Ja. GPT-Image-1.5 finns i OpenAI API och inkluderar samma förbättringar som ChatGPT Images. Bildin- och utdata är ungefär 20% billigare än GPT Image 1, vilket gör den väl lämpad för tillämpningar som marknadsföring, e‑handel och designarbetsflöden.
Vad är ChatGPT Images?
ChatGPTs nya flik Images fungerar som en kreativ hubb för allt visuellt i ChatGPTs gränssnitt och ersätter det personliga bildbiblioteket. Den mest anmärkningsvärda förändringen är integreringen av direkta redigeringsverktyg som låter dig rikta in dig på specifika detaljer i en bild samtidigt som allt annat förblir intakt.
ChatGPT Images drivs av GPT-Image-1.5, OpenAIs senaste och mest avancerade text‑till‑bild‑modell. Den bygger vidare på lanseringen av GPT-Image-1 i mars 2025, som blev en stor framgång med över 700 miljoner genererade bilder under första veckan.
Den erbjuder detaljbevaring och förbättrad textrendering, och påstås vara ”upp till 4×” snabbare än sin föregångare.
De nya funktionerna har rullats ut till alla användare, både gratis- och betalnivåer, på webben, i mobilappen och via API. Endast Business- och Enterprise-konton får vänta lite till på åtkomst.
Nyckelfunktioner i ChatGPT Images
Vad erbjuder då ChatGPT Images jämfört med sin tidigare modell och konkurrenterna? OpenAI lyfter särskilt fram ”precisa redigeringar som bevarar det som är viktigt”. Låt oss titta på nyheterna och vad de innebär.
Dedikerad kreativ arbetsyta
Fliken Images introducerades som en hubb för visuellt skapande i ChatGPTs gränssnitt. Tanken är att separera bildskapande och redigering från vanliga chattinteraktioner.
Det tidigare biblioteket lagrade också alla genererade bilder, men erbjöd bara att ta dig tillbaka till konversationen där de skapades. Det använde kontext från hela konversationshistoriken för att skapa en ny bild från grunden, vilket ofta ledde till hallucinationer i längre trådar.
Det nya tillvägagångssättet är däremot mer bildcentrerat: Varje redigering tar en bild som utgångspunkt och ändrar bara utvalda aspekter av den, i stället för att skapa en helt ny generation.
Bilder är beständiga artefakter, inte begravda i en konversationshistorik. Det möjliggör snabbare feedbackloopar med nya varianter och uppmuntrar experimenterande, vilket i praktiken förvandlar upplevelsen från en chattråd till en duk.
För att främja det kreativa flödet ytterligare introducerar arbetsytan nya utforskningsverktyg som överbryggar gapet mellan idé och genomförande. Användare kan tillämpa inbyggda stilförval (som ”skiss” eller ”dramatisk”) eller bläddra bland trendande estetik för att fånga nästa ”Studio Ghibli.” För ovana skapare erbjuder gränssnittet kreativa förslag och proaktiv uppmaningshjälp för att förfina resultaten.
Detaljbevarande och precisionsredigering
Som den kanske viktigaste nyheten gör uppdateringen det möjligt att välja specifika delar av en bild och ändra dem direkt, utan att påverka resten av kompositionen. Modellen är kontextmedveten, vilket innebär att den förstår vad som ska redigeras samtidigt som omgivande element hålls konsekventa.
Denna typ av skarpa redigeringar möjliggörs av den nya modellens förbättrade förmåga att bevara detaljer.
Den kan hålla objekt, ljussättning, komposition och personers utseende konsekventa mellan utdata och efterföljande redigeringar. Även förbättrad instruktionsföljning bidrar till ökad precision genom att bättre bevara relationerna mellan element.
Precisionsredigering är perfekt för att rätta till småfel och experimentera med specifika detaljer när en fullständig ny generering inte behövs. Den möjliggör också kreativa transformationer, som att ta ett element från en bild och placera det i en annan scen.
Det är dock värt att nämna att modellen har svårt att bevara varje persons exakta identitet när många personer finns i samma bild.
Förbättrad textrendering och realism
En av de stora funktionerna i föregångaren GPT-Image-1 var förmågan att hantera längre text och sammanhängande meningar. Den nya versionen bygger vidare på det och klarar nu tätare och mindre text än tidigare.
