Curso
Introdução ao Aprendizado Profundo com o PyTorch
4 h
86.1K
A linguagem é fundamental para a comunicação humana, e automatizá-la pode trazer imensos benefícios. Os modelos de processamento de linguagem natural (PLN) lutaram durante anos para capturar com eficácia as nuances da linguagem humana, até que houve um avanço: o mecanismo de atenção.
O mecanismo de atenção foi apresentado em 2017 no artigo Attention Is All You Need. Diferentemente dos métodos tradicionais que tratam as palavras isoladamente, a atenção atribui pesos a cada palavra com base em sua relevância para a tarefa atual. Isso permite que o modelo capte dependências de longo alcance, analise contextos locais e globais simultaneamente e resolva ambiguidades atendendo a partes informativas da frase.
Considere a seguinte frase: "Miami, conhecida como a 'cidade mágica', tem belas praias de areia branca." Os modelos tradicionais processariam cada palavra em ordem. O mecanismo de atenção, no entanto, funciona mais como nosso cérebro. Ele atribui uma pontuação a cada palavra com base em sua relevância para a compreensão do foco atual. Palavras como "Miami" e "praias" tornam-se mais importantes ao considerar a localização, portanto, receberiam pontuações mais altas.
Neste artigo, forneceremos uma explicação intuitiva do mecanismo de atenção. Você também pode encontrar uma abordagem mais técnica neste tutorial sobre como os transformadores funcionam. Vamos mergulhar de cabeça!
Vamos começar nossa jornada para entender o mecanismo de atenção considerando o contexto mais amplo dos modelos de linguagem.
Os modelos de linguagem processam a linguagem tentando entender a estrutura gramatical (sintaxe) e o significado (semântica). O objetivo é produzir uma linguagem com a sintaxe e a semântica corretas que sejam relevantes para a entrada.
Os modelos de linguagem dependem de uma série de técnicas para decompor e entender o texto:
Embora os modelos de linguagem tradicionais tenham preparado o caminho para os avanços na PNL, eles enfrentaram desafios para compreender totalmente as complexidades da linguagem natural:
Ao contrário dos modelos tradicionais que tratam as palavras isoladamente, a atenção permite que os modelos de linguagem considerem o contexto. Vamos ver do que se trata!
A mudança de jogo para o campo da PNL ocorreu em 2017, quando o artigo Attention Is All You Need apresentou o mecanismo de atenção.
Este documento propôs uma nova arquitetura chamada de transformador. Diferentemente dos métodos mais antigos, como as redes neurais recorrentes (RNNs) e as redes neurais convolucionais (CNNs), os transformadores usam mecanismos de atenção.
Ao resolver muitos dos problemas dos modelos tradicionais, os transformadores (e a atenção) se tornaram a base de muitos dos modelos de linguagem grandes (LLMs) mais populares da atualidade, como o GPT-4 e o ChatGPT da OpenAI.
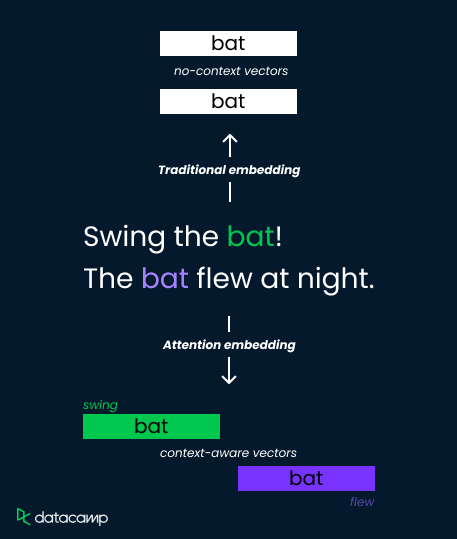
Vamos considerar a palavra "bat" nessas duas frases:
Os métodos tradicionais de incorporação atribuem uma única representação vetorial ao "bastão", limitando sua capacidade de distinguir o significado. Os mecanismos de atenção, no entanto, resolvem isso calculando pesos dependentes do contexto.
Eles analisam as palavras ao redor ("swing" versus "flew") e calculam as pontuações de atenção que determinam a relevância. Essas pontuações são então usadas para ponderar os vetores de incorporação, resultando em representações distintas para "bat" como uma ferramenta esportiva (peso alto em "swing") ou uma criatura voadora (peso alto em "flew").
Isso permite que o modelo capture nuances semânticas e melhore a compreensão.
Vamos agora nos basear em nosso entendimento intuitivo da atenção e aprender como o mecanismo vai além da tradicional incorporação de palavras para aprimorar a compreensão do idioma. Também veremos algumas aplicações da atenção no mundo real.
As técnicas tradicionais de incorporação de palavras, como Word2Vec e GloVe, representam palavras como vetores de dimensão fixa em um espaço semântico com base em estatísticas de co-ocorrência em um grande corpus de texto.
Embora esses embeddings capturem algumas relações semânticas entre as palavras, eles não são sensíveis ao contexto. Isso significa que a mesma palavra terá a mesma incorporação, independentemente de seu contexto em uma frase ou documento.
Essa limitação apresenta desafios em tarefas que exigem uma compreensão diferenciada da linguagem, especialmente quando as palavras têm significados contextuais diferentes. O mecanismo de atenção resolve esse problema, permitindo que os modelos se concentrem seletivamente em partes relevantes das sequências de entrada, incorporando, assim, a sensibilidade ao contexto no processo de aprendizado de representação.
