Da. GPT-Image-1.5 este disponibil în OpenAI API și include aceleași îmbunătățiri ca ChatGPT Images. Intrările și ieșirile de imagini sunt cu aproximativ 20% mai ieftine decât la GPT Image 1, ceea ce îl face potrivit pentru aplicații precum marketing, ecommerce și fluxuri de lucru de design.
Ce este ChatGPT Images?
Noua filă Images din ChatGPT servește drept hub creativ pentru tot ceea ce este vizual în interfața ChatGPT și înlocuiește biblioteca personală de imagini. Cea mai notabilă schimbare este integrarea unor instrumente de editare directă care permit vizarea unor detalii specifice dintr-o imagine, menținând în același timp intacte toate celelalte detalii.
ChatGPT Images este alimentat de GPT-Image-1.5, cel mai nou și mai avansat model AI text‑către‑imagine de la OpenAI. El se bazează pe lansarea modelului GPT-Image-1 din martie 2025, care a fost un mare succes, cu peste 700 de milioane de imagini generate în prima săptămână.
Oferă păstrarea detaliilor și o redare îmbunătățită a textului și, conform afirmațiilor, este „de până la 4 ori” mai rapid decât predecesorul.
Noile funcții au fost lansate pentru toți utilizatorii, atât pe nivelul gratuit, cât și pe cele plătite, în interfața web, mobilă și în API. Doar conturile Business și Enterprise mai trebuie să aștepte accesul.
Funcții-cheie ale ChatGPT Images
Așadar, ce oferă ChatGPT Images față de modelul anterior și competiție? OpenAI promovează în special „editări precise care păstrează ceea ce contează”. Să aruncăm o privire la noile funcții pentru a vedea ce înseamnă.
Spațiu creativ dedicat
Fila Images a fost introdusă ca un hub de creație vizuală în interfața ChatGPT. Ideea din spatele ei este separarea creării și editării imaginilor de interacțiunile obișnuite din chat.
Deși funcția anterioară, Library, stoca și ea toate imaginile generate, oferea doar întoarcerea la conversația în care au fost create. Folosea contextul din întregul istoric al conversației pentru a genera o imagine nouă de la zero, ceea ce adesea ducea la halucinații în firele mai lungi.
Noua abordare este însă mai centrată pe imagine: fiecare editare pornește de la o imagine și schimbă doar aspectele selectate ale acesteia, în loc să creeze o generație complet nouă.
Imaginile sunt artefacte persistente, nu îngropate în istoricul conversației. Acest lucru permite bucle de feedback mai rapide cu variații noi și încurajează experimentarea, transformând efectiv experiența dintr-un fir de chat într-o pânză.
Pentru a susține și mai mult acest flux creativ, spațiul de lucru introduce instrumente noi de explorare care reduc distanța dintre idee și execuție. Utilizatorii pot aplica presetări de stil încorporate (precum „sketch” sau „dramatic”) sau pot răsfoi estetici în tendințe pentru a prinde următorul „Studio Ghibli”. Pentru creatorii fără experiență, interfața oferă sugestii creative și asistență proactivă pentru prompturi, pentru a rafina rezultatele.
Păstrarea detaliilor și editare de precizie
Probabil cea mai importantă funcție nouă: actualizarea permite utilizatorilor să selecteze părți specifice dintr-o imagine și să le modifice direct, fără a altera restul compoziției. Modelul este conștient de context, ceea ce înseamnă că înțelege ce anume trebuie editat, menținând elementele din jur consistente.
Astfel de editări precise sunt posibile datorită abilităților îmbunătățite ale noului model de a păstra detaliile.
Poate menține obiectele, iluminarea, compoziția și aspectul oamenilor consistente între rezultate și editări ulterioare. De asemenea, o mai bună urmărire a instrucțiunilor contribuie la precizia crescută, ajutând la păstrarea mai bună a relațiilor dintre elemente.
