Cours
Introduction au deep learning avec PyTorch
4 h
86.1K
Le langage est essentiel à la communication humaine, et son automatisation peut apporter d'immenses avantages. Les modèles de traitement du langage naturel (NLP) ont lutté pendant des années pour saisir efficacement les nuances du langage humain, jusqu'à ce qu'une avancée se produise : le mécanisme de l'attention.
Le mécanisme d'attention a été présenté en 2017 dans l'article Attention Is All You Need. Contrairement aux méthodes traditionnelles qui traitent les mots de manière isolée, l'attention attribue des poids à chaque mot en fonction de sa pertinence pour la tâche en cours. Cela permet au modèle de saisir les dépendances à long terme, d'analyser simultanément les contextes locaux et globaux et de résoudre les ambiguïtés en tenant compte des parties informatives de la phrase.
Considérez la phrase suivante : Miami, surnommée la "ville magique", possède de magnifiques plages de sable blanc. Les modèles traditionnels traitent chaque mot dans l'ordre. Le mécanisme d'attention, quant à lui, agit davantage comme notre cerveau. Il attribue un score à chaque mot en fonction de sa pertinence pour comprendre le thème actuel. Des mots comme "Miami" et "plages" deviennent plus importants lorsque l'on considère la localisation, ils obtiendraient donc des scores plus élevés.
Dans cet article, nous vous proposons une explication intuitive du mécanisme de l'attention. Vous pouvez également trouver une approche plus technique dans ce tutoriel sur le fonctionnement des transformateurs. Plongeons dans le vif du sujet !
Commençons par comprendre le mécanisme de l'attention en considérant le contexte plus large des modèles de langage.
Les modèles linguistiques traitent la langue en essayant de comprendre la structure grammaticale (syntaxe) et le sens (sémantique). L'objectif est de produire un langage avec la syntaxe et la sémantique correctes qui sont pertinentes pour l'entrée.
Les modèles de langage s'appuient sur une série de techniques pour décomposer et comprendre le texte :
Si les modèles de langage traditionnels ont ouvert la voie aux progrès du NLP, ils ont eu du mal à saisir toute la complexité du langage naturel :
Contrairement aux modèles traditionnels qui traitent les mots de manière isolée, l'attention permet aux modèles linguistiques de tenir compte du contexte. Voyons de quoi il s'agit !
Le changement de donne pour le domaine de la PNL s'est produit en 2017 lorsque l'article Attention Is All You Need a présenté le mécanisme de l'attention.
Ce document propose une nouvelle architecture appelée transformateur. Contrairement aux méthodes plus anciennes telles que les réseaux neuronaux récurrents (RNN) et les réseaux neuronaux convolutifs (CNN), les transformateurs utilisent des mécanismes d'attention.
En résolvant de nombreux problèmes des modèles traditionnels, les transformateurs (et l'attention) sont devenus la base de nombreux grands modèles de langage (LLM) parmi les plus populaires aujourd'hui, comme le GPT-4 et le ChatGPT d'OpenAI.
Considérons le mot "bat" dans ces deux phrases :
Les méthodes d'intégration traditionnelles attribuent une représentation vectorielle unique à la "chauve-souris", ce qui limite leur capacité à distinguer le sens. Les mécanismes d'attention y remédient toutefois en calculant des poids dépendant du contexte.
Ils analysent les mots environnants ("swing" contre "flew") et calculent des scores d'attention qui déterminent la pertinence. Ces scores sont ensuite utilisés pour pondérer les vecteurs d'intégration, ce qui permet d'obtenir des représentations distinctes de la "batte" en tant qu'outil sportif (poids élevé sur "swing") ou en tant que créature volante (poids élevé sur "flew").
Cela permet au modèle de saisir les nuances sémantiques et d'améliorer la compréhension.
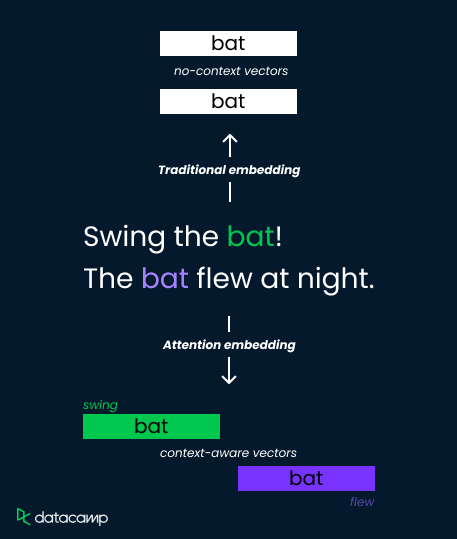
Nous allons maintenant nous appuyer sur notre compréhension intuitive de l'attention et découvrir comment le mécanisme va au-delà des enchâssements de mots traditionnels pour améliorer la compréhension de la langue. Nous examinerons également quelques applications concrètes de l'attention.
Les techniques traditionnelles d'intégration de mots, telles que Word2Vec et GloVe, représentent les mots comme des vecteurs à dimension fixe dans un espace sémantique basé sur des statistiques de cooccurrence dans un large corpus de textes.
Bien que ces enchâssements capturent certaines relations sémantiques entre les mots, ils manquent de sensibilité au contexte. Cela signifie qu'un même mot aura le même ancrage quel que soit son contexte dans une phrase ou un document.
Cette limitation pose des problèmes dans les tâches nécessitant une compréhension nuancée de la langue, en particulier lorsque les mots ont des significations contextuelles différentes. Le mécanisme d'attention résout ce problème en permettant aux modèles de se concentrer sélectivement sur les parties pertinentes des séquences d'entrée, intégrant ainsi la sensibilité au contexte dans le processus d'apprentissage de la représentation.
