Courses
Nhập môn Deep Learning với PyTorch
4 giờ
85.8K
Ngôn ngữ giữ vai trò tối quan trọng trong giao tiếp của con người, và tự động hóa nó có thể mang lại lợi ích to lớn. Các mô hình xử lý ngôn ngữ tự nhiên (NLP) đã chật vật suốt nhiều năm để nắm bắt tinh tế của ngôn ngữ cho đến khi một đột phá xuất hiện — cơ chế attention.
Cơ chế attention được giới thiệu năm 2017 trong bài báo Attention Is All You Need. Khác với các phương pháp truyền thống xem xét từ ngữ tách biệt, attention gán trọng số cho mỗi từ dựa trên mức độ liên quan với nhiệm vụ hiện tại. Điều này cho phép mô hình nắm bắt phụ thuộc tầm xa, đồng thời phân tích cả ngữ cảnh cục bộ lẫn tổng thể, và giải quyết mơ hồ bằng cách tập trung vào những phần thông tin của câu.
Hãy xem câu sau: "Miami, được mệnh danh là 'thành phố phép thuật', có những bãi biển cát trắng tuyệt đẹp." Các mô hình truyền thống sẽ xử lý từng từ theo thứ tự. Cơ chế attention, tuy nhiên, hoạt động giống não bộ chúng ta hơn. Nó gán điểm cho mỗi từ dựa trên mức độ liên quan với trọng tâm đang xét. Các từ như "Miami" và "beaches" trở nên quan trọng hơn khi xét về địa điểm, nên sẽ nhận điểm cao hơn.
Trong bài viết này, chúng tôi sẽ đưa ra một giải thích trực quan về cơ chế attention. Bạn cũng có thể tìm cách tiếp cận kỹ thuật hơn trong hướng dẫn này về cách transformers hoạt động. Cùng bắt đầu nhé!
Hãy bắt đầu hành trình hiểu cơ chế attention bằng cách đặt nó trong bối cảnh rộng hơn của các mô hình ngôn ngữ.
Các mô hình ngôn ngữ xử lý ngôn ngữ bằng cách cố gắng hiểu cấu trúc ngữ pháp (cú pháp) và ý nghĩa (ngữ nghĩa). Mục tiêu là xuất ra ngôn ngữ có cú pháp và ngữ nghĩa đúng, phù hợp với đầu vào.
Các mô hình ngôn ngữ dựa vào một loạt kỹ thuật để phân tách và hiểu văn bản:
Dù các mô hình ngôn ngữ truyền thống đã mở đường cho tiến bộ trong NLP, chúng vẫn gặp khó trong việc nắm bắt đầy đủ sự phức tạp của ngôn ngữ tự nhiên:
Khác với các mô hình truyền thống xem từ ngữ tách biệt, attention cho phép mô hình ngôn ngữ xét đến ngữ cảnh. Hãy xem cụ thể là gì!
Bước ngoặt cho lĩnh vực NLP đến vào năm 2017 khi bài báo Attention Is All You Need giới thiệu cơ chế attention.
Bài báo này đề xuất một kiến trúc mới gọi là transformer. Khác với các phương pháp cũ như mạng nơ-ron hồi quy (RNN) và mạng nơ-ron tích chập (CNN), transformers sử dụng các cơ chế attention.
Bằng cách giải quyết nhiều vấn đề của mô hình truyền thống, transformers (và attention) đã trở thành nền tảng cho nhiều mô hình ngôn ngữ lớn (LLM) phổ biến ngày nay, như GPT-4 của OpenAI và ChatGPT.
Hãy xét từ “bat” trong hai câu sau:
Các phương pháp embedding truyền thống gán một vector biểu diễn duy nhất cho “bat”, hạn chế khả năng phân biệt nghĩa. Tuy nhiên, cơ chế attention khắc phục bằng cách tính các trọng số phụ thuộc ngữ cảnh.
Chúng phân tích các từ xung quanh ("swing" so với "flew") và tính điểm attention xác định mức liên quan. Các điểm này sau đó được dùng để cân trọng các vector embedding, tạo ra biểu diễn khác biệt cho "bat" với nghĩa dụng cụ thể thao (trọng số cao ở "swing") hoặc loài dơi biết bay (trọng số cao ở "flew").
