
Course
Analyzing Marketing Campaigns with pandas
4 hr
33.7K
SettingWithCopyWarning is a warning that Pandas can raise when we do an assignment to a DataFrame. This can happen when we use chained assignments or when we use a DataFrame created from a slice. It's a common source of bugs in Pandas code that we've all faced before. It can be hard to debug because the warning can appear in code that looks like it should work fine.
Understanding the SettingWithCopyWarning is important because it signals potential issues with data manipulation. This warning suggests that your code may not be altering data as intended, which can result in unintended consequences and obscure bugs that are difficult to trace.
In this article, we will explore the SettingWithCopyWarning in pandas and how to avoid it. We will also discuss the future of Pandas and how the copy_on_write option will change how we work with DataFrames.
When we select a slice of a DataFrame and assign it to a variable, we can either get a view or a fresh DataFrame copy.
With a view, the memory between both DataFrames is shared. This means that modifying a value from a cell that is present in both DataFrames will modify both of them.

With a copy, new memory is allocated, and an independent DataFrame with the same values as the original one is created. In this case, both DataFrames are distinct entities, so modifying a value in one of them doesn’t affect the other.
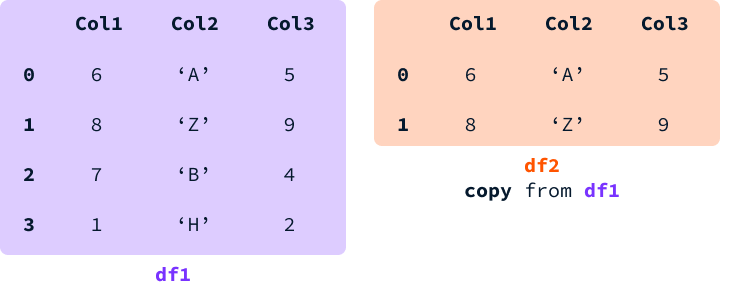
Pandas tries to avoid creating a copy when it can to optimize performance. However, it's impossible to predict in advance whether we will get a view or a copy. The SettingWithCopyWarning is raised whenever we assign a value to a DataFrame for which it is unclear whether it is a copy or a view from another DataFrame.
SettingWithCopyWarning with Real DataWe will use this Real Estate Data London 2024 Kaggle dataset to learn how the SettingWithCopyWarning occurs and how to fix it.
This dataset contains recent real estate data from London. Here's an overview of the columns present in the dataset:
addedOn: The date on which the listing was added.title: The title of the listing.descriptionHtml: An HTML description of the listing.propertyType: The type of the property. The value will be "Not Specified" if the type wasn't specified.sizeSqFeetMax: The maximum size in square feet.bedrooms: The number of bedrooms.listingUpdatedReason: Reason for updating the listing (e.g., new listing, price reduction).price: The price of the listing in pounds.Say we're told that the properties with an unspecified property type are houses. We thus want to update all rows with propertyType equal to "Not Specified" to "House". One way to do this is to filter the rows with a non-specified property type into a temporary DataFrame variable and update the propertyType column values like this:
import pandas as pd
dataset_name = "realestate_data_london_2024_nov.csv"
df = pd.read_csv(dataset_name)
# Obtain all rows with unspecified property type
no_property_type = df[df["propertyType"] == "Not Specified"]
# Update the property type to “House” on those rows
no_property_type["propertyType"] = "House"Executing this code will cause pandas to produce the SettingWithCopyWarning:
SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
no_property_type["propertyType"] = "House"The reason for this is that pandas can't know whether the no_property_type DataFrame is a view or a copy of df.
This is a problem because the behavior of the following code can be very different depending on whether it is a view or a copy.
In this example, our goal is to modify the original DataFrame. This will only happen if no_property_type is a view. If the rest of our code assumes that df was modified, it can be wrong because there’s no way to guarantee that this is the case. Because of this uncertain behavior, Pandas throws the warning to let us know about that fact.
Even if our code runs correctly because we got a view, we could get a copy in subsequent runs, and the code won’t work as intended. Therefore, it’s important not to ignore this warning and ensure our code will always do what we want it to do.