Editarea de precizie este ideală pentru a corecta probleme mici și a experimenta cu detalii specifice atunci când o generație completă nu este necesară. De asemenea, permite transformări creative, cum ar fi preluarea unui element dintr-o imagine și introducerea lui în scena altei imagini.
Totuși, merită menționat că modelul are dificultăți în a menține identitatea exactă a fiecărei persoane atunci când există multe persoane într-o singură imagine.
Redare îmbunătățită a textului și realism
Una dintre funcțiile majore ale modelului predecesor, GPT-Image-1, a fost capacitatea de a gestiona texte mai lungi și propoziții coerente. Noua versiune construiește pe această fundație și este acum capabilă să redea texte mai dense și mai mici decât înainte.
Acest lucru este util mai ales pentru infografice, unde primele rezultate sunt destul de impresionante, și deschide posibilități noi, precum markdown de text într-o imagine, de exemplu într-un ziar. Vom face mai târziu un test de infografice.
Totuși, conform declarației de lansare a OpenAI, limitările privind anumite limbi, precum chineza, araba și ebraica, par să persiste încă.
Deși nu a fost în centrul atenției actualizării, realismul ieșirilor s-a îmbunătățit semnificativ față de modelul anterior. Două cazuri în care se vede clar sunt reflexiile (de exemplu, reflexia puternică într-o fotografie) și multe fețe mici în mulțimi numeroase.
Ca de obicei, îmbunătățirile majore vin cu compromisuri în anumite zone. În acest caz, abilitatea de a genera unele stiluri de artă specifice a regresat. OpenAI recomandă folosirea filtrelor presetate din fila Images sau revenirea la modelul anterior, care este încă disponibil ca un GPT personalizat.
Performanță accelerată
Capacitățile de editare țintită sunt și sursa principală a vitezei crescute de generare. În timp ce generarea completă a unei imagini este vizibil mai rapidă, nu atinge afirmația din nota de lansare a OpenAI. GPT-Images-1.5 pare „de până la 4 ori mai rapid” în principal pentru că regenerează doar ceea ce se schimbă în timpul editărilor.
În mod similar, costul API mai mic cu aproximativ 20% provine în principal din regenerarea parțială a imaginii în timpul editărilor, cu câștiguri suplimentare dintr-o inferență mai eficientă, mai degrabă decât din generații complete mai ieftine.
Per ansamblu, noile funcții permit o utilizare mai eficientă și mai fiabilă, în special pentru fluxurile API.
Exemple ChatGPT Images
Funcțiile anunțate sună cu siguranță promițător. Le-am pus la încercare folosind câteva prompturi simple în combinație cu noul instrument de selecție.
Testarea preciziei editărilor
Scopul primului meu test a fost să evaluez capacitatea modelului de a gestiona schimbări iterative fără degradarea calității. Mai întâi, i-am cerut să creeze o imagine cu un urs brun care merge printr-o pădure finlandeză, în timpul soarelui de la miezul nopții.

Prompt: „Un urs brun mergând printr-o pădure finlandeză deasă în timpul soarelui de la miezul nopții.”
În opinia mea, calitatea primului rezultat este foarte ridicată. Ursul arată natural, tipul arborilor și al tufelor reprezintă foarte bine pădurile finlandeze (aș știu!), iar poziția joasă a soarelui este în linie cu ceea ce vă puteți aștepta în nordul Finlandei în timpul soarelui de la miezul nopții.
În plus, iluminarea și umbrele de pe blana ursului, precum și din fundal, arată destul de realist. Încă se simte cumva că e generat de AI, deși detaliile sunt reușite.
Să încercăm să transformăm ursul într-un urs polar și să vedem ce se întâmplă. Nu există urși polari în Finlanda, dar dacă totul funcționează cum trebuie, fundalul ar trebui să rămână la fel.

Prompt: „Transformă ursul într-un urs polar.”
