はい。GPT-Image-1.5 は OpenAI API で利用可能で、ChatGPT Images と同様の改良点を備えています。画像の入出力は GPT Image 1 より約20%低コストで、マーケティング、EC、デザインのワークフローに適しています。
ChatGPT Images とは?
ChatGPT の新しい Images タブは、ChatGPT の UI 内でビジュアル制作のハブとして機能し、個人用の画像ライブラリを置き換えます。最も大きな変化は、画像内の特定のディテールだけを狙って編集し、他の部分はそのまま保てる直接編集ツールが統合された点です。
ChatGPT Images を支えるのは、OpenAI の最新かつ最先端のテキストから画像のAIモデルである GPT-Image-1.5 です。これは GPT-Image-1(2025年3月リリース)を土台としており、公開初週で7億枚以上が生成される大きな成功を収めました。
ディテール保持とテキスト描画が改善され、前モデルより「最大4倍」高速だとされています。
新機能は、Web、モバイルUI、APIのすべてで、無料・有料の全ユーザーに提供開始済みです。現時点では Business と Enterprise のみ、アクセス待ちとなっています。
ChatGPT Images の主な機能
では、ChatGPT Images は前モデルや競合と比べて何が優れているのでしょうか。OpenAI は特に「大事なものを保ちながらの精密編集」を強調しています。新機能の意味を具体的に見ていきましょう。
専用のクリエイティブ・ワークスペース
Images タブは、ChatGPT の UI 内におけるビジュアル制作のハブとして導入されました。通常のチャットから、画像の生成・編集を切り分ける発想です。
従来の「ライブラリ」機能も生成画像を保存していましたが、できるのは作成元の会話に戻ることだけでした。新たな画像を一から作る際には会話全体の履歴を文脈として用いるため、長いスレッドではしばしばハルシネーションが起きがちでした。
新アプローチは、より画像中心です。各編集は画像を起点とし、全面的に作り直すのではなく、選択した要素のみを変更します。
画像は会話履歴に埋もれない「成果物」として残り、新しいバリエーションで素早いフィードバックループが回せます。実験も促され、体験はチャットスレッドからキャンバスへと近づきます。
この創作フローをさらに後押しするため、ワークスペースにはアイデアと実装のギャップを埋める探索ツールが導入されました。内蔵のスタイルプリセット(「スケッチ」「ドラマチック」など)を適用したり、トレンドの美学を閲覧して次の「スタジオジブリ」を追いかけることも可能です。初心者向けに、UI はクリエイティブな提案やプロンプト支援を積極的に行い、仕上がりを磨く手助けをします。
ディテール保持と精密編集
おそらく最重要の新機能として、画像の特定部分を選択してそこだけを直接編集し、構図の残りには手を触れないことが可能になりました。モデルはコンテキストを理解し、どこを編集すべきかを把握しつつ、周囲の要素の一貫性を保ちます。
