Curso
Análise de campanhas de marketing com pandas
4 h
33.7K
SettingWithCopyWarning é um aviso que o Pandas pode gerar quando fazemos uma atribuição a um DataFrame. Isso pode acontecer quando usamos atribuições encadeadas ou quando usamos um DataFrame criado a partir de uma fatia. Essa é uma fonte comum de erros no código do Pandas que todos nós já enfrentamos. Isso pode ser difícil de depurar porque o aviso pode aparecer em um código que parece funcionar bem.
Entender o site SettingWithCopyWarning é importante porque ele sinaliza possíveis problemas com a manipulação de dados. Esse aviso sugere que seu código pode não estar alterando os dados conforme pretendido, o que pode resultar em consequências não intencionais e bugs obscuros que são difíceis de rastrear.
Neste artigo, exploraremos o site SettingWithCopyWarning em pandas e como evitá-lo. Você pode encontrar o site em pandas e como evitá-lo. Também discutiremos o futuro do Pandas e como a opção copy_on_write mudará a forma como trabalhamos com DataFrames.
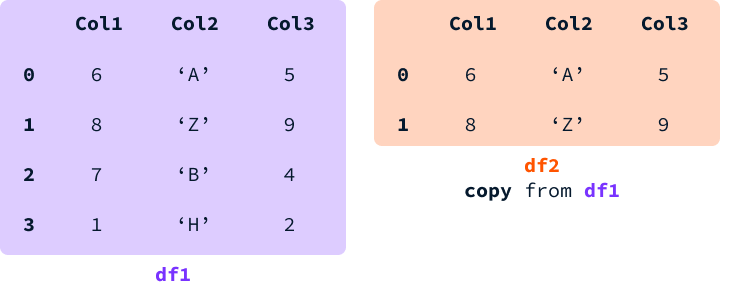
Quando selecionamos uma fatia de um DataFrame e a atribuímos a uma variável, podemos obter uma visualização ou uma nova cópia do DataFrame.
Com uma visualização, a memória entre os dois DataFrames é compartilhada. Isso significa que, ao modificar um valor de uma célula presente em ambos os DataFrames, você modificará os dois.

Com uma cópia, uma nova memória é alocada e um DataFrame independente com os mesmos valores que o original é criado. Nesse caso, os dois DataFrames são entidades distintas, portanto, a modificação de um valor em um deles não afeta o outro.
O Pandas tenta evitar a criação de uma cópia sempre que possível para otimizar o desempenho. No entanto, é impossível prever com antecedência se você receberá uma visualização ou uma cópia. O SettingWithCopyWarning é acionado sempre que atribuímos um valor a um DataFrame para o qual não está claro se é uma cópia ou uma visualização de outro DataFrame.
SettingWithCopyWarning com dados reaisUsaremos esse conjunto de dados do Kaggle Real Estate Data London 2024 para saber como ocorre o SettingWithCopyWarning e como corrigi-lo.
Esse conjunto de dados contém dados imobiliários recentes de Londres. Aqui está uma visão geral das colunas presentes no conjunto de dados:
addedOn: A data em que a listagem foi adicionada.title: O título da listagem.descriptionHtml: Uma descrição HTML da listagem.propertyType: O tipo de propriedade. O valor será "Not Specified" se o tipo não tiver sido especificado.sizeSqFeetMax: O tamanho máximo em pés quadrados.bedrooms: O número de quartos.listingUpdatedReason: Motivo para atualizar a listagem (por exemplo, nova listagem, redução de preço).price: O preço da listagem em libras.Digamos que você saiba que as propriedades com um tipo de propriedade não especificado são casas. Portanto, queremos atualizar todas as linhas com propertyType igual a "Not Specified" para "House". Uma maneira de fazer isso é filtrar as linhas com um tipo de propriedade não especificado em uma variável DataFrame temporária e atualizar os valores da coluna propertyType da seguinte maneira:
import pandas as pd
dataset_name = "realestate_data_london_2024_nov.csv"
df = pd.read_csv(dataset_name)
# Obtain all rows with unspecified property type
no_property_type = df[df["propertyType"] == "Not Specified"]
# Update the property type to “House” on those rows
no_property_type["propertyType"] = "House"A execução desse código fará com que o pandas produza o SettingWithCopyWarning:
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
no_property_type["propertyType"] = "House"O motivo disso é que o pandas não consegue saber se o no_property_type DataFrame é uma visualização ou uma cópia do df.
