Python for Spreadsheet Users
BeginnerSkill Level
4 h
29.1K learners
Execute e edite o código deste tutorial online
Executar códigoA instalação do pandas é simples; basta usar o comando pip install em seu terminal.
pip install pandasComo alternativa, você pode instalá-lo via conda:
conda install pandasDepois de instalar o pandas, é uma boa prática verificar a versão instalada para garantir que tudo esteja funcionando corretamente:
import pandas as pd
print(pd.__version__) # Prints the pandas versionIsso confirma que o pandas está instalado corretamente e permite que você verifique a compatibilidade com outros pacotes.
Para começar a trabalhar com o pandas, importe o pacote Python pandas, conforme mostrado abaixo. Ao importar pandas, o alias mais comum para pandas é pd.
import pandas as pdUse read_csv() com o caminho para o arquivo CSV para ler um arquivo de valores separados por vírgula (consulte nosso tutorial sobre importação de dados com read_csv() para obter mais detalhes).
df = pd.read_csv("diabetes.csv")Essa operação de leitura carrega o arquivo CSV diabetes.csv para gerar um objeto Dataframe do pandas df. Ao longo deste tutorial, você verá como manipular esses objetos DataFrame.
A leitura de arquivos de texto é semelhante à de arquivos CSV. A única nuance é que você precisa especificar um separador com o argumento sep, conforme mostrado abaixo. O argumento separador refere-se ao símbolo usado para separar as linhas em um DataFrame. Vírgula (sep = ","), espaço em branco (sep = "\s"), tabulação (sep = "\t") e dois pontos (sep = ":") são os separadores comumente usados. Aqui, \s representa um único caractere de espaço em branco.
df = pd.read_csv("diabetes.txt", sep="\s")Ler arquivos do Excel (XLS e XLSX) é tão fácil quanto a função read_excel(), usando o caminho do arquivo como entrada.
df = pd.read_excel('diabetes.xlsx')Você também pode especificar outros argumentos, como header for para especificar qual linha se torna o cabeçalho do DataFrame. Tem um valor padrão de 0, que indica a primeira linha como cabeçalhos ou nomes de colunas. Você também pode especificar os nomes das colunas como uma lista no argumento names. O argumento index_col (o padrão é None) pode ser usado se o arquivo contiver um índice de linha.
Observação: Em um pandas DataFrame ou Series, o índice é um identificador que aponta para o local de uma linha ou coluna em um pandas DataFrame. Em resumo, o índice rotula a linha ou coluna de um DataFrame e permite que você acesse uma linha ou coluna específica usando seu índice (você verá isso mais adiante). O índice de linha de um DataFrame pode ser um intervalo (por exemplo, 0 a 303), uma série temporal (datas ou carimbos de data/hora), um identificador exclusivo (por exemplo, employee_ID em uma tabelaemployees ) ou outros tipos de dados. Para colunas, geralmente é uma cadeia de caracteres (denotando o nome da coluna).
A leitura de arquivos do Excel com várias planilhas não é muito diferente. Você só precisa especificar um argumento adicional, sheet_name, no qual você pode passar uma string para o nome da planilha ou um número inteiro para a posição da planilha (observe que o Python usa a indexação 0, em que a primeira planilha pode ser acessada com sheet_name = 0)
# Extracting the second sheet since Python uses 0-indexing
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)Semelhante à função read_csv(), você pode usar read_json() para tipos de arquivo JSON com o nome do arquivo JSON como argumento (para obter mais detalhes, leia este tutorial sobre a importação de dados JSON e HTML para o pandas). O código abaixo lê um arquivo JSON do disco e cria um objeto DataFrame df.
df = pd.read_json("diabetes.json")Se você quiser saber mais sobre a importação de dados com o pandas, confira esta folha de dicas sobre a importação de vários tipos de arquivos com o Python.
Para carregar dados de um banco de dados relacional, use pd.read_sql() junto com uma conexão de banco de dados.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Para grandes conjuntos de dados, considere o uso do SQLAlchemy para otimizar as consultas.
Se os dados forem provenientes de uma API da Web, o pandas poderá lê-los diretamente usando pd.read_json():
df = pd.read_json("https://api.example.com/data.json")Se a resposta da API for paginada ou estiver em um formato JSON aninhado, você poderá precisar de processamento adicional usando json_normalize() de pandas.io.json.
