Sì. GPT-Image-1.5 è disponibile nell’API OpenAI e include gli stessi miglioramenti di ChatGPT Images. Gli input e gli output di immagini costano circa il 20% in meno rispetto a GPT Image 1, il che lo rende adatto ad applicazioni come marketing, ecommerce e workflow di design.
Che cos’è ChatGPT Images?
La nuova scheda Images di ChatGPT è un hub creativo per tutto ciò che è visivo all’interno dell’interfaccia di ChatGPT e sostituisce la libreria di immagini personale. Il cambiamento più evidente è l’integrazione di strumenti di modifica diretta che permettono di intervenire su dettagli specifici di un’immagine mantenendo invariato tutto il resto.
ChatGPT Images è alimentato da GPT-Image-1.5, l’ultimo e più avanzato modello di IA testo-immagine di OpenAI. Si basa sul rilascio del modello GPT-Image-1 del marzo 2025, che è stato un grande successo con oltre 700 milioni di immagini generate nella prima settimana.
Offre conservazione dei dettagli e un rendering del testo migliorato, e si dichiara essere “fino a 4 volte” più veloce del predecessore.
Le nuove funzionalità sono state distribuite a tutti gli utenti, sia del piano gratuito che a pagamento, su web, mobile e API. Solo gli account Business ed Enterprise devono ancora attendere l’accesso.
Funzionalità chiave di ChatGPT Images
Cosa offre quindi ChatGPT Images rispetto al modello precedente e alla concorrenza? OpenAI punta in particolare su “modifiche precise che preservano ciò che conta”. Vediamo le nuove funzioni per capire cosa significa.
Spazio di lavoro creativo dedicato
La scheda Images è stata introdotta come hub per la creazione visiva all’interno della UI di ChatGPT. L’idea è separare la creazione e l’editing di immagini dalle normali interazioni in chat.
Il precedente strumento Library salvava comunque tutte le immagini generate, ma offriva solo di tornare alla conversazione in cui erano state create. Usava il contesto di tutta la cronologia della conversazione per generare una nuova immagine da zero, portando spesso a allucinazioni nei thread più lunghi.
Il nuovo approccio, invece, è più incentrato sull’immagine: ogni modifica prende un’immagine come punto di partenza e cambia solo gli aspetti selezionati, invece di creare una nuova generazione completa.
Le immagini sono artefatti persistenti, non sepolti nella cronologia della conversazione. Questo consente cicli di feedback più rapidi con nuove variazioni e favorisce la sperimentazione, trasformando di fatto l’esperienza da un thread di chat a una vera e propria tela.
Per alimentare ancora di più il flusso creativo, lo spazio di lavoro introduce nuovi strumenti di esplorazione per colmare il divario tra idea ed esecuzione. Puoi applicare preset di stile integrati (come “schizzo” o “drammatico”) o sfogliare estetiche di tendenza per intercettare la prossima “Studio Ghibli”. Per chi è alle prime armi, l’interfaccia offre suggerimenti creativi e supporto proattivo ai prompt per affinare i risultati.
Conservazione dei dettagli ed editing di precisione
Probabilmente la novità più importante: l’aggiornamento consente di selezionare parti specifiche di un’immagine e modificarle direttamente, senza alterare il resto della composizione. Il modello è context-aware, cioè capisce cosa va modificato mantenendo coerenti gli elementi circostanti.
Queste modifiche nette sono rese possibili dalle migliori capacità del nuovo modello nella conservazione dei dettagli.
Riesce a mantenere oggetti, illuminazione, composizione e aspetto delle persone coerenti tra output ed edit successivi. Anche la migliore aderenza alle istruzioni contribuisce alla maggiore precisione, aiutando a preservare meglio le relazioni tra gli elementi.
L’editing di precisione è perfetto per correggere piccoli problemi e sperimentare dettagli specifici quando non serve una generazione completa. Consente anche trasformazioni creative, come portare un elemento da un’immagine nella scena di un’altra.
Vale però la pena menzionare che il modello fa fatica a mantenere l’identità esatta di ogni persona quando in un’unica immagine compaiono molte persone.
Rendering del testo e realismo migliorati
Una delle funzioni principali del modello precedente GPT-Image-1 era la capacità di gestire testi lunghi e frasi coerenti. La nuova versione costruisce su queste basi ed è ora in grado di gestire testi più densi e più piccoli di prima.
Questo è particolarmente utile per le infografiche, dove i primi risultati sono piuttosto impressionanti, e apre nuove possibilità come il markdown del testo in un’immagine, ad esempio in un giornale. Più avanti faremo un test sulle infografiche.
