Cursus
Introductie tot Deep Learning met PyTorch
4 Hr
87.7K
Taal is cruciaal voor menselijke communicatie, en automatisering ervan kan enorme voordelen opleveren. Modellen voor natuurlijke taalverwerking (NLP) hadden jarenlang moeite om de nuances van menselijke taal effectief te vangen, tot er een doorbraak kwam — het attention-mechanisme.
Het attention-mechanisme werd in 2017 geïntroduceerd in de paper Attention Is All You Need. In tegenstelling tot traditionele methoden die woorden los van elkaar behandelen, kent attention gewichten toe aan elk woord op basis van de relevantie voor de huidige taak. Hierdoor kan het model lange-afstandsafhankelijkheden vastleggen, zowel lokale als globale context tegelijk analyseren en onduidelijkheden oplossen door zich te richten op informatieve delen van de zin.
Neem de volgende zin: "Miami, coined the 'magic city,' has beautiful white-sand beaches." Traditionele modellen verwerken elk woord op volgorde. Het attention-mechanisme werkt echter meer als ons brein. Het kent een score toe aan elk woord op basis van de relevantie voor het huidige aandachtspunt. Woorden als "Miami" en "beaches" worden belangrijker wanneer je naar locatie kijkt, dus die krijgen hogere scores.
In dit artikel geven we een intuïtieve uitleg van het attention-mechanisme. Je kunt ook een meer technische aanpak vinden in deze tutorial over hoe transformers werken. Laten we erin duiken!
Laten we onze reis om het attention-mechanisme te begrijpen beginnen door te kijken naar de bredere context van taalmodellen.
Taalmodellen verwerken taal door te proberen de grammaticale structuur (syntaxis) en betekenis (semantiek) te begrijpen. Het doel is om taal uit te voeren met de juiste syntaxis en semantiek die relevant is voor de input.
Taalmodellen maken gebruik van een reeks technieken om tekst op te delen en te begrijpen:
Hoewel traditionele taalmodellen de weg vrijmaakten voor vooruitgang in NLP, liepen ze tegen uitdagingen aan bij het volledig bevatten van de complexiteit van natuurlijke taal:
In tegenstelling tot traditionele modellen die woorden geïsoleerd behandelen, stelt attention taalmodellen in staat om context mee te nemen. Laten we bekijken wat dat inhoudt!
De gamechanger voor het NLP-veld kwam in 2017, toen de paper Attention Is All You Need het attention-mechanisme introduceerde.
Deze paper stelde een nieuwe architectuur voor, een transformer. In tegenstelling tot oudere methoden zoals recurrente neurale netwerken (RNN’s) en convolutionele neurale netwerken (CNN’s), gebruiken transformers attention-mechanismen.
Door veel problemen van traditionele modellen op te lossen, zijn transformers (en attention) de basis geworden voor veel van de populairste large language models (LLM’s) van vandaag, zoals OpenAI’s GPT-4 en ChatGPT.
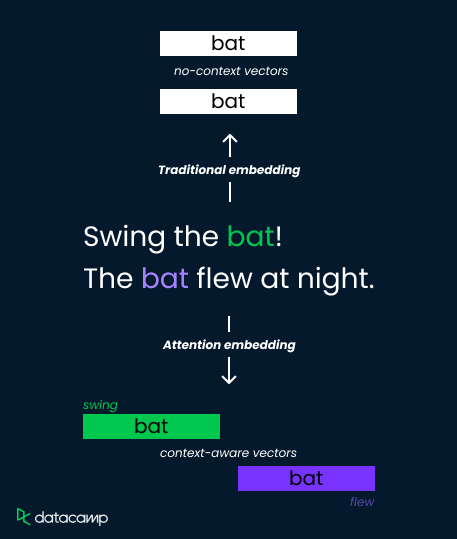
Laten we het woord “bat” in deze twee zinnen bekijken:
Traditionele embedding-methoden kennen één vectorrepresentatie toe aan “bat”, waardoor hun vermogen om betekenis te onderscheiden beperkt is. Attention-mechanismen pakken dit aan door contextafhankelijke gewichten te berekenen.
Ze analyseren omliggende woorden ("swing" versus "flew") en berekenen attention-scores die de relevantie bepalen. Deze scores worden vervolgens gebruikt om de embeddingvectoren te wegen, wat resulteert in verschillende representaties voor "bat" als sporthulpmiddel (hoog gewicht op "swing") of als vliegend dier (hoog gewicht op "flew").
Dit stelt het model in staat semantische nuances te vangen en het begrip te verbeteren.
Laten we voortbouwen op ons intuïtieve begrip van attention en leren hoe het mechanisme verder gaat dan traditionele woordembeddings om taalbegrip te verbeteren. We bekijken ook een paar toepassingen in de echte wereld.
Traditionele technieken voor woordembeddings, zoals Word2Vec en GloVe, representeren woorden als vectors met vaste dimensie in een semantische ruimte op basis van co-occurrencestatistieken in een groot tekstcorpus.
Hoewel deze embeddings bepaalde semantische relaties tussen woorden vastleggen, missen ze contextgevoeligheid. Dat betekent dat hetzelfde woord dezelfde embedding heeft, ongeacht de context binnen een zin of document.
Deze beperking zorgt voor uitdagingen bij taken die een genuanceerd taalbegrip vereisen — zeker wanneer woorden verschillende contextuele betekenissen dragen. Het attention-mechanisme lost dit op door modellen in staat te stellen zich selectief te richten op relevante delen van de inputsequentie, en zo contextgevoeligheid in het representatieleren te brengen.
