultados semelhantes. No nosso caso, ele está retornando dois resultados semelhantes.
results = collection.query(
query_texts=["What is the student name?"],
n_results=2
)
results
Embeddings
Você pode usar qualquer modelo de incorporação de alto desempenho da lista de incorporação. Você pode até mesmo criar suas funções de incorporação personalizadas.
Nesta seção, usaremos o modelo de incorporação da linha OpenAI chamado "text-embedding-ada-002" para converter texto em incorporação.
Depois de criar a função de incorporação do OpenAI, você pode adicionar a lista de documentos de texto para gerar incorporações.
Descubra como usar a API OpenAI para Text Embeddings e criar classificadores de texto, sistemas de recuperação de informações e detectores de similaridade semântica.
from chromadb.utils import embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
model_name="text-embedding-ada-002"
)
students_embeddings = openai_ef([student_info, club_info, university_info])
print(students_embeddings)[[-0.01015068031847477, 0.0070903063751757145, 0.010579396970570087, -0.04118313640356064, 0.0011583581799641252, 0.026857420802116394,....],]Em vez de usar o modelo de incorporação padrão, carregaremos as incorporações já criadas diretamente nas coleções.
- Usaremos a função
get_or_create_collectionpara criar uma nova coleção chamada "Students2". Essa função é diferente decreate_collection. Ele obterá uma coleção ou a criará se ela ainda não existir. - Agora, adicionaremos incorporação, documentos de texto, metadados e IDs à nossa coleção recém-criada.
collection2 = client.get_or_create_collection(name="Students2")
collection2.add(
embeddings = students_embeddings,
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Há também outro método mais direto. Você pode adicionar uma função de incorporação do OpenAI ao criar ou acessar a coleção. Além da OpenAI, você pode usar os modelos Cohere, Google PaLM, HuggingFace e Instructor.
No nosso caso, a adição de novos documentos de texto executará uma função de incorporação da OpenAI em vez do modelo padrão para converter texto em incorporações.
collection2 = client.get_or_create_collection(name="Students2",embedding_function=openai_ef)
collection2.add(
documents = [student_info, club_info, university_info],
metadatas = [{"source": "student info"},{"source": "club info"},{'source':'university info'}],
ids = ["id1", "id2", "id3"]
)Vamos ver a diferença executando uma consulta semelhante na nova coleção.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsNossos resultados melhoraram. A pesquisa de similaridade agora retorna informações sobre a universidade em vez de um clube. Além disso, a distância entre os vetores é menor do que a do modelo de incorporação padrão, o que é bom.

Atualização e remoção de dados
Assim como nos bancos de dados relacionais, você pode atualizar ou remover os valores das coleções. Para atualizar o texto e os metadados, forneceremos o ID específico para o registro e o novo texto.
collection2.update(
ids=["id1"],
documents=["Kristiane Carina, a 19-year-old computer science sophomore with a 3.7 GPA"],
metadatas=[{"source": "student info"}],
)Execute uma consulta simples para verificar se as alterações foram feitas com sucesso.
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsComo podemos ver, em vez de Alexandra, temos Kristiane.

Para remover um registro da coleção, usaremos a função `delete` e especificaremos um ID exclusivo.
collection2.delete(ids = ['id1'])
results = collection2.query(
query_texts=["What is the student name?"],
n_results=2
)
resultsO texto com as informações do aluno foi removido; em vez disso, obtemos os melhores resultados seguintes.

Gerenciamento de coleções
Nesta seção, aprenderemos sobre a função de utilidade de coleta que facilitará muito nossa vida.
Criaremos uma nova coleção chamada "vectordb" e adicionaremos as informações sobre a folha de dicas do Chroma DB, a documentação e a API JS com metadados.
vector_collections = client.create_collection("vectordb")
vector_collections.add(
documents=["This is Chroma DB CheatSheet",
"This is Chroma DB Documentation",
"This document Chroma JS API Docs"],
metadatas=[{"source": "Chroma Cheatsheet"},
{"source": "Chroma Doc"},
{'source':'JS API Doc'}],
ids=["id1", "id2", "id3"]
)Usaremos a função count() para verificar quantos registros a coleção tem.
vector_collections.count()3Para visualizar todos os registros da coleção, use a função .get().
vector_collections.get(){'ids': ['id1', 'id2', 'id3'],
'embeddings': None,
'documents': ['This is Chroma DB CheatSheet',
'This is Chroma DB Documentation',
'This document Chroma JS API Docs'],
'metadatas': [{'source': 'Chroma Cheatsheet'},
{'source': 'Chroma Doc'},
{'source': 'JS API Doc'}]}Para alterar o nome da coleção, use a função modify(). Para visualizar todos os nomes de coleções, use list_collections().
vector_collections.modify(name="chroma_info")
# list all collections
client.list_collections()Parece que, na verdade, renomeamos "vectordb" como "chroma_info".
[Collection(name=Students),
Collection(name=Students2),
Collection(name=chroma_info)]Para acessar qualquer nova coleção, você pode usar get_collection com o nome da coleção.
vector_collections_new = client.get_collection(name="chroma_info")Podemos excluir uma coleção usando a função de cliente delete_collection e especificar o nome da coleção.
client.delete_collection(name="chroma_info")
client.list_collections()[Collection(name=Students), Collection(name=Students2)]Podemos excluir toda a coleção do banco de dados usando client.reset(). No entanto, isso não é recomendado, pois não há como restaurar os dados após a exclusão.
client.reset()
client.list_collections()[]Conclusão
Os armazenamentos de vetores, como o Chroma DB, estão se tornando componentes essenciais de grandes sistemas de modelos de linguagem. Ao fornecer armazenamento especializado e recuperação eficiente de embeddings de vetores, eles permitem o acesso rápido a informações semânticas relevantes para potencializar os LLMs.
Neste tutorial do Chroma DB, abordamos os conceitos básicos de criação de uma coleção, adição de documentos, conversão de texto em embeddings, consulta de similaridade semântica e gerenciamento de coleções.
A próxima etapa do processo de aprendizado é integrar bancos de dados vetoriais ao seu aplicativo de IA generativa. Você pode facilmente ingerir, gerenciar e recuperar dados privados e específicos do domínio para seu aplicativo de IA seguindo o tutorial do LlamaIndex, que é uma estrutura de dados para aplicativos baseados em LLM (Large Language Model). Além disso, você pode seguir o tutorial How to Build LLM Applications with LangChain para mergulhar no mundo dos LLMOps.