După cum putem vedea, fundalul a fost păstrat complet intact, exact cum era intenționat.
Pentru următoarea editare, am selectat capul și ochii ursului polar și i-am pus o pereche de ochelari de soare vintage.

Prompt: „Pune o pereche de ochelari de soare vintage pe urs.” (capul selectat)
Se pare că am aflat ce se întâmplă când selectați o zonă prea mare. Deși fundalul imaginii și corpul ursului sunt păstrate consecvent, capul i s-a transformat într-o mare pereche de ochelari de soare. Să încercăm din nou, selectând doar ochii.

Prompt: „Pune o pereche de ochelari de soare vintage pe urs.” (ochii selectați)
Foarte reușit, și clar mult mai bine! În acest prim test, am putut vedea cât de puternică este de fapt funcția de păstrare a detaliilor: a trebuit să precizăm doar o dată detaliile importante despre decor, apoi am putut itera asupra personajului principal fără să ne facem griji pentru fundal. O altă concluzie importantă este că dimensiunea ferestrei de selecție contează.
Testarea consistenței transformărilor
În continuare, am testat permanența obiectelor în diferite decoruri și limitările modelului în ceea ce privește mulțimile mari. În acest scop, l-am lăsat pe ursul nostru polar să călătorească puțin și am încercat să-l mut într-o scenă aglomerată de metrou din Tokyo.

Prompt: „Plasează acest urs într-o scenă de metrou foarte aglomerată din Tokyo.”
În primul rând, consistența personajului este impresionantă: modelul a păstrat perfect postura și identitatea exactă a ursului și a eliminat reflexia soarelui de pe blană.
Totuși, această păstrare rigidă a dus la o ruptură vizuală cunoscută drept „efectul autocolantului”. Deoarece modelul nu a actualizat contextul de iluminare (păstrând umbra direcțională și reflexiile pădurii în ochelari), ursul arată ca un decupaj 2D lipit pe scenă, nu ca un obiect 3D care o populează.
Perspectiva spulberă și ea iluzia: ursul plutește în fața unui trecător care este fizic mai aproape de cameră.
Încercarea de a corecta această din urmă problemă a fost destul de frustrantă. Am selectat zona trecătorului și intersecția lui cu ursul și am cerut ChatGPT să corecteze perspectiva. La fiecare variație, modelul a inserat o persoană nouă, aproape de cameră, exact așa:

Prompt: „Corectează perspectiva: spatele trecătorului selectat este în prim-plan și ar trebui să acopere parțial ursul. Ursul se află în spatele persoanei.”
Se pare că modelul nu a fost capabil să identifice persoana, chiar și când a fost selectată, și a avut nevoie de un personaj nou pentru a urma comanda din prompt.
Corectarea umbrei și a reflexiilor din ochelari a avut mai mult succes. Am folosit următoarele iterații:
- Umbră: Selectați podeaua din jurul picioarelor ursului și cereți: „În locul umbrei actuale, proiectează o umbră moale, difuză pe gresia din metrou, în concordanță cu iluminarea fluorescentă de deasupra.”
- Ochelari de soare: Selectați ochelarii și cereți: „Actualizează reflexiile ochelarilor de soare pentru a se potrivi cu mediul din metrou.”

Ursul nostru polar în metroul din Tokyo, după corectarea umbrei și a reflexiilor din ochelari
Deja mult mai bine, deși nu perfect.
Per ansamblu, al doilea test nu a fost la fel de reușit ca primul. Deși consistența elementelor între imagini diferite pare să funcționeze bine, recunoașterea personajelor pare să își atingă limitele în medii aglomerate.
Testarea redării textului
În final, am vrut să testez noile capacități de redare a textului, mai ales când vine vorba de text dens și editări. Îmbunătățirile în redarea textului ar fi binevenite pentru că, istoric, modelele de viziune au fost mai bune la obiecte, texturi și scene, nu la simboluri.