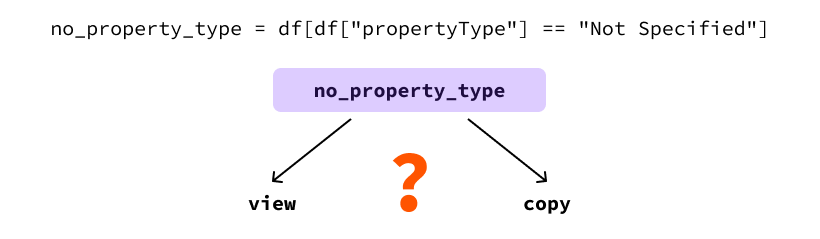
Isso é um problema porque o comportamento do código a seguir pode ser muito diferente, dependendo de você ser uma visualização ou uma cópia.
Neste exemplo, nosso objetivo é modificar o DataFrame original. Isso só ocorrerá se no_property_type for uma visualização. Se o restante do nosso código presumir que df foi modificado, ele pode estar errado porque não há como garantir que esse seja o caso. Devido a esse comportamento incerto, o Pandas lança o aviso para nos informar sobre esse fato.
Mesmo que o nosso código seja executado corretamente porque obtivemos uma visualização, podemos obter uma cópia em execuções subsequentes e o código não funcionará como pretendido. Portanto, é importante não ignorar esse aviso e garantir que nosso código sempre faça o que você deseja.
No exemplo anterior, está claro que uma variável temporária está sendo usada porque estamos atribuindo explicitamente parte do DataFrame a uma variável chamada no_property_type.
Entretanto, em alguns casos, isso não é tão explícito. O exemplo mais comum em que o SettingWithCopyWarning ocorre é com a indexação encadeada. Suponha que substituamos as duas últimas linhas por uma única linha:
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"À primeira vista, não parece que uma variável temporária esteja sendo criada. No entanto, sua execução também resulta em um SettingWithCopyWarning.
A maneira como esse código é executado é:
df[df["propertyType"] == "Not Specified"] é avaliado e armazenado temporariamente na memória. ["propertyType"] desse local de memória temporária é acessado. 
Os acessos ao índice são avaliados um a um e, portanto, a indexação encadeada resulta no mesmo aviso, pois não sabemos se os resultados intermediários são exibições ou cópias. O código acima é essencialmente o mesmo que você faz:
tmp = df[df["propertyType"] == "Not Specified"]
tmp["propertyType"] = "House"Esse exemplo costuma ser chamado de indexação encadeada porque encadeamos os acessos indexados usando []. Primeiro, acessamos [df["propertyType"] == "Not Specified"] e depois ["propertyType"].

SettingWithCopyWarningVamos aprender a escrever nosso código para que não haja ambiguidade e o SettingWithCopyWarning não seja acionado. Descobrimos que o aviso surge de uma ambiguidade sobre se um DataFrame é uma visualização ou uma cópia de outro DataFrame.
A maneira de corrigir isso é garantir que cada DataFrame que criamos seja uma cópia, se quisermos que seja uma cópia, ou uma exibição, se quisermos que seja uma exibição.
loc Vamos corrigir o código do exemplo acima, no qual queremos modificar o DataFrame original. Para evitar o uso de uma variável temporária, use a propriedade loc indexer.