こうしたシャープな編集を支えるのが、新モデルのディテール保持能力の向上です。
オブジェクト、光源、構図、人物の外見を、出力間や連続する編集にわたって一貫して保てます。また、指示追従性の改善により、要素間の関係性をよりよく保持でき、精度向上に寄与しています。
精密編集は、全面的な再生成が不要な場合に細かな不備を直したり、特定のディテールで実験するのに最適です。また、ある画像の要素を別のシーンに持ち込むといった創造的な変換も可能になります。
ただし、1枚の画像に多くの人物が写っている場合、全員の「まったく同じ個体性」を保つのは苦手です。
テキスト描画とリアリズムの向上
前モデル GPT-Image-1 の大きな特徴の一つは、長いテキストや意味の通った文の扱いでした。今回のリリースはその基盤を拡張し、より密度が高く小さなテキストにも対応できるようになりました。
これは特にインフォグラフィックで有用で、初期結果もかなり良好です。新聞のように、画像内でのテキストのマークダウンといった新たな可能性も広がります。後ほどインフォグラフィックのテストも行います。
ただし、OpenAI の発表によると、中国語、アラビア語、ヘブライ語など一部の言語に関する制約は依然残っているようです。
今回の焦点ではないものの、出力のリアリズムも前モデルに比べて大きく改善しました。反射(写真のグレアなど)や、大勢の群衆における多数の小さな顔などで特に効果が見られます。
ただし、大幅なアップグレードには特定分野でのトレードオフがつきものです。今回は、特定のアートスタイルの生成能力がやや後退しています。OpenAI は Images タブのプリセットフィルターの使用、または 前モデル(カスタム GPT として引き続き利用可能)への切り替えを推奨しています。
パフォーマンスの加速
生成速度の大幅な向上の多くも、ターゲットを絞った編集機能に由来します。完全生成の速度も確かに上がっていますが、OpenAI のリリースノートにある主張どおりとは言い切れません。GPT-Images-1.5 が「最大4倍速く」感じられるのは、編集時に変更部分だけを再生成するためです。
同様に、API コストが約20%低下したのも、主に編集時の部分再生成によるもので、残りは推論の効率化による追加の効果であり、完全生成自体が大幅に安くなったわけではありません。
総じて、新機能は特に API ワークフローで、より効率的かつ信頼性の高い活用を可能にします。
ChatGPT Images の作例
発表内容はたしかに魅力的です。ここでは、いくつかのシンプルなプロンプトと新しい選択ツールを組み合わせて、実際に試してみました。
編集精度のテスト
最初のテストの目的は、品質を落とさずに反復的な変更を扱えるかどうかを評価することでした。まず、白夜のフィンランドの森を歩くヒグマの画像を作らせました。

プロンプト:「白夜の時間帯、鬱蒼としたフィンランドの森を歩くヒグマ」