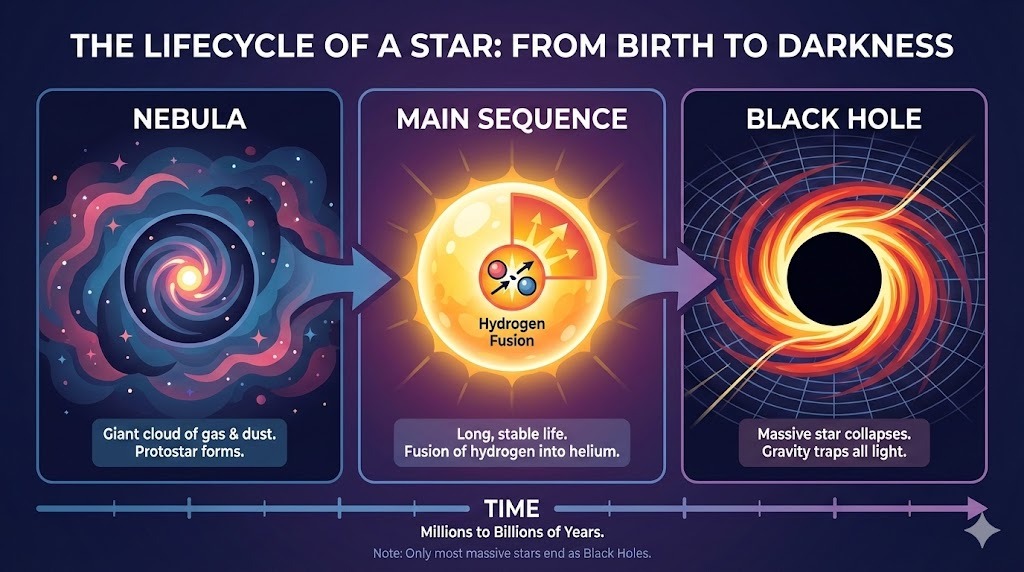
I-am cerut lui ChatGPT un layout complex pentru un infografic despre ciclul de viață al unei stele:
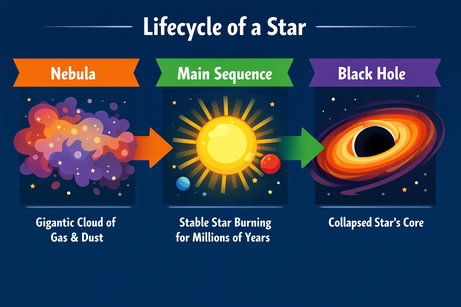
Prompt: "Un infografic orizontal care explică 'Ciclul de viață al unei stele'. Trei secțiuni: Nebuloasă, Secvență principală, Gaură neagră. Folosește stil vectorial plat."
Rezultatul urmează perfect instrucțiunile și redă textul fără erori. Stilul este corect și consecvent în tot infograficul.
Multimodalitatea ieșirilor ChatGPT ne obligă să fim preciși când inserăm text. Când am cerut să adauge un punct în listă „aici” (într-o zonă selectată din imagine), a oferit doar punctul ca ieșire text. Adăugarea clarificării „în imagine” a rezolvat problema:
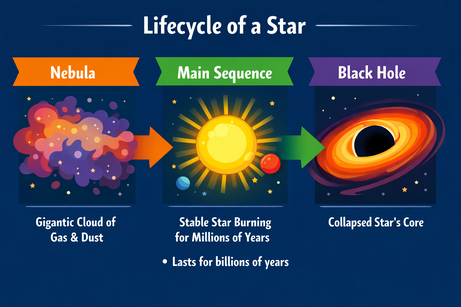
Prompt: „Adaugă în imagine, aici, un punct în listă care spune: 'Durează miliarde de ani'.”
După clarificare, punctul a fost inserat în poziția corectă. Fontul, dimensiunea și culoarea se potrivesc cu stilul graficii.
