Có. GPT-Image-1.5 khả dụng trong OpenAI API và bao gồm cùng các cải tiến như ChatGPT Images. Đầu vào và đầu ra hình ảnh rẻ hơn khoảng 20% so với GPT Image 1, phù hợp cho các ứng dụng như marketing, thương mại điện tử và quy trình thiết kế.
ChatGPT Images là gì?
Tab Images mới của ChatGPT đóng vai trò là trung tâm sáng tạo cho mọi nội dung trực quan trong giao diện ChatGPT và thay thế thư viện ảnh cá nhân. Thay đổi đáng chú ý nhất là tích hợp các công cụ chỉnh sửa trực tiếp cho phép nhắm vào những chi tiết cụ thể trong ảnh mà vẫn giữ nguyên các phần còn lại.
ChatGPT Images được vận hành bởi GPT-Image-1.5, mô hình AI chuyển văn bản thành hình ảnh mới nhất và tiên tiến nhất của OpenAI. Nó kế thừa từ lần ra mắt GPT-Image-1 vào tháng 3/2025, vốn đã rất thành công với hơn 700 triệu ảnh được tạo trong tuần đầu tiên.
Mô hình mang lại khả năng giữ gìn chi tiết và cải thiện hiển thị văn bản, và được cho là “nhanh hơn đến 4 lần” so với phiên bản trước.
Các tính năng mới đã được triển khai cho mọi người dùng, cả miễn phí và trả phí, trên web, ứng dụng di động và API. Chỉ các tài khoản Business và Enterprise là còn phải chờ để được truy cập.
Các tính năng chính của ChatGPT Images
Vậy ChatGPT Images mang đến những gì so với mô hình trước và đối thủ? OpenAI đặc biệt nhấn mạnh “chỉnh sửa chính xác mà vẫn giữ được điều quan trọng”. Hãy xem các tính năng mới để hiểu rõ hơn.
Không gian làm việc sáng tạo chuyên biệt
Tab Images được giới thiệu như một trung tâm sáng tạo trực quan trong giao diện ChatGPT. Ý tưởng là tách riêng việc tạo và chỉnh sửa ảnh khỏi các tương tác trò chuyện thông thường.
Trong khi tính năng Library trước đây cũng lưu mọi ảnh đã tạo, nó chỉ cho phép bạn quay lại đoạn hội thoại mà ảnh được tạo ra. Nó dùng ngữ cảnh từ toàn bộ lịch sử hội thoại để tạo ảnh mới từ đầu, thường dẫn tới ảo giác trong những chuỗi dài.
Cách tiếp cận mới lại đặt hình ảnh làm trung tâm: Mỗi lần chỉnh sửa lấy một bức ảnh làm điểm khởi đầu và chỉ thay đổi những khía cạnh đã chọn, thay vì tạo một ảnh hoàn toàn mới.
Ảnh là các thực thể tồn tại độc lập, không bị chôn vùi trong lịch sử trò chuyện. Điều này cho phép vòng phản hồi nhanh với các biến thể mới và khuyến khích thử nghiệm, hiệu quả biến trải nghiệm từ một chuỗi chat thành một tấm canvas.
Để thúc đẩy dòng chảy sáng tạo, không gian làm việc giới thiệu các công cụ khám phá mới nhằm thu hẹp khoảng cách giữa ý tưởng và thực thi. Người dùng có thể áp dụng preset phong cách sẵn có (như “sketch” hay “dramatic”) hoặc duyệt các xu hướng thẩm mỹ để bắt kịp “Studio Ghibli” tiếp theo. Với người mới, giao diện đưa ra gợi ý sáng tạo và hỗ trợ gợi ý chủ động để tinh chỉnh kết quả.
Giữ nguyên chi tiết và chỉnh sửa chính xác
Có lẽ là tính năng mới quan trọng nhất, bản cập nhật cho phép người dùng chọn các phần cụ thể của ảnh và chỉnh sửa trực tiếp, mà không làm thay đổi phần còn lại của bố cục. Mô hình nhận biết ngữ cảnh, nghĩa là hiểu phần nào cần chỉnh sửa đồng thời giữ cho các yếu tố xung quanh nhất quán.
Những chỉnh sửa sắc nét như vậy khả thi nhờ kỹ năng giữ gìn chi tiết được cải thiện của mô hình mới.
