Tak. GPT-Image-1.5 jest dostępny w OpenAI API i obejmuje te same ulepszenia co ChatGPT Images. Wejścia i wyjścia obrazów są około 20% tańsze niż w GPT Image 1, co dobrze sprawdza się w zastosowaniach takich jak marketing, ecommerce i przepływy pracy projektowe.
Czym jest ChatGPT Images?
Nowa karta Images w ChatGPT pełni funkcję kreatywnego centrum wszystkich treści wizualnych w interfejsie ChatGPT i zastępuje osobistą bibliotekę obrazów. Najistotniejszą zmianą jest integracja narzędzi do bezpośredniej edycji, które pozwalają modyfikować konkretne detale w obrazie, zachowując pozostałe elementy bez zmian.
ChatGPT Images działa w oparciu o GPT-Image-1.5, najnowszy i najbardziej zaawansowany model AI OpenAI do przetwarzania tekstu na obraz. Nawiązuje on do wydania modelu GPT-Image-1 z marca 2025 r., który odniósł duży sukces: w pierwszym tygodniu wygenerowano ponad 700 milionów obrazów.
Oferuje zachowanie detali i lepsze renderowanie tekstu, a według deklaracji jest „nawet do 4x” szybszy od poprzednika.
Nowe funkcje są udostępniane wszystkim użytkownikom, zarówno w planie bezpłatnym, jak i płatnym, w wersji webowej, mobilnej oraz w API. Dostęp dla kont Business i Enterprise pojawi się nieco później.
Kluczowe funkcje ChatGPT Images
Co więc oferuje ChatGPT Images w porównaniu z poprzednim modelem i konkurencją? OpenAI szczególnie promuje „precyzyjne edycje, które zachowują to, co ważne”. Przyjrzyjmy się nowym funkcjom, aby zrozumieć, co to oznacza.
Dedykowana przestrzeń kreatywna
Karta Images została wprowadzona jako centrum tworzenia treści wizualnych w interfejsie ChatGPT. Ideą jest oddzielenie tworzenia i edycji obrazów od zwykłych rozmów czatowych.
Poprzednia funkcja Biblioteka również przechowywała wszystkie wygenerowane obrazy, ale pozwalała jedynie wrócić do rozmowy, w której je utworzono. Do generowania nowego obrazu od zera wykorzystywała kontekst całej historii rozmowy, co często prowadziło do halucynacji w dłuższych wątkach.
Nowe podejście jest jednak bardziej skoncentrowane na obrazie: każda edycja bierze obraz jako punkt wyjścia i zmienia tylko wybrane jego aspekty, zamiast tworzyć zupełnie nową generację.
Obrazy są trwałymi artefaktami, a nie zaginione w historii rozmowy. To umożliwia szybsze pętle informacji zwrotnej z nowymi wariantami i zachęca do eksperymentowania, skutecznie zmieniając doświadczenie z wątku czatowego w pracę na „płótnie”.
Aby jeszcze bardziej wspierać ten przepływ twórczy, przestrzeń robocza wprowadza nowe narzędzia eksploracyjne, które pomagają połączyć pomysł z realizacją. Użytkownicy mogą stosować wbudowane presety stylów (takie jak „sketch” czy „dramatic”) lub przeglądać modne estetyki, by trafić na kolejne „Studio Ghibli”. Dla mniej doświadczonych twórców interfejs oferuje kreatywne podpowiedzi i proaktywną pomoc w formułowaniu promptów, by dopracować efekty.
Zachowanie detali i precyzyjna edycja
Jako chyba najważniejsza nowa funkcja, aktualizacja pozwala użytkownikom wybierać konkretne części obrazu i modyfikować je bezpośrednio, nie zmieniając reszty kompozycji. Model ma świadomość kontekstu, co oznacza, że rozumie, co należy edytować, jednocześnie zachowując spójność elementów otoczenia.
Tak precyzyjne edycje są możliwe dzięki poprawie umiejętności zachowania detali w nowym modelu.
