Ja. GPT-Image-1.5 is beschikbaar in de OpenAI API en omvat dezelfde verbeteringen als ChatGPT Images. Beeldinputs en -outputs zijn ongeveer 20% goedkoper dan GPT Image 1, wat het zeer geschikt maakt voor toepassingen zoals marketing-, ecommerce- en designworkflows.
Wat is ChatGPT Images?
De nieuwe tab Afbeeldingen in ChatGPT dient als creatief knooppunt voor alles wat visueel is binnen de ChatGPT-interface en vervangt de persoonlijke afbeeldingsbibliotheek. De meest opvallende verandering is de integratie van directe bewerkingstools waarmee je specifieke details in een afbeelding kunt aanpassen terwijl alle andere details intact blijven.
ChatGPT Images wordt aangedreven door GPT-Image-1.5, OpenAI’s nieuwste en meest geavanceerde tekst-naar-beeld-AI-model. Het bouwt voort op de release van het GPT-Image-1-model in maart 2025, dat een groot succes was met meer dan 700 miljoen gegenereerde afbeeldingen in de eerste week.
Het biedt detailbehoud en verbeterde textrendering, en zou tot “4x” sneller zijn dan zijn voorganger.
De nieuwe functies zijn uitgerold voor alle gebruikers, zowel gratis als betaald, in de web-, mobiele UI en API. Alleen Business- en Enterprise-accounts moeten nog wachten op toegang.
Belangrijkste functies van ChatGPT Images
Wat biedt ChatGPT Images ten opzichte van het vorige model en de concurrentie? OpenAI benadrukt vooral “precise edits that preserve what matters.” Laten we de nieuwe functies bekijken om te zien wat dat betekent.
Toegewijde creatieve werkruimte
De tab Afbeeldingen is geïntroduceerd als een visueel creatiecentrum binnen de ChatGPT-UI. Het idee erachter is om het maken en bewerken van afbeeldingen te scheiden van normale chatinteracties.
Hoewel de vorige Bibliotheekfunctie ook alle gegenereerde afbeeldingen opsloeg, bood die alleen de mogelijkheid je terug te brengen naar het gesprek waarin ze waren gemaakt. Daarbij werd context uit de hele gespreksgeschiedenis gebruikt om een nieuwe afbeelding vanaf nul te genereren, wat in langere threads vaak leidde tot hallucinaties.
De nieuwe aanpak is echter meer beeldgericht: elke bewerking neemt een afbeelding als uitgangspunt en verandert alleen geselecteerde aspecten ervan, in plaats van een volledig nieuwe generatie te maken.
Afbeeldingen zijn blijvende artefacten, niet weggestopt in een gespreksgeschiedenis. Dit maakt snellere feedbackloops met nieuwe variaties mogelijk en stimuleert experimenteren, waardoor de ervaring effectief verandert van een chatthread naar die van een canvas.
Om deze creatieve flow verder te ondersteunen, introduceert de werkruimte nieuwe verkenningstools die de kloof tussen idee en uitvoering overbruggen. Gebruikers kunnen ingebouwde stijlpresets toepassen (zoals “schets” of “dramatisch”) of door trending esthetieken bladeren om de volgende “Studio Ghibli” te spotten. Voor onervaren makers biedt de UI creatieve suggesties en proactieve promptondersteuning om resultaten te verfijnen.
Detailbehoud en precieze bewerking
Als wellicht belangrijkste nieuwe functie stelt de update gebruikers in staat specifieke delen van een afbeelding te selecteren en die direct te wijzigen, zonder de rest van de compositie te veranderen. Het model is contextbewust, wat betekent dat het begrijpt wat er moet worden bewerkt terwijl de omliggende elementen consistent blijven.
Dit soort scherpe bewerkingen zijn mogelijk dankzij de verbeterde vaardigheden voor detailbehoud van het nieuwe model.