Mô hình có thể giữ đối tượng, ánh sáng, bố cục và diện mạo con người nhất quán xuyên suốt các đầu ra và các lần chỉnh sửa sau đó. Ngoài ra, khả năng tuân thủ hướng dẫn được cải thiện cũng giúp tăng độ chính xác bằng cách bảo toàn tốt hơn mối quan hệ giữa các yếu tố.
Chỉnh sửa chính xác rất phù hợp để xử lý lỗi nhỏ và thử nghiệm chi tiết cụ thể khi không cần tạo lại toàn bộ. Nó cũng cho phép biến đổi sáng tạo, như đưa một phần tử từ ảnh này vào bối cảnh của ảnh khác.
Tuy nhiên, cần lưu ý mô hình gặp khó khi giữ đúng danh tính của từng người nếu có nhiều người trong một ảnh.
Cải thiện hiển thị văn bản và tính chân thực
Một trong những điểm mạnh của mô hình tiền nhiệm GPT-Image-1 là khả năng xử lý văn bản dài và câu mạch lạc. Bản phát hành mới xây dựng trên nền tảng đó và hiện có thể xử lý văn bản dày và nhỏ hơn trước.
Điều này đặc biệt hữu ích cho infographic, nơi kết quả đầu tiên khá ấn tượng, và mở ra khả năng mới như dàn trang văn bản trong ảnh, ví dụ trên báo. Chúng tôi sẽ thử nghiệm infographic ở phần sau.
Tuy vậy, theo tuyên bố phát hành của OpenAI, hạn chế liên quan đến một số ngôn ngữ cụ thể như tiếng Trung, tiếng Ả Rập và tiếng Do Thái vẫn còn tồn tại.
Dù không phải trọng tâm của bản cập nhật, tính chân thực của đầu ra đã cải thiện đáng kể so với mô hình trước. Hai trường hợp thể hiện rõ là phản chiếu, ví dụ ánh lóa trên ảnh, và nhiều khuôn mặt nhỏ trong đám đông lớn.
Như thường thấy, nâng cấp lớn đi kèm đánh đổi ở vài khía cạnh. Trong trường hợp này, khả năng tạo một số phong cách nghệ thuật cụ thể có phần thụt lùi. OpenAI khuyến nghị dùng bộ lọc preset trong tab Images hoặc quay về mô hình trước, hiện vẫn có sẵn dưới dạng GPT tùy chỉnh.
Hiệu năng tăng tốc
Khả năng chỉnh sửa mục tiêu cũng là nguồn gốc chính của tốc độ tạo ảnh tăng lên. Dù tạo ảnh toàn phần nhanh hơn rõ rệt, nó không đạt được tuyên bố trong ghi chú phát hành của OpenAI. GPT-Images-1.5 trông “nhanh hơn đến 4 lần” chủ yếu vì nó chỉ tái tạo phần thay đổi trong các lần chỉnh sửa.
Tương tự, chi phí API giảm khoảng 20% chủ yếu đến từ việc tái tạo một phần ảnh trong lúc chỉnh sửa, kèm lợi ích bổ sung từ suy luận hiệu quả hơn chứ không phải rẻ hơn ở các phiên tạo toàn phần.
Tổng thể, tính năng mới giúp sử dụng hiệu quả và tin cậy hơn, đặc biệt cho quy trình API.
Ví dụ với ChatGPT Images
Những tính năng được công bố nghe rất hấp dẫn. Tôi đã kiểm chứng bằng vài prompt đơn giản kết hợp với công cụ chọn vùng mới.
Kiểm tra độ chính xác khi chỉnh sửa
Mục tiêu đầu tiên của tôi là đánh giá khả năng xử lý thay đổi lặp mà không suy giảm chất lượng. Đầu tiên, tôi yêu cầu tạo ảnh một con gấu nâu đang đi qua khu rừng Phần Lan trong đêm trắng.

Prompt: “A brown bear walking through a dense Finnish forest during the midnight sun.”
Theo tôi, chất lượng đầu ra đầu tiên rất cao. Chú gấu trông tự nhiên, loại cây và bụi rậm thể hiện rất đúng rừng Phần Lan (tôi biết chứ!), và vị trí thấp của mặt trời đúng với những gì bạn có thể thấy ở miền Bắc Phần Lan trong đêm trắng.