Assim como o pandas pode importar dados de vários tipos de arquivos, ele também permite que você exporte dados para vários formatos. Isso acontece especialmente quando os dados são transformados usando o pandas e precisam ser salvos localmente em seu computador. A seguir, você verá como produzir DataFrames do pandas em vários formatos.
Um DataFrame do pandas (aqui estamos usando df) é salvo como um arquivo CSV usando o método .to_csv(). Os argumentos incluem o nome do arquivo com o caminho e index - em que index = True implica a gravação do índice do DataFrame.
df.to_csv("diabetes_out.csv", index=False)Exporte o objeto DataFrame para um arquivo JSON chamando o método .to_json().
df.to_json("diabetes_out.json")Observação: Um arquivo JSON armazena um objeto tabular, como um DataFrame, como um par de valores-chave. Assim, você observaria a repetição de cabeçalhos de coluna em um arquivo JSON.
Assim como na gravação de DataFrames em arquivos CSV, você pode chamar .to_csv(). As únicas diferenças são que o formato do arquivo de saída está em .txt e você precisa especificar um separador usando o argumento sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Chame .to_excel() do objeto DataFrame para salvá-lo como um arquivo “.xls” ou “.xlsx”.
df.to_excel("diabetes_out.xlsx", index=False)Depois de ler dados tabulares como um DataFrame, você precisará ter uma visão geral dos dados. Você pode visualizar uma pequena amostra do conjunto de dados ou um resumo dos dados na forma de estatísticas resumidas.
.head() e .tail()Você pode visualizar as primeiras ou as últimas linhas de um DataFrame usando os métodos .head() ou .tail(), respectivamente. Você pode especificar o número de linhas por meio do argumento n (o valor padrão é 5).
df.head()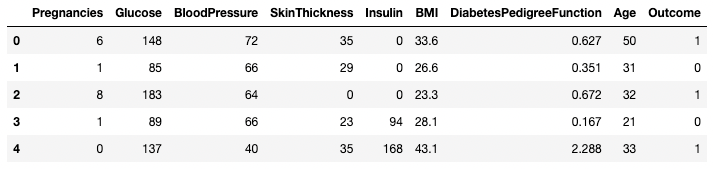
As primeiras cinco linhas do DataFrame
df.tail(n = 10)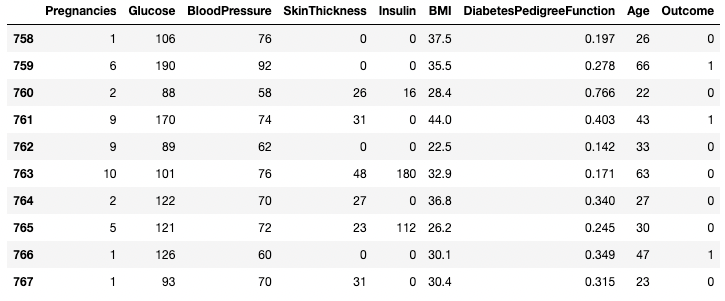
Primeiras 10 linhas do DataFrame
.describe()O método .describe() imprime as estatísticas resumidas de todas as colunas numéricas, como contagem, média, desvio padrão, intervalo e quartis de colunas numéricas.
df.describe()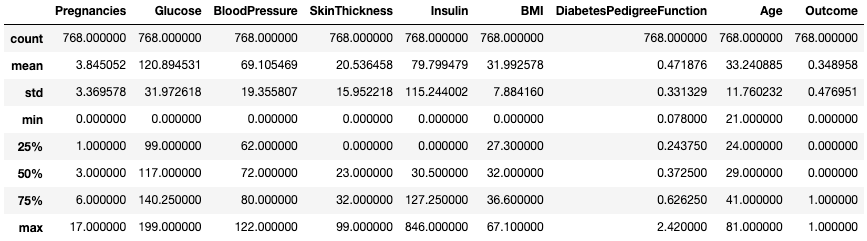
Obtenha estatísticas resumidas com .describe()
Ele oferece uma visão rápida da escala, da inclinação e do intervalo dos dados numéricos.