Het kan objecten, belichting, compositie en het uiterlijk van mensen consistent houden in outputs en daaropvolgende bewerkingen. Ook draagt verbeterde opvolging van instructies bij aan de toegenomen precisie door relaties tussen elementen beter te behouden.
Precieze bewerking is perfect om kleine problemen te corrigeren en te experimenteren met specifieke details wanneer een volledige generatie niet nodig is. Het maakt ook creatieve transformaties mogelijk, zoals het meenemen van een element uit de ene afbeelding naar de scène van een andere.
Het is echter vermeldenswaard dat het model moeite heeft om de exacte identiteit van elke persoon te behouden wanneer er veel mensen op één afbeelding staan.
Verbeterde textrendering en realisme
Een van de grote features van het voorgangermodel GPT-Image-1 was het vermogen om langere tekst en samenhangende zinnen aan te kunnen. De nieuwe release bouwt daarop voort en kan nu dichtere en kleinere tekst aan dan voorheen.
Dit is vooral handig voor infographics, waar de eerste resultaten behoorlijk indrukwekkend zijn, en opent nieuwe mogelijkheden zoals opmaak van tekst in een afbeelding, bijvoorbeeld in een krant. We doen later een test met infographics.
Volgens de aankondiging van OpenAI lijken de beperkingen met betrekking tot sommige specifieke talen, zoals Chinees, Arabisch en Hebreeuws, echter nog steeds te bestaan.
Hoewel het niet de hoofdfocus van de update was, is het realisme van de output aanzienlijk verbeterd ten opzichte van het vorige model. Twee gevallen waarin dat goed te zien is, zijn reflecties, bijvoorbeeld de schittering op een foto, en veel kleine gezichten in grote mensenmassa’s.
Zoals zo vaak gaan grote upgrades gepaard met enkele trade-offs in specifieke gebieden. In dit geval is het vermogen om bepaalde kunststijlen te genereren achteruitgegaan. OpenAI raadt aan om presetfilters in de tab Afbeeldingen te gebruiken of terug te grijpen op het vorige model, dat nog steeds beschikbaar is als een custom GPT.
Versnelde prestaties
De gerichte bewerkingsmogelijkheden zijn ook de belangrijkste bron van de toegenomen generatiesnelheid. Hoewel volledige afbeeldingsgeneratie merkbaar sneller is, wordt de claim in de release note van OpenAI niet gehaald. GPT-Images-1.5 lijkt “tot 4x sneller” vooral omdat het tijdens bewerkingen alleen regenereert wat verandert.
Evenzo komt de ongeveer 20% lagere API-kost voornamelijk door gedeeltelijke regeneratie tijdens bewerkingen, met extra winst door efficiëntere inferentie in plaats van goedkopere volledige generaties.
Al met al maken de nieuwe functies een efficiënter en betrouwbaarder gebruik mogelijk, vooral voor API-workflows.
Voorbeelden van ChatGPT Images
De aangekondigde functies klinken zeker veelbelovend. Ik heb ze getest met een paar simpele prompts in combinatie met de nieuwe selectietool.
Precisie van bewerkingen testen
Het doel van mijn eerste test was om het vermogen van het model te beoordelen om iteratieve wijzigingen af te handelen zonder kwaliteitsverlies. Eerst vroeg ik om een afbeelding van een bruine beer die door een Fins bos loopt tijdens de middernachtzon.

Prompt: “A brown bear walking through a dense Finnish forest during the midnight sun.”
Naar mijn mening is de kwaliteit van de eerste output erg hoog. De beer oogt natuurlijk, het type bomen en struiken representeert Finse bossen heel goed (ik kan het weten!), en de lage stand van de zon komt overeen met wat je kunt verwachten in Noord-Finland tijdens de middernachtzon.
Daarnaast zien de belichting en schaduwen op de vacht van de beer, evenals op de achtergrond, er behoorlijk realistisch uit. Je ziet nog steeds dat het AI is, op de een of andere manier, hoewel de details mooi zijn.
