Kurs
PyTorch ile Deep Learning'e Giriş
4 sa
85.8K
Dil, insan iletişiminin temelidir ve otomasyonu büyük faydalar sağlayabilir. Doğal dil işleme (NLP) modelleri, insan dilinin inceliklerini etkili biçimde yakalamakta yıllarca zorlandı; ta ki bir atılım gerçekleşene kadar — attention (dikkat) mekanizması.
Attention mekanizması 2017 yılında Attention Is All You Need makalesinde tanıtıldı. Sözcükleri birbirinden bağımsız ele alan geleneksel yöntemlerin aksine, attention her sözcüğe mevcut göreve olan ilgisine göre ağırlık atar. Bu sayede model uzun menzilli bağımlılıkları yakalayabilir, yerel ve küresel bağlamları eşzamanlı analiz edebilir ve cümlenin bilgilendirici kısımlarına odaklanarak belirsizlikleri çözebilir.
Şu cümleyi düşünün: "Miami, 'sihirli şehir' olarak adlandırılır, bembeyaz kumlu plajlara sahiptir." Geleneksel modeller her sözcüğü sırayla işler. Oysa attention mekanizması beynimiz gibi davranır. Güncel odağı anlamaya katkısına göre her sözcüğe bir puan verir. Konum söz konusu olduğunda "Miami" ve "plajlar" gibi sözcükler daha önemli hâle gelir ve daha yüksek puan alır.
Bu yazıda attention mekanizmasına sezgisel bir açıklama getireceğiz. Daha teknik bir yaklaşımı ise transformer’lar nasıl çalışır başlıklı bu eğitimde bulabilirsiniz. Hadi başlayalım!
Attention mekanizmasını anlamaya yolculuğumuza dil modellerinin daha geniş bağlamını ele alarak başlayalım.
Dil modelleri, dilin dilbilgisel yapısını (sözdizimi) ve anlamını (anlambilim) kavramaya çalışarak dili işler. Amaç, girdiye uygun ve doğru sözdizimi ile anlambilime sahip çıktılar üretmektir.
Dil modelleri metni parçalamak ve anlamak için bir dizi tekniğe dayanır:
Geleneksel dil modelleri NLP’de ilerlemenin önünü açsa da, doğal dilin karmaşıklıklarını bütünüyle kavramakta zorluklarla karşılaştılar:
Sözcükleri birbirinden bağımsız ele alan geleneksel modellerin aksine attention, dil modellerinin bağlamı dikkate almasını sağlar. Bunun ne anlama geldiğine bakalım!
NLP alanındaki oyunun kurallarını değiştiren gelişme, 2017’de yayınlanan Attention Is All You Need makalesiyle attention mekanizmasının tanıtılması oldu.
Bu makale, transformer adı verilen yeni bir mimari önerdi. Yinelemeli sinir ağları (RNN) ve evrişimli sinir ağları (CNN) gibi eski yöntemlerin aksine transformer’lar attention mekanizmalarını kullanır.
Geleneksel modellerin birçok sorununu çözen transformer’lar (ve attention), bugün OpenAI’nin GPT-4’ü ve ChatGPT gibi en popüler büyük dil modellerinin (LLM) temelini oluşturdu.
Şu iki cümledeki “bat” sözcüğünü ele alalım:
Geleneksel gömme yöntemleri “bat” için tek bir vektör gösterimi atar; bu da anlamı ayırt etme becerisini sınırlar. Oysa attention mekanizmaları, bağlama bağlı ağırlıklar hesaplayarak bunu ele alır.
Çevredeki sözcükleri ("swing" ile "flew" arasındaki fark gibi) analiz eder ve ilgililiği belirleyen attention puanlarını hesaplar. Bu puanlar gömme vektörlerini ağırlıklandırmak için kullanılır; böylece “bat” sözcüğü bir spor aracı ("swing"e yüksek ağırlık) ya da uçan bir canlı ("flew"e yüksek ağırlık) olarak farklı biçimde temsil edilir.
Bu, modelin anlamsal incelikleri yakalamasını ve kavrayışını geliştirmesini sağlar.