Potrafi on utrzymać spójność obiektów, oświetlenia, kompozycji i wyglądu osób w kolejnych wynikach i edycjach. Ulepszone podążanie za instrukcjami dodatkowo zwiększa precyzję, pomagając lepiej zachować relacje między elementami.
Precyzyjna edycja doskonale nadaje się do poprawiania drobnych problemów i eksperymentowania ze szczegółami, gdy pełna generacja nie jest potrzebna. Umożliwia też kreatywne transformacje, np. przeniesienie elementu z jednego obrazu do sceny na innym.
Warto jednak wspomnieć, że model ma trudności z zachowaniem dokładnej tożsamości każdej osoby, gdy na jednym obrazie jest ich wiele.
Lepsze renderowanie tekstu i realizm
Jedną z głównych cech poprzedniego modelu GPT-Image-1 była zdolność do obsługi dłuższego tekstu i spójnych zdań. Nowe wydanie rozwija tę podstawę i potrafi teraz radzić sobie z gęstszym i mniejszym tekstem niż wcześniej.
Jest to szczególnie przydatne w infografikach, gdzie pierwsze wyniki robią spore wrażenie, i otwiera nowe możliwości, takie jak złożone składy tekstu w obrazie, np. w gazecie. Później przeprowadzimy test infografik.
Według komunikatu OpenAI ograniczenia dotyczące niektórych języków, takich jak chiński, arabski i hebrajski, wciąż jednak występują.
Choć nie był to główny cel aktualizacji, realizm wyników znacząco się poprawił w porównaniu z poprzednim modelem. Dobrze widać to na przykład w odbiciach, np. blikach na zdjęciu, oraz w wielu drobnych twarzach w dużych tłumach.
Jak to często bywa, duże ulepszenia pociągają pewne kompromisy w konkretnych obszarach. W tym przypadku pogorszyła się zdolność do generowania niektórych specyficznych stylów artystycznych. OpenAI zaleca używanie gotowych filtrów w karcie Images lub skorzystanie z poprzedniego modelu, który jest wciąż dostępny jako niestandardowy GPT.
Przyspieszona wydajność
Możliwości ukierunkowanej edycji są też głównym źródłem wzrostu szybkości generowania. Choć pełna generacja obrazów jest zauważalnie szybsza, nie osiąga wartości deklarowanych w notce wydawniczej OpenAI. GPT-Images-1.5 wydaje się „nawet do 4x szybszy” głównie dlatego, że podczas edycji regeneruje tylko to, co ulega zmianie.
Podobnie, około 20% niższy koszt w API wynika głównie z częściowej regeneracji obrazu podczas edycji, a dodatkowe korzyści to efekt wydajniejszego wnioskowania, a nie tańszych pełnych generacji.
Ogólnie nowe funkcje umożliwiają bardziej efektywne i przewidywalne użycie, szczególnie w przepływach pracy z API.
Przykłady ChatGPT Images
Zapowiedziane funkcje brzmią niewątpliwie ekscytująco. Przetestowałem je za pomocą kilku prostych promptów w połączeniu z nowym narzędziem zaznaczania.
Testowanie precyzji edycji
Celem pierwszego testu było sprawdzenie zdolności modelu do iteracyjnych zmian bez pogorszenia jakości. Najpierw poprosiłem o obraz brązowego niedźwiedzia idącego przez fiński las podczas białych nocy.

Prompt: „Brązowy niedźwiedź idący przez gęsty fiński las podczas białych nocy”.
Moim zdaniem jakość pierwszego wyniku jest bardzo wysoka. Niedźwiedź wygląda naturalnie, rodzaje drzew i krzewów dobrze oddają fińskie lasy (wiem, co mówię!), a niskie położenie słońca odpowiada temu, czego można się spodziewać w północnej Finlandii podczas białych nocy.
Dodatkowo oświetlenie i cienie na futrze niedźwiedzia oraz w tle wyglądają dość realistycznie. Nadal widać, że to AI, w pewien sposób, choć detale są dopracowane.
Spróbujmy zmienić niedźwiedzia brunatnego na polarnego i zobaczyć, co się stanie. Niedźwiedzi polarnych w Finlandii nie ma, ale jeśli wszystko zadziała, tło powinno pozostać niezmienione.