L'attention permet aux modèles de comprendre les nuances et les ambiguïtés du langage, ce qui les rend plus efficaces dans le traitement de textes complexes. Voici quelques-uns de ses principaux avantages :
Les modèles linguistiques basés sur l'attention ont eu un impact considérable. Des milliers de personnes utilisent des applications fondées sur des modèles basés sur l'attention. Voici quelques-unes des applications les plus populaires :
Maintenant que nous avons appris à mieux connaître le fonctionnement de l'attention, examinons l'auto-attention et l'attention multiple.
L'auto-attention permet à un modèle de s'intéresser à différentes positions de sa séquence d'entrée afin de calculer une représentation de cette séquence. Il permet au modèle d'évaluer l'importance de chaque mot de la séquence par rapport aux autres, en tenant compte des dépendances entre les différents mots de l'entrée. Le mécanisme comporte trois éléments principaux :
Les scores d'attention peuvent être calculés en effectuant un produit point échelonné entre la requête et les vecteurs clés. Enfin, ces scores sont multipliés par les vecteurs de valeur pour obtenir une somme pondérée des valeurs.
L'attention multiple est une extension du mécanisme d'auto-attention. Il améliore la capacité du modèle à saisir diverses informations contextuelles en s'intéressant simultanément à différentes parties de la séquence d'entrée. Pour ce faire, il effectue plusieurs opérations d'auto-attachement en parallèle, chacune avec son propre ensemble de transformations de requêtes, de clés et de valeurs apprises.
L'attention multi-têtes permet une compréhension contextuelle plus fine, une robustesse et une expressivité accrues.
Bien que la mise en œuvre du mécanisme d'attention présente plusieurs avantages, elle s'accompagne également d'une série de difficultés, que la recherche en cours peut potentiellement résoudre.
Les mécanismes d'attention impliquent le calcul de similitudes par paire entre tous les éléments de la séquence d'entrée, ce qui entraîne une complexité quadratique par rapport à la longueur de la séquence. Cette opération peut s'avérer coûteuse en termes de calcul, en particulier pour les longues séquences.
Diverses techniques ont été proposées pour atténuer la complexité des calculs, comme les mécanismes d'attention éparse, les méthodes d'attention approximative et les mécanismes d'attention efficaces tels que le hachage sensible à la localité du modèle Reformer.
Les mécanismes d'attention peuvent suradapter des informations bruyantes ou non pertinentes dans la séquence d'entrée, ce qui conduit à des performances sous-optimales sur des données non vues.
Les techniques de régularisation, telles que l'abandon et la normalisation des couches, peuvent aider à prévenir l'ajustement excessif dans les modèles basés sur l'attention. En outre, des techniques telles que l'abandon de l'attention et le masquage de l'attention ont été proposées pour encourager le modèle à se concentrer sur les informations pertinentes.
Comprendre comment les mécanismes d'attention fonctionnent et interprètent leurs résultats peut s'avérer difficile, en particulier dans les modèles complexes comportant plusieurs couches et têtes d'attention. Vous pouvez en savoir plus sur l'éthique de l'IA dans notre cours ou en écoutant ce podcast avec le Dr. Joy Buolamwini.
Des méthodes de visualisation des poids de l'attention et d'interprétation de leur signification ont été développées pour améliorer l'interprétabilité des modèles basés sur l'attention. En outre, des techniques telles que l'attribution de l'attention visent à identifier les contributions des jetons individuels aux prédictions du modèle, améliorant ainsi la capacité d'explication.
Les mécanismes d'attention consomment beaucoup de mémoire et de ressources informatiques, ce qui les rend difficiles à adapter à des modèles et des ensembles de données plus importants.
Les techniques de mise à l'échelle des modèles basés sur l'attention, telles que l'attention hiérarchique, l'attention efficace en termes de mémoire et l'attention éparse, visent à réduire la consommation de mémoire et les frais généraux de calcul tout en maintenant les performances du modèle.
Résumons ce que nous avons appris jusqu'à présent en nous concentrant sur les différences entre les modèles traditionnels et les modèles basés sur l'attention :
|
Fonctionnalité |
Modèles basés sur l'attention |
Modèles traditionnels de la PNL |
|
Représentation des mots |
Vecteurs d'intégration tenant compte du contexte (pondérés dynamiquement sur la base des scores d'attention) |
Vecteurs d'intégration statiques (un seul vecteur par mot, sans tenir compte du contexte) |
|
Focus |
Il prend en compte le sens des mots environnants (contexte plus large). |
Traite chaque mot de manière indépendante |
|
Points forts |
Saisit les dépendances à long terme, résout les ambiguïtés, comprend les nuances. |
Plus simple, moins coûteux sur le plan informatique |
|
Faiblesses |
Peut être coûteux sur le plan informatique |
Capacité limitée à comprendre un langage complexe, difficultés avec le contexte |
|
Mécanisme sous-jacent |
Réseaux codeur-décodeur avec attention (différentes architectures) |
Techniques telles que l'analyse syntaxique, le stemming, la reconnaissance d'entités nommées, l'intégration de mots. |
Dans cet article, nous avons exploré le mécanisme de l'attention, une innovation qui a révolutionné la PNL. Contrairement aux méthodes précédentes, l'attention permet aux modèles linguistiques de se concentrer sur les parties cruciales d'une phrase, en tenant compte du contexte. Cela leur permet d'appréhender un langage complexe, des connexions à long terme et l'ambiguïté des mots.
Vous pouvez continuer à vous familiariser avec le mécanisme de l'attention :
Lancez-vous dans l'apprentissage profond !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
blog
Lynn Heidmann
Tutoriel
Samuel Shaibu
Tutoriel