最初の出力の品質は非常に高いと感じました。クマは自然で、木々や下草の種類もフィンランドの森をよく表しています(よく知っています!)。太陽の低い位置も、白夜の北部フィンランドで見られる光景に合致しています。
加えて、クマの毛並みや背景の光と影もかなりリアルです。細部は良いものの、どこかAIだと分かる感じは残ります。
では、このクマをホッキョクグマに変えてみましょう。フィンランドにホッキョクグマはいませんが、うまくいけば背景はそのままのはずです。

プロンプト:「クマをホッキョクグマに変えて」
ご覧のとおり、背景は意図どおり完全に維持されました。
次に、ホッキョクグマの頭部と目を選択し、ビンテージのサングラスをかけさせました。

プロンプト:「クマにビンテージのサングラスをかけて」(頭部を選択)
選択範囲が大きすぎると何が起きるか分かりました。背景やクマの体は一貫していますが、頭部全体が巨大なサングラスのようになってしまいました。今度は目だけを選択して試します。

プロンプト:「クマにビンテージのサングラスをかけて」(目を選択)
とても良い、確実に改善しました。最初のテストでは、ディテール保持機能の強力さがよく分かりました。情景の重要要素は最初に一度述べるだけでよく、主役のほうは背景を気にせず反復編集できます。もう一つの学びは、選択範囲の大きさが結果に影響することです。
変換の一貫性テスト
次に、別のシーン間でのオブジェクト永続性と、大勢の人混みにおけるモデルの限界を試しました。ホッキョクグマに少し旅をしてもらい、東京の混雑した地下鉄のシーンに移してみます。

プロンプト:「このクマを、とても混雑した東京の地下鉄のシーンに配置して」
まず、キャラクターの一貫性は見事です。クマの姿勢や個体性は完全に保持され、毛のハイライトも消えています。
しかし、この厳密な保持が「ステッカー効果」と呼ばれる視覚的な違和感を生みました。光の文脈が更新されず(方向性のある影やサングラスの森の反射が残ったため)、クマが3Dオブジェクトではなく、シーンに貼り付けられた2Dの切り抜きのように見えます。
遠近感も錯覚を悪化させています。クマがカメラに近い通行人の前に浮いて見えます。
この後者の問題を直そうとしましたが、かなり骨が折れました。通行人とクマが重なる領域を選択し、遠近を修正するよう依頼しました。ところが毎回、モデルはカメラ手前に新たな人物を挿入してしまいます。例えば次のように。

プロンプト:「遠近を修正:選択した通行人の背中は前景にあり、クマを部分的に隠すべきです。クマは人物の背中の後ろに立っています。」
選択していても人物を特定できず、プロンプトの指示に従わせるために新しいキャラクターを挿入する必要があったようです。
影とサングラスの反射の修正は、よりうまくいきました。以下のように反復しました。
- 影:クマの足元の床を選択し、「現在の影ではなく、頭上の蛍光灯照明と整合する、柔らかく拡散した影をタイル床に落として」と指示
- サングラス:サングラスを選択し、「サングラスの反射を地下鉄の環境に合わせて更新して」と指示

影とサングラスの反射を修正した後の、東京の地下鉄にいるホッキョクグマ