Laten we proberen de beer te veranderen in een ijsbeer en zien wat er gebeurt. Er zijn geen ijsberen in Finland, maar als alles werkt zoals het hoort, zou de achtergrond hetzelfde moeten blijven.

Prompt: “Change the bear to a polar bear.”
Zoals we zien, is de achtergrond volledig intact gebleven, precies zoals bedoeld.
Voor mijn volgende bewerking selecteerde ik het hoofd en de ogen van de ijsbeer en gaf ik hem een vintage zonnebril.

Prompt: “Put a pair of vintage sunglasses on the bear.” (head selected)
Blijkbaar hebben we ontdekt wat er gebeurt als je een te groot gebied selecteert. Hoewel de achtergrond en het lichaam van de beer consistent blijven, veranderde zijn hoofd in één grote zonnebril. Laten we het opnieuw proberen, met alleen zijn ogen geselecteerd.

Prompt: “Put a pair of vintage sunglasses on the bear.” (eyes selected)
Heel gaaf, en zeker veel beter! In deze eerste test zagen we hoe krachtig de functie voor detailbehoud daadwerkelijk is: we hoefden belangrijke details over de omgeving maar één keer te benoemen en konden vervolgens itereren op ons hoofdpersonage zonder ons zorgen te maken over de achtergrond. Een andere belangrijke les is dat de grootte van het selectievenster uitmaakt.
Consistentie bij transformaties testen
Vervolgens testte ik objectpermanentie met betrekking tot verschillende scènes en de beperkingen van het model bij grote menigten. Hiervoor liet ik onze ijsbeer een beetje reizen en probeerde ik hem te verplaatsen naar een drukke metroscène in Tokio.

Prompt: “Place this bear into a very busy subway scene in Tokyo.”
Allereerst is de karakterconsistentie indrukwekkend: het model heeft de exacte houding en identiteit van de beer perfect behouden en de zonneschittering uit zijn vacht verwijderd.
Deze rigide behoudenis veroorzaakte echter een visuele breuk, bekend als het “stickereffect”. Omdat het model de belichtingscontext niet bijwerkte (met behoud van de gerichte schaduw en bosreflecties in de zonnebril), oogt de beer als een 2D-uitsnede die op de scène is geplakt in plaats van een 3D-object dat erin staat.
Het perspectief versterkt de illusiebreuk: de beer zweeft vóór een omstander die fysiek dichter bij de camera staat.
Het proberen te corrigeren van dat laatste punt was behoorlijk frustrerend. Ik selecteerde het gebied van de omstander en zijn kruising met de beer en vroeg ChatGPT het perspectief te corrigeren. Bij elke variant voegde het model een nieuw persoon dicht bij de camera in, zoals dit:

Prompt: “Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back.”
Het lijkt erop dat het model de persoon niet kon identificeren, zelfs niet wanneer geselecteerd, en daarom een nieuw personage nodig had om de opdracht in de prompt op te volgen.
Het corrigeren van de schaduw en de reflecties in de zonnebril was succesvoller. Ik gebruikte de volgende iteraties:
- Schaduw: Selecteer de vloer rond de poten van de beer en prompt “Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting.”
- Zonnebril: Selecteer de zonnebril en prompt “Update the reflections of the sunglasses to match the subway environment.”

Onze ijsbeer in de metro van Tokio na het corrigeren van de schaduw en de reflecties in de zonnebril
Al veel beter, al is het niet perfect.
Over het algemeen was de tweede test minder succesvol dan de eerste. Hoewel elementconsistentie over verschillende beelden goed lijkt te werken, lijkt herkenning van personages zijn grenzen te bereiken in drukke omgevingen.
