Curso
Introducción al aprendizaje profundo con PyTorch
4 h
85.8K
El lenguaje es crucial para la comunicación humana, y automatizarlo puede aportar inmensos beneficios. Los modelos de procesamiento del lenguaje natural (PLN) lucharon durante años para captar eficazmente los matices del lenguaje humano, hasta que se produjo un gran avance: el mecanismo de la atención.
El mecanismo de la atención se introdujo en 2017 en el documento La atención es todo lo que necesitas. A diferencia de los métodos tradicionales que tratan las palabras de forma aislada, la atención asigna pesos a cada palabra en función de su relevancia para la tarea actual. Esto permite al modelo captar las dependencias de largo alcance, analizar simultáneamente los contextos local y global, y resolver las ambigüedades atendiendo a las partes informativas de la frase.
Considera la siguiente frase: "Miami, acuñada como la "ciudad mágica", tiene hermosas playas de arena blanca". Los modelos tradicionales procesarían cada palabra en orden. El mecanismo de atención, sin embargo, actúa más como nuestro cerebro. Asigna una puntuación a cada palabra en función de su relevancia para comprender el enfoque actual. Palabras como "Miami" y "playas" son más importantes cuando se considera la ubicación, por lo que recibirían puntuaciones más altas.
En este artículo, daremos una explicación intuitiva del mecanismo de la atención. También puedes encontrar un enfoque más técnico en este tutorial sobre cómo funcionan los transformadores. ¡Sumerjámonos de lleno!
Empecemos nuestro viaje para comprender el mecanismo de la atención considerando el contexto más amplio de los modelos lingüísticos.
Los modelos lingüísticos procesan el lenguaje intentando comprender la estructura gramatical (sintaxis) y el significado (semántica). El objetivo es producir un lenguaje con la sintaxis y la semántica correctas que sean relevantes para la entrada.
Los modelos lingüísticos se basan en una serie de técnicas para descomponer y comprender el texto:
Aunque los modelos lingüísticos tradicionales allanaron el camino para los avances en la PNL, se enfrentaron a retos a la hora de comprender plenamente las complejidades del lenguaje natural:
A diferencia de los modelos tradicionales que tratan las palabras de forma aislada, la atención permite que los modelos lingüísticos tengan en cuenta el contexto. ¡Veamos de qué se trata!
El cambio de juego para el campo de la PNL se produjo en 2017, cuando el documento La atención es todo lo que necesitas introdujo el mecanismo de la atención.
Este artículo propone una nueva arquitectura denominada transformador. A diferencia de métodos más antiguos, como las redes neuronales recurrentes (RNN) y las redes neuronales convolucionales (CNN), los transformadores utilizan mecanismos de atención.
Al resolver muchos de los problemas de los modelos tradicionales, los transformadores (y la atención) se han convertido en la base de muchos de los grandes modelos lingüísticos (LLM) más populares de la actualidad, como el GPT-4 y el ChatGPT de OpenAI.
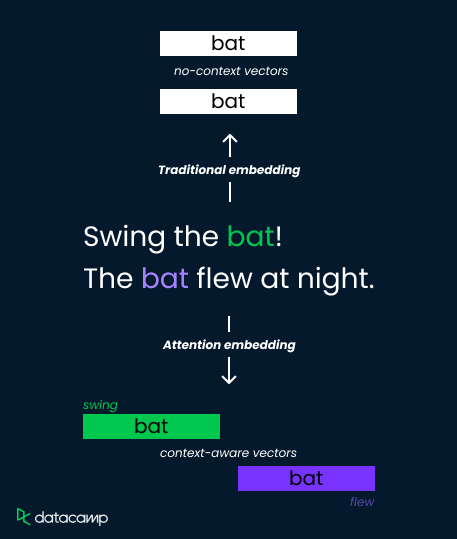
Consideremos la palabra "murciélago" en estas dos frases:
Los métodos tradicionales de incrustación asignan una única representación vectorial al "murciélago", lo que limita su capacidad para distinguir significados. Sin embargo, los mecanismos de atención lo solucionan calculando pesos dependientes del contexto.
Analizan las palabras circundantes ("columpio" frente a "voló") y calculan puntuaciones de atención que determinan la relevancia. A continuación, estas puntuaciones se utilizan para ponderar los vectores de incrustación, lo que da lugar a representaciones distintas del "bate" como herramienta deportiva (mayor peso en "swing") o como criatura voladora (mayor peso en "voló").
Esto permite que el modelo capte los matices semánticos y mejore la comprensión.
Basémonos ahora en nuestra comprensión intuitiva de la atención y aprendamos cómo el mecanismo va más allá de las incrustaciones de palabras tradicionales para mejorar la comprensión del lenguaje. También veremos algunas aplicaciones de la atención en el mundo real.
Las técnicas tradicionales de incrustación de palabras, como Word2Vec y GloVe, representan las palabras como vectores de dimensión fija en un espacio semántico basado en estadísticas de co-ocurrencia en un gran corpus de texto.
Aunque estas incrustaciones captan algunas relaciones semánticas entre las palabras, carecen de sensibilidad al contexto. Esto significa que la misma palabra tendrá la misma incrustación independientemente de su contexto dentro de una frase o documento.
Esta limitación plantea retos en tareas que requieren una comprensión matizada del lenguaje, especialmente cuando las palabras conllevan diferentes significados contextuales. El mecanismo de atención resuelve este problema permitiendo a los modelos centrarse selectivamente en las partes relevantes de las secuencias de entrada, incorporando así la sensibilidad al contexto en el proceso de aprendizaje de la representación.