Cum pot accesa ChatGPT Images?
ChatGPT Images este acum disponibil pentru aproape toți utilizatorii, pe mai multe platforme. Doar suportul pentru utilizatorii din nivelurile Business și Enterprise lipsește încă și va urma ulterior.
În interfață, puteți accesa funcțiile imediat în interfața web sau aplicația mobilă ChatGPT, prin fila Images. Deși numerele exacte nu sunt cunoscute, conturile Free au limite zilnice stricte, iar planurile Plus și Pro au alocări progresiv mai mari și mai stabile.
Pentru dezvoltatori, noul model GPT-Image-1.5 poate fi folosit atât prin OpenAI API, cât și prin Azure OpenAI Service, fiind disponibil pentru generare și editare de imagini. Deși ne așteptăm ca modelul să fie integrat curând în suite creative terțe majore, dezvoltatorii pot deja construi fluxuri de editare direct în propriile aplicații folosind endpoint-urile v1/images/generations și v1/images/edits.
Spre deosebire de predecesorul său, GPT-Image-1.5 expune ieșirea de imagine ca tokeni cu preț separat, folosind endpoint-uri API specifice imaginilor, în locul endpoint-ului unificat /v1/responses. Plătiți doar pentru tokenii necesari pentru a genera schimbările, nu pentru o imagine complet nouă de fiecare dată.
De aceea, se afirmă că noul model este cu aproximativ 20% mai ieftin decât predecesorul, deși prețurile per token nu s-au schimbat față de GPT-Image-1.
Cât de bun este ChatGPT Images?
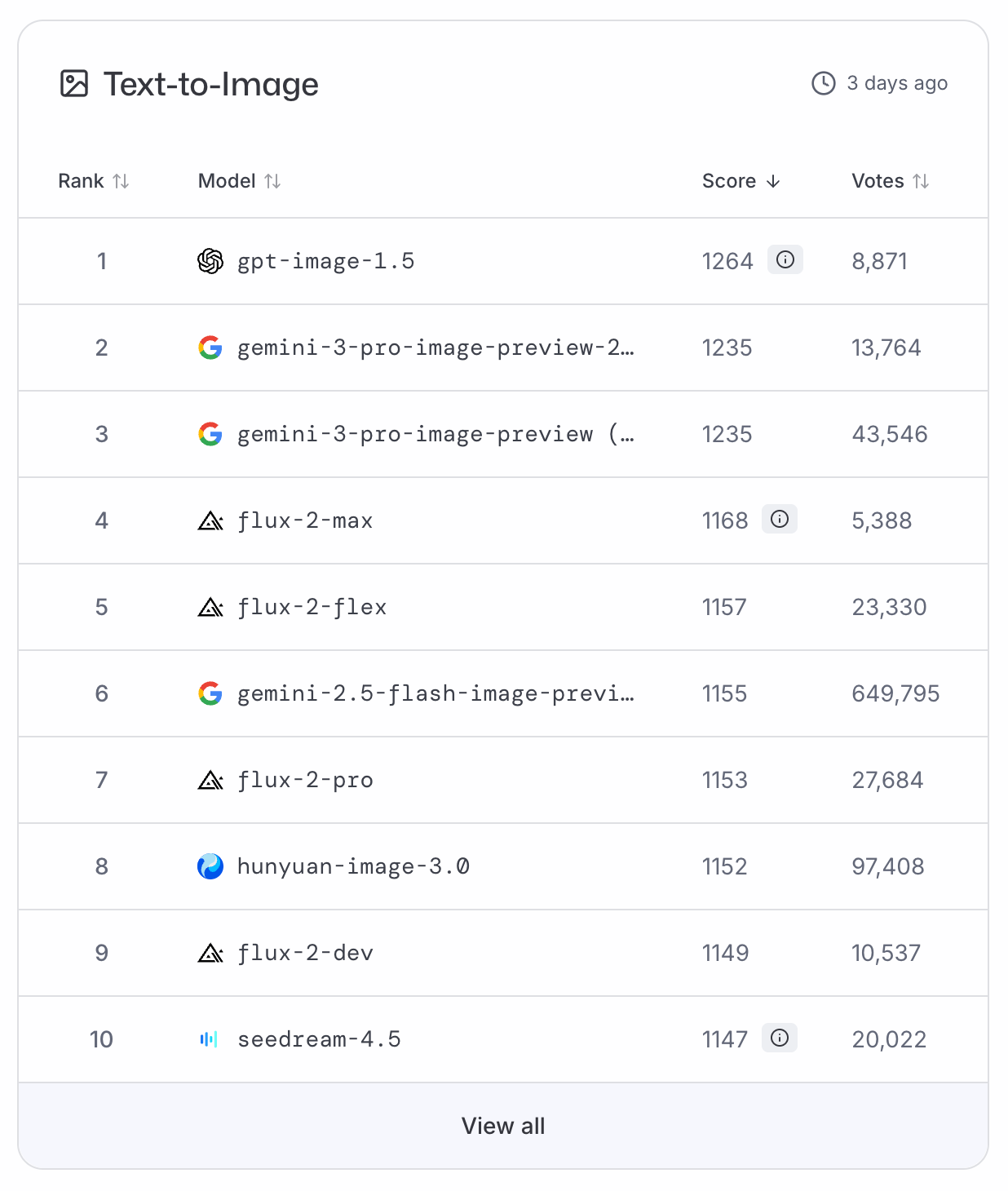
GPT-Image-1.5 a urcat imediat pe primul loc în LMArena și ArtificialAnalysis, în clasamentele pentru text‑către‑imagine, trimițând Nano Banana Pro pe locul al doilea. Cum în prezent nu există date de benchmark disponibile, trebuie să ne bazăm pe aceste clasamente bazate pe voturi pentru o clasificare obiectivă.
Parafrazând un astronaut celebru: GPT-Image-1.5 este un pas mic pentru industrie, dar un salt uriaș pentru OpenAI.
