Kursus
Pengantar Deep Learning dengan PyTorch
4 Hr
85.8K
Bahasa sangat penting bagi komunikasi manusia, dan mengotomatiskannya dapat membawa manfaat besar. Model pemrosesan bahasa alami (NLP) selama bertahun-tahun kesulitan menangkap nuansa bahasa manusia secara efektif hingga terjadi terobosan — mekanisme attention.
Mekanisme attention diperkenalkan pada 2017 dalam makalah Attention Is All You Need. Berbeda dari metode tradisional yang memperlakukan kata secara terpisah, attention memberikan bobot pada setiap kata berdasarkan relevansinya dengan tugas saat ini. Ini memungkinkan model menangkap ketergantungan jarak jauh, menganalisis konteks lokal dan global secara bersamaan, serta menyelesaikan ambiguitas dengan memusatkan perhatian pada bagian kalimat yang informatif.
Pertimbangkan kalimat berikut: "Miami, dijuluki 'kota ajaib', memiliki pantai berpasir putih yang indah." Model tradisional akan memproses setiap kata secara berurutan. Mekanisme attention, bagaimanapun, bertindak lebih seperti otak kita. Ia memberikan skor pada setiap kata berdasarkan relevansinya untuk memahami fokus saat ini. Kata seperti "Miami" dan "pantai" menjadi lebih penting saat mempertimbangkan lokasi, sehingga akan menerima skor lebih tinggi.
Dalam artikel ini, kami akan memberikan penjelasan intuitif tentang mekanisme attention. Anda juga dapat menemukan pendekatan yang lebih teknis dalam tutorial ini tentang cara kerja transformer. Mari kita mulai!
Mari mulai perjalanan memahami mekanisme attention dengan mempertimbangkan konteks yang lebih luas dari model bahasa.
Model bahasa memproses bahasa dengan mencoba memahami struktur gramatikal (sintaksis) dan makna (semantik). Tujuannya adalah menghasilkan bahasa dengan sintaksis dan semantik yang benar serta relevan dengan masukan.
Model bahasa mengandalkan serangkaian teknik untuk mengurai dan memahami teks:
Meski model bahasa tradisional membuka jalan bagi kemajuan NLP, model tersebut menghadapi tantangan dalam memahami sepenuhnya kompleksitas bahasa alami:
Berbeda dari model tradisional yang memperlakukan kata secara terpisah, attention memungkinkan model bahasa mempertimbangkan konteks. Mari lihat lebih jauh!
Perubahan besar bagi bidang NLP datang pada 2017 ketika makalah Attention Is All You Need memperkenalkan mekanisme attention.
Makalah ini mengusulkan arsitektur baru bernama transformer. Berbeda dari metode lama seperti recurrent neural network (RNN) dan convolutional neural network (CNN), transformer menggunakan mekanisme attention.
Dengan menyelesaikan banyak masalah model tradisional, transformer (dan attention) menjadi fondasi bagi banyak model bahasa besar (LLM) paling populer saat ini, seperti GPT-4 milik OpenAI dan ChatGPT.
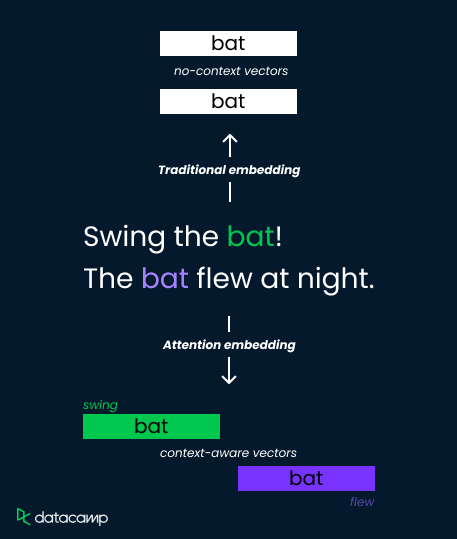
Mari pertimbangkan kata “bat” dalam dua kalimat berikut:
Metode embedding tradisional memberikan satu representasi vektor untuk “bat,” yang membatasi kemampuannya membedakan makna. Namun, mekanisme attention mengatasi ini dengan menghitung bobot yang bergantung pada konteks.
Mereka menganalisis kata-kata di sekitarnya ("swing" versus "flew") dan menghitung skor attention yang menentukan relevansi. Skor ini kemudian digunakan untuk membobotkan vektor embedding, menghasilkan representasi berbeda untuk "bat" sebagai alat olahraga (bobot tinggi pada "swing") atau sebagai hewan terbang (bobot tinggi pada "flew").
Ini memungkinkan model menangkap nuansa semantik dan meningkatkan pemahaman.
Sekarang mari membangun pemahaman intuitif kita tentang attention dan mempelajari bagaimana mekanisme ini melampaui word embedding tradisional untuk meningkatkan pemahaman bahasa. Kita juga akan melihat beberapa penerapan attention di dunia nyata.
Teknik word embedding tradisional, seperti Word2Vec dan GloVe, merepresentasikan kata sebagai vektor berdimensi tetap dalam ruang semantik berdasarkan statistik ko-kemunculan dalam korpus teks yang besar.