Você também pode modificar os quartis usando o argumento percentiles. Aqui, por exemplo, estamos analisando os percentis de 30%, 50% e 70% das colunas numéricas no DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])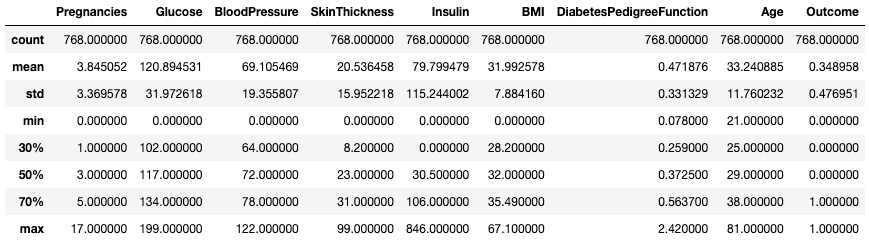
Obter estatísticas resumidas com percentis específicos
Você também pode isolar tipos de dados específicos na saída do resumo usando o argumento include. Aqui, por exemplo, estamos resumindo apenas as colunas com o tipo de dados integer.
df.describe(include=[int])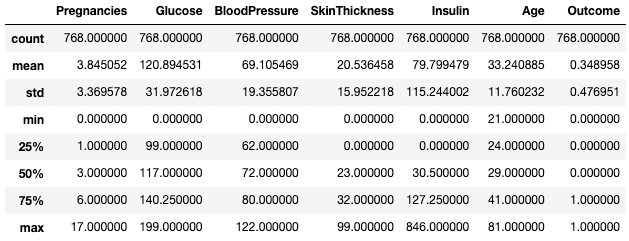
Obter estatísticas resumidas somente de colunas inteiras
Da mesma forma, você pode querer excluir determinados tipos de dados usando o argumento exclude.
df.describe(exclude=[int])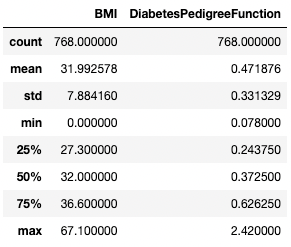
Obter estatísticas resumidas somente de colunas não inteiras
Muitas vezes, os profissionais acham fácil visualizar essas estatísticas transpondo-as com o atributo .T.
df.describe().T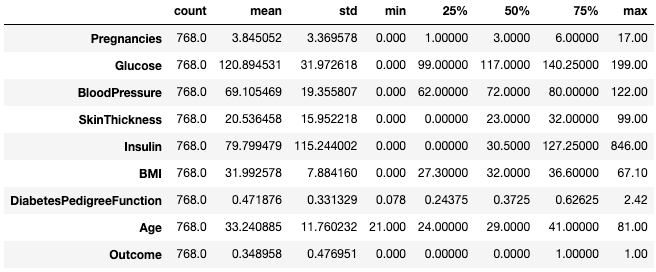
Transpor estatísticas resumidas com .T
Para saber mais sobre a descrição de DataFrames, confira a folha de dicas a seguir.
.info()O método .info() é uma maneira rápida de examinar os tipos de dados, os valores ausentes e o tamanho dos dados de um DataFrame. Aqui, estamos definindo o argumento show_counts como True, que fornece alguns valores sobre o total de valores não ausentes em cada coluna. Também estamos definindo memory_usage como True, que mostra o uso total de memória dos elementos do DataFrame. Quando verbose é definido como True, ele imprime o resumo completo de .info().
df.info(show_counts=True, memory_usage=True, verbose=True)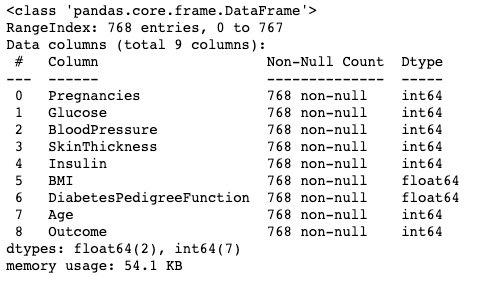
.shapeO número de linhas e colunas de um DataFrame pode ser identificado usando o atributo .shape do DataFrame. Ele retorna uma tupla (linha, coluna) e pode ser indexado para obter apenas linhas, e apenas colunas contam como saída.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9A chamada do atributo .columns de um objeto DataFrame retorna os nomes das colunas na forma de um objeto Index. Como lembrete, um índice pandas é o endereço/rótulo da linha ou coluna.
df.columns
Ele pode ser convertido em uma lista usando a função list().