Prompt: „Zmień niedźwiedzia na polarnego”.
Jak widać, tło pozostało całkowicie nienaruszone, zgodnie z intencją.
W kolejnej edycji zaznaczyłem głowę i oczy niedźwiedzia polarnego i kazałem mu założyć parę vintage’owych okularów przeciwsłonecznych.

Prompt: „Załóż niedźwiedziowi parę vintage’owych okularów przeciwsłonecznych”. (zaznaczona głowa)
Wygląda na to, że wiemy już, co się dzieje, gdy zaznaczony obszar jest zbyt duży. Choć tło obrazu i ciało niedźwiedzia pozostały spójne, jego głowa zamieniła się w jedną wielką parę okularów. Spróbujmy ponownie, zaznaczając tylko oczy.

Prompt: „Załóż niedźwiedziowi parę vintage’owych okularów przeciwsłonecznych”. (zaznaczone oczy)
Bardzo dobrze, zdecydowanie dużo lepiej! W tym pierwszym teście widać, jak potężna jest funkcja zachowania detali: wystarczyło raz określić ważne szczegóły scenerii, a potem mogliśmy iterować nad głównym bohaterem bez martwienia się o tło. Innym ważnym wnioskiem jest to, że rozmiar okna zaznaczenia ma znaczenie.
Testowanie spójności transformacji
Następnie przetestowałem trwałość obiektu w różnych sceneriach oraz ograniczenia modelu w dużych tłumach. W tym celu kazałem naszemu niedźwiedziowi polarnemu trochę „pojechać” i przenieść go do zatłoczonej sceny w tokijskim metrze.

Prompt: „Umieść tego niedźwiedzia w bardzo zatłoczonej scenie w tokijskim metrze”.
Przede wszystkim imponuje spójność postaci: model idealnie zachował dokładną postawę i „tożsamość” niedźwiedzia oraz usunął bliki słoneczne z futra.
Jednak to sztywne zachowanie doprowadziło do wizualnego dysonansu znanego jako „efekt naklejki”. Ponieważ model nie zaktualizował kontekstu oświetlenia (zachował kierunkowy cień i leśne odbicia w okularach), niedźwiedź wygląda jak wycięty 2D element wklejony w scenę, a nie trójwymiarowy obiekt w niej osadzony.
Perspektywa dodatkowo psuje iluzję: niedźwiedź „unosi się” przed przechodniem, który jest fizycznie bliżej kamery.
Próby naprawienia tego drugiego problemu były dość frustrujące. Zaznaczyłem obszar przechodnia i jego skrzyżowanie z niedźwiedziem, prosząc ChatGPT o korektę perspektywy. Przy każdej wariacji model wstawiał nową osobę blisko kamery, tak jak tutaj:

Prompt: „Skoryguj perspektywę: plecy zaznaczonego przechodnia są na pierwszym planie i powinny częściowo zasłaniać niedźwiedzia. Niedźwiedź stoi za plecami tej osoby”.
Wygląda na to, że model nie potrafił zidentyfikować osoby, nawet po zaznaczeniu, i dlatego dodał nową postać, aby wykonać polecenie z promptu.
Naprawa cienia i odbić w okularach była bardziej udana. Użyłem następujących iteracji:
- Cień: Zaznacz podłogę wokół łap niedźwiedzia i wpisz prompt: „Zamiast obecnego cienia, rzuć miękki, rozproszony cień na płytki metra, zgodny z górnym oświetleniem świetlówkami”.
- Okulary: Zaznacz okulary i wpisz prompt: „Zaktualizuj odbicia w okularach przeciwsłonecznych tak, aby odpowiadały środowisku metra”.

Nasz niedźwiedź polarny w tokijskim metrze po naprawieniu cienia i odbić w okularach
Zdecydowanie lepiej, choć wciąż nie idealnie.
Ogólnie ten drugi test nie był tak udany jak pierwszy. O ile spójność elementów między różnymi obrazami działa dobrze, o tyle rozpoznawanie postaci zdaje się osiągać swoje granice w zatłoczonych scenach.