In the previous example, it’s clear that a temporary variable is being used because we're explicitly assigning part of the DataFrame to a variable named no_property_type.
However, in some cases, this is not so explicit. The most common example where SettingWithCopyWarning occurs is with chained indexing. Suppose that we replace the last two lines by a single line:
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"At first glance, it doesn't look like a temporary variable is being created. However, executing it results in a SettingWithCopyWarning as well.
The way this code is executed is:
df[df["propertyType"] == "Not Specified"] is evaluated and stored temporarily into memory. ["propertyType"] of that temporary memory location is accessed. 
Index accesses are evaluated one by one, and, therefore, chained indexing results in the same warning because we don't know if the intermediary results are views or copies. The above code is essentially the same as doing:
tmp = df[df["propertyType"] == "Not Specified"]
tmp["propertyType"] = "House"This example is often referred to as chained indexing because we chain indexed accesses using []. First, we access [df["propertyType"] == "Not Specified"] then ["propertyType"].

SettingWithCopyWarningLet’s learn how to write our code so that there's no ambiguity and the SettingWithCopyWarning isn't triggered. We learned that the warning arises from an ambiguity about whether a DataFrame is a view or a copy of another DataFrame.
The way to fix it is to ensure that each DataFrame we create is a copy if we want it to be a copy or a view if we want it to be a view.
loc Let’s fix the code from the example above where we want to modify the original DataFrame. To avoid using a temporary variable, use the loc indexer property.
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"With this code, we're acting directly on the original df DataFrame via the loc indexer property, so there's no need for intermediate variables. This is what we need to do when we want to modify the original DataFrame directly.
This may look like chained indexing at first glance because there are still parameters, but it isn’t. What defines each indexing is the square brackets [].

Note that using loc is only safe if we directly assign a value, as we did above. If we instead use a temporary variable, we again fall into the same problem. Here are two examples of code that do not fix the problem:
loc with a temporary variable:# Using loc plus temporary variable doesn’t fix the issue
no_property_type = df.loc[df["propertyType"] == "Not Specified"]
no_property_type["propertyType"] = "House"loc together with an index (same as chained indexing):# Using loc plus indexing is the same as chained indexing
df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"Both these examples tend to confuse people because it’s a common misconception that as long as there’s a loc, we’re modifying the original data. This is incorrect. The only way to ensure that the value is being assigned to the original DataFrame is to assign it directly using a single loc without any separate indexing.
copy()When we want to make sure we’re operating on a copy of the DataFrame, we should use the .copy() method.
Say we're asked to analyze the price per square foot of the properties. We don't want to modify the original data. The goal is to create a new DataFrame with the analysis results to send to another team.
The first step is to filter out some rows and clean the data. Specifically, we need to:
sizeSqFeetMax is not defined.price is "POA" (price on application)."£25,000,000")We can do the steps above using the following code:
# 1. Filter out all properties without a size or a price
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")]
# 2. Remove the £ and , characters from the price columns
properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False)
# 3. Convert the price column to numeric values
properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])To calculate the price per square foot, we create a new column whose values are the result of dividing price column by the sizeSqFeetMax column:
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]If we execute this code, we get the SettingWithCopyWarning again. This should be no surprise because we explicitly created and modified a temporary DataFrame variable properties_with_size_and_price.
Since we want to work on a copy of the data rather than the original DataFrame, we can fix the issue by making sure that properties_with_size_and_price is a fresh DataFrame copy and not a view by using the .copy() method on the first line:
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()Safely adding new columns
Creating new columns behaves in the same way as assigning values. Whenever it is ambiguous whether we are working with a copy or a view, pandas will raise a SettingWithCopyWarning.
If we want to work with a copy of the data, we should explicitly copy it using the .copy() method. Then, we are free to assign a new column in whichever way we want. We did this when we created the pricePerSqFt column in the previous example.
On the other hand, if we want to modify the original DataFrame there are two cases to consider.
note column for every row where the house type is missing: df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")loc indexer property. For example:df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"Note that in this case, the value on the columns that were not selected will be undefined so the first approach is preferred since it allows us to specify a value for each row.
