Corso
Introduzione al Deep Learning con PyTorch
4 h
85.8K
Il linguaggio è fondamentale per la comunicazione umana e automatizzarlo può portare enormi benefici. Per anni i modelli di elaborazione del linguaggio naturale (NLP) hanno faticato a cogliere efficacemente le sfumature del linguaggio umano finché non è arrivata una svolta — il meccanismo di attention.
Il meccanismo di attention è stato introdotto nel 2017 nel paper Attention Is All You Need. A differenza dei metodi tradizionali che trattano le parole in isolamento, l'attention assegna pesi a ogni parola in base alla sua rilevanza per il compito corrente. Questo consente al modello di catturare dipendenze a lungo raggio, analizzare contemporaneamente il contesto locale e globale e risolvere le ambiguità concentrandosi sulle parti più informative della frase.
Considera la frase: "Miami, soprannominata la 'magic city', ha splendide spiagge di sabbia bianca." I modelli tradizionali elaborerebbero ogni parola in sequenza. Il meccanismo di attention, invece, funziona più come il nostro cervello. Assegna un punteggio a ogni parola in base alla sua rilevanza per comprendere il focus attuale. Parole come "Miami" e "spiagge" diventano più importanti quando si considera la località, quindi ricevono punteggi più alti.
In questo articolo forniremo una spiegazione intuitiva del meccanismo di attention. Puoi anche trovare un approccio più tecnico in questo tutorial su come funzionano i transformer. Iniziamo!
Iniziamo il nostro percorso per capire l'attenzione considerando il contesto più ampio dei modelli linguistici.
I modelli linguistici elaborano il linguaggio cercando di comprenderne la struttura grammaticale (sintassi) e il significato (semantica). L'obiettivo è produrre linguaggio con sintassi e semantica corrette e pertinenti all'input.
I modelli linguistici si affidano a una serie di tecniche per scomporre e comprendere il testo:
Pur avendo aperto la strada ai progressi dell'NLP, i modelli tradizionali hanno incontrato difficoltà nel cogliere appieno le complessità del linguaggio naturale:
A differenza dei modelli tradizionali che trattano le parole in isolamento, l'attenzione consente ai modelli linguistici di considerare il contesto. Vediamo di cosa si tratta!
La svolta per il campo dell'NLP è arrivata nel 2017, quando il paper Attention Is All You Need ha introdotto il meccanismo di attention.
Questo paper ha proposto una nuova architettura chiamata transformer. A differenza di metodi più datati come le reti neurali ricorrenti (RNN) e le reti neurali convoluzionali (CNN), i transformer utilizzano meccanismi di attention.
Risolti molti dei problemi dei modelli tradizionali, i transformer (e l'attenzione) sono diventati la base di molti dei più popolari large language model (LLM) odierni, come GPT-4 di OpenAI e ChatGPT.
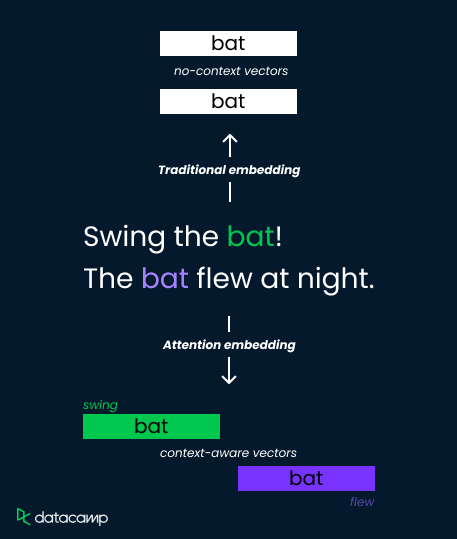
Consideriamo la parola “bat” in queste due frasi:
I metodi di embedding tradizionali assegnano a “bat” una singola rappresentazione vettoriale, limitando la capacità di distinguerne il significato. I meccanismi di attention, invece, affrontano il problema calcolando pesi dipendenti dal contesto.
Analizzano le parole circostanti ("swing" rispetto a "flew") e calcolano punteggi di attention che determinano la rilevanza. Questi punteggi vengono poi usati per pesare i vettori di embedding, ottenendo rappresentazioni distinte per "bat" come attrezzo sportivo (peso alto su "swing") o come animale volante (peso alto su "flew").
Questo permette al modello di catturare le sfumature semantiche e migliorare la comprensione.
Ora, partendo dall'intuizione che abbiamo costruito sull'attenzione, vediamo come questo meccanismo vada oltre i tradizionali word embedding per migliorare la comprensione del linguaggio. Esamineremo anche alcune applicazioni reali dell'attenzione.
Tecniche tradizionali di word embedding, come Word2Vec e GloVe, rappresentano le parole come vettori a dimensione fissa in uno spazio semantico basato sulle statistiche di co-occorrenza in un ampio corpus di testo.
Sebbene questi embedding catturino alcune relazioni semantiche tra parole, mancano di sensibilità al contesto. Ciò significa che la stessa parola avrà lo stesso embedding a prescindere dal contesto in cui appare in una frase o in un documento.
Questa limitazione crea problemi nei compiti che richiedono una comprensione sfumata del linguaggio — soprattutto quando le parole assumono significati diversi in base al contesto. Il meccanismo di attention risolve questo problema consentendo ai modelli di concentrarsi selettivamente sulle parti rilevanti delle sequenze in input, introducendo così sensibilità al contesto nel processo di apprendimento delle rappresentazioni.
