是的。GPT-Image-1.5 可通过 OpenAI API 使用,并包含与 ChatGPT Images 相同的改进。图像输入与输出的成本较 GPT Image 1 约降低 20%,非常适合营销、电商与设计类工作流等应用。
什么是 ChatGPT Images?
ChatGPT 新增的 Images 标签页是 ChatGPT 界面中所有视觉创作的中心,并取代了个人图像库。最显著的变化是集成了直接编辑工具,用户可以针对图像中的特定细节进行修改,同时保持其他细节不变。
ChatGPT Images 由 OpenAI 最新、最先进的文本转图像 AI 模型 GPT-Image-1.5 提供支持。它建立在GPT-Image-1 模型(2025 年 3 月发布)的基础上,后者在发布首周就生成了超过 7 亿张图像。
它提供更好的细节保真与文本渲染,据称速度较前代“最高可提升 4 倍”。
新功能已在网页、移动端界面与 API 面向所有用户(免费与付费)推出。仅商业版与企业版账户尚需等待开通。
ChatGPT Images 的关键功能
那么,相较于前代与竞品,ChatGPT Images 有何亮点?OpenAI 尤其强调“在保留关键要素的同时进行精确编辑”。我们来看看这些新功能意味着什么。
专用创作空间
Images 标签页作为 ChatGPT 界面内的视觉创作中心亮相。其理念是在常规对话之外,独立出图像创作与编辑流程。
此前的“库”功能同样存储所有已生成图像,但只能带您回到其生成时的对话。它会利用整段对话历史的上下文从零生成新图像,在线程较长时常导致幻觉。
而新方法更以图像为中心:每次编辑都以一张图像为起点,仅更改选定部分,而非完全重新生成。
图像作为持久化的创作成果,不再埋没于对话历史中。这带来更快的反馈循环与新变体尝试,鼓励实验探索,体验也从“对话串”转变为“画布”。
为进一步促进创作流程,工作区引入了新探索工具,缩短从灵感到落地的距离。用户可应用内置风格预设(如“素描”“戏剧化”),或浏览流行美学以追赶下一个“吉卜力工作室”。对于经验不足的创作者,界面提供创意建议与主动提示支持,帮助打磨结果。
细节保真与精确编辑
或许是最重要的新特性:更新后,用户可以选择图像中的特定区域直接进行修改,而不改变其余构图。模型具备上下文感知能力,能理解应编辑之处,同时保持周围元素一致。
这类干净利落的编辑得益于新模型在细节保真方面的提升。
它能够在多次输出与后续编辑中,保持物体、光线、构图以及人物外观的一致性。同时,指令跟随能力的提升有助于更好地保留元素之间的关系,从而提高精度。
当无需整体重生图像时,精确编辑非常适合修复小问题或针对细节进行试验。它也支持创意转换,例如将一张图像中的元素带入另一张图像的场景中。
不过值得一提的是,当一张图像中包含很多人时,模型难以完全保持每个人的精确身份特征。
更佳的文本渲染与真实感
前代模型 GPT-Image-1 的一大特性是能处理较长文本并生成连贯句子。新版本在此基础上进一步改进,如今能处理更密集、更小号的文本。
这对信息图尤其有用,首批结果颇为亮眼,也带来新可能,比如在图像中渲染报纸等 markdown 风格文本。我们稍后将对信息图进行测试。
