Да. GPT-Image-1.5 доступна в OpenAI API и включает те же улучшения, что и ChatGPT Images. Входные и выходные изображения примерно на 20% дешевле, чем в GPT Image 1, что делает модель подходящей для маркетинга, ecommerce и рабочих процессов в дизайне.
Что такое ChatGPT Images?
Новая вкладка Images в ChatGPT служит креативным центром для всего визуального в интерфейсе ChatGPT и заменяет личную библиотеку изображений. Самое заметное изменение — интеграция инструментов прямого редактирования, позволяющих нацеливаться на конкретные детали в изображении, сохраняя неизменными все остальные.
За ChatGPT Images стоит GPT-Image-1.5 — последняя и самая продвинутая текст-В-изображение модель OpenAI. Она развивает успех GPT-Image-1, выпущенной в марте 2025 года, которая стала большим успехом — свыше 700 миллионов изображений за первую неделю.
Она обеспечивает сохранение деталей и улучшенный рендеринг текста и, как заявлено, работает «до 4 раз» быстрее предшественника.
Новые функции развернуты для всех пользователей — и бесплатных, и платных — в веб-версии, мобильном интерфейсе и API. Доступ пока ждут только аккаунты Business и Enterprise.
Ключевые функции ChatGPT Images
Итак, что предлагает ChatGPT Images по сравнению с предыдущей моделью и конкурентами? OpenAI особенно продвигает «точные правки с сохранением важного». Давайте посмотрим на новые функции и разберёмся, что это означает.
Отдельное креативное пространство
Вкладка Images была представлена как центр визуального творчества в интерфейсе ChatGPT. Идея — отделить создание и редактирование изображений от обычных чат-взаимодействий.
Ранее функция Library тоже хранила все созданные изображения, но лишь предлагала вернуться к беседе, где они были сгенерированы. Для создания нового изображения она использовала контекст всей истории общения, что часто приводило к галлюцинациям в длинных ветках.
Новый подход более ориентирован на само изображение: каждая правка берёт за отправную точку конкретный кадр и меняет только выбранные аспекты, а не создаёт совершенно новую генерацию.
Изображения — это постоянные артефакты, а не элементы, «зарытые» в истории чата. Это ускоряет цикл обратной связи при создании вариаций и поощряет эксперименты, превращая опыт из чат-потока в работу на холсте.
Чтобы поддержать этот творческий поток, в рабочем пространстве появились новые инструменты для исследования, сокращающие путь от идеи к реализации. Пользователи могут применять встроенные пресеты стиля (например, «sketch» или «dramatic») или просматривать трендовые эстетики, чтобы не упустить следующий «Studio Ghibli». Новичкам интерфейс предлагает креативные подсказки и проактивную помощь с промптами для уточнения результатов.
Сохранение деталей и точное редактирование
Пожалуй, самая важная новая функция — возможность выделять конкретные части изображения и напрямую изменять их, не затрагивая остальную композицию. Модель учитывает контекст, то есть понимает, что именно нужно изменить, сохраняя при этом согласованность окружающих элементов.
Такие «острые» правки обеспечиваются улучшенными возможностями модели по сохранению деталей.
Она способна сохранять объекты, освещение, композицию и внешность людей согласованными между выходами и последующими правками. Кроме того, улучшенное следование инструкциям повышает точность, лучше сохраняя отношения между элементами.
Точное редактирование идеально подходит для исправления мелких недочётов и экспериментов с отдельными деталями, когда полная регенерация не нужна. Также оно позволяет на творческие трансформации, например перенести элемент из одного изображения в сцену другого.
Однако стоит отметить, что модели сложно сохранять точную идентичность каждого человека, если на изображении много людей.
Улучшенный рендеринг текста и реализм
Одной из ключевых особенностей предыдущей модели GPT-Image-1 была способность справляться с длинными фразами и связными предложениями. Новый релиз развивает эту основу и теперь способен корректнее отображать более плотный и мелкий текст, чем прежде.