Tuttavia, secondo la nota di rilascio di OpenAI, sembrano persistere limitazioni per alcune lingue specifiche, come cinese, arabo ed ebraico.
Anche se non era il focus principale dell’aggiornamento, il realismo degli output è migliorato notevolmente rispetto al modello precedente. Due casi in cui si nota bene sono i riflessi, ad esempio i bagliori su una foto, e i tanti piccoli volti in grandi folle di persone.
Come spesso accade, grandi upgrade comportano qualche compromesso in aree specifiche. In questo caso, la capacità di generare alcuni stili artistici particolari è regredita. OpenAI consiglia di usare i filtri preimpostati nella scheda Images o di tornare al modello precedente, che è ancora disponibile come GPT personalizzato.
Prestazioni accelerate
Le capacità di modifica mirata sono anche la principale fonte dell’aumento di velocità di generazione. Sebbene la generazione completa sia sensibilmente più rapida, non raggiunge quanto dichiarato nella nota di rilascio di OpenAI. GPT-Images-1.5 sembra “fino a 4 volte più veloce” soprattutto perché rigenera solo ciò che cambia durante le modifiche.
Allo stesso modo, il costo API inferiore di circa il 20% deriva principalmente dalla rigenerazione parziale dell’immagine durante gli edit, con ulteriori vantaggi da un’inferenza più efficiente piuttosto che da generazioni complete più economiche.
Nel complesso, le nuove funzioni consentono un uso più efficiente e affidabile, soprattutto per i workflow via API.
Esempi di ChatGPT Images
Le funzionalità annunciate sono decisamente interessanti. Le ho messe alla prova con alcuni prompt semplici in combinazione con il nuovo strumento di selezione.
Test dell’accuratezza delle modifiche
L’obiettivo del primo test era valutare la capacità del modello di gestire cambiamenti iterativi senza degradare la qualità. Prima gli ho chiesto di creare l’immagine di un orso bruno che cammina in una foresta finlandese durante il sole di mezzanotte.

Prompt: “Un orso bruno che cammina in una fitta foresta finlandese durante il sole di mezzanotte.”
A mio avviso, la qualità del primo output è molto alta. L’orso sembra naturale, il tipo di alberi e cespugli rappresenta molto bene le foreste finlandesi (me ne intendo!) e la bassa posizione del sole è in linea con ciò che ti aspetti nella Finlandia settentrionale durante il sole di mezzanotte.
Inoltre, l’illuminazione e le ombre sul pelo dell’orso, così come sullo sfondo, appaiono piuttosto realistiche. Si capisce ancora che è IA, in qualche modo, anche se i dettagli sono ben fatti.
Proviamo a trasformare l’orso in un orso polare e vediamo che succede. In Finlandia non ci sono orsi polari, ma se tutto funziona come dovrebbe, lo sfondo dovrebbe restare uguale.

Prompt: “Trasforma l’orso in un orso polare.”
Come si vede, lo sfondo è stato mantenuto completamente intatto, proprio come previsto.
Per la modifica successiva ho selezionato la testa e gli occhi dell’orso polare e gli ho fatto indossare un paio di occhiali da sole vintage.

Prompt: “Metti un paio di occhiali da sole vintage all’orso.” (testa selezionata)
Abbiamo scoperto cosa succede quando selezioni un’area troppo grande. Mentre lo sfondo e il corpo dell’orso restano coerenti, la testa si è trasformata in un unico grande paio di occhiali da sole. Riproviamo, selezionando solo gli occhi.

Prompt: “Metti un paio di occhiali da sole vintage all’orso.” (occhi selezionati)
Molto meglio, e decisamente più riuscito! In questo primo test abbiamo visto quanto sia potente la funzione di conservazione dei dettagli: ci è bastato specificare una sola volta i dettagli importanti della scena, potendo iterare sul protagonista senza preoccuparci dello sfondo. Un altro punto chiave è che la dimensione della finestra di selezione conta.
Test della coerenza nelle trasformazioni
Poi ho testato la permanenza dell’oggetto al variare delle scene e i limiti del modello nelle grandi folle. Per questo, ho fatto viaggiare un po’ il nostro orso polare e ho provato a inserirlo in una scena affollata della metropolitana di Tokyo.

Prompt: “Inserisci questo orso in una scena molto affollata della metropolitana di Tokyo.”