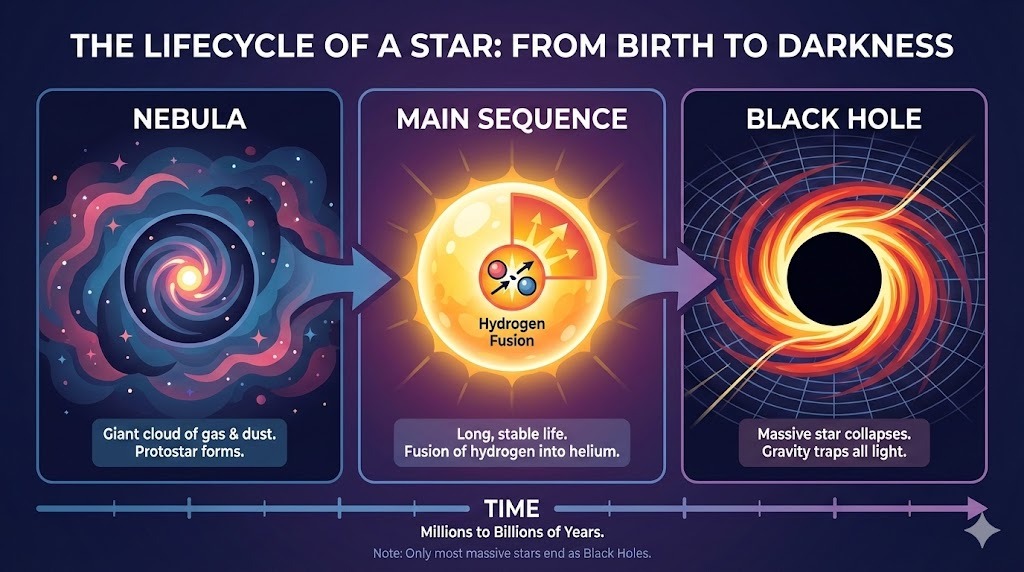
Textrendering testen
Tot slot wilde ik de nieuwe textrendering testen, vooral bij dichte tekst en bewerkingen. Verbeteringen in textrendering zijn welkom, omdat visiemodellen historisch gezien beter waren in objecten, texturen en scènes dan in symbolen.
Ik vroeg ChatGPT om een complexe lay-out voor een infographic over de levenscyclus van een ster:
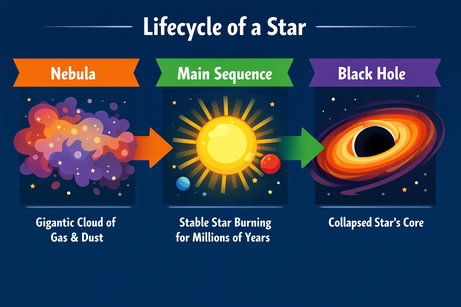
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
De output volgt de instructies perfect en rendert de tekst zonder fouten. De stijl is accuraat en consistent door de hele infographic.
De multimodaliteit van ChatGPT dwingt ons nauwkeurig te zijn bij het invoegen van tekst. Bij de prompt om een opsommingsteken “hier” toe te voegen (op een geselecteerd gebied in de afbeelding), gaf het alleen het opsommingsteken als tekstoutput. De toevoeging “aan de afbeelding” deed het ‘m:
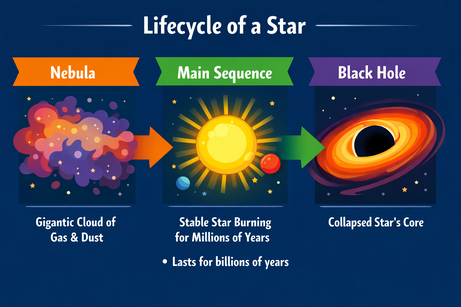
Prompt: “Add a bullet point to the image here that says: 'Lasts for billions of years'.”
Na de verduidelijking werd het opsommingsteken op de juiste plek ingevoegd. Lettertype, grootte en kleur passen bij de stijl van de graphic.
Hoe krijg ik toegang tot ChatGPT Images?
ChatGPT Images is nu beschikbaar voor bijna alle gebruikers op meerdere platformen. Alleen ondersteuning voor gebruikers in de Business- en Enterprise-tiers ontbreekt nog en volgt later.