Testowanie renderowania tekstu
Na koniec chciałem sprawdzić nowe możliwości renderowania tekstu, zwłaszcza w przypadku gęstego tekstu i edycji. Usprawnienia w tym obszarze byłyby mile widziane, bo historycznie modele wizji lepiej radziły sobie z obiektami, fakturami i scenami niż z symbolami.
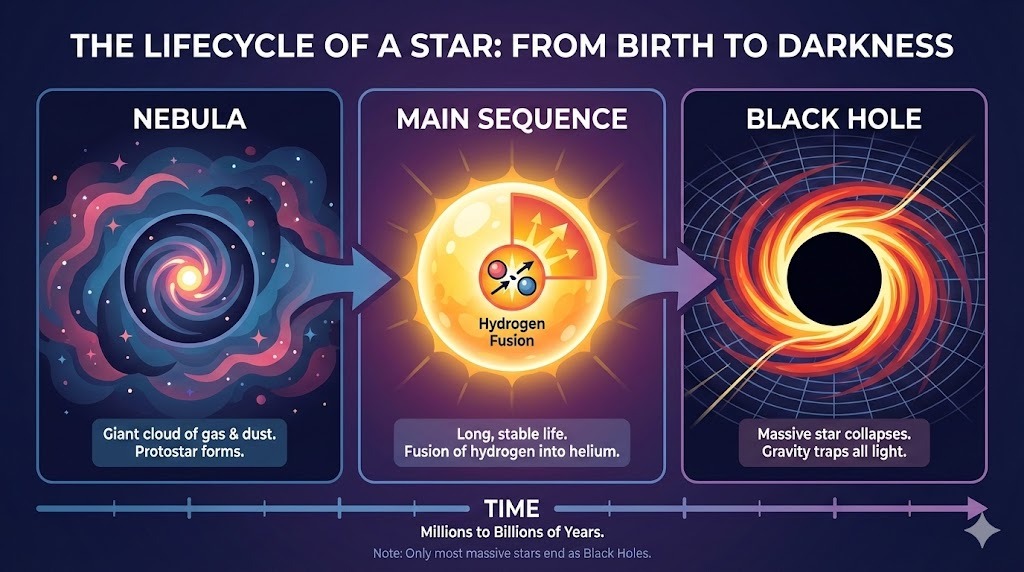
Poprosiłem ChatGPT o złożony układ infografiki o cyklu życia gwiazdy:
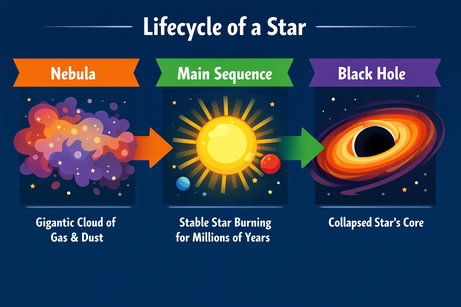
Prompt: "Pozioma infografika wyjaśniająca 'Cykl życia gwiazdy'. Trzy sekcje: Mgławica, Ciąg główny, Czarna dziura. Styl płaskich wektorów."
Wynik idealnie podąża za instrukcjami i renderuje tekst bez błędów. Styl jest trafny i spójny w całej infografice.
Wielomodowe wyjście ChatGPT wymusza precyzję przy wstawianiu tekstu. Gdy poprosiłem o dodanie wypunktowania „tutaj” (w zaznaczonym obszarze obrazu), model zwrócił punkt jako zwykły tekst. Dodanie doprecyzowania „do obrazu” rozwiązało problem:
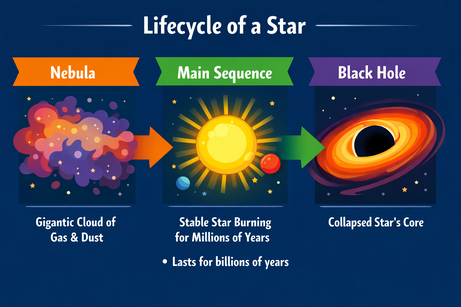
Prompt: „Dodaj w tym miejscu do obrazu punkt listy z napisem: 'Trwa miliardy lat'.”