Ngoài ra, ánh sáng và bóng đổ trên lông gấu cũng như hậu cảnh trông khá chân thực. Bạn vẫn có thể nhận ra đó là AI, ở đâu đó, dù các chi tiết rất đẹp.
Hãy thử đổi gấu nâu thành gấu Bắc Cực và xem chuyện gì xảy ra. Ở Phần Lan không có gấu Bắc Cực, nhưng nếu mọi thứ hoạt động đúng, hậu cảnh phải giữ nguyên.

Prompt: “Change the bear to a polar bear.”
Như ta thấy, hậu cảnh được giữ nguyên hoàn toàn, đúng như mong đợi.
Ở lần chỉnh tiếp theo, tôi chọn phần đầu và mắt của gấu Bắc Cực và cho chú đeo một cặp kính mát cổ điển.

Prompt: “Put a pair of vintage sunglasses on the bear.” (đã chọn vùng đầu)
Có vẻ ta đã thấy điều gì xảy ra khi chọn vùng quá lớn. Dù hậu cảnh và thân gấu được giữ nhất quán, phần đầu biến thành một chiếc kính khổng lồ. Thử lại, chỉ chọn vùng mắt.

Prompt: “Put a pair of vintage sunglasses on the bear.” (đã chọn vùng mắt)
Rất ngầu, và chắc chắn tốt hơn nhiều! Qua bài test đầu, ta thấy tính năng giữ chi tiết mạnh mẽ thế nào: Ta chỉ cần nêu chi tiết quan trọng về bối cảnh một lần, rồi có thể lặp lại với nhân vật chính mà không lo hậu cảnh. Một kết luận quan trọng khác là kích thước khung chọn rất quan trọng.
Kiểm tra tính nhất quán khi chuyển cảnh
Tiếp theo, tôi kiểm tra tính bền vững của đối tượng khi chuyển bối cảnh và giới hạn của mô hình trong đám đông lớn. Vì mục đích này, tôi cho gấu Bắc Cực “du lịch” và thử đưa chú vào cảnh tàu điện ngầm đông đúc ở Tokyo.

Prompt: “Place this bear into a very busy subway scene in Tokyo.”
Trước hết, tính nhất quán nhân vật rất ấn tượng: mô hình giữ nguyên tư thế và “diện mạo” chính xác của gấu, đồng thời loại bỏ ánh lóa mặt trời trên lông.
Tuy nhiên, sự bảo toàn quá cứng khiến xuất hiện “hiệu ứng nhãn dán”. Vì mô hình không cập nhật ngữ cảnh ánh sáng (giữ bóng đổ định hướng và phản chiếu rừng trong kính mát), chú gấu trông như hình cắt 2D dán lên cảnh, thay vì vật thể 3D trong đó.
Phối cảnh càng làm vỡ ảo giác: gấu nổi phía trước một người qua đường vốn ở gần máy ảnh hơn.
Cố sửa vấn đề thứ hai khá nản. Tôi chọn vùng người qua đường và chỗ giao với gấu, rồi yêu cầu ChatGPT chỉnh phối cảnh. Mỗi biến thể, mô hình lại chèn một người mới gần máy ảnh, như thế này:

Prompt: “Correct the perspective: The selected bystander’s back is in the foreground and should partially obscure the bear. The bear is standing behind the person’s back.”
Có vẻ mô hình không nhận diện được người đó, kể cả khi đã chọn vùng, nên cần thêm nhân vật mới để làm theo lệnh trong prompt.
Việc sửa bóng đổ và phản chiếu trên kính mát thì thành công hơn. Tôi dùng các bước sau:
- Bóng đổ: Chọn phần sàn quanh chân gấu và dùng prompt “Instead of the current shadow, cast a soft, diffuse shadow on the subway tile floor consistent with the overhead fluorescent lighting.”
- Kính mát: Chọn kính mát và dùng prompt “Update the reflections of the sunglasses to match the subway environment.”

Chú gấu Bắc Cực trong tàu điện ngầm Tokyo sau khi sửa bóng đổ và phản chiếu trên kính
Đã tốt hơn nhiều, dù chưa hoàn hảo.
Tổng kết, bài test thứ hai không thành công như bài đầu. Dù tính nhất quán yếu tố giữa các ảnh có vẻ hoạt động tốt, nhận diện nhân vật có giới hạn trong môi trường đông người.