list(df.columns)
.isnull()O DataFrame de amostra não tem nenhum valor ausente. Vamos apresentar alguns para tornar as coisas interessantes. O método .copy() faz uma cópia do DataFrame original. Isso é feito para garantir que qualquer alteração na cópia não seja refletida no DataFrame original. Usando .loc (a ser discutido mais tarde), você pode definir as linhas de dois a cinco da coluna Pregnancies como valores NaN, que denotam valores ausentes.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)
Você pode ver que agora as linhas 2 a 5 são NaN
Você pode verificar se cada elemento em um DataFrame está ausente usando o método .isnull().
df2.isnull().head(7)Como geralmente é mais útil saber a quantidade de dados ausentes, você pode combinar .isnull() com .sum() para contar o número de nulos em cada coluna.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Você também pode fazer uma soma dupla para obter o número total de nulos no DataFrame.
df2.isnull().sum().sum()4O pacote pandas oferece várias maneiras de classificar, subconjuntar, filtrar e isolar dados em seus DataFrames. Aqui, veremos as formas mais comuns.
Para classificar um DataFrame por uma coluna específica:
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderVocê pode classificar por várias colunas:
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Se você filtrar ou classificar um DataFrame, o índice poderá ficar desalinhado. Use o site .reset_index() para corrigir isso:
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnPara extrair dados com base em uma condição:
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100[ ] Você pode isolar uma única coluna usando um colchete [ ] com o nome de uma coluna. O resultado é um objeto pandas Series. Uma série pandas é uma matriz unidimensional que contém dados de qualquer tipo, incluindo inteiros, flutuantes, strings, booleanos, objetos python etc. Um DataFrame é composto de muitas séries que funcionam como colunas.
df['Outcome']
Isolando uma coluna no pandas
[[ ]] Você também pode fornecer uma lista de nomes de colunas dentro dos colchetes para buscar mais de uma coluna. Aqui, os colchetes são usados de duas maneiras diferentes. Usamos os colchetes externos para indicar um subconjunto de um DataFrame e os colchetes internos para criar uma lista.
df[['Pregnancies', 'Outcome']]
Isolamento de duas colunas no pandas
[ ] Uma única linha pode ser obtida se você passar uma série booleana com um valor True. No exemplo abaixo, a segunda linha com index = 1 é retornada. Aqui, .index retorna os rótulos de linha do DataFrame, e a comparação transforma isso em uma matriz unidimensional booleana.
df[df.index==1]
Isolamento de uma linha no pandas
[ ] Da mesma forma, duas ou mais linhas podem ser retornadas usando o método .isin() em vez de um operador ==.
df[df.index.isin(range(2,10))]
Isolamento de linhas específicas no pandas
.loc[] e .iloc[] para buscar linhasVocê pode buscar linhas específicas por rótulos ou condições usando .loc[] e .iloc[] ("location" e "integer location"). .loc[] usa um rótulo para apontar para uma linha, coluna ou célula, enquanto .iloc[] usa a posição numérica. Para entender a diferença entre os dois, vamos modificar o índice de df2 criado anteriormente.
df2.index = range(1,769)O exemplo abaixo retorna um pandas Series em vez de um DataFrame. O 1 representa o índice da linha (rótulo), enquanto o 1 em .iloc[] é a posição da linha (primeira linha).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Você também pode buscar várias linhas fornecendo um intervalo entre colchetes.
df2.loc[100:110]
Isolamento de linhas no pandas com .loc[]
df2.iloc[100:110]![Isolamento de linhas no pandas com .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Isolamento de linhas no pandas com .iloc[]
Você também pode fazer um subconjunto com .loc[] e .iloc[] usando uma lista em vez de um intervalo.