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"Com esse código, estamos agindo diretamente no df DataFrame original por meio da propriedade loc indexer, portanto, não há necessidade de variáveis intermediárias. Isso é o que precisamos fazer quando quisermos modificar diretamente o DataFrame original.
À primeira vista, isso pode parecer uma indexação encadeada, pois ainda há parâmetros, mas não é assim. O que define cada indexação são os colchetes [].

Observe que o uso do loc só é seguro se atribuirmos um valor diretamente, como fizemos acima. Se, em vez disso, usarmos uma variável temporária, cairemos novamente no mesmo problema. Aqui estão dois exemplos de código que não corrigem o problema:
loc com uma variável temporária:# Using loc plus temporary variable doesn’t fix the issue
no_property_type = df.loc[df["propertyType"] == "Not Specified"]
no_property_type["propertyType"] = "House"loc junto com um índice (o mesmo que indexação encadeada):# Using loc plus indexing is the same as chained indexing
df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"Esses dois exemplos tendem a confundir as pessoas porque é um equívoco comum pensar que, enquanto houver um loc, estaremos modificando os dados originais. Isso está incorreto. A única maneira de garantir que o valor esteja sendo atribuído ao DataFrame original é atribuí-lo diretamente usando um único loc sem nenhuma indexação separada.
copy()Quando quisermos ter certeza de que estamos operando em uma cópia do DataFrame, devemos usar o método o método .copy() .
Digamos que nos peçam para analisar o preço por metro quadrado das propriedades. Não queremos modificar os dados originais. O objetivo é criar um novo DataFrame com os resultados da análise para enviar a outra equipe.
A primeira etapa é filtrar algumas linhas e limpar os dados. Especificamente, precisamos:
sizeSqFeetMax não está definido.price é "POA" (preço sob consulta)."£25,000,000").Você pode executar as etapas acima usando o código a seguir:
# 1. Filter out all properties without a size or a price
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")]
# 2. Remove the £ and , characters from the price columns
properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False)
# 3. Convert the price column to numeric values
properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])Para calcular o preço por pé quadrado, criamos uma nova coluna cujos valores são o resultado da divisão da coluna price pela coluna sizeSqFeetMax:
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]Se executarmos esse código, você receberá o endereço SettingWithCopyWarning novamente. Isso não deve ser uma surpresa, pois criamos e modificamos explicitamente uma variável DataFrame temporária properties_with_size_and_price.
Como queremos trabalhar em uma cópia dos dados em vez do DataFrame original, podemos corrigir o problema certificando-nos de que properties_with_size_and_price é uma cópia nova do DataFrame e não uma visualização, usando o método o método .copy() na primeira linha:
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()Adicionar novas colunas com segurança
A criação de novas colunas se comporta da mesma forma que a atribuição de valores. Sempre que for ambíguo se você estiver trabalhando com uma cópia ou com uma visualização, o pandas exibirá um SettingWithCopyWarning.
Se quisermos trabalhar com uma cópia dos dados, devemos copiá-los explicitamente usando o método .copy(). Então, você pode atribuir uma nova coluna da maneira que quiser. Fizemos isso quando criamos a coluna pricePerSqFt no exemplo anterior.
Por outro lado, se quisermos modificar o DataFrame original, há dois casos a serem considerados.
note para cada linha em que o tipo de casa estiver faltando: df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")loc. Por exemplo:df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"Observe que, nesse caso, o valor nas colunas que não foram selecionadas será indefinido, portanto, a primeira abordagem é preferível, pois nos permite especificar um valor para cada linha.
SettingWithCopyWarning Erro no Pandas 3.0No momento, o site SettingWithCopyWarning é apenas um aviso, não um erro. Nosso código ainda é executado, e o Pandas simplesmente nos informa que devemos ter cuidado.
De acordo com a a documentação oficial do PandasSettingWithCopyWarning não será mais usado a partir da versão 3.0 e será substituído por um error por padrão, impondo padrões de código mais rígidos.