不过,根据 OpenAI 的发布说明,某些特定语言(如中文、阿拉伯语、希伯来语)方面的限制似乎仍然存在。
尽管这并非本次更新的重点,相较前代,输出的真实感也显著提升。两个体现较为明显的场景是反射(如照片高光)以及在大人群中呈现的众多小人脸。
与往常一样,大幅升级也会在某些方面有所取舍。本次在生成某些特定艺术风格上的能力有所回落。OpenAI 建议在 Images 标签页使用预设滤镜,或改用上一代模型(可作为自定义 GPT 继续使用)。
性能加速
生成速度的大幅提升主要也来自定向编辑能力。尽管整图生成明显更快,但并未完全达到 OpenAI 发布说明中的宣称。GPT-Image-1.5 看起来“最高快 4 倍”,主要是因为在编辑时仅重新生成变化的部分。
同样地,API 成本大约降低 20% 也主要得益于编辑期间的部分重生成,再加上推理更高效,而非整图生成更便宜。
总体而言,新功能让使用更高效、更可靠,尤其适用于 API 工作流。
ChatGPT Images 示例
这些发布的功能确实令人期待。我用几个简单提示词配合新选择工具进行了测试。
测试编辑精度
我的首个测试目标是评估模型在不降低质量的情况下处理迭代更改的能力。首先,我要求其创建一张在午夜阳光下穿行芬兰森林的棕熊图像。

提示词:“一只棕熊在午夜阳光下穿过茂密的芬兰森林。”
在我看来,第一次输出的质量非常高。熊看起来很自然,树木与灌木的类型很好地呈现了芬兰森林(我很清楚!),而太阳的低位也符合芬兰北部午夜阳光时的景象。
此外,无论是熊毛上的光影,还是背景中的明暗,都相当真实。虽然仍能隐约看出是 AI,但细节表现很不错。
我们试着把棕熊变成北极熊看看会怎样。芬兰并没有北极熊,但如果一切运作正常,背景应保持不变。

提示词:“把这只熊换成北极熊。”
如我们所见,背景完全保持不变,正如预期。
接下来,我选择了北极熊的头部和眼睛,给它戴上一副复古太阳镜。

提示词:“给熊戴上一副复古太阳镜。”(选择头部)
看来当选择区域过大时会发生什么:虽然图像背景和熊的身体保持一致,但它的头变成了一大副太阳镜。再试一次,只选择眼睛。

提示词:“给熊戴上一副复古太阳镜。”(选择眼睛)
很酷,也确实好得多!通过这第一组测试,我们看到了细节保真功能的强大:关于场景的重要细节只需说明一次,就可以围绕主角反复迭代,而无需担心背景。另一个要点是,选择框的大小很重要。
测试变换一致性
接着,我测试了对象在不同场景中的持久性,以及模型在大型人群中的局限。为此,我让我们的北极熊“旅行”一下,尝试把它放进东京拥挤的地铁场景中。

提示词:“把这只熊放到一个非常拥挤的东京地铁场景中。”
首先,角色一致性令人印象深刻:模型完美保留了熊的姿态与身份特征,并去除了毛发上的阳光反射。
然而,这种过于僵硬的保留导致了视觉上的“贴纸效应”。由于模型没有更新光照环境(保留了定向阴影和太阳镜上的森林反射),熊看起来更像被贴到场景上的 2D 剪影,而非真实 3D 物体。
透视也进一步破坏了真实感:熊漂浮在一位更靠近镜头的路人前面。
尝试修复后者的过程颇为挫败。我选中了那位路人与熊相交的区域,要求 ChatGPT 纠正透视。每个变体中,模型都会在镜头前插入一个新人物,就像这样:

提示词:“纠正透视:所选路人的背部位于前景,应部分遮挡熊。熊站在该人的背后。”
看起来模型即便在选中情况下也无法识别该人物,因此通过在画面前景插入新人物来满足提示中的指令。
修复阴影和太阳镜反射则更为顺利。我进行了以下迭代:
- 阴影:选择熊脚边地面并提示:“将当前阴影改为柔和、漫射的阴影,与地铁顶部荧光灯照明一致,投射在地砖上。”
- 太阳镜:选择太阳镜并提示:“将太阳镜的反射更新为与地铁环境相匹配。”

修复阴影与太阳镜反射后的北极熊,身处东京地铁
已经好很多,但仍不完美。
总体而言,第二组测试不如第一组成功。虽然跨图像的元素一致性表现良好,但在拥挤环境中的角色识别似乎达到了上限。
测试文本渲染
最后,我想测试新的文本渲染能力,尤其是在密集文本与编辑场景下。如果文本渲染有所改进将非常可喜,因为从历史来看,视觉模型更擅长物体、材质与场景,而非符号。
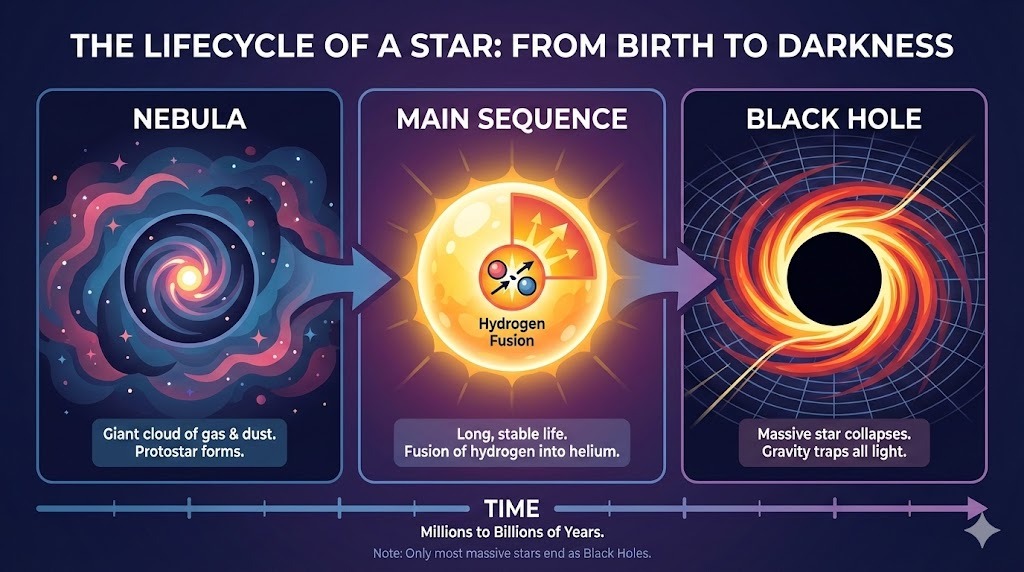
我让 ChatGPT 设计一个关于恒星生命周期的信息图的复杂版式:
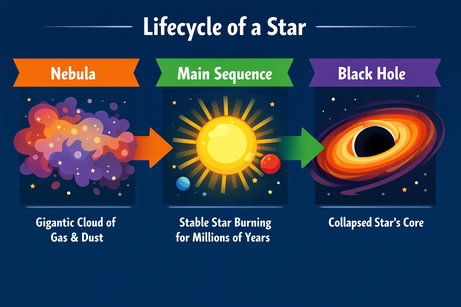
提示词:“一张横向信息图,解释‘恒星的生命周期’。三部分:星云、主序星、黑洞。使用扁平矢量风格。”
输出严格遵循指令,文本无误渲染,风格在整张信息图中准确且一致。
由于 ChatGPT 的输出具备多模态,在插入文本时需要更精确。当我提示在“这里”添加一个项目符号(选中了图像中的区域)时,它只以文本输出了该项目符号。补充说明“添加到图像中”后问题得到解决:
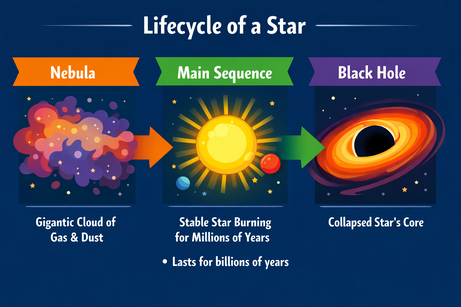
提示词:“在图像这里添加一个项目符号,写着:‘可持续数十亿年’。”
在澄清之后,项目符号被插入到正确位置。字体、大小与颜色均与图形风格一致。
如何访问 ChatGPT Images?
ChatGPT Images 现已在多个平台面向几乎所有用户开放。仅商业版与企业版用户的支持尚未上线,将于稍后推出。
在界面中,您可以立即通过 ChatGPT 的网页端或移动端应用的 Images 标签页使用这些功能。尽管具体数值未知,但免费账户有严格的日配额限制,而 Plus 与 Pro 套餐则提供逐步提升且更稳定的额度。
对开发者而言,新模型 GPT-Image-1.5 可通过 OpenAI API 与 Azure OpenAI Service 使用,支持图像生成与编辑。我们预计该模型很快会集成进主流第三方创意套件,开发者也可已通过 v1/images/generations 与 v1/images/edits 端点,将编辑工作流直接构建到自家应用中。
与前代不同,GPT-Image-1.5 将图像输出作为单独计价的 tokens,通过图像专用的 API 端点提供,而非统一的 /v1/responses。您只需为生成变更所需的 tokens 付费,而不是每次都为整张新图像买单。
这也是为什么新模型据称比前代便宜约 20%,尽管每 token 价格相较 GPT-Image-1 并未变化。
ChatGPT Images 有多强?