Это особенно полезно для инфографики, где первые результаты весьма впечатляющие, и открывает новые возможности — например, верстку текста в изображении, как в газетной полосе. Тест инфографики мы проведём далее.
Однако, судя по заявлению OpenAI, ограничения в отношении некоторых языков, таких как китайский, арабский и иврит, по-прежнему сохраняются.
Хотя это не было главным фокусом обновления, реализм результата заметно улучшился по сравнению с предыдущей моделью. Особенно хорошо это заметно на отражениях, например блик на фото, и множестве маленьких лиц в больших толпах людей.
Как часто бывает, крупные апгрейды сопровождаются компромиссами в отдельных областях. В данном случае ухудшилась способность генерировать некоторые специфические художественные стили. OpenAI рекомендует использовать предустановленные фильтры во вкладке Images или обратиться к предыдущей модели, которая по-прежнему доступна как настраиваемый GPT.
Ускоренная производительность
Именно возможности точечного редактирования вносят наибольший вклад в рост скорости генерации. Полная генерация действительно быстрее, но не достигает заявленных в релизе OpenAI показателей. GPT-Images-1.5 кажется «до 4 раз быстрее» прежде всего потому, что при правках регенерирует только изменяемые области.
Аналогично, снижение стоимости API примерно на 20% в основном обусловлено частичной регенерацией при правках, а дополнительный выигрыш — более эффективным инференсом, а не удешевлением полной генерации.
В целом новые функции делают использование модели более эффективным и надёжным, особенно в API-процессах.
Примеры ChatGPT Images
Анонсированные функции звучат многообещающе. Я проверил их на практике с помощью нескольких простых промптов в сочетании с новым инструментом выделения.
Проверка точности правок
Цель первого теста — оценить способность модели справляться с итеративными изменениями без потери качества. Сначала я попросил создать изображение бурого медведя, идущего по финскому лесу во время белых ночей.

Промпт: «Бурый медведь, идущий по густому финскому лесу во время белых ночей».
На мой взгляд, качество первого результата очень высокое. Медведь выглядит естественно, тип деревьев и кустарников хорошо передаёт финский лес (я-то знаю!), а низкое положение солнца соответствует тому, что можно увидеть на севере Финляндии во время белых ночей.
Кроме того, освещение и тени на шерсти медведя, как и на заднем плане, выглядят довольно реалистично. По‑прежнему как-то чувствуется, что это ИИ, но детали приятные.
Попробуем превратить медведя в белого и посмотрим, что получится. В Финляндии белые медведи не водятся, но если всё сработает как надо, фон должен остаться прежним.

Промпт: «Поменяй медведя на белого медведя».
Как видим, фон полностью сохранился — именно как и задумывалось.
В следующей правке я выделил голову и глаза белого медведя и надел на него винтажные солнечные очки.

Промпт: «Надень на медведя винтажные солнечные очки». (выделена голова)
Похоже, мы узнали, что происходит, если выделить слишком большую область. Хотя фон и тело медведя сохранились, его голова превратилась в одни большие очки. Попробуем снова, выделив только глаза.

Промпт: «Надень на медведя винтажные солнечные очки». (выделены глаза)
Очень здорово и явно гораздо лучше! В этом первом тесте мы увидели, насколько мощна функция сохранения деталей: нам пришлось один раз задать важные детали сцены, после чего мы могли менять главного героя, не беспокоясь о фоне. Ещё один важный вывод — размер окна выделения имеет значение.
Проверка согласованности трансформаций
Далее я проверил «постоянство объекта» при переносе в разные сцены и ограничения модели в больших толпах. Для этого я «отправил» нашего белого медведя в токийское метро, поместив его в оживлённую сцену.

Промпт: «Помести этого медведя в очень оживлённую сцену в токийском метро».
Во‑первых, впечатляет согласованность персонажа: модель идеально сохранила точную позу и «личность» медведя и убрала блики солнца с его шерсти.
Однако такая жёсткая сохранность вызвала визуальный разрыв, известный как «стикер-эффект». Поскольку модель не обновила контекст освещения (сохранив направленную тень и лесные отражения в очках), медведь выглядит как 2D-вырезка, наклеенная на сцену, а не как трёхмерный объект в ней.