Po doprecyzowaniu punkt został wstawiony we właściwe miejsce. Krój, rozmiar i kolor odpowiadają stylowi grafiki.
Jak uzyskać dostęp do ChatGPT Images?
ChatGPT Images jest już dostępny dla niemal wszystkich użytkowników na różnych platformach. Brakuje jeszcze wsparcia dla użytkowników w planach Business i Enterprise, które pojawi się później.
W interfejsie można korzystać z funkcji od razu w wersji webowej lub aplikacji mobilnej ChatGPT poprzez kartę Images. Choć dokładne liczby nie są znane, na kontach Free obowiązują ścisłe dzienne limity, a w planach Plus i Pro limity są wyższe i bardziej stabilne.
Dla deweloperów nowy model GPT-Image-1.5 jest dostępny zarówno w OpenAI API, jak i w Azure OpenAI Service — można go używać do generowania i edycji obrazów. Choć spodziewamy się szybkiej integracji modelu z głównymi pakietami kreatywnymi firm trzecich, już teraz można budować przepływy edycyjne bezpośrednio we własnych aplikacjach, korzystając z endpointów v1/images/generations i v1/images/edits.
W przeciwieństwie do poprzednika GPT-Image-1.5 rozlicza wyjścia obrazów jako osobno wyceniane tokeny, używając dedykowanych endpointów API do obrazów zamiast ujednoliconego /v1/responses. Płacą Państwo tylko za tokeny potrzebne do wygenerowania zmian, a nie za każdy nowy obraz w całości.
Dlatego właśnie nowy model ma być około 20% tańszy od poprzednika, choć ceny za token nie zmieniły się względem GPT-Image-1.
Jak dobry jest ChatGPT Images?
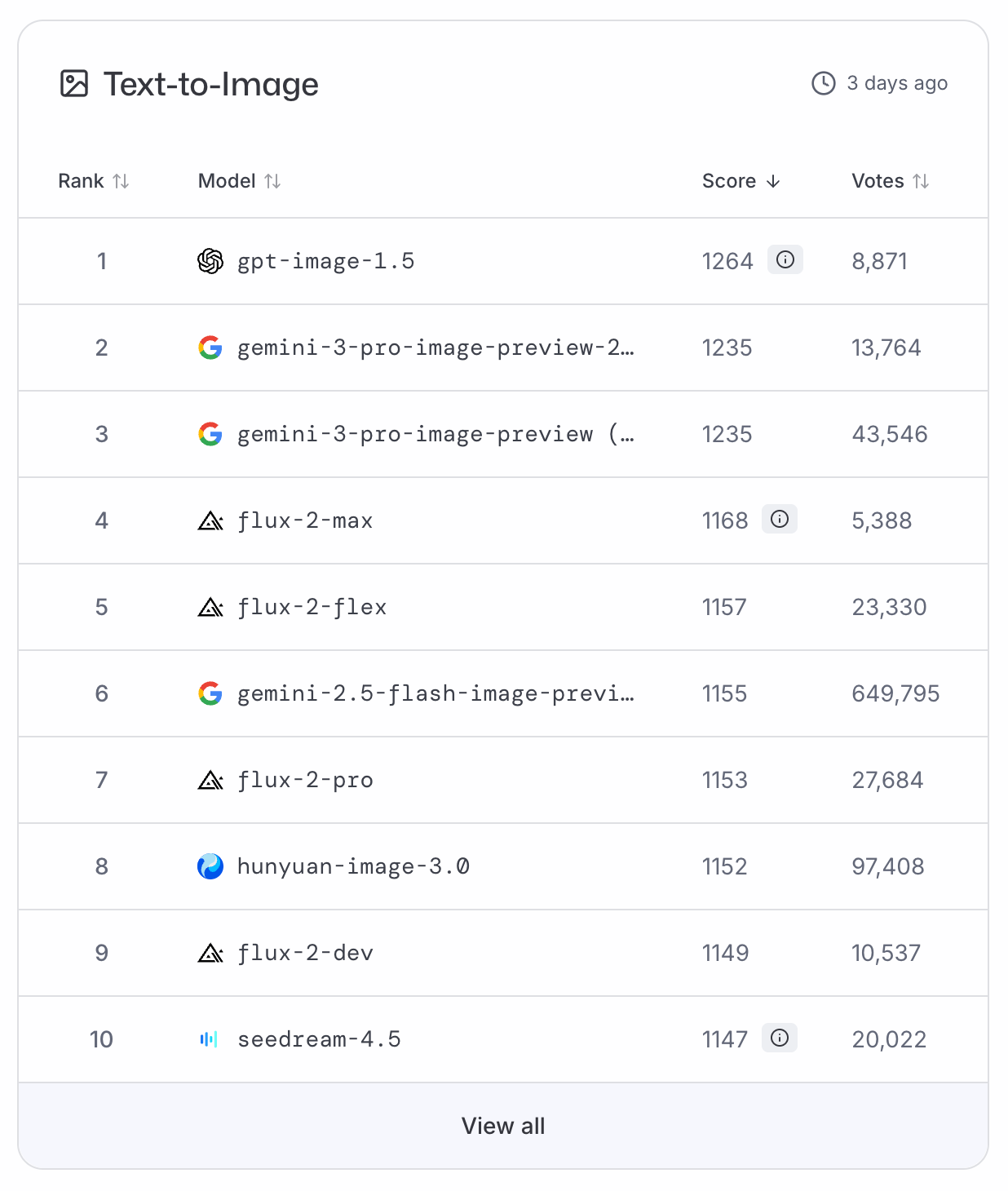
GPT-Image-1.5 od razu wspiął się na szczyt rankingów LMArena i ArtificialAnalysis dla modeli tekst–obraz, spychając Nano Banana Pro na drugie miejsce. Ponieważ obecnie brak danych benchmarkowych, musimy opierać się na tych rankingach opartych na głosowaniu jako obiektywnej klasyfikacji.
Parafrazując słynnego astronautę: GPT-Image-1.5 to mały krok dla branży, ale wielki skok dla OpenAI.