Kiểm tra hiển thị văn bản
Cuối cùng, tôi muốn thử khả năng hiển thị văn bản mới, nhất là với văn bản dày đặc và khi chỉnh sửa. Cải thiện hiển thị văn bản rất đáng mong đợi vì theo lịch sử, các mô hình thị giác thường giỏi vật thể, kết cấu, cảnh quan hơn là ký hiệu.
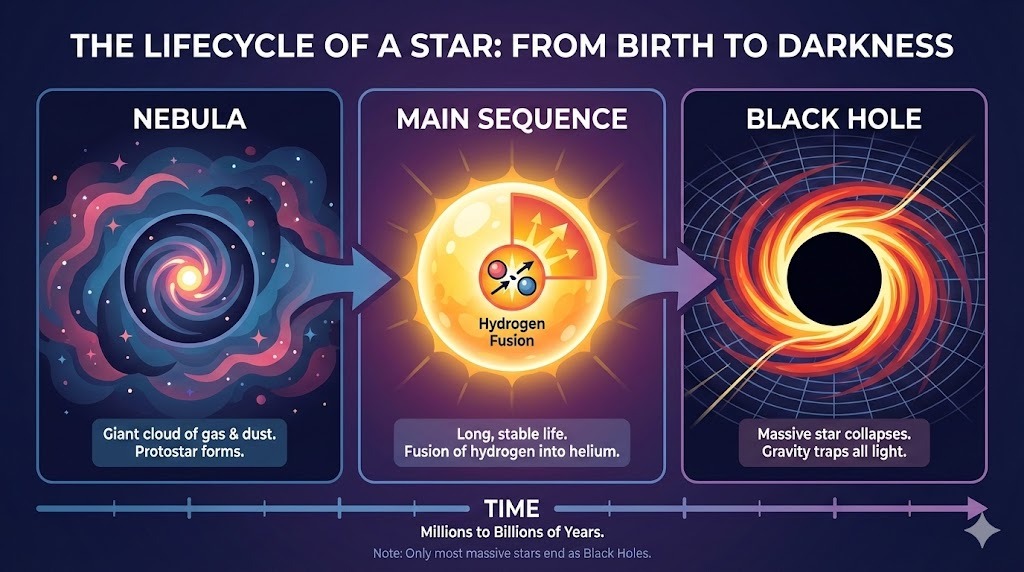
Tôi yêu cầu ChatGPT tạo bố cục phức tạp cho một infographic về vòng đời của ngôi sao:
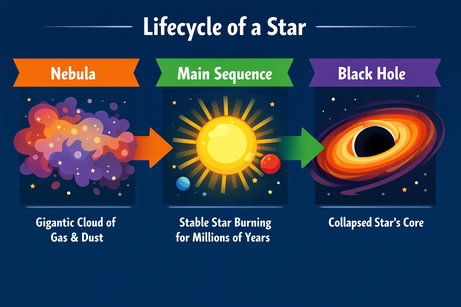
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style."
Kết quả bám sát hướng dẫn và hiển thị văn bản không lỗi. Phong cách chính xác và nhất quán trong toàn bộ infographic.
Tính đa phương thức đầu ra của ChatGPT buộc chúng ta phải chính xác khi chèn văn bản. Khi yêu cầu thêm một gạch đầu dòng “ở đây” (vào vùng đã chọn trong ảnh), hệ thống chỉ trả về gạch đầu dòng dưới dạng văn bản. Thêm làm rõ “vào ảnh” thì đã hiệu quả:
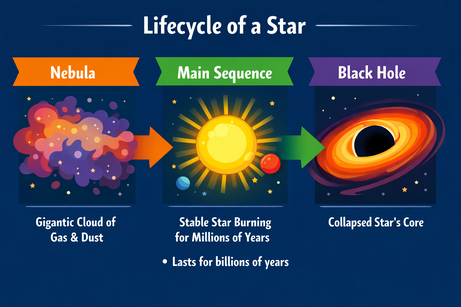
Prompt: “Add a bullet point to the image here that says: 'Lasts for billions of years'.”
Sau khi làm rõ, gạch đầu dòng được chèn đúng vị trí. Phông chữ, kích thước và màu sắc khớp với phong cách đồ họa.