Prima di tutto, la coerenza del personaggio è notevole: il modello ha preservato perfettamente la postura e l’identità esatte dell’orso, rimuovendo il bagliore del sole dal pelo.
Tuttavia, questa conservazione rigida ha causato una dissonanza visiva nota come “effetto adesivo”. Poiché il modello non ha aggiornato il contesto di illuminazione (mantenendo l’ombra direzionale e i riflessi del bosco sugli occhiali), l’orso sembra un ritaglio 2D incollato sulla scena, invece di un oggetto 3D che la abita.
La prospettiva rompe ulteriormente l’illusione: l’orso “galleggia” davanti a un passante che è fisicamente più vicino alla fotocamera.
Cercare di correggere quest’ultimo problema è stato piuttosto frustrante. Ho selezionato l’area del passante e la sua intersezione con l’orso e ho chiesto a ChatGPT di correggere la prospettiva. A ogni variazione, il modello ha inserito una nuova persona vicino alla fotocamera, proprio così:

Prompt: “Correggi la prospettiva: la schiena del passante selezionato è in primo piano e dovrebbe oscurare parzialmente l’orso. L’orso è in piedi dietro la schiena della persona.”
Sembra che il modello non sia stato in grado di identificare la persona, anche se selezionata, e abbia quindi richiesto un nuovo personaggio per seguire il comando del prompt.
Correggere l’ombra e i riflessi sugli occhiali da sole è andata meglio. Ho usato queste iterazioni:
- Ombra: Seleziona il pavimento attorno ai piedi dell’orso e usa il prompt “Al posto dell’ombra attuale, proietta un’ombra morbida e diffusa sulle piastrelle della metropolitana, coerente con l’illuminazione fluorescente dall’alto”.
- Occhiali da sole: Seleziona gli occhiali da sole e usa il prompt “Aggiorna i riflessi degli occhiali da sole per abbinarli all’ambiente della metropolitana”.

Il nostro orso polare nella metropolitana di Tokyo dopo la correzione di ombra e riflessi sugli occhiali da sole
Già molto meglio, anche se non perfetto.
Nel complesso, il secondo test non è stato riuscito come il primo. Mentre la coerenza degli elementi tra immagini diverse sembra funzionare bene, il riconoscimento dei personaggi sembra raggiungere i suoi limiti in ambienti affollati.
Test del rendering del testo
Infine, ho voluto testare le nuove capacità di rendering del testo, soprattutto per testi densi e modifiche. Miglioramenti nel rendering del testo sarebbero i benvenuti perché, storicamente, i modelli di visione se la sono cavata meglio con oggetti, texture e scene, non con i simboli.
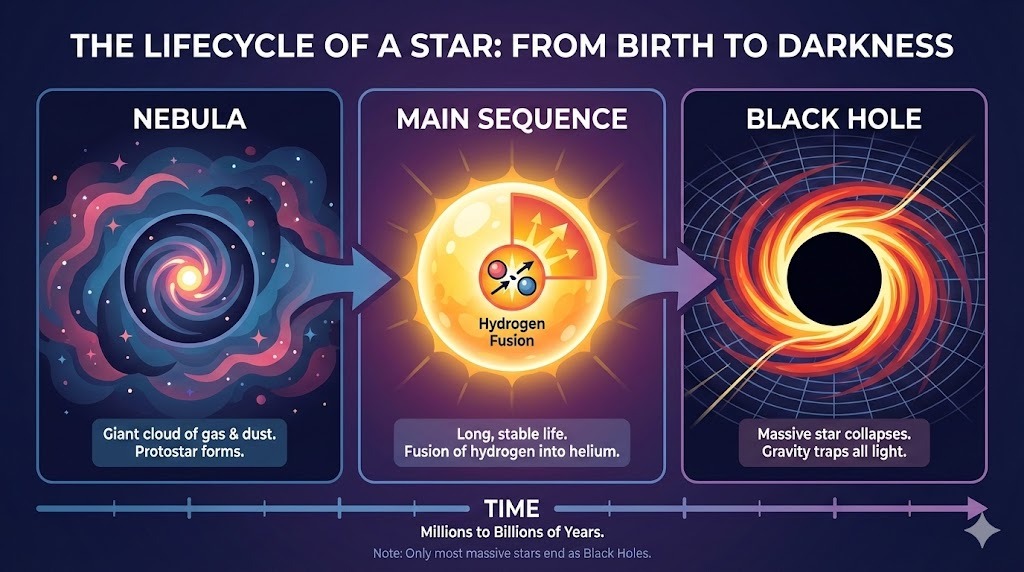
Ho chiesto a ChatGPT un layout complesso per un’infografica sul ciclo di vita di una stella:
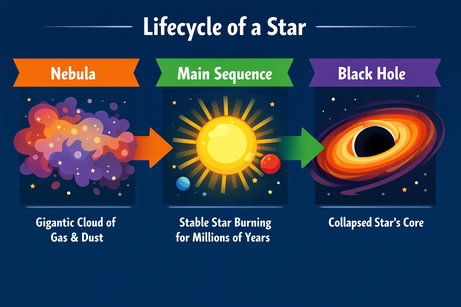
Prompt: "Un’infografica orizzontale che spiega il ‘Ciclo di vita di una stella’. Tre sezioni: Nebulosa, Sequenza principale, Buco nero. Usa uno stile vettoriale piatto."