Deși editarea de precizie nu este complet nouă, aducerea ei nativă în ChatGPT marchează cea mai mare schimbare a acestei lansări. Totuși, precizia este esențială: nu uitați să selectați doar zonele necesare pentru a evita probleme precum „ursul polar fără cap” întâlnit în testare.
Din experiența mea, actualizarea aduce un salt semnificativ de calitate, reflectat și în clasamente. Imaginile standard par mai vii, iar infograficele sunt mult mai puțin simplificate decât înainte.
Utilizatorii au acum un control semnificativ mai mare asupra fiecărui rezultat, înlocuind vechiul flux de lucru bazat pe prompturi complexe de continuare și pe „să sperăm la ce e mai bun”. Acest lucru se datorează în mare măsură faptului că păstrarea detaliilor funcționează foarte bine. În testele noastre, a menținut elementele complet intacte.
Consistența personajelor este solidă, însă utilizatorii ar trebui să fie atenți la „efectul autocolantului” și la problemele logice de perspectivă. Deși editările țintite facilitează corectarea acestora, limitările persistă în scene aglomerate, cu mulți oameni.
ChatGPT Images vs. Nano Banana Pro
Modelul de top pe care ChatGPT Images trebuie să îl depășească este în mod clar Nano Banana Pro de la Google. Tabelul următor compară cele două modele:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Model de editare |
Precizie: selecție de zonă și editare in-place |
Raționare: conversațional și mascarea inteligentă |
|
Flux de lucru |
Spațiu creativ dedicat |
Funcție integrată în chat |
|
Iterație |
Eficient: regenerare parțială |
Explorator: remixare |
|
Consistență |
Păstrare ridicată a layout-ului și a detaliilor |
Păstrare ridicată a layout-ului și a detaliilor |
|
Ecosistem |
OpenAI și Azure |
Google / stiva Gemini |
Deși atât GPT-Image-1.5, cât și Nano Banana Pro oferă rezultate excelente, modelele diferă în filozofiile de editare, fluxurile de lucru și orientarea către clienți.