Điều này cho phép mô hình nắm bắt sắc thái ngữ nghĩa và cải thiện khả năng hiểu.
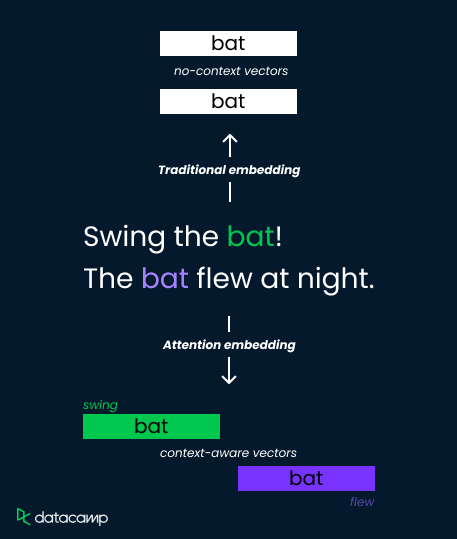
Giờ hãy dựa trên trực giác về attention để xem cơ chế này vượt lên trên word embedding truyền thống như thế nào nhằm nâng cao khả năng hiểu ngôn ngữ. Chúng ta cũng sẽ xem một vài ứng dụng thực tế của attention.
Các kỹ thuật word embedding truyền thống như Word2Vec và GloVe biểu diễn từ dưới dạng các vector có kích thước cố định trong không gian ngữ nghĩa dựa trên thống kê đồng xuất hiện trong một kho văn bản lớn.
Dù các embedding này nắm bắt một số quan hệ ngữ nghĩa giữa các từ, chúng thiếu độ nhạy ngữ cảnh. Nghĩa là cùng một từ sẽ có embedding như nhau bất kể bối cảnh trong câu hay tài liệu.
Hạn chế này đặt ra thách thức cho những tác vụ đòi hỏi hiểu biết tinh tế về ngôn ngữ — đặc biệt khi từ mang nghĩa khác nhau theo ngữ cảnh. Cơ chế attention giải quyết vấn đề bằng cách cho phép mô hình chọn lọc tập trung vào những phần liên quan của chuỗi đầu vào, từ đó đưa độ nhạy ngữ cảnh vào quá trình học biểu diễn.
Attention giúp mô hình hiểu sắc thái và mơ hồ trong ngôn ngữ, khiến chúng hiệu quả hơn khi xử lý văn bản phức tạp. Một số lợi ích chính gồm:
Tác động của các mô hình ngôn ngữ dựa trên attention là rất lớn. Hàng nghìn người sử dụng các ứng dụng xây dựng trên nền tảng này. Một số ứng dụng phổ biến nhất là:
Giờ khi đã quen với cách attention hoạt động, hãy xem self-attention và multi-head attention.
Self-attention cho phép mô hình tập trung vào các vị trí khác nhau trong chuỗi đầu vào để tính toán một biểu diễn cho chuỗi đó. Nó cho phép mô hình đánh giá tầm quan trọng của từng từ trong chuỗi so với các từ khác, nắm bắt các phụ thuộc giữa các từ khác nhau trong đầu vào. Cơ chế này có ba thành phần chính:
Điểm attention có thể được tính bằng tích vô hướng có tỉ lệ giữa các vector query và key. Cuối cùng, các điểm này được nhân với các vector value để cho ra tổng có trọng số của các value.
Multi-head attention là phần mở rộng của self-attention. Nó tăng khả năng của mô hình trong việc nắm bắt thông tin ngữ cảnh đa dạng bằng cách đồng thời tập trung vào các phần khác nhau của chuỗi đầu vào. Điều này đạt được bằng cách thực hiện nhiều phép self-attention song song, mỗi phép có bộ biến đổi query, key và value được học riêng.
Multi-head attention dẫn đến hiểu biết ngữ cảnh tinh vi hơn, tăng độ vững và khả năng biểu đạt.
Dù triển khai cơ chế attention mang lại nhiều lợi ích, nó cũng đi kèm các thách thức riêng, mà nghiên cứu hiện nay có thể giải quyết.