かなり改善しましたが、完璧ではありません。
総じて、2つ目のテストは1つ目ほど順調ではありませんでした。別画像間での要素の一貫性は良好な一方、混雑環境ではキャラクター認識に限界が見られます。
テキスト描画のテスト
最後に、新しいテキスト描画能力、特に密度の高いテキストや編集時の挙動を試しました。テキスト描画の改善は歓迎です。歴史的に視覚モデルは、記号よりもオブジェクト、テクスチャ、シーンを得意としてきたからです。
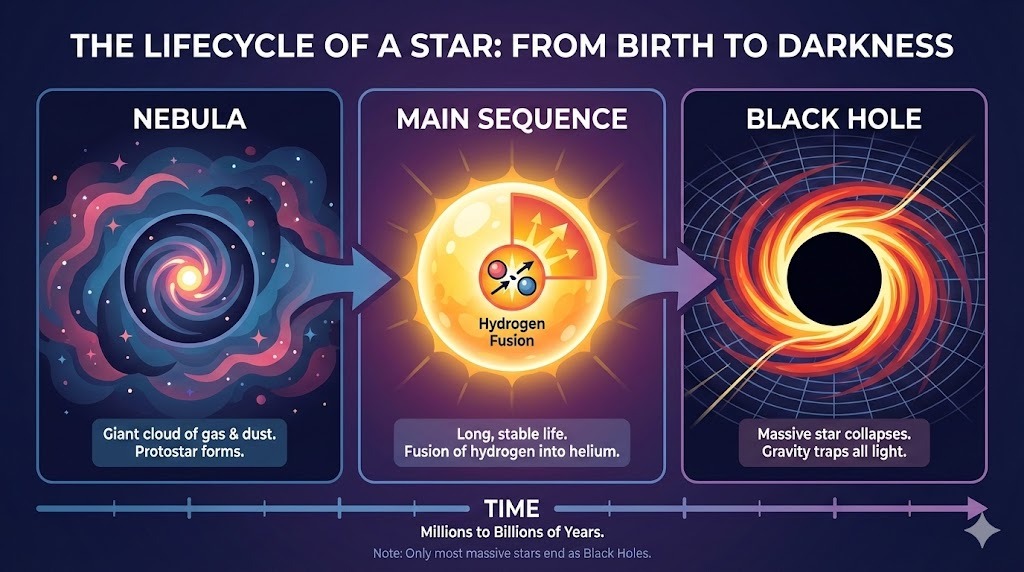
ChatGPT に、恒星のライフサイクルに関するインフォグラフィックの複雑なレイアウトを依頼しました。
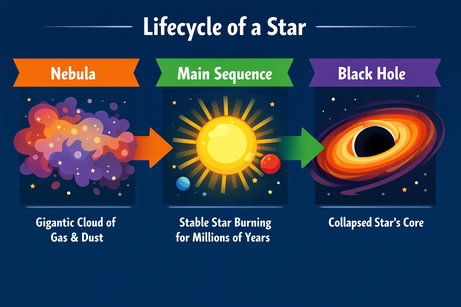
プロンプト: "『恒星のライフサイクル』を説明する横長のインフォグラフィック。セクションは3つ:星雲、主系列、ブラックホール。フラットなベクタースタイルで。"
出力は指示どおりで、誤りなくテキストを描画できました。スタイルも全体で一貫しています。
ChatGPT の出力がマルチモーダルである点には注意が必要です。選択範囲に対して「ここに」箇条書きを追加してとだけ指示した際は、テキスト出力として箇条書きが返ってきました。「画像に」という明示を加えたところ、うまくいきました。
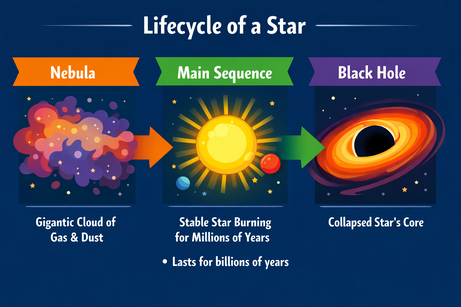
プロンプト:「この画像のここに『数十億年続く』という箇条書きを追加して」
明示後は、箇条書きが正しい位置に挿入されました。フォント、サイズ、色はグラフィックのスタイルに合致しています。
ChatGPT Images へのアクセス方法
ChatGPT Images は、ほぼすべてのユーザーに、複数のプラットフォームで提供されています。Business と Enterprise への対応のみ、後日提供予定です。
UI では、Web またはモバイルアプリの Images タブからすぐに利用できます。正確な数値は非公開ですが、Free アカウントには厳格なデイリー上限があり、Plus と Pro では段階的に高く安定した枠が用意されています。
開発者は、新しい GPT-Image-1.5 モデルを OpenAI API と Azure OpenAI Service の両方から、画像の生成と編集に利用できます。主要なサードパーティのクリエイティブスイートへの統合が今後期待されますが、すでに v1/images/generations と v1/images/edits エンドポイントで、自前アプリに編集ワークフローを実装可能です。
前モデルと異なり、GPT-Image-1.5 は画像出力をトークンとして個別課金し、統一の /v1/responses ではなく画像専用の API エンドポイントを用います。毎回、画像全体ではなく、変更に必要なトークン分のみを支払います。
このため、新モデルは前モデルより約20%安いとされていますが、トークン単価自体は GPT-Image-1 から変更されていません。