Detta är särskilt användbart för infografik, där de första resultaten är ganska imponerande, och öppnar för nya möjligheter som text i tidningsliknande layout. Vi gör ett infografiktest längre fram.
Enligt OpenAIs pressmeddelande verkar dock begränsningar kvarstå för vissa specifika språk, såsom kinesiska, arabiska och hebreiska.
Även om det inte var huvudfokus i uppdateringen har realismen i utdata förbättrats avsevärt jämfört med den tidigare modellen. Två fall där det märks tydligt är reflektioner, till exempel blänk i ett foto, och många små ansikten i stora folksamlingar.
Som så ofta kommer större uppgraderingar med vissa kompromisser. I det här fallet har förmågan att generera vissa specifika konststilar försämrats. OpenAI rekommenderar att använda förinställda filter i fliken Images eller använda den tidigare modellen, som är fortfarande tillgänglig som en anpassad GPT.
Snabbare prestanda
Det är också i de riktade redigeringsmöjligheterna som största delen av den ökade genereringshastigheten uppstår. Även om full bildgenerering märkbart är snabbare, når den inte upp till påståendet i OpenAIs releasesammanfattning. GPT-Images-1.5 framstår som ”upp till 4× snabbare” främst för att den bara regenererar det som ändras vid redigeringar.
På samma sätt kommer den cirka 20% lägre API-kostnaden huvudsakligen av partiell regenerering under redigeringar, med ytterligare vinster från effektivare inferens snarare än billigare fulla genereringar.
Sammantaget möjliggör de nya funktionerna en mer effektiv och pålitlig användning, särskilt för API-arbetsflöden.
Exempel på ChatGPT Images
De utannonserade funktionerna låter onekligen lovande. Jag satte dem på prov med några enkla uppmaningar i kombination med det nya markeringsverktyget.
Test av redigeringsprecision
Målet med mitt första test var att utvärdera modellens förmåga att hantera iterativa ändringar utan kvalitetsförsämring. Först bad jag den skapa en bild av en brunbjörn som går genom en finsk skog under midnattssolen.

Uppmaning: ”A brown bear walking through a dense Finnish forest during the midnight sun.”
Enligt min mening är kvaliteten på den första bilden mycket hög. Björnen ser naturlig ut, typen av träd och buskar representerar finska skogar väl (jag borde veta!), och solens låga position stämmer med vad du kan förvänta dig i norra Finland under midnattssolen.
Dessutom ser ljussättningen och skuggorna i björnens päls, liksom i bakgrunden, ganska realistiska ut. Du kan fortfarande ana att det är AI på något sätt, även om detaljerna är fina.
Låt oss försöka göra björnen till en isbjörn och se vad som händer. Det finns inga isbjörnar i Finland, men om allt fungerar som det ska bör bakgrunden förbli densamma.

Uppmaning: ”Change the bear to a polar bear.”
Som vi kan se behölls bakgrunden helt intakt, precis som avsett.
Vid nästa redigering markerade jag isbjörnens huvud och ögon och satte på honom ett par vintage-solglasögon.

Uppmaning: ”Put a pair of vintage sunglasses on the bear.” (huvud markerat)
Det verkar som vi upptäckte vad som händer när du markerar ett för stort område. Medan bildens bakgrund och björnens kropp förblir konsekventa, förvandlades hans huvud till ett stort par solglasögon. Låt oss försöka igen, och bara markera ögonen.

Uppmaning: ”Put a pair of vintage sunglasses on the bear.” (ögon markerade)
Väldigt snyggt, och definitivt mycket bättre! I det första testet såg vi hur kraftfull funktionen för detaljbevarande faktiskt är: Vi behövde bara ange viktiga detaljer om miljön en gång och kunde iterera över huvudkaraktären utan att oroa oss för bakgrunden. En annan viktig lärdom är att storleken på markeringsrutan spelar roll.
Test av transformationskonsekvens
Därefter testade jag objektspermanens i olika miljöer och modellens begränsningar i stora folkmassor. För detta lät jag vår isbjörn resa lite och försökte placera honom i en fullsatt tunnelbanescen i Tokyo.

Uppmaning: ”Place this bear into a very busy subway scene in Tokyo.”