L’output segue perfettamente le istruzioni e rende il testo senza errori. Lo stile è accurato e coerente in tutta l’infografica.
La multimodalità dell’output di ChatGPT ci obbliga a essere precisi quando si inserisce del testo. Quando ho chiesto di aggiungere un punto elenco “qui” (su un’area selezionata nell’immagine), ha fornito il punto elenco come semplice output testuale. Aggiungendo la precisazione “nell’immagine” ha funzionato:
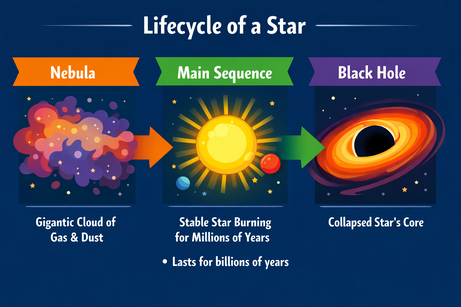
Prompt: “Aggiungi qui all’immagine un punto elenco con la frase: 'Dura miliardi di anni'.”
Dopo la precisazione, il punto elenco è stato inserito nella posizione giusta. Font, dimensioni e colore si abbinano allo stile della grafica.
Come posso accedere a ChatGPT Images?
ChatGPT Images è ora disponibile per quasi tutti gli utenti su più piattaforme. Manca ancora il supporto per gli utenti dei piani Business ed Enterprise, che arriverà più avanti.
Nella UI puoi accedere subito alle funzionalità nella versione web o nell’app mobile di ChatGPT tramite la scheda Images. Anche se i numeri esatti non sono noti, si applicano limiti giornalieri rigidi per gli account Free e soglie via via più alte e stabili per i piani Plus e Pro.
Per gli sviluppatori, il nuovo modello GPT-Image-1.5 è utilizzabile sia tramite l’API OpenAI che tramite Azure OpenAI Service, dove è disponibile per generazione ed editing di immagini. In attesa che venga integrato nelle principali suite creative di terze parti, è già possibile costruire flussi di modifica direttamente nelle proprie applicazioni usando gli endpoint v1/images/generations e v1/images/edits.
A differenza del predecessore, GPT-Image-1.5 espone l’output immagine come token a prezzo separato, usando endpoint API specifici per le immagini invece dell’endpoint unificato /v1/responses. Paghi solo i token necessari a generare le modifiche, invece che una nuova immagine completa ogni volta.
Per questo il nuovo modello viene dichiarato circa il 20% più economico del precedente, anche se i prezzi per token non sono cambiati rispetto a GPT-Image-1.
Quanto è valido ChatGPT Images?