df2.loc[[100, 200, 300]]![Isolamento de linhas usando uma lista no pandas com .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Isolamento de linhas usando uma lista no pandas com .loc[]
df2.iloc[[100, 200, 300]]
Isolamento de linhas usando uma lista no pandas com .iloc[]
Você também pode selecionar colunas específicas junto com as linhas. É nesse ponto que o .iloc[] é diferente do .loc[] - ele exige a localização da coluna e não os rótulos da coluna.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolamento de colunas usando uma lista no pandas com .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Isolamento de colunas no pandas com .loc[]
df2.iloc[100:110, :3]![Isolamento de colunas usando em pandas com .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Isolamento de colunas com .iloc[]
Para fluxos de trabalho mais rápidos, você pode passar o índice inicial de uma linha como um intervalo.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolamento de colunas usando em pandas com .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Isolamento de colunas e linhas no pandas com .loc[]
df2.iloc[760:, :3]
Isolando colunas e linhas no pandas com .iloc[]
Você pode atualizar/modificar determinados valores usando o operador de atribuição =
df2.loc[df['Age']==81, ['Age']] = 80O pandas permite que você filtre dados por condições sobre valores de linha/coluna. Por exemplo, o código abaixo seleciona a linha em que a pressão arterial é exatamente 122. Aqui, estamos isolando as linhas usando os colchetes [ ], conforme visto nas seções anteriores. No entanto, em vez de inserir índices de linha ou nomes de coluna, estamos inserindo uma condição em que a coluna BloodPressure é igual a 122. Denotamos essa condição usando df.BloodPressure == 122.
df[df.BloodPressure == 122]
Isolamento de linhas com base em uma condição no pandas
O exemplo abaixo buscou todas as linhas em que Outcome é 1. Aqui, df.Outcome seleciona essa coluna, df.Outcome == 1 retorna uma série de valores booleanos determinando quais Outcomes são iguais a 1 e, em seguida, [] obtém um subconjunto de df em que essa série booleana é True.
df[df.Outcome == 1]
Isolamento de linhas com base em uma condição no pandas
Você pode usar um operador > para fazer comparações. O código abaixo busca Pregnancies, Glucose e BloodPressure para todos os registros com BloodPressure maior que 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]
Isolamento de linhas e colunas com base em uma condição no pandas
A limpeza de dados é uma das tarefas mais comuns na ciência de dados. O pandas permite que você pré-processe dados para qualquer uso, incluindo, entre outros, o treinamento de modelos de aprendizado de máquina e aprendizado profundo. Vamos usar o DataFrame df2 de antes, com quatro valores ausentes, para ilustrar alguns casos de uso de limpeza de dados. Como lembrete, veja como você pode ver quantos valores ausentes existem em um DataFrame.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Uma maneira de lidar com dados ausentes é eliminá-los. Isso é particularmente útil nos casos em que você tem muitos dados e a perda de uma pequena parte não afetará a análise downstream. Você pode usar um método .dropna() conforme mostrado abaixo. Aqui, estamos salvando os resultados de .dropna() em um DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2O argumento axis permite que você especifique se está descartando linhas ou colunas com valores ausentes. O padrão axis remove as linhas que contêm NaNs. Use axis = 1 para remover as colunas com um ou mais valores NaN. Além disso, observe como estamos usando o argumento inplace=True, que permite que você ignore o salvamento da saída de .dropna() em um novo DataFrame.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()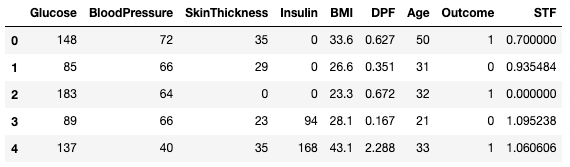
Eliminação de dados ausentes no pandas
Você também pode eliminar linhas e colunas com valores ausentes, definindo o argumento how como 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Em vez de eliminar, substituir os valores ausentes por uma estatística resumida ou um valor específico (dependendo do caso de uso) talvez seja o melhor caminho a seguir. Por exemplo, se houver uma linha faltante em uma coluna de temperatura que indique as temperaturas ao longo dos dias da semana, substituir esse valor faltante pela temperatura média da semana pode ser mais eficaz do que eliminar completamente os valores. Você pode substituir os dados ausentes pela média da linha ou da coluna usando o código abaixo.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Vamos adicionar algumas duplicatas aos dados originais para que você saiba como eliminar duplicatas em um DataFrame. Aqui, estamos usando o método .concat() para concatenar as linhas do DataFrame df2 ao DataFrame df2, adicionando duplicatas perfeitas de cada linha em df2.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Você pode remover todas as linhas duplicadas (padrão) do DataFrame usando o método .drop_duplicates() .