För det första är karaktärskonsekvensen imponerande: modellen bevarade björnens exakta hållning och identitet perfekt och tog bort solblänket från pälsen.
Detta styva bevarande orsakade dock en visuell diskrepans känd som ”klistermärkeseffekten”. Eftersom modellen inte uppdaterade ljuskontexten (behöll den riktade skuggan och skogsreflektionerna i solglasögonen) ser björnen ut som en 2D‑utklipp figur som klistrats på scenen snarare än ett 3D‑objekt i den.
Perspektivet bryter också illusionen: björnen svävar framför en förbipasserande som egentligen står närmare kameran.
Att försöka åtgärda det senare var ganska frustrerande. Jag markerade området med den förbipasserande och dess skärning med björnen och bad ChatGPT korrigera perspektivet. Vid varje variant lade modellen in en ny person nära kameran, precis så här:

Uppmaning: ”Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back.”
Det verkar som att modellen inte kunde identifiera personen, även när den var markerad, och därför krävdes en ny figur för att följa instruktionen i uppmaningen.
Att fixa skuggan och reflektionerna i solglasögonen gick bättre. Jag använde följande iterationer:
- Skugga: Markera golvet runt björnens fötter och använd uppmaningen ”Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting.”
- Solglasögon: Markera solglasögonen och använd uppmaningen ”Update the reflections of the sunglasses to match the subway environment.”

Vår isbjörn i Tokyos tunnelbana efter att skugga och glasögonreflektioner åtgärdats
Redan mycket bättre, om än inte perfekt.
Överlag var det andra testet inte lika lyckat som det första. Medan elementkonsekvens mellan olika bilder verkar fungera bra, verkar igenkänning av personer nå sina gränser i trånga miljöer.
Test av textrendering
Till sist ville jag testa de nya förmågorna för textrendering, särskilt vad gäller tät text och redigeringar. Förbättringar av textrendering vore välkomna eftersom visionsmodeller historiskt har varit bättre på objekt, texturer och scener än på symboler.
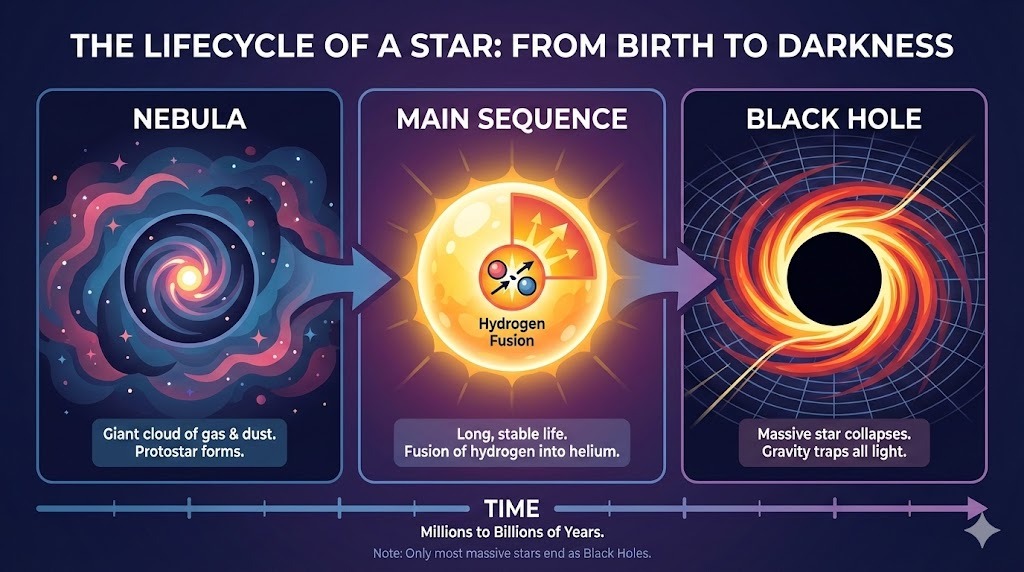
Jag bad ChatGPT om en komplex layout för en infografik över en stjärnas livscykel:
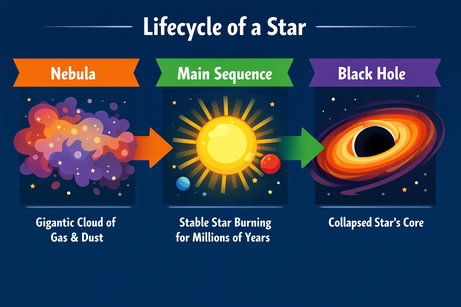
Uppmaning: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
Resultatet följer instruktionerna perfekt och renderar texten utan fel. Stilen är korrekt och konsekvent genom hela infografiken.