In de UI kun je de functies meteen gebruiken in de web- of mobiele app van ChatGPT via de tab Afbeeldingen. Hoewel de exacte aantallen niet bekend zijn, gelden strikte daglimieten voor Gratis-accounts en geleidelijk hogere, stabielere limieten voor Plus- en Pro-abonnementen.
Voor ontwikkelaars is het nieuwe GPT-Image-1.5-model beschikbaar via zowel de OpenAI API als Azure OpenAI Service, waar het kan worden gebruikt voor het genereren en bewerken van afbeeldingen. Hoewel we verwachten dat het model binnenkort wordt geïntegreerd in grote creatieve suites van derden, kunnen ontwikkelaars nu al bewerkingsworkflows rechtstreeks in hun eigen applicaties bouwen met de endpoints v1/images/generations en v1/images/edits.
In tegenstelling tot zijn voorganger rekent GPT-Image-1.5 beeldoutput af als apart geprijsde tokens, via beeldspecifieke API-endpoints in plaats van de uniforme /v1/responses. Je betaalt alleen voor de tokens die nodig zijn om de wijzigingen te genereren, in plaats van elke keer voor een volledig nieuwe afbeelding.
Daarom zou het nieuwe model ongeveer 20% goedkoper zijn dan zijn voorganger, hoewel prijzen per token niet zijn veranderd ten opzichte van GPT-Image-1.
Hoe goed is ChatGPT Images?
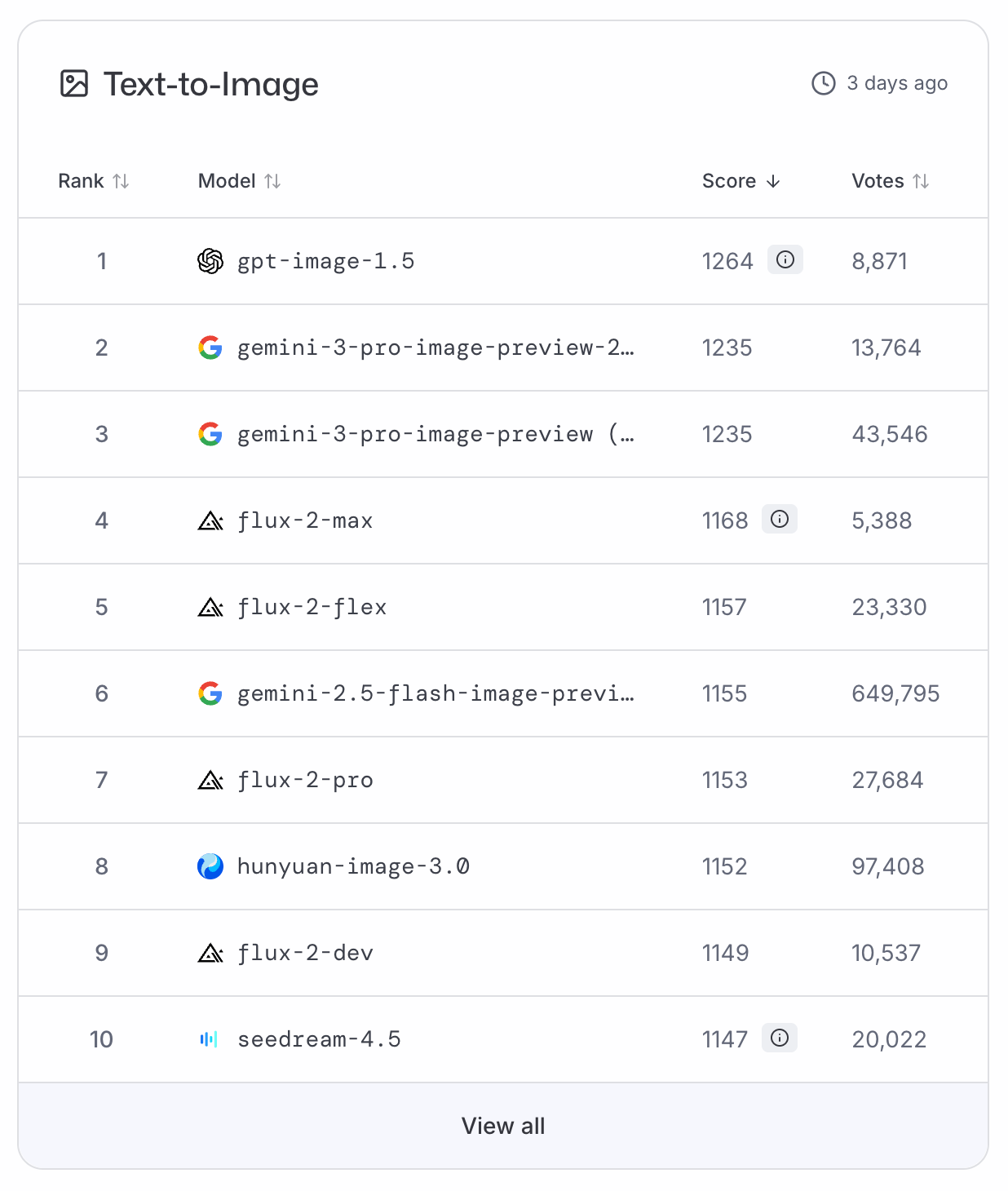
GPT-Image-1.5 klom meteen naar de top van de LMArena- en ArtificialAnalysis-ranglijsten voor tekst-naar-beeld, waarmee Nano Banana Pro naar de tweede plaats werd verwezen. Omdat er momenteel geen benchmarkdata beschikbaar is, moeten we voor een objectieve classificatie vertrouwen op deze op stemmen gebaseerde ranglijsten.
Om een beroemde astronaut te parafraseren: GPT-Image-1.5 is een kleine stap voor de industrie, maar een reuzensprong voor OpenAI.