Перспектива ещё сильнее рушит иллюзию: медведь «парит» перед прохожим, который фактически ближе к камере.
Попытки исправить последнее оказались довольно раздражающими. Я выделил область прохожего и её пересечение с медведем и попросил ChatGPT скорректировать перспективу. В каждой вариации модель добавляла нового человека близко к камере — вот так:

Промпт: «Скорректируй перспективу: спина выделенного прохожего находится на переднем плане и должна частично закрывать медведя. Медведь стоит за спиной человека».
Похоже, модель не смогла опознать человека, даже при выделении, и потому добавляла нового персонажа, чтобы выполнить инструкцию.
Исправление тени и отражений в очках прошло успешнее. Я сделал такие итерации:
- Тень: выделите пол вокруг лап медведя и введите промпт: «Вместо текущей тени добавь мягкую рассеянную тень на плиточный пол метро, согласованную с верхним люминесцентным освещением».
- Очки: выделите очки и введите промпт: «Обнови отражения в очках, чтобы они соответствовали окружению метро».

Наш белый медведь в токийском метро после исправления тени и отражений в очках
Стало гораздо лучше, хотя и не идеально.
В целом второй тест получился менее удачным, чем первый. Хотя согласованность элементов между разными изображениями работает хорошо, распознавание персонажей, похоже, достигает предела в многолюдных сценах.
Проверка рендеринга текста
Наконец, я хотел проверить новые возможности рендеринга текста, особенно в отношении плотного текста и правок. Улучшения здесь были бы кстати, потому что исторически зрительные модели лучше справлялись с объектами, текстурами и сценами, а не с символами.
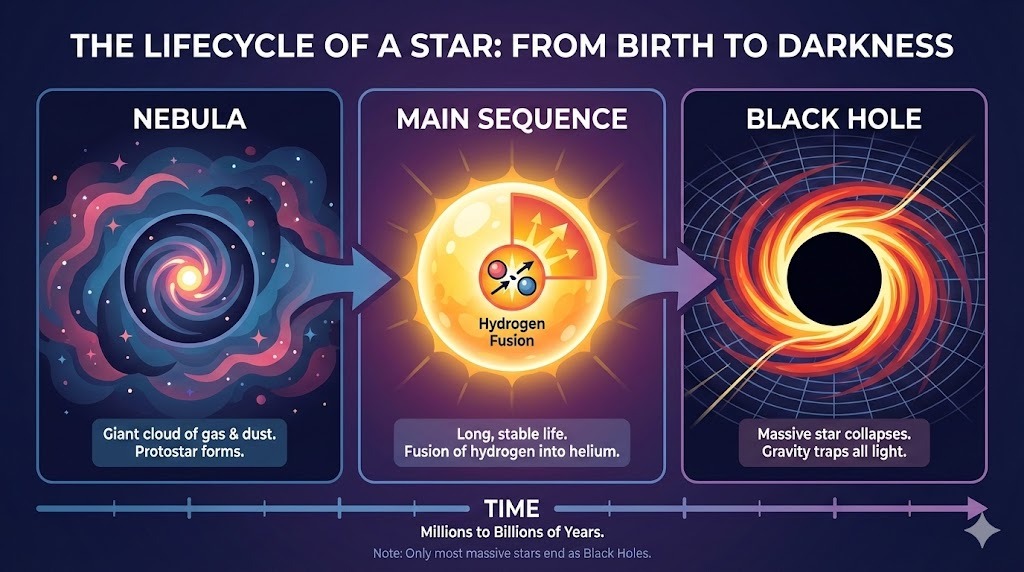
Я попросил ChatGPT создать сложный макет инфографики о жизненном цикле звезды:
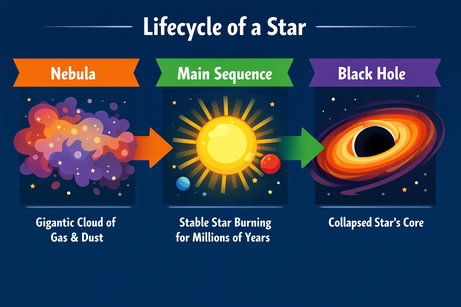
Промпт: "Горизонтальная инфографика, объясняющая «Жизненный цикл звезды». Три секции: Туманность, Главная последовательность, Чёрная дыра. Плоский векторный стиль."
