ได้ โมเดล GPT-Image-1.5 พร้อมใช้งานใน OpenAI API และมีการปรับปรุงเช่นเดียวกับ ChatGPT Images อินพุตและเอาต์พุตของภาพมีราคาถูกกว่า GPT Image 1 ราว 20% จึงเหมาะสำหรับงานด้านการตลาด อีคอมเมิร์ซ และเวิร์กโฟลว์ด้านการออกแบบ
ChatGPT Images คืออะไร?
แท็บ Images ใหม่ของ ChatGPT ทำหน้าที่เป็นศูนย์กลางงานสร้างสรรค์สำหรับทุกอย่างที่เป็นภาพภายใน UI ของ ChatGPT และมาแทนที่ไลบรารีภาพส่วนตัว ความเปลี่ยนแปลงที่โดดเด่นคือการผสานเครื่องมือแก้ไขโดยตรงที่ช่วยให้ระบุและแก้ไขรายละเอียดเฉพาะส่วนของภาพได้ โดยคงรายละเอียดอื่น ๆ ไว้ครบถ้วน
ChatGPT Images ขับเคลื่อนด้วย GPT-Image-1.5 โมเดล AI สร้างภาพจากข้อความรุ่นล่าสุดและล้ำหน้าที่สุดของ OpenAI ซึ่งต่อยอดจากการเปิดตัว GPT-Image-1 เมื่อมีนาคม 2025 ซึ่งประสบความสำเร็จอย่างมากด้วยจำนวนภาพที่สร้างกว่า 700 ล้านภาพในสัปดาห์แรก
จุดเด่นคือการคงรายละเอียดและการเรนเดอร์ข้อความที่ดีขึ้น และอ้างว่าสร้างภาพได้เร็วกว่าเดิม “สูงสุด 4 เท่า”
ฟีเจอร์ใหม่เปิดให้ผู้ใช้ทุกคน ทั้งแบบฟรีและเสียค่าบริการ บนเว็บ มือถือ และ API แล้ว ยกเว้นบัญชี Business และ Enterprise ที่ยังต้องรอการเข้าถึง
ฟีเจอร์เด่นของ ChatGPT Images
แล้ว ChatGPT Images มีอะไรเหนือกว่าโมเดลเดิมและคู่แข่งบ้าง? OpenAI โปรโมตเป็นพิเศษเรื่อง “การแก้ไขอย่างแม่นยำที่คงสิ่งสำคัญไว้” มาดูฟีเจอร์ใหม่เพื่อทำความเข้าใจว่าหมายถึงอะไร
พื้นที่ทำงานสร้างสรรค์เฉพาะ
แท็บ Images ถูกเพิ่มเข้ามาเป็นศูนย์กลางการสร้างงานภาพภายใน UI ของ ChatGPT แนวคิดคือแยกการสร้างและแก้ไขภาพออกจากการสนทนาทั่วไป
ขณะที่ฟีเจอร์ Library เดิมก็เก็บภาพที่สร้างไว้เช่นกัน แต่มีเพียงการพากลับไปยังบทสนทนาที่ภาพถูกสร้างขึ้น และใช้บริบทจากประวัติการสนทนาทั้งหมดเพื่อสร้างภาพใหม่ตั้งแต่ต้น ซึ่งมักนำไปสู่อาการหลอนของ AIในเธรดที่ยาว
แนวทางใหม่เน้นที่ภาพมากขึ้น: แต่ละการแก้ไขจะเริ่มจากภาพต้นฉบับและปรับเฉพาะส่วนที่เลือก แทนที่จะสร้างใหม่ทั้งหมด
ภาพกลายเป็นชิ้นงานที่คงอยู่ ไม่ถูกฝังอยู่ในประวัติการสนทนา สิ่งนี้ช่วยให้ได้ข้อเสนอแนะเร็วขึ้นด้วยเวอร์ชันใหม่ ๆ และเอื้อต่อการทดลอง เปลี่ยนประสบการณ์จากเธรดแชทให้เหมือนการทำงานบนผ้าใบ
เพื่อหนุนการไหลลื่นเชิงสร้างสรรค์ พื้นที่ทำงานยังมีเครื่องมือสำรวจใหม่ ๆ เพื่อเชื่อมช่องว่างระหว่างแนวคิดกับการลงมือทำ ผู้ใช้สามารถใช้พรีเซ็ตสไตล์ในตัว (เช่น “sketch” หรือ “dramatic”) หรือเรียกดูสไตล์ยอดนิยมเพื่อเกาะเทรนด์ “Studio Ghibli” ได้ สำหรับผู้ที่ยังไม่ชำนาญ UI จะมีคำแนะนำสร้างสรรค์และการช่วยเขียนพรอมต์เชิงรุกเพื่อปรับผลลัพธ์ให้ดีขึ้น