La atención permite a los modelos comprender los matices y ambigüedades del lenguaje, lo que les hace más eficaces en el procesamiento de textos complejos. Algunas de sus principales ventajas son:
El impacto de los modelos lingüísticos basados en la atención ha sido tremendo. Miles de personas utilizan aplicaciones construidas sobre modelos basados en la atención. Algunas de las aplicaciones más populares son:
Ahora que ya sabemos cómo funciona la atención, veamos la autoatención y la atención multicabeza.
La autoatención permite a un modelo atender a distintas posiciones de su secuencia de entrada para calcular una representación de esa secuencia. Permite que el modelo pondere la importancia de cada palabra de la secuencia en relación con las demás, captando las dependencias entre las distintas palabras de la entrada. El mecanismo tiene tres elementos principales:
Las puntuaciones de atención pueden calcularse haciendo un producto escalar de puntos entre la consulta y los vectores clave. Finalmente, estas puntuaciones se multiplican por los vectores de valores para obtener una suma ponderada de valores.
La atención multicabeza es una ampliación del mecanismo de autoatención. Aumenta la capacidad del modelo para captar información contextual diversa, atendiendo simultáneamente a distintas partes de la secuencia de entrada. Lo consigue realizando múltiples operaciones paralelas de autoatención, cada una con su propio conjunto de transformaciones aprendidas de consulta, clave y valor.
La atención multicabezal conduce a una comprensión contextual más fina, mayor robustez y expresividad.
Aunque la aplicación del mecanismo de atención tiene varias ventajas, también conlleva su propio conjunto de retos, que la investigación en curso puede abordar potencialmente.
Los mecanismos de atención implican el cálculo de similitudes por pares entre todos los tokens de la secuencia de entrada, lo que da lugar a una complejidad cuadrática con respecto a la longitud de la secuencia. Esto puede ser costoso desde el punto de vista informático, especialmente para secuencias largas.
Se han propuesto varias técnicas para mitigar la complejidad computacional, como los mecanismos de atención dispersa, los métodos de atención aproximada y los mecanismos de atención eficientes, como el hashing sensible a la localidad del modelo Reformer.
Los mecanismos de atención pueden sobreajustar la información ruidosa o irrelevante de la secuencia de entrada, lo que conduce a un rendimiento subóptimo en los datos no vistos.
Las técnicas de regularización, como el abandono y la normalización de capas, pueden ayudar a evitar el sobreajuste en los modelos basados en la atención. Además, se han propuesto técnicas como el abandono de la atención y el enmascaramiento de la atención para animar al modelo a centrarse en la información relevante.
Comprender cómo funcionan los mecanismos de atención e interpretar sus resultados puede ser un reto, sobre todo en modelos complejos con múltiples capas y cabezas de atención. Esto suscita inquietudes sobre la ética de esta nueva tecnología - puedes aprender más sobre la ética de la IA en nuestro curso, o escuchando este podcast de con el investigador de IA Dr. Joy Buolamwini.
Se han desarrollado métodos para visualizar los pesos de la atención e interpretar su significado, con el fin de mejorar la interpretabilidad de los modelos basados en la atención. Además, técnicas como la atribución de atención pretenden identificar las contribuciones de fichas individuales a las predicciones del modelo, mejorando la explicabilidad.
Los mecanismos de atención consumen mucha memoria y recursos informáticos, lo que dificulta su ampliación a modelos y conjuntos de datos más grandes.
Las técnicas para escalar los modelos basados en la atención, como la atención jerárquica, la atención eficiente en memoria y la atención dispersa, pretenden reducir el consumo de memoria y la sobrecarga computacional, manteniendo al mismo tiempo el rendimiento del modelo.
Resumamos lo que hemos aprendido hasta ahora centrándonos en las diferencias entre los modelos tradicionales y los basados en la atención:
|
Función |
Modelos basados en la atención |
Modelos tradicionales de PNL |
|
Representación de palabras |
Vectores de incrustación sensibles al contexto (ponderados dinámicamente en función de las puntuaciones de atención) |
Vectores de incrustación estáticos (un único vector por palabra, sin tener en cuenta el contexto) |
|
Enfoque |
Considera el significado de las palabras circundantes (mirando el contexto más amplio) |
Trata cada palabra de forma independiente |
|
Puntos fuertes |
Capta las dependencias de largo alcance, resuelve la ambigüedad, comprende los matices |
Más sencillo, computacionalmente más barato |
|
Puntos débiles |
Puede ser costoso computacionalmente |
Capacidad limitada para comprender un lenguaje complejo, dificultades con el contexto |
|
Mecanismo subyacente |
Redes codificador-decodificador con atención (varias arquitecturas) |
Técnicas como el análisis sintáctico, el stemming, el reconocimiento de entidades con nombre, la incrustación de palabras |
En este artículo exploramos el mecanismo de la atención, una innovación que revolucionó la PNL. A diferencia de los métodos anteriores, la atención permite a los modelos lingüísticos centrarse en las partes cruciales de una frase, teniendo en cuenta el contexto. Esto les permite captar el lenguaje complejo, las conexiones de largo alcance y la ambigüedad de las palabras.
Puedes seguir aprendiendo sobre el mecanismo de la atención:
¡Empieza con el Aprendizaje Profundo!
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Dimitri Didmanidze
7 min
blog
Laiba Siddiqui
13 min
blog
Stanislav Karzhev
12 min
blog
Bhavishya Pandit
8 min
Tutorial
Josep Ferrer