Attention stelt modellen in staat nuances en ambiguïteiten in taal te begrijpen, waardoor ze effectiever worden in het verwerken van complexe teksten. Enkele belangrijke voordelen zijn:
De impact van attention-gebaseerde taalmodellen is enorm geweest. Duizenden mensen gebruiken applicaties die op attention-modellen zijn gebouwd. Enkele van de populairste toepassingen zijn:
Nu we beter weten hoe attention werkt, kijken we naar self-attention en multi-head attention.
Self-attention stelt een model in staat om aandacht te besteden aan verschillende posities in zijn inputsequentie om een representatie van die sequentie te berekenen. Het laat het model het belang van elk woord in de sequentie wegen ten opzichte van andere woorden, waarbij afhankelijkheden tussen verschillende woorden in de input worden vastgelegd. Het mechanisme heeft drie hoofdelementen:
Attention-scores kunnen worden berekend door een geschaald inwendig product (dotproduct) te nemen tussen de query- en key-vectoren. Uiteindelijk worden deze scores vermenigvuldigd met de value-vectoren om een gewogen som van waarden te produceren.
Multi-head attention is een uitbreiding op het self-attention-mechanisme. Het vergroot het vermogen van het model om diverse contextuele informatie te vangen door gelijktijdig aandacht te besteden aan verschillende delen van de inputsequentie. Dit gebeurt door meerdere parallelle self-attention-bewerkingen uit te voeren, elk met een eigen set aangeleerde transformaties voor query, key en value.
Multi-head attention leidt tot fijnmaziger contextbegrip, meer robuustheid en expressiviteit.
Hoewel het implementeren van het attention-mechanisme meerdere voordelen heeft, brengt het ook eigen uitdagingen met zich mee, die in lopend onderzoek mogelijk worden aangepakt.
Attention-mechanismen vereisen het berekenen van paarsgewijze overeenkomsten tussen alle tokens in de inputsequentie, wat resulteert in kwadratische complexiteit ten opzichte van de sequentielength. Dit kan computationeel kostbaar zijn, vooral bij lange sequenties.
Er zijn diverse technieken voorgesteld om de computationele complexiteit te verminderen, zoals sparse attention-mechanismen, benaderende attention-methoden en efficiënte attention-technieken zoals locality-sensitive hashing in het Reformer-model.
Attention-mechanismen kunnen overfitten op ruis of irrelevante informatie in de inputsequentie, wat leidt tot suboptimale prestaties op ongeziene data.
Regularisatietechnieken, zoals dropout en layer normalization, kunnen overfitting in attention-gebaseerde modellen helpen voorkomen. Daarnaast zijn technieken zoals attention dropout en attention masking voorgesteld om het model te stimuleren zich op relevante informatie te richten.
Begrijpen hoe attention-mechanismen werken en hun output interpreteren kan lastig zijn, vooral in complexe modellen met meerdere lagen en attention-heads. Dit roept vragen op over de ethiek van deze nieuwe technologie — je kunt meer leren over AI-ethiek in onze cursus, of door te luisteren naar deze podcast met AI-onderzoeker dr. Joy Buolamwini.
Methoden voor het visualiseren van attention-gewichten en het interpreteren van hun betekenis zijn ontwikkeld om de uitlegbaarheid van attention-gebaseerde modellen te vergroten. Daarnaast streven technieken zoals attention-attributie ernaar om de bijdrage van afzonderlijke tokens aan de voorspellingen van het model te identificeren, wat de uitlegbaarheid verbetert.
Attention-mechanismen verbruiken aanzienlijk veel geheugen en rekenbronnen, waardoor opschalen naar grotere modellen en datasets een uitdaging is.
Technieken om attention-gebaseerde modellen te schalen, zoals hiërarchische attention, geheugenefficiënte attention en sparse attention, zijn erop gericht het geheugengebruik en de rekenlast te verminderen, terwijl de modelprestaties behouden blijven.
Laten we samenvatten wat we tot nu toe hebben geleerd door te focussen op de verschillen tussen traditionele en attention-gebaseerde modellen:
|
Kenmerk |
Attention-gebaseerde modellen |
Traditionele NLP-modellen |
|
Woordrepresentatie |
Contextbewuste embeddingvectoren (dynamisch gewogen op basis van attention-scores) |
Statische embeddingvectoren (één vector per woord, geen context) |
|
Focus |
Bekijkt omliggende woorden voor betekenis (kijkt naar de bredere context) |
Behandelt elk woord onafhankelijk |
|
Sterke punten |
Vangt lange-afstandsafhankelijkheden, lost ambiguïteit op, begrijpt nuances |
Eenvoudiger, rekenkundig goedkoper |
|
Zwakke punten |
Kan rekenkundig duur zijn |
Beperkt vermogen om complexe taal te begrijpen, worstelt met context |
|
Onderliggend mechanisme |
Encoder-decoder-netwerken met attention (verschillende architecturen) |
Technieken zoals parsing, stemming, named entity recognition, woordembeddings |
In dit artikel hebben we het attention-mechanisme verkend, een innovatie die NLP heeft getransformeerd. In tegenstelling tot eerdere methoden stelt attention taalmodellen in staat te focussen op cruciale delen van een zin, met inachtneming van context. Zo kunnen ze complexe taal, lange-afstandsrelaties en woordambiguïteit beter bevatten.
Je kunt verder leren over het attention-mechanisme door:
Aan de slag met deep learning!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