ChatGPT Images se concentrează pe izolarea la nivel de pixel, având avantajul controlului manual: puteți selecta o zonă exactă, iar aceasta este tratată ca o pânză pentru in‑painting, în timp ce restul imaginii este blocat. Nano Banana Pro, pe de altă parte, încearcă să înțeleagă intenția dumneavoastră pentru a face modificările corecte.
În ceea ce privește fluxul de lucru, și cele două companii au ales căi diferite: fila Images din ChatGPT se simte ca un studio creativ, separat de conversații, în timp ce Nano Banana Pro este pe deplin integrat în fluxul de chat.
Actualizare: Noua versiune a modelului de generare de imagini non‑pro de la Google, Nano Banana 2, a introdus îmbunătățiri semnificative. Deși Nano Banana Pro are încă un mic avantaj, noul model oferă (aproape) aceeași calitate la o viteză mult mai mare.
Când să folosiți ChatGPT Images vs. Nano Banana Pro
Aș sugerea să folosiți ChatGPT Images dacă trebuie să corectați layout-uri, să editați text sau să faceți modificări precise pe o imagine existentă fără a-i altera stilul. Alegeți Nano Banana Pro dacă aveți nevoie să generați vizuale cu multe date, să remixați mai multe imagini sau dacă preferați ca un asistent inteligent să vă intuiască intenția, în locul controlului manual.
Folosind aceleași prompturi ca mai sus, am recreat imaginile de test. Personal, mi-au plăcut mai mult infograficele Nano Banana Pro, în timp ce imaginile cu ursul au fost la egalitate.
Prompt: "Un infografic orizontal care explică 'Ciclul de viață al unei stele'. Trei secțiuni: Nebuloasă, Secvență principală, Gaură neagră. Folosește stil vectorial plat." (Nano Banana Pro)
Cazuri de utilizare pentru ChatGPT Images
Pe baza testelor practice și a punctelor forte specifice ale GPT-Image-1.5, modelul strălucește când vine vorba de procese iterative și editare de text. Iată câteva cazuri de top:
- Flux de lucru de marketing: Crearea de reclame pentru social media sau imagini de produs în care anumite detalii se schimbă (de ex., „Schimbă puloverul din roșu în albastru”)
- Infografice educaționale: Generarea de diagrame pentru manuale, prezentări sau bloguri, precum exemplul nostru „ciclul de viață al unei stele”
- Storyboarding: Vizualizarea unui scenariu sau a unei benzi desenate în care același personaj trebuie să apară în locații diferite
- Modă: Folosirea creației hibride de conținut pentru a explora vizual combinații de ținute, ca în acest tutorial FLUX.2 pentru vizualizarea garderobei
- Design interior: Combinarea unei schițe sau fotografii cu prompturi pentru a redecora încăperi într-un anumit stil
- Mockup-uri UI/UX: Vizualizarea rapidă a modului în care ar putea arăta o pagină de destinație sau ambalajul unui produs nou
Concluzii
De la lansarea Nano Banana Pro, OpenAI a fost sub presiune puternică să țină pasul. Cu această actualizare promițătoare, revin în cursa pentru cel mai capabil model AI text‑către‑imagine. Nu este lipsit de cusururi, dar, concentrându-vă pe elementele esențiale, precum tipografia clară și editarea precisă, puteți obține rezultate bune. Pentru a începe, încercați funcția în interfața ChatGPT sau în OpenAI Playground. Pentru inspirație, puteți consulta galeria și ghidul de prompturi.
Dacă doriți să începeți să construiți instrumente folosind modelele GPT, traseul nostru de competențe OpenAI Fundamentals este pentru dumneavoastră.