Làm sao truy cập ChatGPT Images?
ChatGPT Images hiện khả dụng cho hầu hết người dùng trên nhiều nền tảng. Chỉ còn hỗ trợ cho nhóm Business và Enterprise là chưa có và sẽ bổ sung sau.
Trong giao diện, bạn có thể dùng ngay trên web hoặc ứng dụng di động của ChatGPT qua tab Images. Dù chưa rõ con số chính xác, tài khoản Free có giới hạn hàng ngày nghiêm ngặt, còn gói Plus và Pro có hạn mức cao hơn và ổn định hơn.
Với nhà phát triển, mô hình GPT-Image-1.5 mới có thể dùng qua cả OpenAI API và Azure OpenAI Service, hỗ trợ tạo và chỉnh sửa ảnh. Dù kỳ vọng mô hình sớm được tích hợp vào các bộ công cụ sáng tạo bên thứ ba, nhà phát triển đã có thể xây dựng quy trình chỉnh sửa trực tiếp trong ứng dụng của mình bằng các endpoint v1/images/generations và v1/images/edits.
Khác với tiền nhiệm, GPT-Image-1.5 tính phí token đầu ra hình ảnh riêng, dùng các endpoint API dành cho ảnh thay vì /v1/responses hợp nhất. Bạn chỉ trả cho số token cần để tạo phần thay đổi, thay vì cho cả ảnh mới mỗi lần.
Đây là lý do mô hình mới được cho là rẻ hơn khoảng 20% so với tiền nhiệm, dù giá theo token không thay đổi so với GPT-Image-1.
ChatGPT Images tốt đến mức nào?
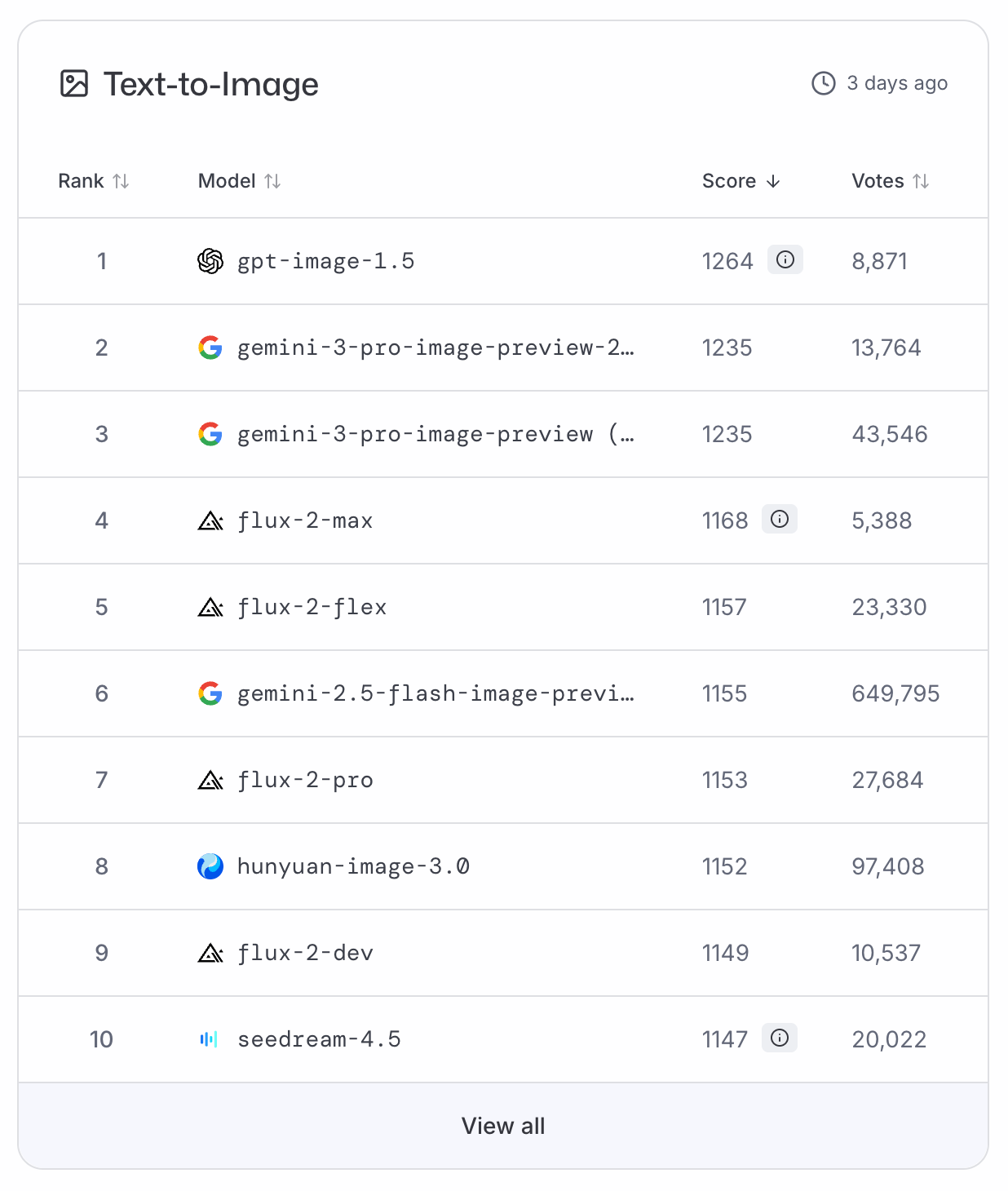
GPT-Image-1.5 đã lập tức leo lên đầu bảng xếp hạng LMArena và ArtificialAnalysis cho tác vụ văn bản thành hình ảnh, đẩy Nano Banana Pro xuống vị trí thứ hai. Vì hiện chưa có dữ liệu benchmark, chúng ta phải dựa vào các bảng xếp hạng dựa trên bình chọn này để có đánh giá khách quan.
Mượn lời một phi hành gia nổi tiếng: GPT-Image-1.5 là một bước nhỏ với ngành, nhưng là bước nhảy vọt với OpenAI.