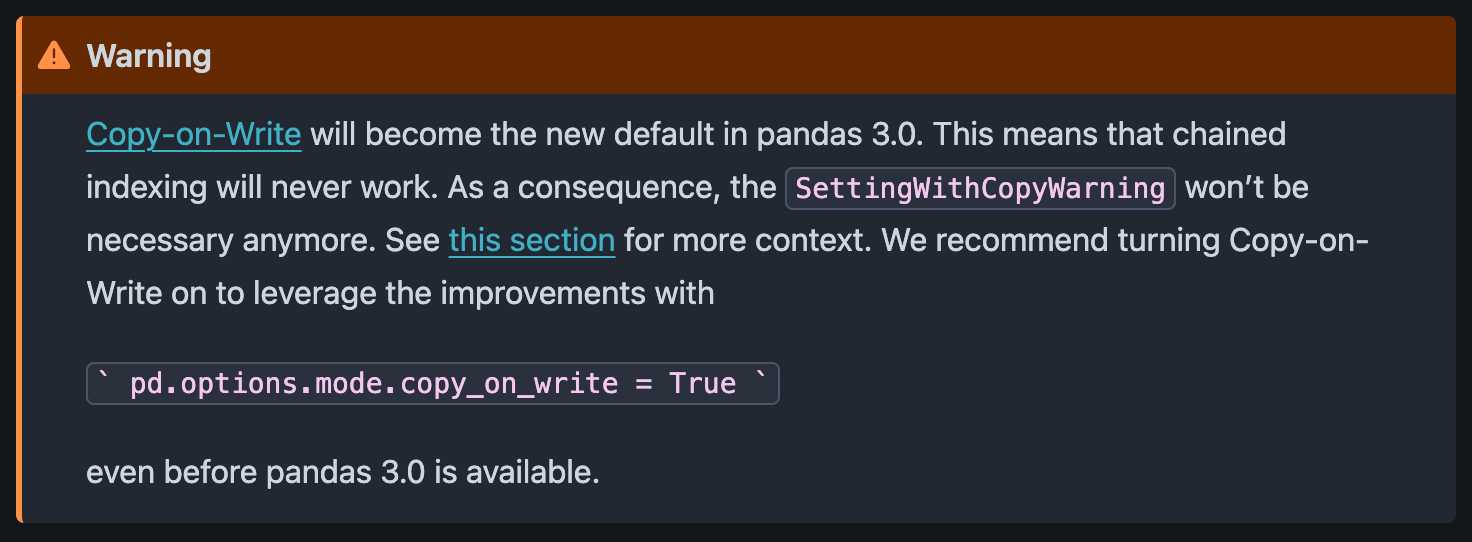
Para garantir que nosso código permaneça compatível com futuras versões do pandas, é recomendável que você já o atualize para gerar um erro em vez de um aviso.
Para isso, você deve definir a seguinte opção após a importação do pandas:
import pandas as pd
pd.options.mode.copy_on_write = TrueAo adicionar isso ao código existente, você se certificará de que lidamos com cada atribuição ambígua em nosso código e de que o código ainda funcionará quando atualizarmos para o pandas 3.0.
O SettingWithCopyWarning ocorre sempre que nosso código torna ambíguo se um valor que estamos modificando é uma visualização ou uma cópia. Podemos corrigir isso sendo sempre explícitos sobre o que queremos:
copy().loc indexer e atribuir o valor diretamente ao acessar os dados sem usar variáveis intermediárias.Apesar de não ser um erro, não devemos ignorar esse aviso, pois ele pode levar a resultados inesperados. Além disso, a partir do Pandas 3.0, isso se tornará um erro por padrão, portanto, devemos preparar nosso código para o futuro ativando a Copy-on-Write em nosso código atual usando o pd.options.mode.copy_on_write = True. Isso garantirá que o código permaneça funcional para futuras versões do Pandas.
Aprenda sobre Pandas com estes cursos!
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Karlijn Willems
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Kurtis Pykes