df3 = df3.drop_duplicates()
df3.shape(768, 9)Uma tarefa comum de limpeza de dados é renomear colunas. Com o método .rename(), você pode usar columns como argumento para renomear colunas específicas. O código abaixo mostra o dicionário para mapear nomes de colunas antigos e novos.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()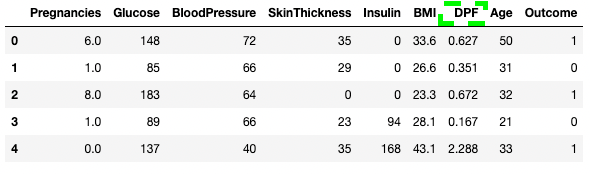
Renomear colunas no pandas
Você também pode atribuir diretamente nomes de colunas como uma lista ao DataFrame.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()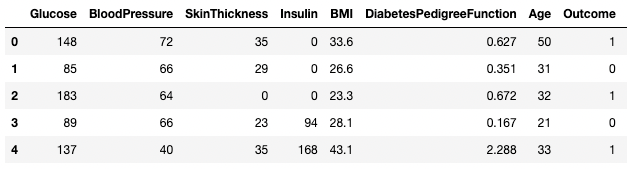
Renomear colunas no pandas
Para saber mais sobre limpeza de dados e para obter fluxos de trabalho de limpeza de dados mais fáceis e previsíveis, confira a lista de verificação a seguir, que fornece a você um conjunto abrangente de tarefas comuns de limpeza de dados.
A principal proposta de valor do pandas está em sua funcionalidade de análise rápida de dados. Nesta seção, vamos nos concentrar em um conjunto de técnicas de análise que você pode usar no pandas.
Como você viu anteriormente, é possível obter a média de cada valor de coluna usando o método .mean().
df.mean()
Imprimir a média das colunas no pandas
Um modo pode ser calculado de forma semelhante usando o método .mode().
df.mode()
Imprimir o modo das colunas no pandas
Da mesma forma, a mediana de cada coluna é calculada com o método .median()
df.median()
Imprimindo a mediana das colunas em pandas
O pandas fornece computação rápida e eficiente ao combinar duas ou mais colunas como variáveis escalares. O código abaixo divide cada valor na coluna Glucose com o valor correspondente na coluna Insulin para calcular uma nova coluna chamada Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Criar uma nova coluna a partir de colunas existentes no pandas
.value_counts()Muitas vezes, você trabalhará com valores categóricos e desejará contar o número de observações que cada categoria tem em uma coluna. Os valores de categoria podem ser contados usando os métodos .value_counts(). Aqui, por exemplo, estamos contando o número de observações em que o Outcome é diabético (1) e o número de observações em que o Outcome não é diabético (0).
df['Outcome'].value_counts()
Usando .value_counts() em pandas
Ao adicionar o argumento normalize, você retorna proporções em vez de contagens absolutas.
df['Outcome'].value_counts(normalize=True)
Usando .value_counts() em pandas com normalização
Desative a classificação automática dos resultados usando o argumento sort (True por padrão). A classificação padrão é baseada nas contagens em ordem decrescente.
df['Outcome'].value_counts(sort=False)
Usando .value_counts() em pandas com classificação
Você também pode aplicar o .value_counts() a um objeto DataFrame e a colunas específicas dentro dele, em vez de apenas a uma coluna. Aqui, por exemplo, estamos aplicando value_counts() em df com o argumento de subconjunto, que recebe uma lista de colunas.
df.value_counts(subset=['Pregnancies', 'Outcome'])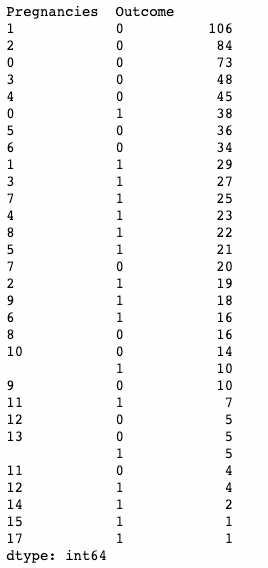
Usando .value_counts() em pandas durante o subconjunto de colunas
.groupby() em pandasO pandas permite que você agregue valores agrupando-os por valores de coluna específicos. Você pode fazer isso combinando o método .groupby() com um método de resumo de sua escolha. O código abaixo exibe a média de cada uma das colunas numéricas agrupadas por Outcome.
df.groupby('Outcome').mean()
Agregando dados por uma coluna no pandas
.groupby() permite que você agrupe por mais de uma coluna, passando uma lista de nomes de colunas, como mostrado abaixo.