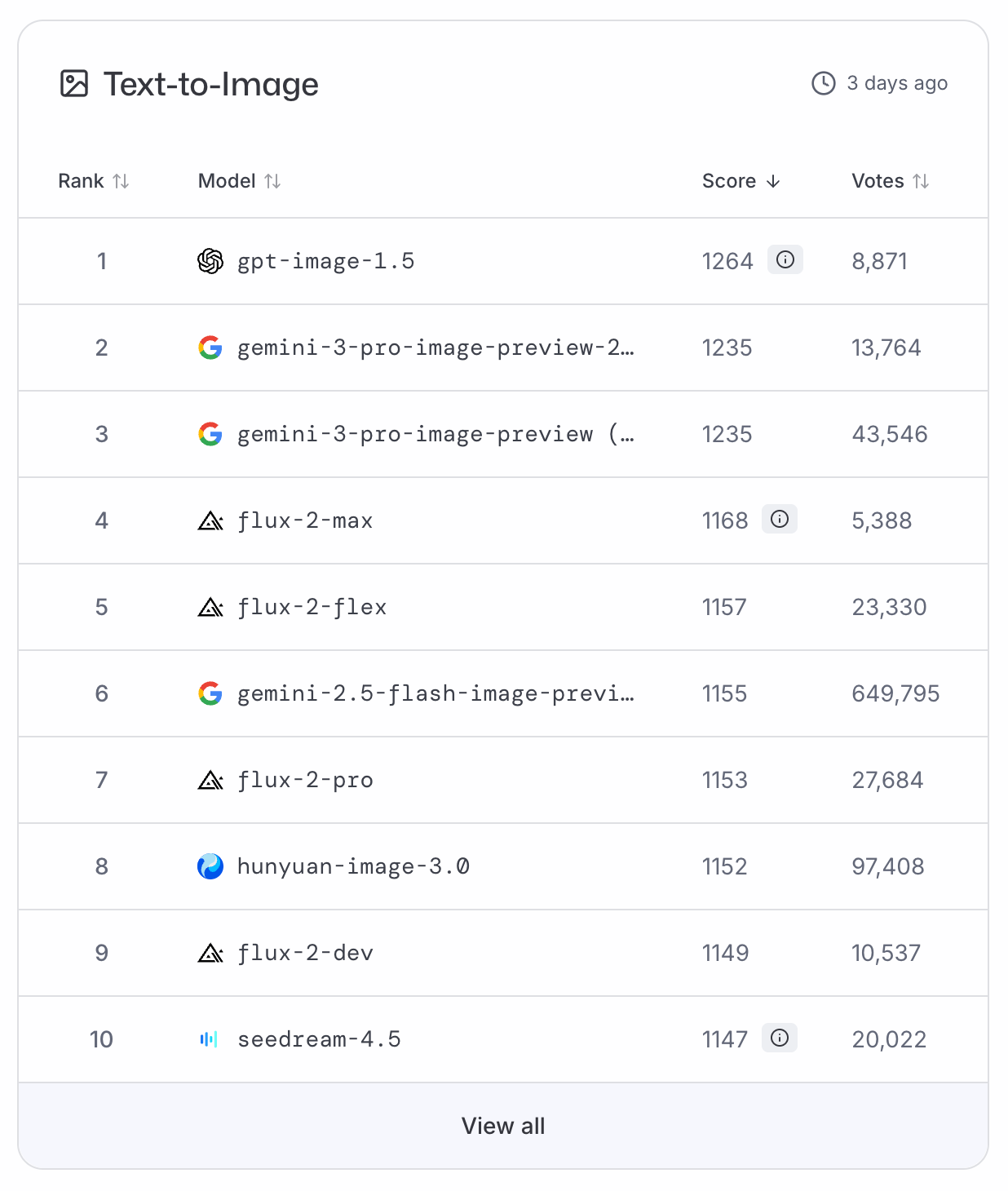
GPT-Image-1.5 上线后迅速登顶LMArena 与ArtificialAnalysis 的文本转图像排行榜,将 Nano Banana Pro 压至第二。由于目前尚无基准数据,我们需要依赖这些投票类排名来做较为客观的判断。
借用一位著名宇航员的话:GPT-Image-1.5 对行业而言或许是小步前进,但对 OpenAI 来说是巨大飞跃。
虽然精确编辑并非全新概念,但将其原生引入 ChatGPT 是本次发布的最大转变。不过精度至关重要:请记得仅选择必要区域,避免出现测试中遇到的“无头北极熊”等问题。
就我的体验而言,此次更新带来了显著的质量提升,这也反映在排行榜名次上。标准图像更具生气,而信息图不再像以前那样过于简化。
用户如今可以对每次输出施加更多控制,取代以往“堆叠复杂追问、听天由命”的工作流。这主要归功于细节保真表现出色——在我们的测试中,模型能将元素完全保留下来。
角色一致性很强,但需留意“贴纸效应”与逻辑透视问题。尽管定向编辑让修复更容易,拥挤场景(多人)中的局限仍然存在。
ChatGPT Images vs. Nano Banana Pro
目前 ChatGPT Images 需要超越的头号对手显然是 Google 的 Nano Banana Pro。下表对两者做出比较:
|
ChatGPT Images |
Nano Banana Pro |
|
|
编辑模型 |
精确度:区域选择与就地编辑 |
推理:对话式与智能遮罩 |
|
工作流 |
专用创作工作区 |
集成于聊天功能 |
|
迭代 |
高效:部分重生成 |
探索:Remix 混合重构 |
|
一致性 |
高水平版式与细节保留 |
高水平版式与细节保留 |
|
生态 |
OpenAI 与 Azure |
Google / Gemini 技术栈 |
尽管 GPT-Image-1.5 与 Nano Banana Pro 都能产出优秀结果,但两者在编辑理念、工作流与客户侧重点上存在差异。
ChatGPT Images 注重像素级的精确隔离,优势在于手动控制:您可以精确选择区域,模型将该选区视作局部修补的画布,而其余图像被锁定。相对地,Nano Banana Pro 会尝试理解您的意图,以做出合适更改。