Choć precyzyjna edycja nie jest zupełną nowością, jej natywne wprowadzenie do ChatGPT stanowi największą zmianę tego wydania. Kluczowa jest jednak precyzja: proszę pamiętać o zaznaczaniu wyłącznie niezbędnych obszarów, aby uniknąć błędów w rodzaju „bezgłowego niedźwiedzia polarnego”, na który natknęliśmy się w testach.
Z mojego doświadczenia aktualizacja przynosi znaczący skok jakości, co odzwierciedlają również rankingi. Standardowe obrazy są bardziej „żywe”, a infografiki wyglądają znacznie mniej uproszczone niż wcześniej.
Użytkownicy mają teraz znacznie większą kontrolę nad każdym wynikiem, zastępując dawny proces tworzenia złożonych promptów uzupełniających i „liczenia na cud”. W dużej mierze dlatego, że zachowanie detali działa bardzo dobrze. W naszych testach elementy pozostawały całkowicie nienaruszone.
Spójność postaci jest silna, choć należy uważać na „efekt naklejki” i problemy z logiczną perspektywą. Choć ukierunkowane edycje ułatwiają ich poprawę, ograniczenia nadal występują w zatłoczonych scenach z wieloma ludźmi.
ChatGPT Images vs. Nano Banana Pro
Obecnie najpoważniejszym rywalem, którego musi pokonać ChatGPT Images, jest wyraźnie Nano Banana Pro od Google. Poniższa tabela porównuje oba modele:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Model edycji |
Precyzja: wybór obszaru i edycja in-place |
Rozumowanie: konwersacyjność i inteligentne maskowanie |
|
Przepływ pracy |
Dedykowana przestrzeń kreatywna |
Zintegrowane w czacie |
|
Iteracja |
Wydajna: częściowa regeneracja |
Eksploracyjna: remiksowanie |
|
Spójność |
Wysoka spójność układu i detali |
Wysoka spójność układu i detali |
|
Ekosystem |
OpenAI i Azure |
Google / stos Gemini |
Choć zarówno GPT-Image-1.5, jak i Nano Banana Pro oferują doskonałe rezultaty, oba modele różnią się filozofią edycji, przepływem pracy i ukierunkowaniem na klienta.