Hoewel precieze bewerking niet helemaal nieuw is, is de native integratie in ChatGPT de grootste verschuiving in deze release. Maar precisie is cruciaal: onthoud dat je alleen de noodzakelijke gebieden selecteert om glitches zoals de ‘hoofdzeloze ijsbeer’ uit de test te voorkomen.
Uit mijn ervaring levert de update een duidelijke kwaliteitsstap op, wat ook terug te zien is in de ranglijsten. Standaardafbeeldingen voelen levendiger, en infographics ogen veel minder simplistisch dan voorheen.
Gebruikers hebben nu aanzienlijk meer controle over elke output, in plaats van de oude workflow met complexe vervolgprompts en hopen op het beste. Dit komt grotendeels doordat detailbehoud heel goed werkt. In onze tests bleven elementen volledig intact.
Karakterconsistentie is sterk, al moet je letten op het ‘stickereffect’ en logische perspectiefproblemen. Hoewel gerichte bewerkingen het makkelijker maken om dit te corrigeren, blijven er beperkingen bestaan in drukke scènes met veel mensen.
ChatGPT Images vs. Nano Banana Pro
De huidige te kloppen favoriet voor ChatGPT Images is duidelijk Google’s Nano Banana Pro. De volgende tabel vergelijkt beide modellen:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Bewerkingsmodel |
Precisie: Gebiedsselectie & bewerking ter plekke |
Redeneren: Conversational & slimme masking |
|
Workflow |
Toegewijde creatieve werkruimte |
Geïntegreerde chatfunctie |
|
Iteratie |
Efficiënt: Gedeeltelijke regeneratie |
Verkennend: Remixen |
|
Consistentie |
Hoog behoud van lay-out & details |
Hoog behoud van lay-out & details |
|
Ecosysteem |
OpenAI & Azure |
Google / Gemini Stack |
Hoewel zowel GPT-Image-1.5 als Nano Banana Pro uitstekende resultaten bieden, verschillen beide modellen in hun bewerkingsfilosofie, workflows en klantfocus.