การคงรายละเอียดและการแก้ไขอย่างแม่นยำ
ถือเป็นฟีเจอร์ใหม่ที่สำคัญที่สุด ผู้ใช้สามารถเลือกส่วนเฉพาะของภาพและแก้ไขได้โดยตรง โดยไม่กระทบองค์ประกอบที่เหลือ โมเดลรับรู้บริบท เข้าใจว่าส่วนใดควรถูกแก้ไข พร้อมรักษาความสอดคล้องขององค์ประกอบรอบข้าง
การแก้ไขที่คมกริบลักษณะนี้เป็นไปได้ด้วยความสามารถการคงรายละเอียดที่ดีขึ้นของโมเดลใหม่
มันสามารถคงวัตถุ แสง องค์ประกอบ และรูปลักษณ์ของผู้คนให้สม่ำเสมอข้ามผลลัพธ์และการแก้ไขต่อเนื่อง อีกทั้งการทำตามคำสั่งที่ดีขึ้นยังช่วยเพิ่มความแม่นยำด้วยการรักษาความสัมพันธ์ระหว่างองค์ประกอบต่าง ๆ ได้ดีกว่าเดิม
การแก้ไขอย่างแม่นยำเหมาะสำหรับการแก้ปัญหาเล็ก ๆ และการทดลองกับรายละเอียดเฉพาะ เมื่อไม่จำเป็นต้องสร้างใหม่ทั้งหมด นอกจากนี้ยังเปิดทางให้การแปลงเชิงสร้างสรรค์ เช่น นำองค์ประกอบจากภาพหนึ่งไปวางในฉากของอีกภาพหนึ่ง
อย่างไรก็ตาม ควรกล่าวถึงว่าโมเดลยังมีความยากในการคงอัตลักษณ์ที่แม่นยำของทุกคน หากมีผู้คนจำนวนมากในภาพเดียว
การเรนเดอร์ข้อความและความสมจริงที่ดีขึ้น
หนึ่งในจุดเด่นของ GPT-Image-1 รุ่นก่อนคือความสามารถในการจัดการข้อความยาวและประโยคที่สอดคล้องกัน รุ่นใหม่ต่อยอดจากพื้นฐานนั้น และสามารถจัดการข้อความที่หนาแน่นและขนาดเล็กได้ดีกว่าเดิม
สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับอินโฟกราฟิก ซึ่งผลลัพธ์แรก ๆ น่าประทับใจ และเปิดความเป็นไปได้ใหม่ ๆ เช่น การทำเครื่องหมายข้อความในภาพ เช่น ในหนังสือพิมพ์ เราจะทดสอบอินโฟกราฟิกในภายหลัง
อย่างไรก็ตาม ตามคำแถลงของ OpenAI ข้อจำกัดด้านภาษาเฉพาะบางภาษา เช่น จีน อาหรับ และฮีบรู ดูเหมือนว่ายังคงมีอยู่
แม้จะไม่ใช่จุดโฟกัสหลักของอัปเดตนี้ แต่ความสมจริงของผลลัพธ์ก็ดีขึ้นอย่างเห็นได้ชัดเมื่อเทียบกับโมเดลก่อนหน้า สองกรณีที่เห็นได้ชัดคือการสะท้อนแสง เช่น แสงสะท้อนบนภาพถ่าย และใบหน้าขนาดเล็กจำนวนมากในฝูงชนขนาดใหญ่
อย่างที่มักเกิดขึ้น การอัปเกรดใหญ่ก็มาพร้อมข้อแลกเปลี่ยนในบางด้าน ในกรณีนี้ ความสามารถในการสร้างสไตล์งานศิลป์บางประเภทถดถอยลง OpenAI แนะนำให้ใช้ฟิลเตอร์พรีเซ็ตในแท็บ Images หรือหันไปใช้โมเดลก่อนหน้า ซึ่งยังคงใช้งานได้ในรูปแบบ GPT แบบกำหนดเอง
ประสิทธิภาพที่เร็วขึ้น
ความสามารถในการแก้ไขแบบเฉพาะจุดเป็นแหล่งที่มาส่วนใหญ่ของความเร็วการสร้างที่เพิ่มขึ้น แม้ว่าการสร้างภาพเต็มจะเร็วขึ้นอย่างเห็นได้ชัด แต่ยังไม่ถึงตามที่ OpenAI ระบุไว้ GPT-Images-1.5 ดูเหมือน “เร็วขึ้นสูงสุด 4 เท่า” เป็นหลักเพราะมันสร้างใหม่เฉพาะส่วนที่มีการเปลี่ยนแปลงระหว่างการแก้ไข