A atenção permite que os modelos entendam as nuances e ambiguidades da linguagem, tornando-os mais eficientes no processamento de textos complexos. Alguns de seus principais benefícios são:
O impacto dos modelos de linguagem baseados em atenção tem sido enorme. Milhares de pessoas usam aplicativos criados com base em modelos baseados em atenção. Alguns dos aplicativos mais populares são:
Agora que você já está mais familiarizado com o funcionamento da atenção, vamos dar uma olhada na autoatenção e na atenção de várias cabeças.
A autoatenção permite que um modelo atenda a diferentes posições de sua sequência de entrada para calcular uma representação dessa sequência. Ele permite que o modelo pese a importância de cada palavra na sequência em relação às outras, capturando as dependências entre as diferentes palavras na entrada. O mecanismo tem três elementos principais:
As pontuações de atenção podem ser calculadas por meio de um produto escalonado de pontos entre a consulta e os vetores-chave. Por fim, essas pontuações são multiplicadas pelos vetores de valores para gerar uma soma ponderada de valores.
A atenção de várias cabeças é uma extensão do mecanismo de autoatenção. Ele aumenta a capacidade do modelo de capturar diversas informações contextuais ao atender simultaneamente a diferentes partes da sequência de entrada. Você consegue isso executando várias operações paralelas de autoatenção, cada uma com seu próprio conjunto de transformações aprendidas de consulta, chave e valor.
A atenção de várias cabeças leva a uma compreensão contextual mais refinada, maior robustez e expressividade.
Embora a implementação do mecanismo de atenção tenha vários benefícios, ela também traz seu próprio conjunto de desafios, que podem ser abordados por pesquisas em andamento.
Os mecanismos de atenção envolvem a computação de semelhanças de pares entre todos os tokens na sequência de entrada, resultando em uma complexidade quadrática em relação ao comprimento da sequência. Isso pode ser computacionalmente caro, especialmente para sequências longas.
Várias técnicas foram propostas para reduzir a complexidade computacional, como mecanismos de atenção esparsos, métodos de atenção aproximados e mecanismos de atenção eficientes, como o hashing sensível à localidade do modelo Reformer.
Os mecanismos de atenção podem se ajustar excessivamente a informações ruidosas ou irrelevantes na sequência de entrada, levando a um desempenho abaixo do ideal em dados não vistos.
As técnicas de regularização, como dropout e normalização de camadas, podem ajudar a evitar o ajuste excessivo em modelos baseados em atenção. Além disso, foram propostas técnicas como o abandono da atenção e o mascaramento da atenção para incentivar o modelo a se concentrar em informações relevantes.
Compreender como os mecanismos de atenção operam e interpretam seus resultados pode ser um desafio, principalmente em modelos complexos com várias camadas e cabeças de atenção. Isso levanta preocupações sobre a ética dessa nova tecnologia - você pode saber mais sobre a ética da IA em nosso curso ou ouvindo este podcast com o pesquisador de IA Dr. Joy Buolamwini.
Métodos para visualizar os pesos da atenção e interpretar seu significado foram desenvolvidos para aumentar a interpretabilidade dos modelos baseados em atenção. Além disso, técnicas como a atribuição de atenção visam identificar as contribuições de tokens individuais para as previsões do modelo, melhorando a explicabilidade.
Os mecanismos de atenção consomem recursos computacionais e de memória significativos, o que torna difícil dimensioná-los para modelos e conjuntos de dados maiores.
As técnicas de dimensionamento de modelos baseados em atenção, como atenção hierárquica, atenção com eficiência de memória e atenção esparsa, visam reduzir o consumo de memória e a sobrecarga computacional, mantendo o desempenho do modelo.
Vamos resumir o que aprendemos até agora, concentrando-nos nas diferenças entre os modelos tradicionais e os baseados em atenção:
|
Recurso |
Modelos baseados em atenção |
Modelos tradicionais de PNL |
|
Representação de palavras |
Vetores de incorporação com reconhecimento de contexto (ponderados dinamicamente com base em pontuações de atenção) |
Vetores de incorporação estáticos (um único vetor por palavra, sem considerar o contexto) |
|
Foco |
Considera o significado das palavras ao redor (observando o contexto mais amplo) |
Trata cada palavra de forma independente |
|
Pontos fortes |
Captura dependências de longo alcance, resolve ambiguidades, compreende nuances |
Mais simples, computacionalmente mais barato |
|
Pontos fracos |
Pode ser computacionalmente caro |
Capacidade limitada de entender linguagem complexa, dificuldades com o contexto |
|
Mecanismo subjacente |
Redes de codificador-decodificador com atenção (várias arquiteturas) |
Técnicas como análise, stemming, reconhecimento de entidades nomeadas, incorporação de palavras |
Neste artigo, exploramos o mecanismo de atenção, uma inovação que revolucionou a PNL. Diferentemente dos métodos anteriores, a atenção permite que os modelos de linguagem se concentrem em partes cruciais de uma frase, considerando o contexto. Isso permite que eles compreendam a linguagem complexa, as conexões de longo alcance e a ambiguidade das palavras.
Você pode continuar aprendendo sobre o mecanismo de atenção:
Comece a usar a aprendizagem profunda!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Dimitri Didmanidze
7 min
blog
Stanislav Karzhev
9 min
blog
Laiba Siddiqui
13 min
blog
Matt Crabtree
11 min
Tutorial
Josep Ferrer