Kurs
Einführung in Deep Learning mit PyTorch
4 Std.
86.1K
Sprache ist entscheidend für die menschliche Kommunikation, und sie zu automatisieren kann immense Vorteile bringen. Modelle zur Verarbeitung natürlicher Sprache (NLP) kämpften jahrelang darum, die Nuancen der menschlichen Sprache effektiv zu erfassen, bis ein Durchbruch gelang - der Aufmerksamkeitsmechanismus.
Der Aufmerksamkeitsmechanismus wurde 2017 in dem Papier Attention Is All You Need vorgestellt . Im Gegensatz zu traditionellen Methoden, die Wörter isoliert behandeln, wird bei der Aufmerksamkeit jedes Wort nach seiner Relevanz für die aktuelle Aufgabe gewichtet. So kann das Modell weitreichende Abhängigkeiten erfassen, lokale und globale Kontexte gleichzeitig analysieren und Mehrdeutigkeiten auflösen, indem es informative Teile des Satzes berücksichtigt.
Betrachte den folgenden Satz: Miami, auch die "magische Stadt" genannt, hat wunderschöne weiße Sandstrände. Traditionelle Modelle würden jedes Wort der Reihe nach verarbeiten. Der Aufmerksamkeitsmechanismus funktioniert jedoch eher wie unser Gehirn. Es weist jedem Wort eine Punktzahl zu, die auf seiner Relevanz für das Verständnis des aktuellen Schwerpunkts basiert. Wörter wie "Miami" und "Strände" werden wichtiger, wenn es um den Standort geht, und erhalten daher eine höhere Punktzahl.
In diesem Artikel geben wir eine intuitive Erklärung für den Aufmerksamkeitsmechanismus. Eine etwas technischere Herangehensweise findest du auch in diesem Tutorial über die Funktionsweise von Transformatoren. Lass uns gleich eintauchen!
Beginnen wir unsere Reise zum Verständnis des Aufmerksamkeitsmechanismus, indem wir den größeren Kontext der Sprachmodelle betrachten.
Sprachmodelle verarbeiten Sprache, indem sie versuchen, die grammatikalische Struktur (Syntax) und die Bedeutung (Semantik) zu verstehen. Das Ziel ist es, eine Sprache mit der richtigen Syntax und Semantik auszugeben, die für die Eingabe relevant ist.
Sprachmodelle stützen sich auf eine Reihe von Techniken, um Texte aufzuschlüsseln und zu verstehen:
Traditionelle Sprachmodelle ebneten zwar den Weg für die Fortschritte in der NLP, aber es war schwierig, die Komplexität der natürlichen Sprache vollständig zu erfassen:
Im Gegensatz zu traditionellen Modellen, die Wörter isoliert betrachten, können Sprachmodelle mit Aufmerksamkeit den Kontext berücksichtigen. Mal sehen, worum es hier geht!
Der Wendepunkt für das NLP-Feld kam 2017, als das Papier Attention Is All You Need den Aufmerksamkeitsmechanismus vorstellte.
In diesem Beitrag wird eine neue Architektur vorgeschlagen, die Transformator genannt wird. Im Gegensatz zu älteren Methoden wie rekurrenten neuronalen Netzen (RNNs) und faltigen neuronalen Netzen (CNNs) verwenden Transformatoren Aufmerksamkeitsmechanismen.
Durch die Lösung vieler Probleme traditioneller Modelle sind Transformatoren (und Aufmerksamkeit) die Grundlage für viele der heute populärsten großen Sprachmodelle (LLMs) wie GPT-4 und ChatGPT von OpenAI geworden.
Betrachten wir das Wort "Fledermaus" in diesen beiden Sätzen:
Herkömmliche Einbettungsmethoden weisen der "Fledermaus" eine einzige Vektordarstellung zu, was ihre Fähigkeit einschränkt, Bedeutungen zu unterscheiden. Aufmerksamkeitsmechanismen lösen dieses Problem jedoch, indem sie kontextabhängige Gewichtungen berechnen.
Sie analysieren die umgebenden Wörter ("Schaukel" versus "flog") und berechnen Aufmerksamkeitswerte, die die Relevanz bestimmen. Diese Werte werden dann verwendet, um die Einbettungsvektoren zu gewichten, was zu unterschiedlichen Darstellungen für "Fledermaus" als Sportgerät (hohe Gewichtung von "schwingen") oder als fliegendes Lebewesen (hohe Gewichtung von "flog") führt.
So kann das Modell semantische Nuancen erfassen und das Verständnis verbessern.