ChatGPT Images stawia na perfekcyjną izolację pikselową, co przekłada się na manualną kontrolę: można zaznaczyć dokładny obszar, a model traktuje go jak płótno do inpaintingu, podczas gdy reszta obrazu jest zablokowana. Nano Banana Pro z kolei próbuje zrozumieć intencję, by samodzielnie wprowadzić właściwe zmiany.
Również w zakresie workflow obie firmy wybrały inne ścieżki: karta Images w ChatGPT przypomina studio kreatywne, oddzielone od rozmów, natomiast Nano Banana Pro jest w pełni włączony w strumień czatu.
Aktualizacja: nowa wersja „nie-pro” modelu generowania obrazów Google, Nano Banana 2, wprowadziła istotne usprawnienia. Choć Nano Banana Pro wciąż ma niewielką przewagę, nowy model oferuje (prawie) tę samą jakość przy znacznie większej szybkości.
Kiedy używać ChatGPT Images, a kiedy Nano Banana Pro
Sugeruję wybrać ChatGPT Images, gdy trzeba poprawić układy, edytować tekst lub wprowadzać precyzyjne zmiany w istniejącym obrazie bez zmiany stylu. Wybierz Nano Banana Pro, jeśli trzeba tworzyć wizualizacje bogate w dane, remiksować wiele obrazów lub preferuje się inteligentnego asystenta, który odgaduje intencję, zamiast manualnej kontroli.
Korzystając z tych samych promptów co wyżej, odtworzyłem obrazy testowe. Osobiście bardziej spodobały mi się infografiki Nano Banana Pro, natomiast obrazy z niedźwiedziem były porównywalne.
Prompt: "Pozioma infografika wyjaśniająca 'Cykl życia gwiazdy'. Trzy sekcje: Mgławica, Ciąg główny, Czarna dziura. Styl płaskich wektorów." (Nano Banana Pro)
Zastosowania ChatGPT Images
Na podstawie naszych testów i specyficznych mocnych stron GPT-Image-1.5 model błyszczy w procesach iteracyjnych i edycji tekstu. Oto kilka najważniejszych zastosowań:
- Przepływ marketingowy: Tworzenie reklam w social media lub zdjęć produktowych, gdzie konkretne detale ulegają zmianie (np. „Zmień sweter z czerwonego na niebieski”)
- Infografiki edukacyjne: Generowanie diagramów do podręczników, prezentacji lub blogów, jak nasz przykład „cyklu życia gwiazdy”
- Storyboardy: Wizualizacja scenariusza lub komiksu, w którym ta sama postać musi się pojawić w różnych miejscach
- Moda: Wykorzystanie hybrydowego tworzenia treści do wizualnego eksplorowania zestawień strojów, jak w tym samouczku wizualizatora garderoby FLUX.2
- Aranżacja wnętrz: Łączenie szkicu lub zdjęcia z promptami, by przeprojektować pokoje w określonym stylu
- Makiety UI/UX: Szybka wizualizacja tego, jak mogłaby wyglądać strona docelowa czy opakowanie nowego produktu
Wnioski końcowe
Od premiery Nano Banana Pro OpenAI było pod sporą presją, by dotrzymać kroku. Dzięki tej obiecującej aktualizacji wracają do wyścigu o najbardziej zaawansowany model tekst–obraz. Nie jest bezbłędny, ale skupiając się na podstawach, jak ostra typografia i precyzyjna edycja, można uzyskać dobre rezultaty. Aby zacząć, proszę wypróbować funkcję w interfejsie ChatGPT lub w OpenAI Playground. Dla inspiracji warto zajrzeć do galerii i przewodnika po promptach.
Jeśli chcą Państwo zacząć budować narzędzia z użyciem modeli GPT, nasza ścieżka OpenAI Fundamentals jest dla Państwa.