L'attenzione permette ai modelli di comprendere sfumature e ambiguità del linguaggio, rendendoli più efficaci nell'elaborazione di testi complessi. Alcuni dei suoi principali vantaggi sono:
L'impatto dei modelli linguistici basati sull'attenzione è stato enorme. Migliaia di persone usano applicazioni costruite su questi modelli. Alcune tra le più diffuse sono:
Ora che abbiamo più familiarità con il funzionamento dell'attenzione, vediamo self-attention e multi-head attention.
La self-attention consente a un modello di prestare attenzione a diverse posizioni della propria sequenza di input per calcolarne una rappresentazione. Permette di pesare l'importanza di ciascuna parola nella sequenza rispetto alle altre, catturando le dipendenze tra parole diverse nell'input. Il meccanismo ha tre elementi principali:
I punteggi di attention possono essere calcolati effettuando un prodotto scalare scalato tra i vettori query e key. Infine, questi punteggi vengono moltiplicati per i vettori value per restituire una somma pesata dei value.
La multi-head attention è un'estensione della self-attention. Migliora la capacità del modello di catturare informazioni contestuali eterogenee prestando contemporaneamente attenzione a diverse parti della sequenza di input. Ciò avviene eseguendo più operazioni di self-attention in parallelo, ciascuna con il proprio set di trasformazioni apprese di query, key e value.
La multi-head attention porta a una comprensione contestuale più fine, maggiore robustezza ed espressività.
Sebbene l'implementazione del meccanismo di attention offra numerosi vantaggi, comporta anche una serie di sfide che la ricerca in corso può potenzialmente affrontare.
I meccanismi di attention richiedono il calcolo delle somiglianze a coppie tra tutti i token nella sequenza di input, con una complessità quadratica rispetto alla lunghezza della sequenza. Questo può essere costoso dal punto di vista computazionale, soprattutto per sequenze lunghe.
Sono state proposte varie tecniche per ridurre la complessità computazionale, come meccanismi di attention sparsa, metodi di attention approssimata e meccanismi efficienti come il locality-sensitive hashing del modello Reformer.
I meccanismi di attention possono sovradattarsi a informazioni rumorose o irrilevanti nella sequenza di input, portando a prestazioni subottimali su dati non visti.
Tecniche di regolarizzazione, come dropout e layer normalization, possono aiutare a prevenire l'overfitting nei modelli basati sull'attenzione. Inoltre, sono state proposte tecniche come attention dropout e attention masking per incoraggiare il modello a concentrarsi sulle informazioni rilevanti.
Comprendere come operino i meccanismi di attention e interpretarne l'output può essere difficile, soprattutto in modelli complessi con più layer e teste di attention. Questo solleva preoccupazioni sull'etica di questa nuova tecnologia — puoi saperne di più sull'etica dell'IA nel nostro corso o ascoltando questo podcast con la ricercatrice di IA Joy Buolamwini.
Sono stati sviluppati metodi per visualizzare i pesi di attention e interpretarne il significato, così da aumentare l'interpretabilità dei modelli basati sull'attenzione. Inoltre, tecniche come l'attribuzione dell'attenzione mirano a identificare il contributo dei singoli token alle previsioni del modello, migliorandone la spiegabilità.
I meccanismi di attention consumano risorse significative di memoria e calcolo, risultando difficili da scalare a modelli e dataset più grandi.
Tecniche per scalare i modelli basati sull'attenzione, come attention gerarchica, attention efficiente in memoria e attention sparsa, mirano a ridurre il consumo di memoria e il carico computazionale mantenendo le prestazioni del modello.
Ricapitoliamo quanto abbiamo imparato finora, concentrandoci sulle differenze tra modelli tradizionali e basati sull'attenzione:
|
Caratteristica |
Modelli basati sull'attenzione |
Modelli NLP tradizionali |
|
Rappresentazione delle parole |
Vettori di embedding sensibili al contesto (pesati dinamicamente in base ai punteggi di attention) |
Vettori di embedding statici (un singolo vettore per parola, senza considerare il contesto) |
|
Focus |
Considera le parole circostanti per il significato (guardando al contesto più ampio) |
Tratta ogni parola in modo indipendente |
|
Punti di forza |
Cattura dipendenze a lungo raggio, risolve ambiguità, comprende le sfumature |
Più semplice, meno costoso computazionalmente |
|
Punti deboli |
Può essere costoso computazionalmente |
Capacità limitata di comprendere linguaggio complesso, fatica con il contesto |
|
Meccanismo sottostante |
Reti encoder-decoder con attention (varie architetture) |
Tecniche come parsing, stemming, named entity recognition, word embedding |
In questo articolo abbiamo esplorato il meccanismo di attention, un'innovazione che ha rivoluzionato l'NLP. A differenza dei metodi precedenti, l'attenzione consente ai modelli linguistici di concentrarsi sulle parti cruciali di una frase, considerando il contesto. Questo permette di cogliere linguaggio complesso, connessioni a lungo raggio e ambiguità lessicali.
Puoi continuare a imparare sul meccanismo di attention:
Inizia con il Deep Learning!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min