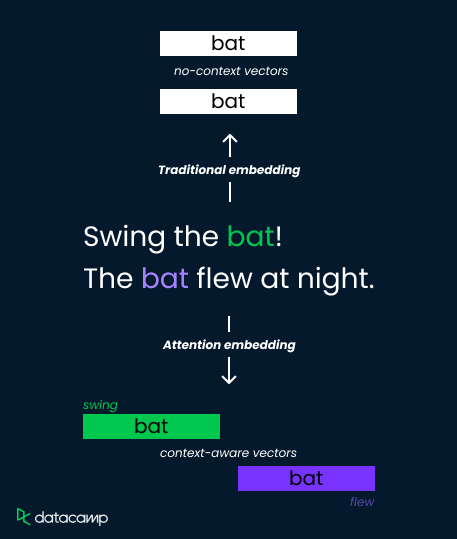
Şimdi attention’a dair sezgisel anlayışımızı genişleterek, mekanizmanın geleneksel sözcük gömmelerin ötesine nasıl geçtiğini ve dil kavrayışını nasıl geliştirdiğini öğrenelim. Ayrıca attention’ın birkaç gerçek dünya uygulamasına da bakacağız.
Word2Vec ve GloVe gibi geleneksel sözcük gömme teknikleri, büyük metin derlemlerindeki birlikte görülme istatistiklerine dayanarak sözcükleri anlamsal bir uzayda sabit boyutlu vektörler olarak temsil eder.
Bu gömmeler sözcükler arasındaki bazı anlamsal ilişkileri yakalasa da bağlam duyarlılığından yoksundur. Yani aynı sözcük, cümle ya da belgedeki bağlamı ne olursa olsun aynı gömmeye sahip olur.
Bu sınırlama, özellikle sözcüklerin farklı bağlamsal anlamlar taşıdığı görevlerde zorluk yaratır. Attention mekanizması, modellerin girdi dizilerinin ilgili kısımlarına seçici biçimde odaklanmasını sağlayarak bu sorunu çözer ve temsil öğrenme sürecine bağlam duyarlılığını katar.
Attention, modellerin dildeki incelikleri ve belirsizlikleri anlamasını sağlayarak karmaşık metinleri işlemekte daha etkili olmalarına yardımcı olur. Başlıca faydaları şunlardır:
Attention tabanlı dil modellerinin etkisi çok büyük oldu. Attention tabanlı modellerin üzerine kurulu uygulamaları binlerce kişi kullanıyor. En popüler uygulamalardan bazıları şunlardır:
Artık attention’ın nasıl çalıştığına daha aşina olduğumuza göre, self-attention ve multi-head attention’a bakalım.
Self-attention, bir modelin bir girdi dizisinin farklı konumlarına dikkat ederek o dizinin bir temsilini hesaplamasını sağlar. Modelin dizideki her sözcüğün önemini diğerlerine göre ağırlıklandırmasına ve girdideki farklı sözcükler arasındaki bağımlılıkları yakalamasına imkân verir. Mekanizmanın üç ana öğesi vardır:
Attention puanları, sorgu ve anahtar vektörleri arasında ölçeklendirilmiş noktasal çarpım yapılarak hesaplanabilir. Son aşamada bu puanlar değer vektörleriyle çarpılarak değerlerin ağırlıklı toplamı üretilir.
Multi-head attention, self-attention mekanizmasının bir uzantısıdır. Girdi dizisinin farklı kısımlarına eşzamanlı olarak dikkat ederek modelin çeşitli bağlamsal bilgileri yakalama yeteneğini artırır. Bunu, her biri kendi öğrenilmiş sorgu, anahtar ve değer dönüşümlerine sahip birden çok paralel self-attention işlemi yürüterek başarır.
Multi-head attention, daha ince bağlamsal anlama, artan sağlamlık ve ifade gücü sağlar.
Attention mekanizmasını uygulamanın pek çok faydası olsa da, beraberinde gelen zorluklar da vardır ve bunlar üzerine yapılan araştırmalar potansiyel çözümler sunmaktadır.