Вывод точно следует инструкциям и рендерит текст без ошибок. Стиль точный и выдержан по всей инфографике.
Мультимодальность вывода ChatGPT требует точности при вставке текста. Когда я попросил добавить маркер «сюда» (в выделенную область изображения), модель просто выдала маркер как текстовый ответ. Добавление уточнения «на изображение» решило проблему:
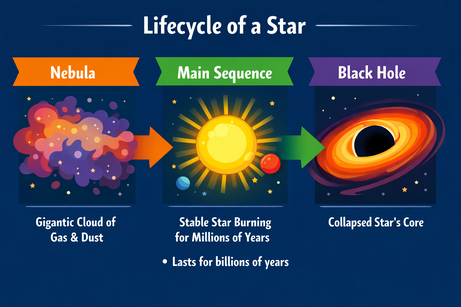
Промпт: «Добавь сюда на изображение маркер с текстом: 'Lasts for billions of years'.»
После уточнения маркер был вставлен в нужное место. Шрифт, размер и цвет соответствуют стилю графики.
Как получить доступ к ChatGPT Images?
ChatGPT Images уже доступен почти всем пользователям на разных платформах. Поддержка для уровней Business и Enterprise пока отсутствует и появится позже.
В интерфейсе вы можете сразу воспользоваться функциями во вкладке Images — в веб-версии или мобильном приложении ChatGPT. Хотя точные цифры неизвестны, для бесплатных аккаунтов действуют строгие дневные лимиты, а для планов Plus и Pro — более высокие и стабильные квоты.
Разработчикам новая модель GPT-Image-1.5 доступна через OpenAI API и Azure OpenAI Service для генерации и редактирования изображений. Хотя вскоре мы ожидаем интеграцию модели в ведущие сторонние креативные пакеты, уже сейчас можно строить рабочие процессы редактирования прямо в своих приложениях через эндпоинты v1/images/generations и v1/images/edits.
В отличие от предшественницы, GPT-Image-1.5 выставляет стоимость вывода изображений как отдельные токены, используя специализированные для изображений эндпоинты API вместо унифицированного /v1/responses. Вы платите только за токены, необходимые для внесённых изменений, а не за полную генерацию картинки каждый раз.
Поэтому новая модель считается примерно на 20% дешевле предшественницы, хотя цены за токен не изменились по сравнению с GPT-Image-1.
Насколько хорош ChatGPT Images?