ChatGPTs multimodalitet tvingar oss att vara precisa när vi ska infoga text. När jag bad om att lägga till en punktlista ”här” (i ett markerat område i bilden) gav den bara punktlistan som textutdata. Att lägga till förtydligandet ”till bilden” gjorde susen:
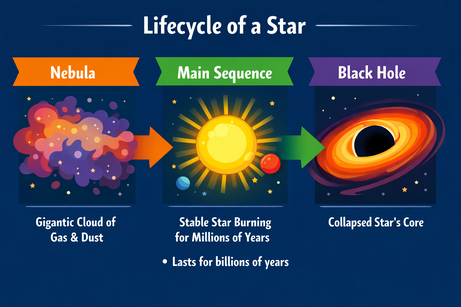
Uppmaning: ”Add a bullet point to the image here that says: 'Lasts for billions of years'.”
Efter förtydligandet placerades punktlistan på rätt plats. Typsnitt, storlek och färg matchar grafikens stil.
Hur får jag tillgång till ChatGPT Images?
ChatGPT Images är nu tillgängligt för nästan alla användare på flera plattformar. Endast stöd för användare i Business- och Enterprise-nivåerna saknas fortfarande och kommer senare.
I gränssnittet kan du komma åt funktionerna direkt i ChatGPTs webbgränssnitt eller mobilapp via fliken Images. Även om exakta siffror inte är kända gäller strikta dagliga gränser för kostnadsfria konton och successivt högre, mer stabila tilldelningar på Plus- och Pro‑planer.
För utvecklare kan den nya modellen GPT-Image-1.5 användas via både OpenAI API och Azure OpenAI Service, där den finns för bildgenerering och redigering. Även om vi förväntar oss att modellen snart integreras i större kreativa tredjepartssviter kan utvecklare redan nu bygga redigeringsarbetsflöden direkt i sina egna applikationer med ändpunkterna v1/images/generations och v1/images/edits.
Till skillnad från sin föregångare exponerar GPT-Image-1.5 bildutdata som separat prissatta token och använder bildspecifika API‑ändpunkter i stället för det enhetliga /v1/responses. Du betalar bara för token som krävs för att generera ändringarna, i stället för för en helt ny bild varje gång.
Detta är anledningen till att den nya modellen påstås vara cirka 20% billigare än sin föregångare, även om priset per token inte har ändrats jämfört med GPT-Image-1.
Hur bra är ChatGPT Images?
GPT-Image-1.5 klättrade omedelbart till toppen av LMArena och ArtificialAnalysis för text‑till‑bild, och petade ner Nano Banana Pro till andraplatsen. Eftersom det för närvarande inte finns någon benchmarkdata får vi förlita oss på dessa röstningsbaserade listor för en objektiv klassificering.
För att parafrasera en berömd astronaut: GPT-Image-1.5 är ett litet steg för branschen, men ett gigantiskt kliv för OpenAI.
Även om precisionsredigering inte är helt nytt markerar att ta in det inbyggt i ChatGPT den största förändringen i lanseringen. Men precision är avgörande: kom ihåg att bara markera nödvändiga områden för att undvika glitchar som den ”huvudlösa isbjörnen” i testet.
Min erfarenhet är att uppdateringen ger ett betydande kvalitetslyft, vilket också återspeglas i topplistorna. Standardbilder känns mer levande, och infografik ser betydligt mindre förenklad ut än tidigare.
Användare har nu avsevärt mer kontroll över varje resultat, vilket ersätter det gamla arbetsflödet med att snickra ihop komplexa följduppmaningar och hoppas på det bästa. Detta beror till stor del på att detaljbevarande fungerar mycket väl. I våra tester hölls elementen helt intakta.