df.groupby(['Pregnancies', 'Outcome']).mean()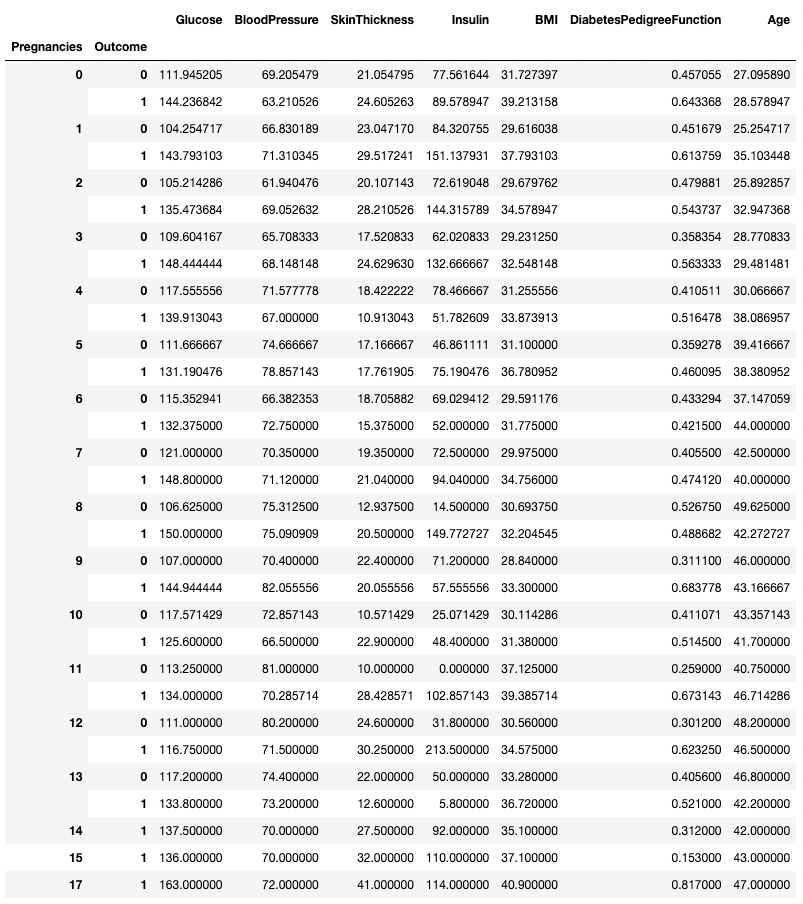
Agregando dados por duas colunas no pandas
Qualquer método de resumo pode ser usado junto com .groupby(), incluindo .min(), .max(), .mean(), .median(), .sum(), .mode(), entre outros.
O pandas também permite que você calcule estatísticas resumidas como tabelas dinâmicas. Isso facilita a obtenção de conclusões com base em uma combinação de variáveis. O código abaixo seleciona as linhas como valores exclusivos de Pregnancies, os valores da coluna são os valores exclusivos de Outcome e as células contêm o valor médio de BMI no grupo correspondente.
Por exemplo, para Pregnancies = 5 e Outcome = 0, o IMC médio é de 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc=np.mean)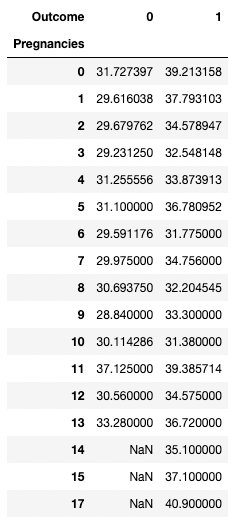
Agregação de dados por meio de dinamização com pandas
O pandas fornece wrappers convenientes para as funções de plotagem do Matplotlib para facilitar a visualização de seus DataFrames. A seguir, você verá como fazer visualizações de dados comuns usando o pandas.
O pandas permite que você trace as relações entre as variáveis usando gráficos de linha. Abaixo você encontra um gráfico de linhas do IMC e da glicose em relação ao índice de fileiras.