在工作流上,两家公司也选择了不同路径:ChatGPT 的 Images 标签页像一个独立于对话之外的创意工作室,而 Nano Banana Pro 则完全融入聊天流中。
更新:Google 的非 Pro 版图像生成模型新版本 Nano Banana 2 带来了显著改进。虽然 Nano Banana Pro 仍略占优势,但新模型以更快的速度提供了(几乎)相同的质量。
何时用 ChatGPT Images,何时用 Nano Banana Pro
如果您需要修正版式、编辑文本,或在不改变风格的情况下对现有图像进行精确修改,我建议使用 ChatGPT Images。若需要生成数据量大的可视化、混合重构多张图片,或偏好由智能助手揣摩意图而非手动控制,则选择 Nano Banana Pro。
我用相同提示词重现了测试图像。就个人而言,我更喜欢 Nano Banana Pro 的信息图,而熊的图像则不相上下。
提示词:“一张横向信息图,解释‘恒星的生命周期’。三部分:星云、主序星、黑洞。使用扁平矢量风格。”(Nano Banana Pro)
ChatGPT Images 的应用场景
基于我们的上手测试与 GPT-Image-1.5 的特长,该模型在迭代流程与文本编辑方面表现出色。以下是几个重点用例:
- 营销工作流:创建社交媒体广告或产品照片,其中特定细节可能需要变更(如“把毛衣从红色改成蓝色”)
- 教育类信息图:为教材、演示或博客生成图示,例如我们的“恒星生命周期”示例
- 分镜脚本:可视化剧本或漫画,在不同地点保持同一角色出现
- 时尚:通过混合创作探索穿搭组合,例如这篇FLUX.2 衣橱可视化教程
- 室内设计:结合草图或照片与提示词,以特定风格重新装饰房间
- UI/UX 原型:快速可视化网站落地页或新产品包装的可能样式
结语
自 Nano Banana Pro 发布以来,OpenAI 面临着不小的追赶压力。凭借这次颇具前景的更新,他们重回最强文本转图像 AI 模型之争。它并非完美,但若专注于清晰的字体排印与精确编辑,您就能获得不错的结果。开始体验吧:在 ChatGPT 界面中试用该功能,或前往OpenAI Playground。如需灵感,可查看作品集与提示指南。
如果您想开始使用 GPT 模型构建工具,我们的OpenAI Fundamentals 技能路径适合您。