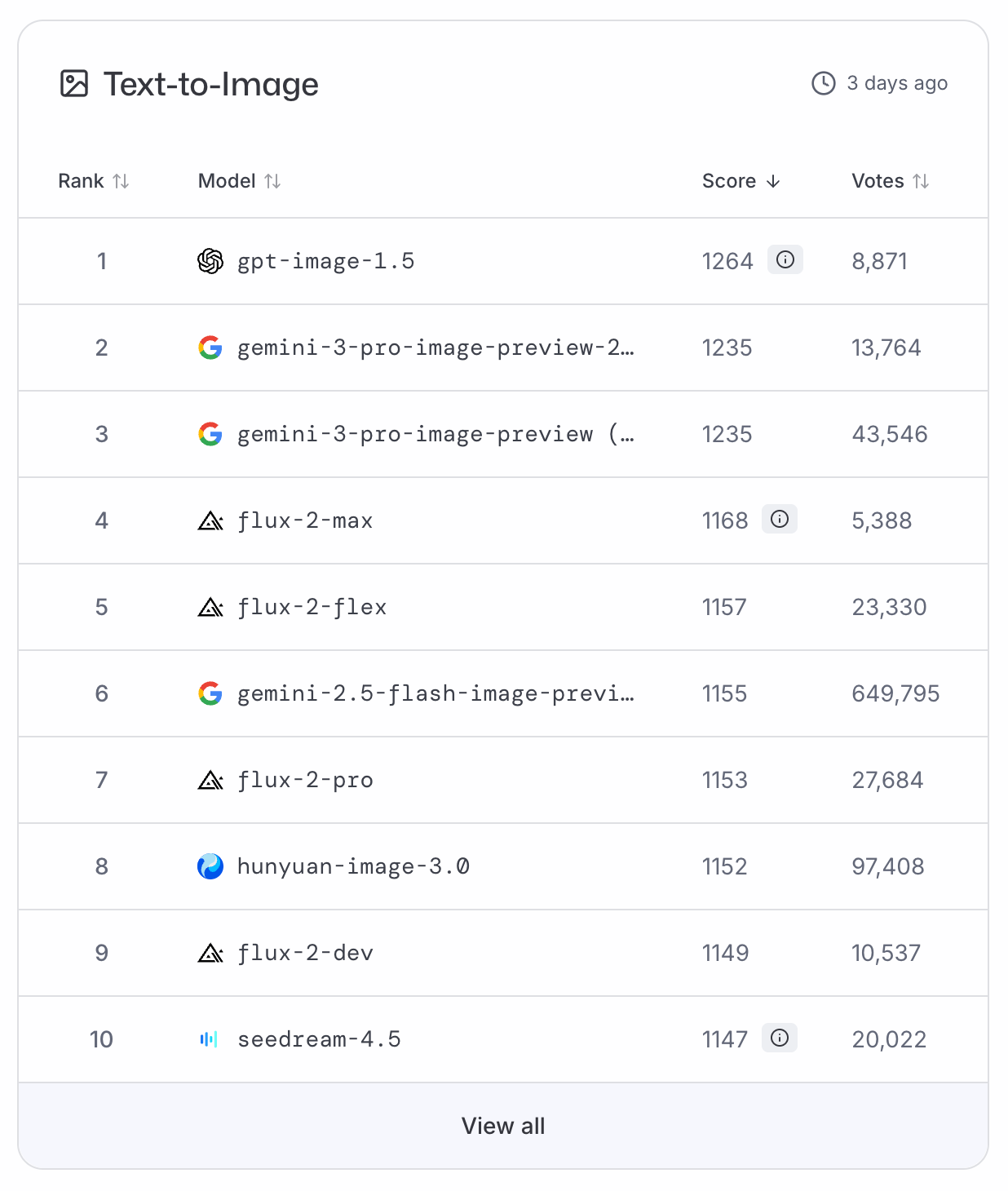
GPT-Image-1.5 è salito subito in cima alle classifiche LMArena e ArtificialAnalysis sul testo-immagine, relegando Nano Banana Pro al secondo posto. Poiché al momento non ci sono benchmark disponibili, dobbiamo affidarci a queste classifiche basate sui voti per una valutazione oggettiva.
Parafrasando un famoso astronauta: GPT-Image-1.5 è un piccolo passo per il settore, ma un grande balzo per OpenAI.
Sebbene l’editing di precisione non sia del tutto nuovo, integrarlo nativamente in ChatGPT è il cambiamento più rilevante del rilascio. Tuttavia la precisione è fondamentale: ricorda di selezionare solo le aree necessarie per evitare glitch come “l’orso polare senza testa” incontrato nei test.
Per esperienza, l’aggiornamento offre un notevole salto di qualità, riflesso anche nelle classifiche. Le immagini standard risultano più vive e le infografiche molto meno semplificate rispetto a prima.
Ora hai molto più controllo su ogni output, rimpiazzando il vecchio flusso di lavoro fatto di prompt di follow-up complessi e speranze. Questo soprattutto perché la conservazione dei dettagli funziona molto bene. Nei nostri test ha mantenuto gli elementi completamente intatti.
La coerenza dei personaggi è solida, anche se bisogna fare attenzione all’“effetto adesivo” e ai problemi logici di prospettiva. Sebbene le modifiche mirate rendano più facile correggerli, persistono limitazioni nelle scene affollate con molte persone.