เช่นเดียวกัน ต้นทุน API ที่ลดลงราว 20% มาจากการสร้างภาพบางส่วนระหว่างการแก้ไขเป็นหลัก พร้อมกำไรเพิ่มเติมจากอินเฟอเรนซ์ที่มีประสิทธิภาพขึ้น มากกว่าการสร้างเต็มที่ถูกลง
โดยรวม ฟีเจอร์ใหม่ช่วยให้การใช้งานมีประสิทธิภาพและน่าเชื่อถือมากขึ้น โดยเฉพาะเวิร์กโฟลว์ผ่าน API
ตัวอย่าง ChatGPT Images
ฟีเจอร์ที่ประกาศมาน่าตื่นเต้นไม่น้อย ฉันทดสอบด้วยพรอมต์ง่าย ๆ ไม่กี่แบบร่วมกับเครื่องมือเลือกพื้นที่ใหม่
ทดสอบความแม่นยำในการแก้ไข
เป้าหมายแรกของฉันคือประเมินความสามารถของโมเดลในการจัดการการเปลี่ยนแปลงแบบวนซ้ำโดยไม่ทำให้คุณภาพลดลง ขั้นแรก ฉันให้สร้างภาพหมีสีน้ำตาลที่กำลังเดินผ่านป่าฟินแลนด์ในช่วงพระอาทิตย์เที่ยงคืน

พรอมต์: “A brown bear walking through a dense Finnish forest during the midnight sun.”
สำหรับฉัน คุณภาพของผลลัพธ์แรกสูงมาก หมีดูเป็นธรรมชาติ ประเภทของต้นไม้และพุ่มไม้แทนป่าฟินแลนด์ได้ดีมาก (ฉันรู้ดี!) และตำแหน่งดวงอาทิตย์ต่ำก็สอดคล้องกับสิ่งที่คาดได้ในฟินแลนด์ตอนเหนือช่วงพระอาทิตย์เที่ยงคืน
นอกจากนี้ แสงและเงาบนขนของหมี รวมถึงฉากหลัง ดูค่อนข้างสมจริง แม้จะยังพอมองออกว่าเป็น AI อยู่บ้าง แต่รายละเอียดก็สวยงาม
ลองเปลี่ยนหมีเป็นหมีขั้วโลกดูว่าจะเกิดอะไรขึ้น แม้ในฟินแลนด์จะไม่มีหมีขั้วโลก แต่ถ้าทุกอย่างทำงานตามที่ควร ฉากหลังควรคงเดิม

พรอมต์: “Change the bear to a polar bear.”
ตามที่เห็น ฉากหลังถูกคงไว้ครบถ้วน ตรงตามที่ตั้งใจ
สำหรับการแก้ไขถัดไป ฉันเลือกบริเวณศีรษะและดวงตาของหมีขั้วโลก แล้วให้มันสวมแว่นกันแดดวินเทจ

พรอมต์: “Put a pair of vintage sunglasses on the bear.” (เลือกบริเวณศีรษะ)
ดูเหมือนเราพบว่าเกิดอะไรขึ้นเมื่อเลือกพื้นที่กว้างเกินไป แม้ฉากหลังและลำตัวของหมีจะคงเดิม แต่ศีรษะของมันกลายเป็นแว่นกันแดดขนาดใหญ่ ลองใหม่อีกครั้งโดยเลือกเฉพาะดวงตา

พรอมต์: “Put a pair of vintage sunglasses on the bear.” (เลือกบริเวณดวงตา)
เจ๋งมาก และดีกว่าอย่างชัดเจน! ในการทดสอบแรกนี้ เราได้เห็นพลังของความสามารถคงรายละเอียดอย่างแท้จริง: เราต้องระบุรายละเอียดสำคัญของฉากเพียงครั้งเดียว แล้วสามารถวนแก้ไขตัวละครหลักได้โดยไม่ต้องกังวลกับพื้นหลัง อีกข้อสรุปสำคัญคือขนาดของหน้าต่างเลือกพื้นที่มีความสำคัญ
ทดสอบความคงเส้นคงวาในการย้ายฉาก
ต่อมา ฉันทดสอบการคงอยู่ของวัตถุเมื่อย้ายไปยังฉากต่างกัน และข้อจำกัดของโมเดลเมื่ออยู่ในฝูงชนหนาแน่น เพื่อจุดประสงค์นี้ ฉันพาหมีขั้วโลกของเราเดินทางไปที่ฉากรถไฟใต้ดินที่แออัดในโตเกียว

พรอมต์: “Place this bear into a very busy subway scene in Tokyo.”