Dù chỉnh sửa chính xác không hoàn toàn mới, việc đưa nó vào ChatGPT một cách nguyên bản là thay đổi lớn nhất của bản phát hành. Tuy nhiên, độ chính xác là chìa khóa: hãy nhớ chỉ chọn vùng cần thiết để tránh lỗi như “gấu Bắc Cực không đầu” trong thử nghiệm.
Theo trải nghiệm của tôi, bản cập nhật mang lại bước nhảy chất lượng rõ rệt, điều này cũng phản ánh trên bảng xếp hạng. Ảnh tiêu chuẩn trở nên sinh động hơn, và infographic ít bị đơn giản hóa hơn trước.
Người dùng giờ có nhiều quyền kiểm soát hơn với mỗi đầu ra, thay cho quy trình cũ là soạn prompt theo sau thật phức tạp và hy vọng vào may mắn. Điều này chủ yếu nhờ khả năng giữ chi tiết hoạt động rất tốt. Trong các bài thử, mô hình giữ các yếu tố nguyên vẹn.
Tính nhất quán nhân vật rất ổn, nhưng người dùng nên lưu ý “hiệu ứng nhãn dán” và các vấn đề phối cảnh phi logic. Dù chỉnh sửa mục tiêu giúp sửa chúng dễ hơn, hạn chế vẫn tồn tại trong cảnh đông người.
ChatGPT Images so với Nano Banana Pro
Đối thủ mà ChatGPT Images cần vượt qua hiện nay rõ ràng là Nano Banana Pro của Google. Bảng sau so sánh hai mô hình:
|
ChatGPT Images |
Nano Banana Pro |
|
|
Mô hình chỉnh sửa |
Chính xác: Chọn vùng & chỉnh sửa tại chỗ |
Lý giải: Hội thoại & che mặt nạ thông minh |
|
Quy trình |
Không gian sáng tạo chuyên biệt |
Tích hợp trong chat |
|
Lặp |
Hiệu quả: Tái tạo một phần |
Khám phá: Remix |
|
Nhất quán |
Giữ bố cục & chi tiết cao |
Giữ bố cục & chi tiết cao |
|
Hệ sinh thái |
OpenAI & Azure |
Google / Gemini Stack |
Dù cả GPT-Image-1.5 và Nano Banana Pro đều cho kết quả xuất sắc, hai mô hình khác nhau về triết lý chỉnh sửa, quy trình làm việc và đối tượng khách hàng.