ChatGPT Images vs. Nano Banana Pro
Il principale rivale che ChatGPT Images deve battere è chiaramente il Nano Banana Pro di Google. La seguente tabella confronta i due modelli:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Modello di editing |
Precisione: selezione area e modifica in-place |
Ragionamento: conversazionale e smart masking |
|
Workflow |
Spazio di lavoro creativo dedicato |
Funzione integrata nella chat |
|
Iterazione |
Efficiente: rigenerazione parziale |
Esplorativa: remix |
|
Coerenza |
Alta tenuta di layout e dettagli |
Alta tenuta di layout e dettagli |
|
Ecosistema |
OpenAI e Azure |
Google / stack Gemini |
Sebbene sia GPT-Image-1.5 che Nano Banana Pro offrano ottimi risultati, i due modelli differiscono per filosofia di editing, workflow e focus sul cliente.
ChatGPT Images punta sull’isolamento al pixel, che dà il meglio nel controllo manuale: puoi selezionare un’area esatta e il modello tratta la selezione come una tela per l’in-painting mentre il resto dell’immagine è bloccato. Nano Banana Pro, invece, cerca di capire cosa vuoi ottenere per applicare le modifiche giuste.
Anche sul workflow le strade sono diverse: la scheda Images in ChatGPT sembra uno studio creativo, separato dalle conversazioni, mentre Nano Banana Pro è pienamente integrato nel flusso della chat.
Aggiornamento: la nuova versione del modello di generazione immagini non pro di Google, Nano Banana 2, ha introdotto miglioramenti significativi. Pur mantenendo Nano Banana Pro un leggero vantaggio, il nuovo modello offre (quasi) la stessa qualità a una velocità molto maggiore.
Quando usare ChatGPT Images vs. Nano Banana Pro
Ti suggerisco di usare ChatGPT Images se devi correggere layout, modificare testo o apportare cambiamenti precisi a un’immagine esistente senza alterarne lo stile. Scegli Nano Banana Pro se devi generare visual ricchi di dati, fare remix di più immagini o preferisci che un assistente “intelligente” intuisca l’intento al posto del controllo manuale.
Usando gli stessi prompt di sopra, ho ricreato le immagini di test. Personalmente, ho preferito le infografiche di Nano Banana Pro, mentre le immagini dell’orso erano alla pari.
Prompt: "Un’infografica orizzontale che spiega il ‘Ciclo di vita di una stella’. Tre sezioni: Nebulosa, Sequenza principale, Buco nero. Usa uno stile vettoriale piatto." (Nano Banana Pro)
Casi d’uso di ChatGPT Images
In base ai nostri test pratici e ai punti di forza specifici di GPT-Image-1.5, il modello dà il meglio nei processi iterativi e nell’editing del testo. Ecco alcuni casi d’uso principali:
- Workflow marketing: Creazione di annunci social o scatti di prodotto in cui dettagli specifici possono cambiare (es.: “Cambia il maglione da rosso a blu”)
- Infografiche educative: Generazione di diagrammi per libri di testo, presentazioni o blog, come il nostro esempio del “ciclo di vita di una stella”
- Storyboarding: Visualizzazione di una sceneggiatura o di un fumetto in cui lo stesso personaggio deve comparire in luoghi diversi
- Moda: Uso di creazione ibrida di contenuti per esplorare visivamente combinazioni di outfit, come in questo tutorial sul visualizzatore di guardaroba FLUX.2
- Interior design: Combinare uno schizzo grezzo o una foto con prompt per ridisegnare stanze in un certo stile
- Mockup UI/UX: Visualizzare rapidamente come potrebbe apparire la landing page di un sito o il packaging di un nuovo prodotto
Considerazioni finali
Dopo l’uscita di Nano Banana Pro, OpenAI era sotto pressione per tenere il passo. Con questo aggiornamento promettente, è tornata in corsa per il modello testo-immagine più capace. Non è perfetto, ma concentrandoti su elementi essenziali come tipografia nitida ed editing preciso, puoi ottenere buoni risultati. Per iniziare, prova la funzione nell’interfaccia di ChatGPT o nel Playground di OpenAI. Per ispirarti, dai un’occhiata alla galleria e alla guida ai prompt.
Se vuoi iniziare a creare strumenti usando i modelli GPT, il nostro skill track OpenAI Fundamentals fa per te.
Che tipo di modifiche alle immagini può gestire ChatGPT Images?
In cosa GPT-Image-1.5 è migliore rispetto al modello di immagini precedente?
ChatGPT Images è disponibile per tutti?
Gli sviluppatori possono usare il nuovo modello di immagini tramite API?


Author
Josef Waples