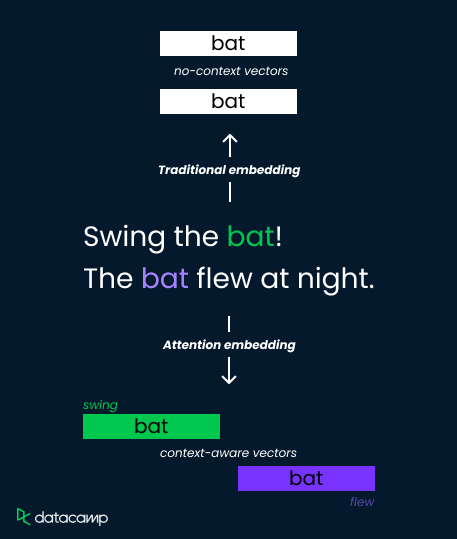
Bauen wir nun auf unserem intuitiven Verständnis von Aufmerksamkeit auf und erfahren wir, wie der Mechanismus über die traditionellen Worteinbettungen hinausgeht, um das Sprachverstehen zu verbessern. Wir werden uns auch ein paar praktische Anwendungen von Aufmerksamkeit ansehen.
Herkömmliche Worteinbettungstechniken wie Word2Vec und GloVe stellen Wörter als festdimensionale Vektoren in einem semantischen Raum dar, der auf der Statistik des gemeinsamen Vorkommens in einem großen Textkorpus basiert.
Diese Einbettungen erfassen zwar einige semantische Beziehungen zwischen Wörtern, aber es fehlt ihnen an Kontextsensitivität. Das bedeutet, dass ein und dasselbe Wort unabhängig von seinem Kontext innerhalb eines Satzes oder Dokuments die gleiche Einbettung hat.
Diese Einschränkung stellt bei Aufgaben, die ein differenziertes Sprachverständnis erfordern, eine Herausforderung dar - vor allem, wenn Wörter unterschiedliche kontextuelle Bedeutungen haben. Der Aufmerksamkeitsmechanismus löst dieses Problem, indem er es den Modellen ermöglicht, sich selektiv auf relevante Teile der Eingabesequenzen zu konzentrieren und so die Kontextsensitivität in den Repräsentationslernprozess einzubeziehen.
Aufmerksamkeit ermöglicht es den Modellen, Nuancen und Mehrdeutigkeiten in der Sprache zu verstehen, wodurch sie komplexe Texte effektiver verarbeiten können. Einige der wichtigsten Vorteile sind:
Die Auswirkungen von aufmerksamkeitsbasierten Sprachmodellen sind gewaltig. Tausende von Menschen nutzen Anwendungen, die auf aufmerksamkeitsbasierten Modellen basieren. Einige der beliebtesten Anwendungen sind:
Jetzt, wo wir mehr darüber wissen, wie Aufmerksamkeit funktioniert, wollen wir uns die Selbstaufmerksamkeit und die Mehrkopfaufmerksamkeit ansehen.
Die Selbstaufmerksamkeit ermöglicht es einem Modell, verschiedene Positionen seiner Eingabesequenz zu beachten, um eine Darstellung dieser Sequenz zu berechnen. Sie ermöglicht es dem Modell, die Bedeutung jedes Worts in der Sequenz im Verhältnis zu den anderen zu gewichten und so die Abhängigkeiten zwischen den verschiedenen Wörtern in der Eingabe zu erfassen. Der Mechanismus besteht aus drei Hauptelementen:
Die Aufmerksamkeitswerte können durch ein skaliertes Punktprodukt zwischen der Abfrage und den Schlüsselvektoren berechnet werden. Letztendlich werden diese Punktzahlen mit den Wertvektoren multipliziert, um eine gewichtete Summe der Werte zu erhalten.
Die Mehrkopfaufmerksamkeit ist eine Erweiterung des Mechanismus der Selbstaufmerksamkeit. Es verbessert die Fähigkeit des Modells, verschiedene Kontextinformationen zu erfassen, indem es gleichzeitig auf verschiedene Teile der Eingabesequenz achtet. Er erreicht dies, indem er mehrere parallele Self-Attention-Operationen durchführt, jede mit ihrem eigenen Satz an gelernten Abfrage-, Schlüssel- und Wertumwandlungen.
Aufmerksamkeit mit mehreren Köpfen führt zu einem feineren kontextuellen Verständnis, erhöhter Robustheit und Ausdrucksfähigkeit.
Die Umsetzung des Aufmerksamkeitsmechanismus hat zwar mehrere Vorteile, bringt aber auch eine Reihe von Herausforderungen mit sich, die durch die laufende Forschung möglicherweise gelöst werden können.