ก่อนอื่น ความคงเส้นคงวาของตัวละครน่าประทับใจ: โมเดลคงท่าทางและอัตลักษณ์ของหมีได้อย่างแม่นยำ และลบแสงสะท้อนจากขนของมันออกไป
อย่างไรก็ดี การคงรูปแบบที่แข็งเกินไปก่อให้เกิดความไม่ต่อเนื่องทางภาพที่เรียกว่า “เอฟเฟ็กต์สติกเกอร์” เพราะโมเดลไม่ได้อัปเดตบริบทของแสง (ยังคงเงาทิศทางและภาพสะท้อนป่าในแว่นกันแดด) ทำให้หมีดูเหมือนภาพตัดแปะ 2 มิติบนฉาก มากกว่าจะเป็นวัตถุ 3 มิติที่อยู่ในนั้นจริง ๆ
มุมมองภาพยิ่งทำให้ภาพลวงแตก เพราะหมีลอยอยู่หน้าโดยสารที่อยู่ใกล้กล้องกว่า
การพยายามแก้ปัญหาหลังเป็นเรื่องน่าหงุดหงิด ฉันเลือกพื้นที่ของคนที่ยืนอยู่และจุดที่ตัดกับหมี แล้วสั่งให้ ChatGPT แก้มุมมอง สำหรับแต่ละเวอร์ชัน โมเดลจะแทรกคนใหม่ที่ใกล้กล้องเข้ามาแบบนี้:

พรอมต์: “Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back.”
ดูเหมือนว่าโมเดลไม่สามารถระบุบุคคลนั้นได้ แม้จะเลือกพื้นที่ไว้แล้ว จึงต้องเพิ่มตัวละครใหม่ให้ทำตามคำสั่งในพรอมต์แทน
การแก้เงาและภาพสะท้อนในแว่นกันแดดทำได้สำเร็จมากกว่า ฉันใช้การวนซ้ำดังนี้:
- เงา: เลือกพื้นรอบเท้าหมี แล้วพิมพ์พรอมต์ “Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting.”
- แว่นกันแดด: เลือกแว่นกันแดด แล้วพิมพ์พรอมต์ “Update the reflections of the sunglasses to match the subway environment.”

หมีขั้วโลกของเราในรถไฟใต้ดินโตเกียวหลังแก้เงาและภาพสะท้อนในแว่นกันแดดแล้ว
ดีขึ้นมาก แม้จะยังไม่สมบูรณ์แบบ
โดยรวม การทดสอบที่สองประสบความสำเร็จน้อยกว่าการทดสอบแรก แม้ความคงเส้นคงวาขององค์ประกอบข้ามภาพต่าง ๆ จะทำงานได้ดี แต่การระบุตัวละครดูเหมือนจะถึงขีดจำกัดในฉากที่มีผู้คนหนาแน่น
ทดสอบการเรนเดอร์ข้อความ
สุดท้าย ฉันต้องการทดสอบความสามารถการเรนเดอร์ข้อความ โดยเฉพาะเมื่อเป็นข้อความหนาแน่นและการแก้ไข หากการเรนเดอร์ข้อความดีขึ้นจะเป็นเรื่องน่ายินดี เพราะโดยประวัติแล้ว โมเดลมองภาพมักถนัดวัตถุ พื้นผิว และฉาก มากกว่าสัญลักษณ์
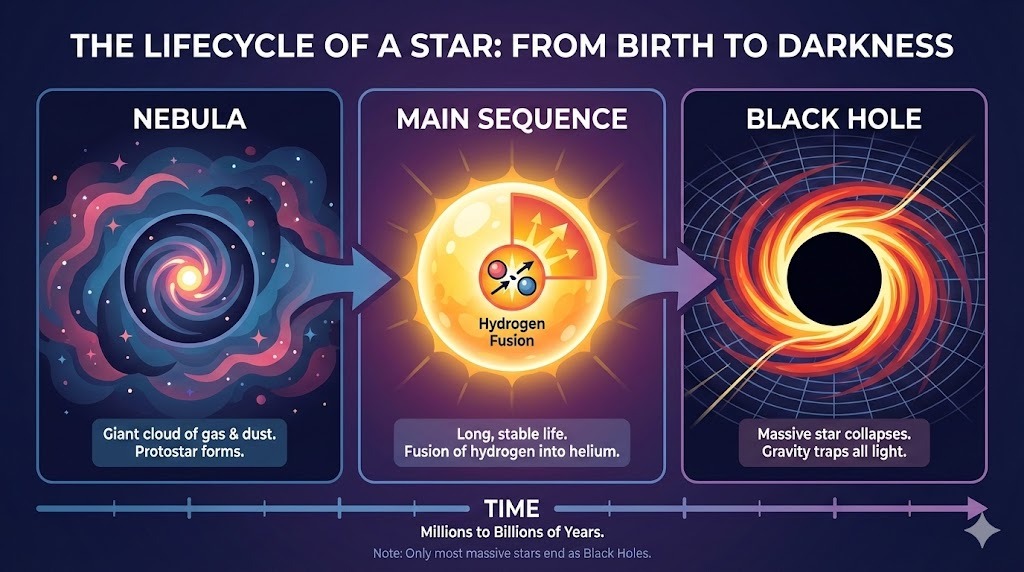
ฉันให้ ChatGPT สร้างเลย์เอาต์ซับซ้อนสำหรับอินโฟกราฟิกเรื่องวัฏจักรชีวิตของดาว:
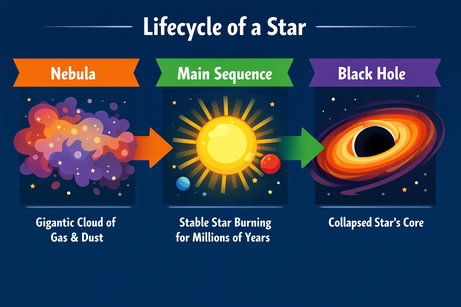
พรอมต์: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
ผลลัพธ์ทำตามคำสั่งอย่างเคร่งครัด และเรนเดอร์ข้อความได้โดยไม่มีข้อผิดพลาด สไตล์ถูกต้องและสม่ำเสมอตลอดทั้งอินโฟกราฟิก
ความเป็นมัลติโหมดของ ChatGPT บังคับให้เราต้องชัดเจนเมื่อต้องแทรกข้อความ เมื่อสั่งให้เพิ่มหัวข้อย่อย “ตรงนี้” (ในพื้นที่ที่เลือกในภาพ) มันคืนหัวข้อย่อยมาเป็นข้อความเท่านั้น การเพิ่มคำชี้แจงว่า “ในภาพ” จึงได้ผล:
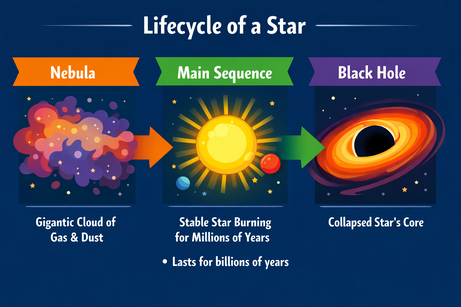
พรอมต์: “Add a bullet point to the image here that says: 'Lasts for billions of years'.”
หลังการชี้แจง หัวข้อย่อยถูกแทรกในตำแหน่งที่ถูกต้อง ฟอนต์ ขนาด และสี สอดคล้องกับสไตล์ของกราฟิก
จะเข้าถึง ChatGPT Images ได้อย่างไร?
ตอนนี้ ChatGPT Images เปิดให้ผู้ใช้เกือบทั้งหมดบนหลายแพลตฟอร์มแล้ว เหลือเพียงผู้ใช้ระดับ Business และ Enterprise ที่ยังไม่รองรับและจะตามมาในภายหลัง
ใน UI สามารถเข้าถึงฟีเจอร์ได้ทันทีในเว็บหรือแอปมือถือของ ChatGPT ผ่านแท็บ Images แม้ไม่มีตัวเลขแน่ชัด แต่บัญชี Free จะมีลิมิตรายวันที่เข้มงวด และแผน Plus กับ Pro จะมีโควตาที่สูงขึ้นและเสถียรกว่า
สำหรับนักพัฒนา โมเดล GPT-Image-1.5 ใหม่ สามารถใช้งานได้ผ่านทั้ง OpenAI API และ Azure OpenAI Service สำหรับการสร้างและแก้ไขภาพ คาดว่าจะได้เห็นการผนวกรวมโมเดลนี้ในชุดเครื่องมือสร้างสรรค์ของบุคคลที่สามรายใหญ่ในไม่ช้า แต่นักพัฒนาสามารถสร้างเวิร์กโฟลว์การแก้ไขในแอปของตนได้แล้วผ่านเอนด์พอยต์ v1/images/generations และ v1/images/edits
ต่างจากรุ่นก่อน GPT-Image-1.5 คิดราคาการแสดงผลภาพเป็นโทเค็นแยกต่างหาก โดยใช้เอนด์พอยต์ API เฉพาะภาพ แทน /v1/responses แบบรวม คุณจ่ายเฉพาะโทเค็นที่ใช้สร้างการเปลี่ยนแปลง แทนการจ่ายเพื่อสร้างภาพใหม่ทั้งภาพทุกครั้ง
นี่คือสาเหตุที่โมเดลใหม่ถูกอ้างว่าถูกกว่ารุ่นก่อนราว 20% แม้ว่าราคาโทเค็นต่อหน่วยจะไม่เปลี่ยนเมื่อเทียบกับ GPT-Image-1
ChatGPT Images ดีแค่ไหน?