ChatGPT Images tập trung vào cô lập điểm ảnh chuẩn xác, mạnh ở khả năng kiểm soát thủ công: Bạn có thể chọn một vùng chính xác, và hệ thống xử lý vùng chọn như một canvas để in-painting trong khi phần còn lại bị “khóa”. Ngược lại, Nano Banana Pro cố hiểu ý định của bạn để tự đưa ra thay đổi phù hợp.
Về quy trình, hai công ty cũng chọn hướng khác nhau: Tab Images trong ChatGPT giống một studio sáng tạo, tách khỏi hội thoại, trong khi Nano Banana Pro tích hợp hoàn toàn vào luồng chat.
Cập nhật: Phiên bản mới của mô hình tạo ảnh không-pro từ Google, Nano Banana 2, đã mang lại một số cải tiến đáng kể. Dù Nano Banana Pro vẫn nhỉnh hơn đôi chút, mô hình mới cho chất lượng (gần như) tương đương với tốc độ nhanh hơn nhiều.
Khi nào dùng ChatGPT Images và khi nào dùng Nano Banana Pro
Tôi đề xuất dùng ChatGPT Images khi bạn cần sửa bố cục, chỉnh văn bản, hoặc thực hiện thay đổi chính xác trên ảnh có sẵn mà không làm đổi phong cách. Chọn Nano Banana Pro khi bạn cần tạo hình ảnh giàu dữ liệu, remix nhiều bức ảnh, hoặc thích một trợ lý thông minh đoán ý định hơn là kiểm soát thủ công.
Dùng cùng prompt như trên, tôi đã tái tạo các ảnh thử nghiệm. Cá nhân tôi thích infographic của Nano Banana Pro hơn, còn ảnh gấu thì ngang ngửa.
Prompt: "A horizontal infographic explaining the 'Lifecycle of a Star'. Three sections: Nebula, Main Sequence, Black Hole. Use flat vector style." (Nano Banana Pro)
Trường hợp sử dụng ChatGPT Images
Dựa trên thử nghiệm thực tế và các điểm mạnh của GPT-Image-1.5, mô hình tỏa sáng ở quy trình lặp và chỉnh văn bản. Một vài trường hợp tiêu biểu:
- Quy trình marketing: Tạo quảng cáo mạng xã hội hoặc ảnh sản phẩm nơi chi tiết cụ thể có thể thay đổi (ví dụ, “Đổi áo len từ đỏ sang xanh”)
- Infographic giáo dục: Tạo sơ đồ cho sách giáo khoa, thuyết trình, hoặc blog, như ví dụ “vòng đời của một ngôi sao”
- Dựng storyboard: Hình dung kịch bản hoặc truyện tranh nơi cùng một nhân vật xuất hiện ở nhiều địa điểm khác nhau
- Thời trang: Dùng nội dung lai để khám phá trực quan phối đồ, như trong hướng dẫn visualizer tủ đồ FLUX.2
- Thiết kế nội thất: Kết hợp phác thảo thô hoặc ảnh với prompt để trang trí lại phòng theo một phong cách nhất định
- Mockup UI/UX: Nhanh chóng hình dung trang đích website hoặc bao bì cho sản phẩm mới
Kết luận
Kể từ khi Nano Banana Pro ra mắt, OpenAI chịu nhiều áp lực để bắt kịp. Với bản cập nhật đầy hứa hẹn này, họ đã trở lại cuộc đua mô hình văn bản thành hình ảnh mạnh nhất. Không hoàn hảo, nhưng nếu tập trung vào những thứ cốt lõi như chữ sắc nét và chỉnh sửa chính xác, bạn sẽ có kết quả tốt. Để bắt đầu, hãy thử tính năng trong giao diện ChatGPT của bạn hoặc trong OpenAI Playground. Để lấy cảm hứng, bạn có thể xem bộ sưu tập và hướng dẫn prompt.
Nếu bạn muốn bắt đầu xây dựng công cụ dùng các mô hình GPT, lộ trình kỹ năng OpenAI Fundamentals của chúng tôi là dành cho bạn.
ChatGPT Images có thể xử lý những loại chỉnh sửa ảnh nào?
GPT-Image-1.5 tốt hơn mô hình ảnh trước đó ở điểm nào?
ChatGPT Images có khả dụng cho mọi người không?
Nhà phát triển có thể dùng mô hình ảnh mới qua API không?


Author
Josef Waples