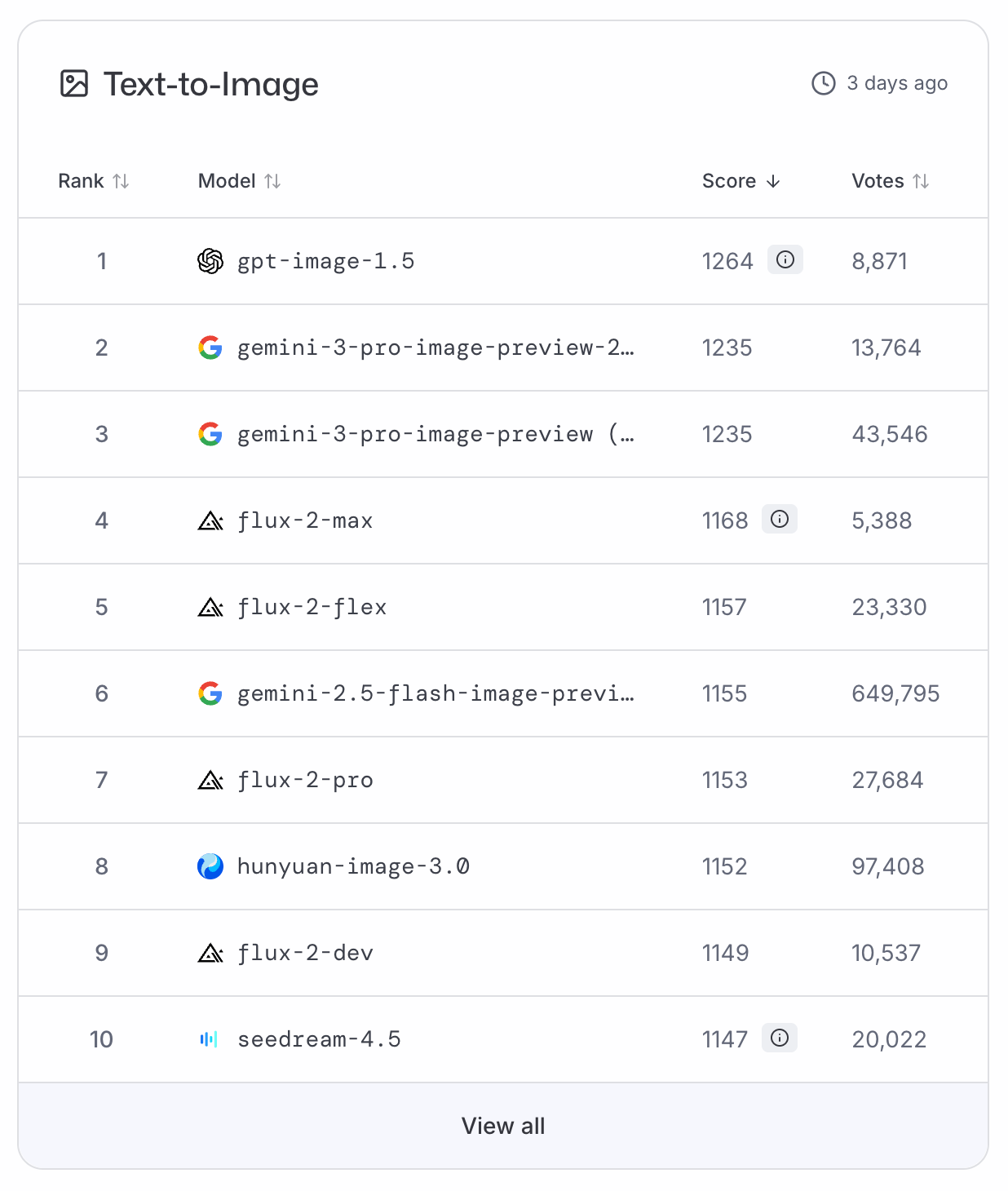
GPT-Image-1.5 сразу поднялась на вершину рейтингов LMArena и ArtificialAnalysis по текст-В-изображение, сместив Nano Banana Pro на второе место. Поскольку бенчмарков пока нет, для объективной оценки приходится полагаться на рейтинги на основе голосований.
Переиначивая слова известного астронавта: GPT-Image-1.5 — это маленький шаг для индустрии, но гигантский скачок для OpenAI.
Хотя точное редактирование — не абсолютная новинка, его нативное появление в ChatGPT — главный сдвиг обновления. Но точность критична: выделяйте только необходимые области, чтобы избежать «глюков» вроде «безголового белого медведя», с которым мы столкнулись в тестах.
По моему опыту, обновление даёт заметный скачок качества, что отражено и в рейтингах. Обычные изображения выглядят живее, а инфографика — гораздо менее упрощённой.
Пользователи теперь получают существенно больший контроль над результатом, заменяя прежний подход — «сочинять сложные уточняющие промпты и надеяться на лучшее». Во многом это благодаря отличной работе механизма сохранения деталей: в наших тестах элементы оставались полностью нетронутыми.
Согласованность персонажей сильная, но стоит следить за «стикер-эффектом» и логическими ошибками перспективы. Точечные правки упрощают исправление, но ограничения в многолюдных сценах всё ещё есть.