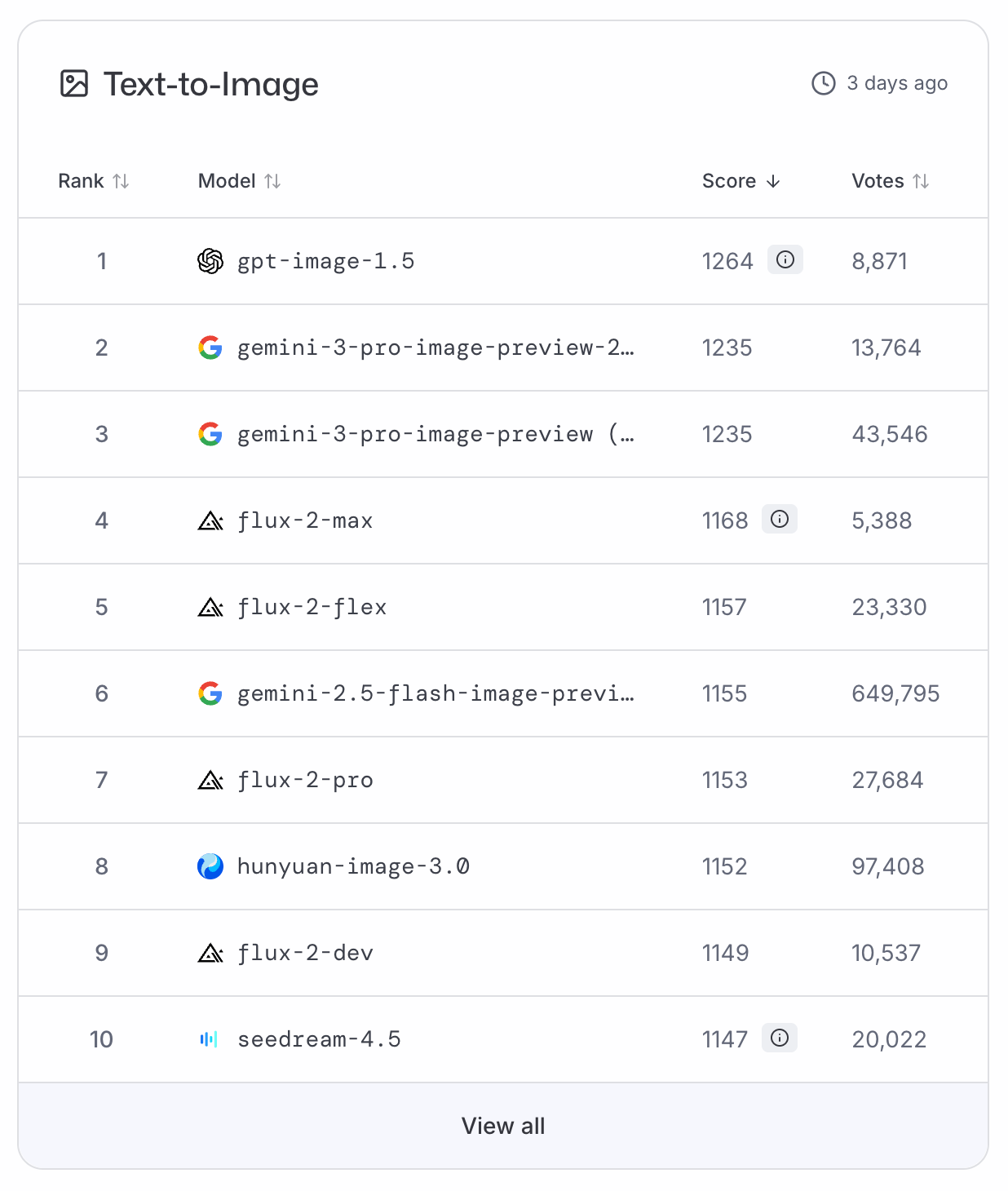
GPT-Image-1.5 ทะยานขึ้นสู่อันดับต้น ๆ ของLMArena และArtificialAnalysis ในตารางจัดอันดับ text-to-image ส่ง Nano Banana Pro ลงมาอยู่ที่สอง เนื่องจากยังไม่มีข้อมูล benchmark จึงต้องอาศัยการจัดอันดับจากการโหวตเหล่านี้เพื่อการจัดประเภทอย่างเป็นกลาง
ขอยืมคำพูดนักบินอวกาศชื่อดังมาปรับใช้: GPT-Image-1.5 คือก้าวเล็ก ๆ ของอุตสาหกรรม แต่เป็นก้าวกระโดดของ OpenAI
แม้การแก้ไขอย่างแม่นยำจะไม่ใช่ของใหม่ทั้งหมด แต่การนำมาไว้ใน ChatGPT โดยกำเนิดคือความเปลี่ยนแปลงที่ใหญ่ที่สุดของการอัปเดต อย่างไรก็ดี ความแม่นยำคือกุญแจ: อย่าลืมเลือกเฉพาะพื้นที่ที่จำเป็นเพื่อหลีกเลี่ยงความเพี้ยนแบบ 'หมีขั้วโลกไร้หัว' ที่พบในการทดสอบ
จากประสบการณ์ของฉัน การอัปเดตนี้ยกระดับคุณภาพอย่างมีนัยสำคัญ ซึ่งสะท้อนในตารางจัดอันดับด้วย ภาพมาตรฐานดูมีชีวิตชีวามากขึ้น และอินโฟกราฟิกดูไม่เรียบง่ายเกินไปเหมือนก่อน
ผู้ใช้มีการควบคุมผลลัพธ์แต่ละภาพมากขึ้น แทนเวิร์กโฟลว์เก่าที่ต้องแต่งพรอมต์ติดตามที่ซับซ้อนแล้วลุ้นผล ส่วนใหญ่มาจากการคงรายละเอียดที่ทำงานได้ดีมาก ในการทดสอบของเรา มันคงองค์ประกอบต่าง ๆ ไว้อย่างครบถ้วน
ความคงเส้นคงวาของตัวละครแข็งแรง แต่ควรระวัง 'เอฟเฟ็กต์สติกเกอร์' และปัญหามุมมองที่ไม่สมเหตุสมผล แม้การแก้ไขแบบเฉพาะจุดจะช่วยแก้ได้ง่ายขึ้น แต่ข้อจำกัดยังคงอยู่ในฉากที่มีผู้คนจำนวนมาก
ChatGPT Images vs. Nano Banana Pro
คู่แข่งที่ ChatGPT Images ต้องโค่นในตอนนี้อย่างชัดเจนคือ Nano Banana Pro ของ Google ตารางต่อไปนี้เปรียบเทียบทั้งสองโมเดล:
|
ChatGPT Images |
Nano Banana Pro |
|
|
โมเดลการแก้ไข |
ความแม่นยำ: เลือกพื้นที่ & แก้ไขในตำแหน่งเดิม |