SettingWithCopyWarning Error in Pandas 3.0Right now, SettingWithCopyWarning is only a warning, not an error. Our code is still executed, and Pandas simply inform us to be careful.
According to the official Pandas documentation, SettingWithCopyWarning won’t be used anymore starting with version 3.0 and will be replaced by an actual error by default, enforcing stricter code standards.
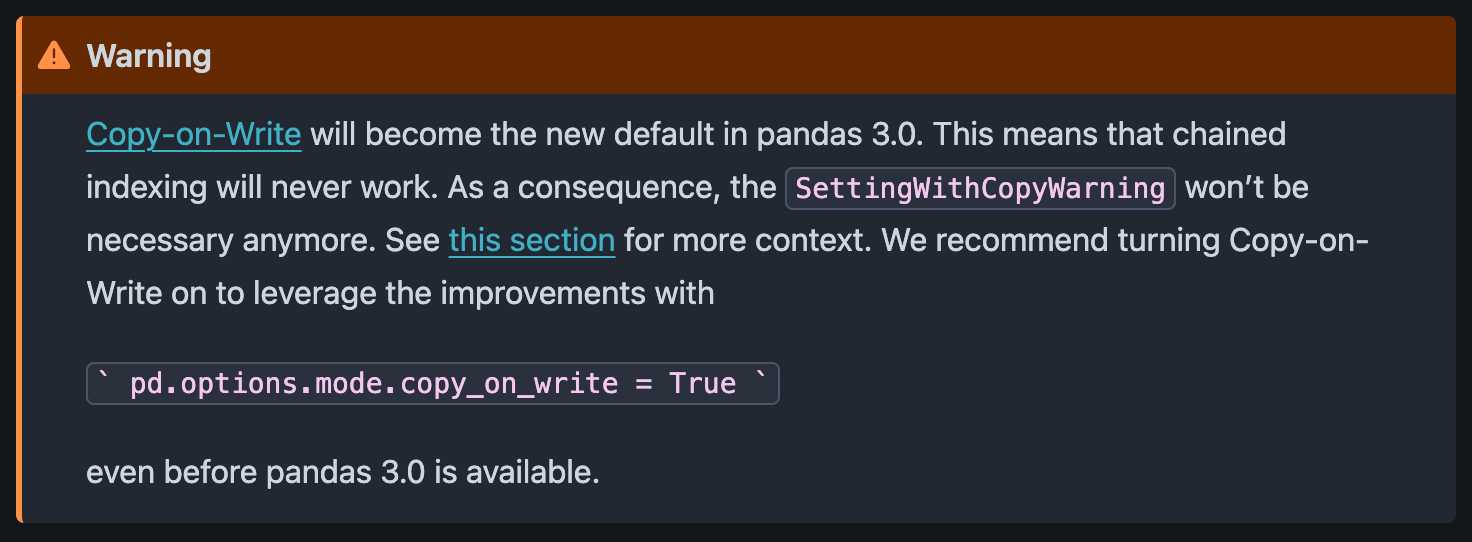
To make sure that our code remains compatible with future versions of pandas, it is recommended to already update it to raise an error instead of a warning.
This is done by setting the following option after importing pandas:
import pandas as pd
pd.options.mode.copy_on_write = TrueAdding this to existing code will make sure that we deal with each ambiguous assignment in our code and make sure that the code still works when we update to pandas 3.0.
The SettingWithCopyWarning occurs whenever our code makes it ambiguous whether a value we’re modifying is a view or a copy. We can fix it by always being explicit about what we want:
copy() method.loc indexer property and assign the value directly when accessing the data without using intermediate variables.Despite not being an error, we should not ignore this warning because it can lead to unexpected results. Moreover, starting with Pandas 3.0, it will become an error by default, so we should future-proof our code by turning on Copy-on-Write in our current code using the pd.options.mode.copy_on_write = True. This will ensure that the code remains functional for future versions of Pandas.
To learn more about Pandas, consider these resources:
Learn Pandas with these courses!
Course
Course
Course
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