ChatGPT Images vs. Nano Banana Pro
Главный конкурент, которого должен обойти ChatGPT Images, — очевидно, Nano Banana Pro от Google. В таблице ниже сравниваются обе модели:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Модель редактирования |
Точность: выделение области и правки «на месте» |
Рассуждение: диалог и умное маскирование |
|
Рабочий процесс |
Отдельное креативное пространство |
Интеграция в чат |
|
Итерации |
Эффективность: частичная регенерация |
Исследование: ремиксинг |
|
Согласованность |
Высокое сохранение макета и деталей |
Высокое сохранение макета и деталей |
|
Экосистема |
OpenAI и Azure |
Google / стек Gemini |
Хотя GPT-Image-1.5 и Nano Banana Pro дают отличные результаты, модели различаются философией редактирования, рабочими процессами и ориентацией на клиента.
ChatGPT Images делает ставку на пиксель-точную изоляцию, что даёт преимущество в ручном контроле: вы выделяете точную область, и модель воспринимает её как холст для дорисовки, блокируя остальную часть изображения. Nano Banana Pro, напротив, пытается понять ваше намерение и внести соответствующие изменения.
С точки зрения рабочего процесса компании тоже выбрали разные пути: вкладка Images в ChatGPT ощущается как креативная студия, отделённая от бесед, тогда как Nano Banana Pro полностью интегрирован в поток чата.
Обновление: новая версия «не-pro» модели генерации изображений Google, Nano Banana 2, принесла значимые улучшения. Хотя Nano Banana Pro по-прежнему чуть впереди, новая модель предлагает (почти) то же качество на куда большей скорости.
Когда использовать ChatGPT Images, а когда Nano Banana Pro
Я бы рекомендовал ChatGPT Images, если нужно править макеты, редактировать текст или вносить точные изменения в существующее изображение без изменения стиля. Выбирайте Nano Banana Pro, если нужно создавать визуализации с большим объёмом данных, делать ремиксы из нескольких картинок или вы предпочитаете умного ассистента, который угадывает намерение, вместо ручного контроля.
Используя те же промпты, я воссоздал тестовые изображения. Лично мне инфографика Nano Banana Pro понравилась больше, а «медвежьи» сцены получились на равных.
Промпт: "Горизонтальная инфографика, объясняющая «Жизненный цикл звезды». Три секции: Туманность, Главная последовательность, Чёрная дыра. Плоский векторный стиль." (Nano Banana Pro)
Сценарии использования ChatGPT Images
Основываясь на наших практических тестах и сильных сторонах GPT-Image-1.5, модель особенно хороша в итеративных процессах и редактировании текста. Вот несколько топовых кейсов:
- Маркетинговые процессы: создание объявлений для соцсетей или продуктовых снимков, где меняются конкретные детали (например, «Поменяй свитер с красного на синий»)
- Образовательная инфографика: генерация диаграмм для учебников, презентаций или блогов — как в нашем примере «жизненного цикла звезды»
- Сторибординг: визуализация сценария или комикса, где один и тот же персонаж появляется в разных локациях
- Мода: гибридное создание контента для визуального подбора образов — как в этом туториале по визуализатору гардероба FLUX.2
- Дизайн интерьеров: сочетание наброска или фото с промптами для редизайна комнат в определённом стиле
- UI/UX-макеты: быстрая визуализация лендинга или упаковки нового продукта
Итоги
После релиза Nano Banana Pro на OpenAI сильно давила необходимость не отставать. С этим многообещающим обновлением компания вновь в гонке за самый мощный текст-В-изображение ИИ. Это не идеал, но, фокусируясь на базовых вещах — чёткой типографике и точных правках, — можно получать отличные результаты. Чтобы начать, попробуйте функцию в интерфейсе ChatGPT или в OpenAI Playground. Для вдохновения загляните в галерею и руководство по промптам.
Если вы хотите начать создавать инструменты на основе GPT-моделей, вам подойдёт наш трек навыков OpenAI Fundamentals.