การให้เหตุผล: การสนทนา & มาสก์อัจฉริยะ |
|
เวิร์กโฟลว์ |
พื้นที่ทำงานสร้างสรรค์เฉพาะ |
ฟีเจอร์แชทแบบบูรณาการ |
|
การวนซ้ำ |
มีประสิทธิภาพ: สร้างใหม่บางส่วน |
สำรวจ: การรีมิกซ์ |
|
ความคงเส้นคงวา |
คงเลย์เอาต์ & รายละเอียดสูง |
คงเลย์เอาต์ & รายละเอียดสูง |
|
ระบบนิเวศ |
OpenAI & Azure |
Google / กลุ่มเทคโนโลยี Gemini |
แม้ทั้ง GPT-Image-1.5 และ Nano Banana Pro จะให้ผลลัพธ์ยอดเยี่ยม แต่ทั้งสองโมเดลต่างกันในปรัชญาการแก้ไข เวิร์กโฟลว์ และโฟกัสลูกค้า
ChatGPT Images โฟกัสการแยกพิกเซลอย่างแม่นยำ ซึ่งเด่นด้านการควบคุมแบบแมนนวล: เลือกพื้นที่ได้ตรงเป๊ะ และปฏิบัติต่อพื้นที่นั้นเหมือนผ้าใบสำหรับ in-painting โดยที่ส่วนอื่นของภาพถูกล็อกไว้ ขณะที่ Nano Banana Pro พยายามเข้าใจเจตนาของคุณเพื่อปรับเปลี่ยนให้ถูกต้อง
ด้านเวิร์กโฟลว์ ทั้งสองบริษัทยังเลือกแนวทางต่างกัน: แท็บ Images ใน ChatGPT ให้ความรู้สึกเหมือนสตูดิโอสร้างสรรค์ แยกจากการสนทนา ในขณะที่ Nano Banana Pro ผสานในสตรีมแชทอย่างเต็มรูปแบบ
อัปเดต: เวอร์ชันใหม่ของโมเดลสร้างภาพแบบไม่โปรของ Google คือ Nano Banana 2 ได้เพิ่มการปรับปรุงที่สำคัญ แม้ Nano Banana Pro จะยังได้เปรียบเล็กน้อย แต่โมเดลใหม่ให้คุณภาพ (เกือบ) เท่ากันที่ความเร็วสูงกว่ามาก
ควรใช้ ChatGPT Images หรือ Nano Banana Pro เมื่อใด
ฉันแนะนำให้ใช้ ChatGPT Images หากต้องแก้เลย์เอาต์ แก้ไขข้อความ หรือปรับเปลี่ยนเฉพาะจุดในภาพที่มีอยู่โดยไม่เปลี่ยนสไตล์ เลือก Nano Banana Pro หากต้องสร้างภาพข้อมูลหนาแน่น รีมิกซ์ภาพหลายใบ หรือชอบให้ผู้ช่วยอัจฉริยะเดาเจตนามากกว่าควบคุมด้วยตนเอง