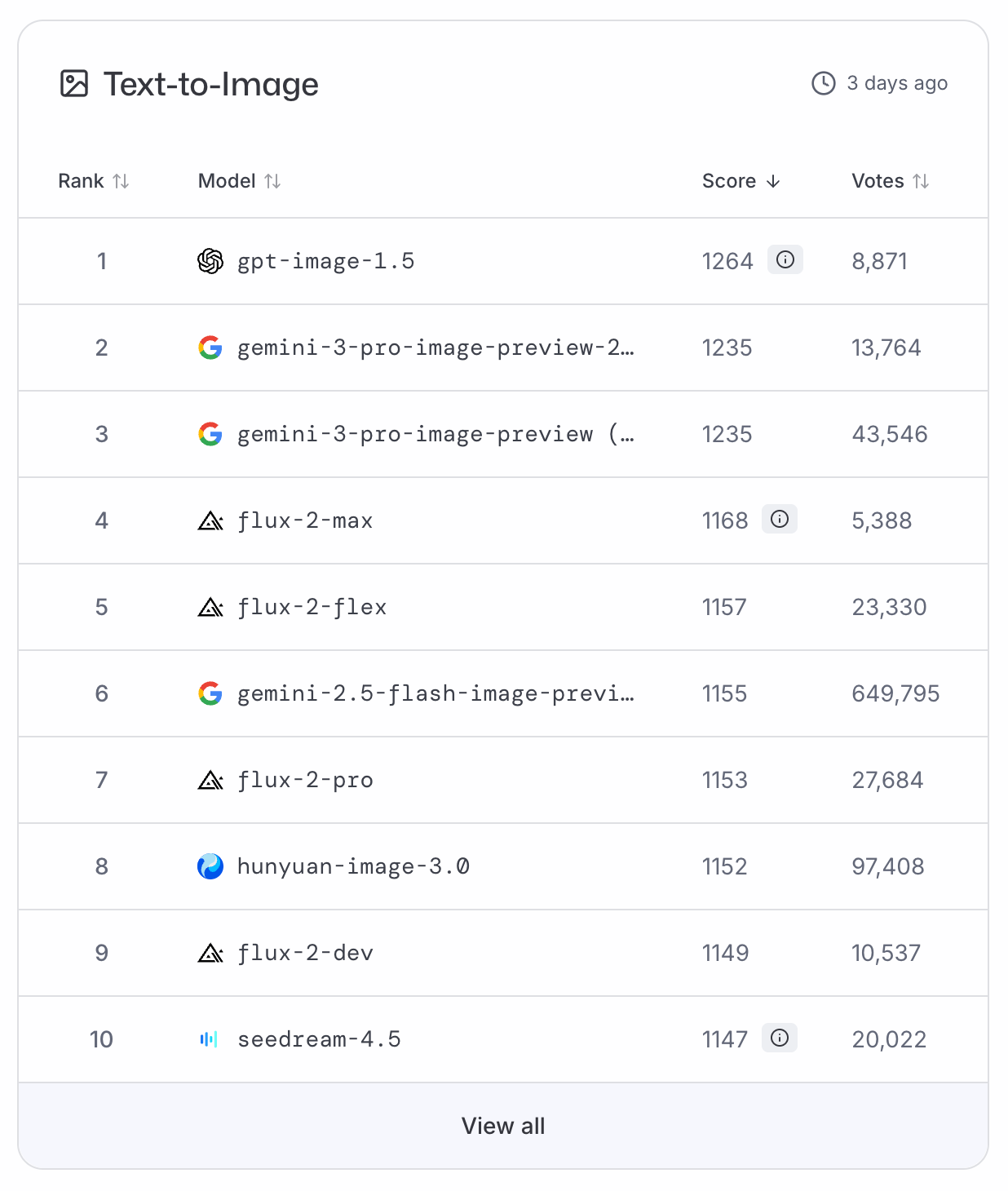
ChatGPT Images の実力は?
GPT-Image-1.5 は LMArena と ArtificialAnalysis のテキストから画像のランキングで首位に躍り出て、Nano Banana Pro を2位に押しやりました。現時点でベンチマークデータがないため、客観的な位置づけとしては、これらの投票ベースのランキングに頼る必要があります。
有名な宇宙飛行士の言葉を借りれば、GPT-Image-1.5 は業界にとっては小さな一歩、しかし OpenAI にとっては大きな飛躍です。
精密編集自体は目新しいものではありませんが、ChatGPT にネイティブ統合したことが今回最大の転換点です。ただし、精度が鍵です。テストで見られた「首なしホッキョクグマ」のような不具合を避けるには、必要最小限の範囲だけを選択しましょう。
私の経験では、品質は大きく向上しており、ランキング結果にもそれが表れています。標準的な画像は以前よりも生き生きとしており、インフォグラフィックは過度に単純化されなくなりました。
ユーザーは各出力をより細かく制御できるようになり、複雑な追加入力で運を天に任せる旧来のワークフローを置き換えられます。これは主に、ディテール保持が非常にうまく機能するためです。テスト全般で、要素は完全に保たれました。
キャラクターの一貫性も強力ですが、「ステッカー効果」や論理的な遠近の問題には注意が必要です。ターゲット編集で修正しやすくなったとはいえ、人混みなどのシーンには依然として限界があります。
ChatGPT Images と Nano Banana Pro の比較
現在、ChatGPT Images が打ち勝つべき筆頭は、明らかに Google の Nano Banana Pro です。以下の表で両モデルを比較します。
|
ChatGPT Images |
Nano Banana Pro |
|
|
編集モデル |
精密:領域選択&インプレース編集 |
推論:会話的&スマートマスキング |
|
ワークフロー |
専用のクリエイティブ・ワークスペース |
チャット機能に統合 |
|
反復 |
効率的:部分再生成 |
探索的:リミックス |
|
一貫性 |
高いレイアウト&ディテール保持 |
高いレイアウト&ディテール保持 |
|
エコシステム |
OpenAI & Azure |
Google / Gemini スタック |
GPT-Image-1.5 と Nano Banana Pro はいずれも優れた結果を出しますが、編集哲学、ワークフロー、顧客志向が異なります。
ChatGPT Images はピクセル単位の分離に注力し、手動コントロールに強みがあります。正確な領域を選択し、その部分をインペイント用のキャンバスのように扱い、他の部分はロックします。一方、Nano Banana Pro は、意図を理解して最適な変更を施そうとします。