Bei den Aufmerksamkeitsmechanismen werden paarweise Ähnlichkeiten zwischen allen Token in der Eingabesequenz berechnet, was zu einer quadratischen Komplexität in Bezug auf die Sequenzlänge führt. Das kann sehr rechenintensiv sein, besonders bei langen Sequenzen.
Es wurden verschiedene Techniken vorgeschlagen, um die Rechenkomplexität zu verringern, z. B. spärliche Aufmerksamkeitsmechanismen, approximative Aufmerksamkeitsmethoden und effiziente Aufmerksamkeitsmechanismen wie das ortsabhängige Hashing des Reformer-Modells.
Aufmerksamkeitsmechanismen können verrauschte oder irrelevante Informationen in der Eingangssequenz überbewerten, was zu einer suboptimalen Leistung bei ungesehenen Daten führt.
Regularisierungstechniken wie Dropout und Layer-Normalisierung können helfen, eine Überanpassung in aufmerksamkeitsbasierten Modellen zu verhindern. Außerdem wurden Techniken wie Aufmerksamkeitsabschaltung und Aufmerksamkeitsmaskierung vorgeschlagen, um das Modell dazu zu bringen, sich auf relevante Informationen zu konzentrieren.
Zu verstehen, wie Aufmerksamkeitsmechanismen funktionieren und ihre Ergebnisse interpretieren, kann eine Herausforderung sein, insbesondere bei komplexen Modellen mit mehreren Schichten und Aufmerksamkeitsköpfen. Das wirft Fragen über die Ethik dieser neuen Technologie auf - du kannst mehr über KI-Ethik in unserem Kurs erfahren oder dir diesen Podcast mit dem KI-Forscher Dr. Joy Buolamwini.
Um die Interpretierbarkeit von aufmerksamkeitsbasierten Modellen zu verbessern, wurden Methoden zur Visualisierung von Aufmerksamkeitsgewichten und zur Interpretation ihrer Bedeutung entwickelt. Außerdem zielen Techniken wie die Aufmerksamkeitsattribution darauf ab, die Beiträge einzelner Token zu den Vorhersagen des Modells zu identifizieren und so die Erklärbarkeit zu verbessern.
Aufmerksamkeitsmechanismen verbrauchen viel Speicherplatz und Rechenressourcen, was es schwierig macht, sie auf größere Modelle und Datensätze zu übertragen.
Techniken zur Skalierung von aufmerksamkeitsbasierten Modellen, wie hierarchische Aufmerksamkeit, speichereffiziente Aufmerksamkeit und spärliche Aufmerksamkeit, zielen darauf ab, den Speicherverbrauch und den Rechenaufwand zu reduzieren und gleichzeitig die Leistung des Modells zu erhalten.
Fassen wir zusammen, was wir bisher gelernt haben, indem wir uns auf die Unterschiede zwischen traditionellen und aufmerksamkeitsbasierten Modellen konzentrieren:
|
Feature |
Aufmerksamkeitsbasierte Modelle |
Traditionelle NLP-Modelle |
|
Wortdarstellung |
Kontextabhängige Einbettungsvektoren (dynamisch gewichtet auf Basis von Aufmerksamkeitswerten) |
Statische Einbettungsvektoren (ein Vektor pro Wort, kein Kontext berücksichtigt) |
|
Focus |
Betrachtet die umliegenden Wörter auf ihre Bedeutung hin (im größeren Kontext) |
Behandelt jedes Wort unabhängig |
|
Stärken |
Erfasst weitreichende Abhängigkeiten, löst Mehrdeutigkeiten auf, versteht Nuancen |
Einfacher, rechnerisch günstiger |
|
Schwachstellen |
Kann rechenintensiv sein |
Begrenzte Fähigkeit, komplexe Sprache zu verstehen, Probleme mit dem Kontext |
|
Zugrunde liegender Mechanismus |
Encoder-Decoder-Netzwerke mit Aufmerksamkeit (verschiedene Architekturen) |
Techniken wie Parsing, Stemming, Named Entity Recognition, Worteinbettungen |
In diesem Artikel haben wir den Aufmerksamkeitsmechanismus untersucht, eine Innovation, die das NLP revolutioniert hat. Im Gegensatz zu früheren Methoden ermöglicht die Aufmerksamkeitsfunktion den Sprachmodellen, sich auf wichtige Teile eines Satzes zu konzentrieren und dabei den Kontext zu berücksichtigen. So können sie komplexe Sprache, weitreichende Zusammenhänge und mehrdeutige Wörter erfassen.
Du kannst dich weiter über den Aufmerksamkeitsmechanismus informieren:
Mach den Anfang mit Deep Learning!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Sejal Jaiswal
Tutorial
Mark Pedigo
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