Karaktärskonsekvensen är stark, men se upp för ”klistermärkeseffekten” och logiska perspektivproblem. Även om riktade redigeringar gör det lättare att fixa dessa, kvarstår begränsningar i trånga scener med många människor.
ChatGPT Images vs. Nano Banana Pro
Den nuvarande ledaren som ChatGPT Images tydligt måste besegra är Googles Nano Banana Pro. Tabellen nedan jämför båda modellerna:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Redigeringsmodell |
Precision: Områdesmarkering & redigering på plats |
Resonemang: Konversation & smart maskning |
|
Arbetsflöde |
Dedikerad kreativ arbetsyta |
Integrerad chattfunktion |
|
Iteration |
Effektivt: Partiell regenerering |
Utforskande: Remixning |
|
Konsekvens |
Hög behållning av layout & detaljer |
Hög behållning av layout & detaljer |
|
Ekosystem |
OpenAI & Azure |
Google / Gemini‑stacken |
Även om både GPT-Image-1.5 och Nano Banana Pro levererar utmärkta resultat skiljer sig modellerna åt i redigeringsfilosofi, arbetsflöde och kundfokus.
ChatGPT Images fokuserar på pixelfri isolering, vilket är starkt för manuell kontroll: Du kan välja ett exakt område, och den behandlar markeringen som en duk för in‑painting medan resten av bilden låses. Nano Banana Pro försöker å andra sidan förstå vad du vill göra för att göra rätt ändringar.
När det gäller arbetsflödet har företagen också valt olika vägar: Fliken Images i ChatGPT känns som en kreativ studio, separerad från konversationer, medan Nano Banana Pro är fullt integrerad i chattflödet.
Uppdatering: Googles nya version av den icke‑pro bildgenereringsmodellen, Nano Banana 2, har introducerat betydande förbättringar. Nano Banana Pro har fortfarande ett litet övertag, men den nya modellen erbjuder (nästan) samma kvalitet i mycket högre hastighet.
När ska du använda ChatGPT Images kontra Nano Banana Pro
Jag skulle föreslå ChatGPT Images om du behöver fixa layouter, redigera text eller göra precisa ändringar i en befintlig bild utan att ändra stilen. Välj Nano Banana Pro om du behöver generera datatunga visualiseringar, remixa flera bilder eller föredrar att en smart assistent gissar din avsikt framför manuell kontroll.
Med samma uppmaningar som ovan återskapade jag testbilderna. Personligen gillade jag Nano Banana Pros infografik mer, medan björnbilderna var likvärdiga.
Uppmaning: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
Användningsområden för ChatGPT Images
Baserat på våra praktiska tester och GPT-Image-1.5:s specifika styrkor glänser modellen i iterativa processer och textredigering. Här är några viktiga användningsområden:
- Marknadsföringsflöde: Skapa annonser för sociala medier eller produktbilder där specifika detaljer kan ändras (t.ex. ”Byt tröjan från röd till blå”)
- Pedagogisk infografik: Generera diagram till läroböcker, presentationer eller bloggar, som vårt exempel ”en stjärnas livscykel”
- Storyboard: Visualisera ett manus eller ett seriealbum där samma karaktär behöver dyka upp på olika platser
- Mode: Använd hybrida innehållsflöden för att visuellt utforska outfit‑kombinationer, som i den här handledningen för FLUX.2 garderobsvisualisering
- Inredningsdesign: Kombinera en grov skiss eller ett foto med uppmaningar för att inreda rum i en viss stil
- UI/UX‑mockups: Snabbt visualisera hur en webbplatsens landningssida eller förpackningen för en ny produkt skulle kunna se ut
Avslutande tankar
Sedan lanseringen av Nano Banana Pro har OpenAI stått under stor press att hänga med. Med den här lovande uppdateringen är de tillbaka i racet om den mest kapabla text‑till‑bild‑modellen. Den är inte felfri, men genom att fokusera på det väsentliga som skarp typografi och precisa redigeringar kan du få bra resultat. För att komma igång, testa funktionen i ditt ChatGPT‑gränssnitt eller i OpenAI Playground. För inspiration kan du kolla in galleriet och uppmaningsguiden.
Om du vill börja bygga verktyg med GPT‑modeller är vår OpenAI Fundamentals-väg något för dig.