df[['BMI', 'Glucose']].plot.line()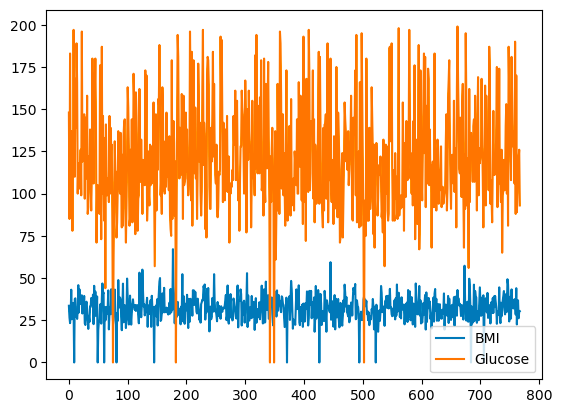
Gráfico de linhas básico com o pandas
Você pode selecionar a opção de cores usando o argumento de cor.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})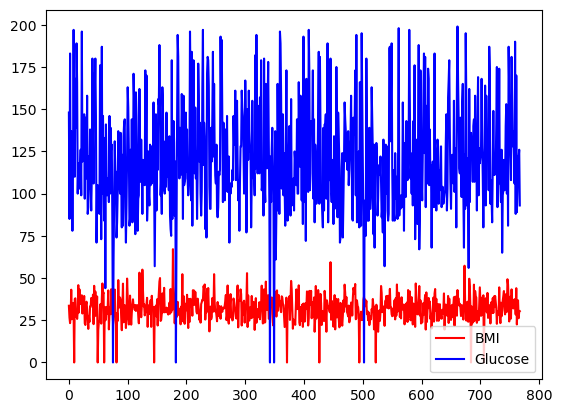
Gráfico de linha básico com pandas, com cores personalizadas
Todas as colunas de df também podem ser plotadas em escalas e eixos diferentes usando o argumento subplots.
df.plot.line(subplots=True)
Subplots para gráficos de linhas com pandas
Para colunas discretas, você pode usar um gráfico de barras sobre as contagens de categorias para visualizar sua distribuição. A variável Outcome com valores binários é visualizada abaixo.
df['Outcome'].value_counts().plot.bar()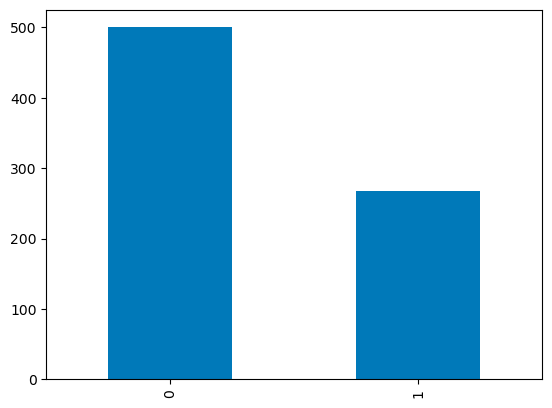
Gráficos de barras em pandas
A distribuição de quartis de variáveis contínuas pode ser visualizada usando um boxplot. O código abaixo permite que você crie um boxplot com o pandas.
df.boxplot(column=['BMI'], by='Outcome')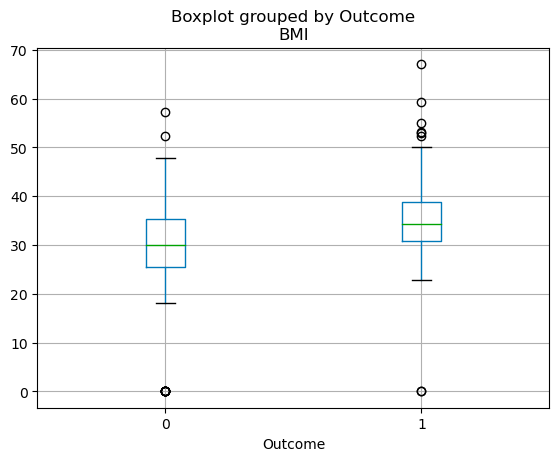
Boxplots em pandas
No tutorial acima, você pode ver apenas a superfície do que é possível fazer com o pandas. Seja analisando dados, visualizando-os, filtrando-os ou agregando-os, o pandas oferece um conjunto de recursos incrivelmente rico que permite que você acelere qualquer fluxo de trabalho de dados. Além disso, ao combinar o pandas com outros pacotes de ciência de dados, você poderá criar painéis interativos, criar modelos preditivos usando aprendizado de máquina, automatizar fluxos de trabalho de dados e muito mais. Confira os recursos abaixo para acelerar sua jornada de aprendizado com os pandas:
Mais cursos sobre pandas
Curso
Curso
Curso
blog
Matt Crabtree
15 min
Tutorial
Natassha Selvaraj
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Satyam Tripathi