Attention mekanizmaları, girdi dizisindeki tüm token’lar arasında ikili benzerlikler hesaplamayı içerir; bu da dizi uzunluğuna göre karesel karmaşıklığa yol açar. Özellikle uzun diziler için hesaplama maliyeti yüksek olabilir.
Seyrek attention mekanizmaları, yaklaşıklama temelli attention yöntemleri ve Reformer modelinin yerellik duyarlı özetlemesi gibi verimli attention mekanizmaları, hesaplama karmaşıklığını azaltmak için önerilmiştir.
Attention mekanizmaları, girdi dizisindeki gürültülü veya alakasız bilgilere aşırı uyum sağlayarak görülmemiş verilerde yetersiz performansa yol açabilir.
Dropout ve katman normalizasyonu gibi düzenlileştirme teknikleri, attention tabanlı modellerde aşırı öğrenimi önlemeye yardımcı olabilir. Ayrıca attention dropout ve attention maskesi gibi teknikler, modelin ilgili bilgiye odaklanmasını teşvik etmek için önerilmiştir.
Özellikle birden çok katman ve attention başlığına sahip karmaşık modellerde, attention mekanizmalarının nasıl çalıştığını ve çıktılarının nasıl yorumlanacağını anlamak zor olabilir. Bu da bu yeni teknolojinin etiğine dair endişeleri gündeme getirir — Yapay zeka etiği hakkında daha fazla bilgiyi kursumuzda ya da AI araştırmacısı Dr. Joy Buolamwini ile yapılan bu podcast’i dinleyerek edinebilirsiniz.
Attention ağırlıklarını görselleştirmek ve anlamlarını yorumlamak için yöntemler geliştirilmiştir; bu da attention tabanlı modellerin yorumlanabilirliğini artırır. Ek olarak, attention atfı gibi teknikler, modelin tahminlerine tek tek token’ların katkılarını belirlemeyi hedefleyerek açıklanabilirliği geliştirir.
Attention mekanizmaları önemli miktarda bellek ve hesaplama kaynağı tüketir; bu da daha büyük modellere ve veri kümelerine ölçeklemeyi zorlaştırır.
Hiyerarşik attention, bellek açısından verimli attention ve seyrek attention gibi attention tabanlı modelleri ölçekleme teknikleri, bellek tüketimini ve hesaplama yükünü azaltırken model performansını korumayı amaçlar.
Şimdiye kadar öğrendiklerimizi, geleneksel ve attention tabanlı modeller arasındaki farklara odaklanarak özetleyelim:
|
Özellik |
Attention Tabanlı Modeller |
Geleneksel NLP Modelleri |
|
Sözcük Temsili |
Bağlama duyarlı gömme vektörleri (attention puanlarına göre dinamik olarak ağırlıklandırılır) |
Statik gömme vektörleri (her sözcük için tek vektör, bağlam dikkate alınmaz) |
|
Odak |
Anlam için çevredeki sözcükleri dikkate alır (daha geniş bağlama bakar) |
Her sözcüğü bağımsız ele alır |
|
Güçlü Yanlar |
Uzun menzilli bağımlılıkları yakalar, belirsizliği giderir, incelikleri anlar |
Daha basit, hesaplama açısından daha ucuz |
|
Zayıf Yanlar |
Hesaplama maliyeti yüksek olabilir |
Karmaşık dili anlama yeteneği sınırlıdır, bağlamla zorlanır |
|
Temel Mekanizma |
Attention’lı kodlayıcı-çözücü ağlar (çeşitli mimariler) |
Ayrıştırma, gövdeleme, adlandırılmış varlık tanıma, sözcük gömme gibi teknikler |
Bu yazıda, NLP’yi kökten değiştiren bir yenilik olan attention mekanizmasını inceledik. Önceki yöntemlerden farklı olarak attention, dil modellerinin bir cümlenin kritik kısımlarına bağlamı dikkate alarak odaklanmasını sağlar. Bu da karmaşık dili, uzun menzilli bağlantıları ve sözcüklerdeki anlam belirsizliğini kavramalarına imkân verir.
Attention mekanizması hakkında öğrenmeye şu yollarla devam edebilirsiniz:
Derin Öğrenmeye başlayın!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