ChatGPT Images richt zich op pixel-perfecte isolatie, wat sterk is in handmatige controle: je kunt een exact gebied selecteren, en het behandelt die selectie als canvas voor inpainting terwijl de rest van de afbeelding vergrendeld blijft. Nano Banana Pro probeert daarentegen te begrijpen wat je wilt doen om de juiste wijzigingen door te voeren.
Wat de workflow betreft kozen beide bedrijven ook voor verschillende paden: de tab Afbeeldingen in ChatGPT voelt als een creatieve studio, los van gesprekken, terwijl Nano Banana Pro volledig is geïntegreerd in de chatstroom.
Update: Google’s nieuwe versie van het non-pro afbeeldingsgeneratiemodel, Nano Banana 2, heeft aanzienlijke verbeteringen doorgevoerd. Hoewel Nano Banana Pro nog een kleine voorsprong heeft, biedt het nieuwe model (bijna) dezelfde kwaliteit met een veel hogere snelheid.
Wanneer gebruik je ChatGPT Images vs. Nano Banana Pro
Ik zou ChatGPT Images gebruiken als je lay-outs moet corrigeren, tekst wilt bewerken of precieze wijzigingen aan een bestaande afbeelding wilt doorvoeren zonder de stijl te veranderen. Kies Nano Banana Pro als je data-intensieve visuals moet genereren, meerdere beelden wilt remixen of liever een slimme assistent je intentie laat raden in plaats van handmatige controle.
Met dezelfde prompts als hierboven heb ik de testafbeeldingen opnieuw gemaakt. Persoonlijk vond ik de infographics van Nano Banana Pro mooier, terwijl de berenafbeeldingen gelijkwaardig waren.
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
Gebruiksscenario’s voor ChatGPT Images
Op basis van onze hands-on tests en de specifieke sterke punten van GPT-Image-1.5 blinkt het model uit bij iteratieve processen en tekstbewerking. Enkele topgebruiksscenario’s:
- Marketingworkflow: Het maken van socialmedia-advertenties of productshots waarbij specifieke details kunnen veranderen (bijv. “Verander de trui van rood naar blauw”)
- Educatieve infographics: Diagrammen genereren voor leerboeken, presentaties of blogs, zoals ons voorbeeld “levenscyclus van een ster”
- Storyboarding: Een script of strip visualiseren waarbij hetzelfde personage op verschillende locaties moet verschijnen
- Mode: Hybride contentcreatie gebruiken om outfitcombinaties visueel te verkennen, zoals in deze FLUX.2-tutorial voor garderobevisualisatie
- Interieurontwerp: Een ruwe schets of foto combineren met prompts om kamers in een bepaalde stijl opnieuw in te richten
- UI/UX-mock-ups: Snel visualiseren hoe een website-landingpage of verpakking voor een nieuw product eruit zou kunnen zien
Tot slot
Sinds de release van Nano Banana Pro staat OpenAI onder grote druk om bij te blijven. Met deze veelbelovende update zijn ze terug in de race voor het meest capabele tekst-naar-beeld-AI-model. Het is niet foutloos, maar door te focussen op essentials zoals scherpe typografie en precieze bewerking kun je goede resultaten behalen. Om te beginnen kun je de functie uitproberen in je ChatGPT-UI of in de OpenAI Playground. Ter inspiratie kun je de galerij en de promptgids bekijken.
Als je tools wilt gaan bouwen met GPT-modellen, is onze OpenAI Fundamentals skill track iets voor jou.
Welke soorten afbeeldingsbewerkingen kan ChatGPT Images aan?
Waarin is GPT-Image-1.5 beter dan het vorige beeldmodel?
Is ChatGPT Images voor iedereen beschikbaar?
Kunnen ontwikkelaars het nieuwe beeldmodel via de API gebruiken?


Author
Josef Waples