ワークフローでも両社は別の道を選びました。ChatGPT の Images タブは会話と切り離されたクリエイティブスタジオのように感じられるのに対し、Nano Banana Pro はチャットストリームに完全統合されています。
アップデート:Google の非 Pro 版画像生成モデルの新バージョン Nano Banana 2 が大幅な改良を導入しました。Nano Banana Pro にわずかな優位性は残るものの、新モデルははるかに高速で(ほぼ)同等の品質を提供します。
ChatGPT Images と Nano Banana Pro の使い分け
レイアウトの修正、テキストの編集、既存画像のスタイルを変えずに精密な変更が必要な場合は ChatGPT Images をおすすめします。データ量の多いビジュアルの生成、複数画像のリミックス、あるいは手動より賢いアシスタントに意図推測を任せたい場合は Nano Banana Pro を選ぶとよいでしょう。
上記と同じプロンプトで再現したところ、個人的にはインフォグラフィックは Nano Banana Pro のほうが好みで、クマの画像はほぼ同等でした。
プロンプト: "『恒星のライフサイクル』を説明する横長のインフォグラフィック。セクションは3つ:星雲、主系列、ブラックホール。フラットなベクタースタイルで。"(Nano Banana Pro)
ChatGPT Images のユースケース
ハンズオン検証と GPT-Image-1.5 の強みから、反復プロセスやテキスト編集で特に力を発揮します。代表例は次のとおりです。
- マーケティングのワークフロー:特定のディテールが変更対象となるSNS広告や商品写真の作成(例:「セーターの色を赤から青に変更」)
- 教育用インフォグラフィック:教科書、プレゼン、ブログ向けの図表生成(本記事の「恒星のライフサイクル」の例など)
- ストーリーボード:同じキャラクターを異なる場所に登場させる脚本やコミックのビジュアライズ
- ファッション:ハイブリッドなコンテンツ制作でコーディネートを視覚的に検討(例:こちらの FLUX.2 ワードローブ可視化チュートリアル)
- インテリアデザイン:ラフスケッチや写真にプロンプトを組み合わせて、特定スタイルで部屋をリデザイン
- UI/UX モックアップ:新製品のランディングページやパッケージの見た目を素早く可視化
まとめ
Nano Banana Pro の登場以来、OpenAI にはキャッチアップの圧力がかかっていましたが、この有望なアップデートで、最も高機能なテキストから画像のAIモデルを巡る競争に復帰しました。完璧ではないものの、はっきりしたタイポグラフィと精密編集といった要点にフォーカスすれば、良好な結果を得られます。まずは ChatGPT の UI か OpenAI Playground で試してみてください。インスピレーションには ギャラリーやプロンプトガイドが役立ちます。
GPT モデルを使ったツール開発を始めたい方は、OpenAI Fundamentals スキルトラックをご活用ください。