Các cơ chế attention bao gồm việc tính tương đồng theo cặp giữa mọi token trong chuỗi đầu vào, dẫn đến độ phức tạp bậc hai theo độ dài chuỗi. Điều này có thể tốn kém về mặt tính toán, đặc biệt với chuỗi dài.
Nhiều kỹ thuật đã được đề xuất để giảm độ phức tạp tính toán, như cơ chế attention thưa (sparse), attention xấp xỉ, và các cơ chế attention hiệu quả như hashing nhạy cảm vị trí trong mô hình Reformer.
Các cơ chế attention có thể overfit vào thông tin nhiễu hoặc không liên quan trong chuỗi đầu vào, dẫn đến hiệu năng kém trên dữ liệu chưa thấy.
Các kỹ thuật regularization như dropout và chuẩn hóa lớp (layer normalization) có thể giúp ngăn overfitting trong các mô hình dựa trên attention. Ngoài ra, các kỹ thuật như attention dropout và attention masking được đề xuất để khuyến khích mô hình tập trung vào thông tin liên quan.
Hiểu cách cơ chế attention vận hành và diễn giải đầu ra của chúng có thể là thách thức, đặc biệt trong các mô hình phức tạp với nhiều lớp và nhiều head attention. Điều này dấy lên lo ngại về đạo đức của công nghệ mới — bạn có thể tìm hiểu thêm về đạo đức AI trong khóa học của chúng tôi, hoặc nghe podcast với nhà nghiên cứu AI Dr. Joy Buolamwini.
Các phương pháp trực quan hóa trọng số attention và diễn giải ý nghĩa của chúng đã được phát triển để tăng tính diễn giải của các mô hình dựa trên attention. Ngoài ra, các kỹ thuật như quy gán attention nhằm xác định mức đóng góp của từng token vào dự đoán của mô hình, cải thiện khả năng giải thích.
Các cơ chế attention tiêu tốn nhiều bộ nhớ và tài nguyên tính toán, khiến việc mở rộng sang mô hình và dữ liệu lớn trở nên thách thức.
Các kỹ thuật mở rộng mô hình dựa trên attention, như attention phân cấp (hierarchical), attention tiết kiệm bộ nhớ, và attention thưa, nhằm giảm tiêu thụ bộ nhớ và chi phí tính toán trong khi vẫn duy trì hiệu năng.
Hãy tổng kết những gì chúng ta đã học bằng cách tập trung vào khác biệt giữa mô hình truyền thống và mô hình dựa trên attention:
|
Tính năng |
Mô hình dựa trên Attention |
Mô hình NLP truyền thống |
|
Biểu diễn từ |
Vector embedding nhận biết ngữ cảnh (được cân động dựa trên điểm attention) |
Vector embedding tĩnh (một vector cho mỗi từ, không xét ngữ cảnh) |
|
Trọng tâm |
Xem xét các từ xung quanh để hiểu nghĩa (nhìn vào bối cảnh rộng hơn) |
Xử lý mỗi từ một cách độc lập |
|
Điểm mạnh |
Nắm bắt phụ thuộc tầm xa, giải quyết mơ hồ, hiểu sắc thái |
Đơn giản hơn, rẻ hơn về tính toán |
|
Điểm yếu |
Có thể tốn kém về tính toán |
Khả năng hiểu ngôn ngữ phức tạp hạn chế, gặp khó với ngữ cảnh |
|
Cơ chế nền tảng |
Mạng encoder-decoder với attention (nhiều kiến trúc khác nhau) |
Các kỹ thuật như parsing, stemming, nhận diện thực thể, word embeddings |
Trong bài viết này, chúng ta đã khám phá cơ chế attention, một đổi mới đã cách mạng hóa NLP. Khác với các phương pháp trước đây, attention cho phép mô hình ngôn ngữ tập trung vào những phần then chốt của câu, đồng thời xét đến ngữ cảnh. Điều này giúp chúng nắm bắt ngôn ngữ phức tạp, các kết nối tầm xa và mơ hồ của từ.
Bạn có thể tiếp tục học về cơ chế attention bằng cách:
Bắt đầu với Deep Learning!
Courses
Courses
Courses