เมื่อใช้พรอมต์เดียวกับด้านบน ฉันสร้างภาพทดสอบซ้ำอีกครั้ง โดยส่วนตัวฉันชอบอินโฟกราฟิกของ Nano Banana Pro มากกว่า ส่วนภาพหมีนั้นสูสีกัน
พรอมต์: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
กรณีใช้งาน ChatGPT Images
จากการทดสอบจริงและจุดแข็งเฉพาะของ GPT-Image-1.5 โมเดลนี้โดดเด่นเมื่อเป็นกระบวนการแบบวนซ้ำและการแก้ไขข้อความ กรณีใช้งานเด่นมีดังนี้:
- เวิร์กโฟลว์การตลาด: สร้างโฆษณาโซเชียลหรือภาพสินค้า ที่ต้องเปลี่ยนรายละเอียดเฉพาะ (เช่น “เปลี่ยนสีเสื้อกันหนาวจากแดงเป็นน้ำเงิน”)
- อินโฟกราฟิกเพื่อการศึกษา: สร้างแผนภาพสำหรับตำรา นำเสนอ หรือบล็อก อย่างตัวอย่าง “วัฏจักรชีวิตของดาว” ของเรา
- สตอรีบอร์ด: จำลองภาพสคริปต์หรือคอมิกที่ตัวละครเดียวกันต้องปรากฏในหลายสถานที่
- แฟชั่น: ใช้การสร้างคอนเทนต์แบบผสมเพื่อสำรวจชุดแต่งกายด้วยภาพ เช่น ในบทเรียนสร้างตัวช่วยจัดตู้เสื้อผ้า FLUX.2
- ออกแบบภายใน: ผสมสเก็ตช์คร่าว ๆ หรือภาพถ่ายเข้ากับพรอมต์เพื่อปรับตกแต่งห้องในสไตล์เฉพาะ
- ต้นแบบ UI/UX: จำลองภาพหน้าแลนดิ้งเว็บไซต์หรือบรรจุภัณฑ์ของสินค้าว่าอาจมีหน้าตาอย่างไรอย่างรวดเร็ว
ข้อคิดส่งท้าย
นับตั้งแต่การเปิดตัว Nano Banana Pro OpenAI เผชิญแรงกดดันอย่างมากให้ก้าวให้ทัน ด้วยการอัปเดตที่มีความหวังนี้ พวกเขากลับเข้าสู่สนามแข่งโมเดล AI สร้างภาพจากข้อความที่ทรงความสามารถอีกครั้ง แม้ไม่ไร้ที่ติ แต่หากโฟกัสที่สิ่งจำเป็นอย่างตัวอักษรคมชัดและการแก้ไขแม่นยำ ก็ได้ผลลัพธ์ที่ดี เริ่มต้นได้ด้วยการลองใช้ฟีเจอร์ใน UI ของ ChatGPT หรือในOpenAI Playground สำหรับแรงบันดาลใจ ลองดูแกลเลอรีและคำแนะนำการเขียนพรอมต์
หากต้องการเริ่มสร้างเครื่องมือด้วยโมเดล GPT OpenAI Fundamentals skill track ของเราคือจุดเริ่มที่เหมาะสม