Meski embedding ini menangkap beberapa hubungan semantik antarkata, embedding tersebut tidak peka konteks. Artinya, kata yang sama akan memiliki embedding yang sama terlepas dari konteksnya dalam kalimat atau dokumen.
Keterbatasan ini menimbulkan tantangan pada tugas yang memerlukan pemahaman bahasa yang bernuansa — terutama ketika kata membawa makna kontekstual yang berbeda. Mekanisme attention memecahkan masalah ini dengan memungkinkan model fokus secara selektif pada bagian-bagian relevan dari urutan masukan, sehingga memasukkan kepekaan konteks ke dalam proses pembelajaran representasi.
Attention memungkinkan model memahami nuansa dan ambiguitas dalam bahasa, sehingga lebih efektif memproses teks yang kompleks. Beberapa manfaat utamanya adalah:
Dampak model bahasa berbasis attention sangat besar. Ribuan orang menggunakan aplikasi yang dibangun di atas model berbasis attention. Beberapa aplikasi paling populer adalah:
Sekarang setelah kita lebih akrab dengan cara kerja attention, mari lihat self-attention dan multi-head attention.
Self-attention memungkinkan model memerhatikan berbagai posisi dalam urutan masukannya untuk menghitung representasi dari urutan tersebut. Ini memungkinkan model menimbang pentingnya setiap kata dalam urutan relatif terhadap yang lain, menangkap ketergantungan antar kata berbeda dalam masukan. Mekanisme ini memiliki tiga elemen utama:
Skor attention dapat dihitung dengan melakukan perkalian titik berskala antara vektor query dan key. Pada akhirnya, skor ini dikalikan dengan vektor value untuk menghasilkan jumlah berbobot dari value.
Multi-head attention adalah perluasan dari mekanisme self-attention. Ini meningkatkan kemampuan model untuk menangkap informasi kontekstual yang beragam dengan secara simultan memerhatikan bagian-bagian berbeda dari urutan masukan. Hal ini dicapai dengan melakukan beberapa operasi self-attention paralel, masing-masing dengan seperangkat transformasi query, key, dan value yang dipelajari sendiri.
Multi-head attention menghasilkan pemahaman konteks yang lebih halus, peningkatan ketangguhan, dan daya ekspresif.
Meskipun penerapan mekanisme attention memiliki sejumlah manfaat, mekanisme ini juga hadir dengan tantangannya sendiri, yang dapat ditangani oleh penelitian yang sedang berlangsung.
Mekanisme attention melibatkan perhitungan kemiripan berpasangan antara semua token dalam urutan masukan, menghasilkan kompleksitas kuadrat terhadap panjang urutan. Ini bisa mahal secara komputasi, terutama untuk urutan yang panjang.
Berbagai teknik telah diajukan untuk mengurangi kompleksitas komputasi, seperti mekanisme attention jarang (sparse), metode attention pendekatan (approximate), dan mekanisme attention efisien seperti locality-sensitive hashing pada model Reformer.
Mekanisme attention dapat melakukan overfitting pada informasi yang bising atau tidak relevan dalam urutan masukan, yang mengarah pada kinerja suboptimal pada data yang belum pernah dilihat.
Teknik regularisasi, seperti dropout dan normalisasi lapisan, dapat membantu mencegah overfitting pada model berbasis attention. Selain itu, teknik seperti attention dropout dan attention masking telah diajukan untuk mendorong model fokus pada informasi yang relevan.
Memahami bagaimana mekanisme attention beroperasi dan menafsirkan keluarannya bisa menantang, khususnya dalam model kompleks dengan banyak lapisan dan head attention. Ini menimbulkan kekhawatiran tentang etika teknologi baru ini — Anda dapat mempelajari lebih lanjut tentang etika AI dalam kursus kami, atau dengan mendengarkan podcast bersama peneliti AI Dr. Joy Buolamwini ini.
Metode untuk memvisualisasikan bobot attention dan menafsirkan maknanya telah dikembangkan untuk meningkatkan interpretabilitas model berbasis attention. Selain itu, teknik seperti atribusi attention bertujuan mengidentifikasi kontribusi token individual terhadap prediksi model, sehingga meningkatkan keterjelasan.
Mekanisme attention mengonsumsi sumber daya memori dan komputasi yang signifikan, sehingga menantang untuk diskalakan ke model dan dataset yang lebih besar.
Teknik untuk menskalakan model berbasis attention, seperti attention hierarkis, attention hemat memori, dan attention jarang, bertujuan mengurangi konsumsi memori dan beban komputasi sambil mempertahankan kinerja model.
Mari kita rangkum apa yang telah kita pelajari sejauh ini dengan berfokus pada perbedaan antara model tradisional dan model berbasis attention:
|
Fitur |
Model Berbasis Attention |
Model NLP Tradisional |
|
Representasi Kata |
Vektor embedding peka konteks (dibobot secara dinamis berdasarkan skor attention) |
Vektor embedding statis (satu vektor per kata, tanpa mempertimbangkan konteks) |
|
Fokus |
Mempertimbangkan kata-kata di sekitarnya untuk makna (melihat konteks yang lebih luas) |
Memperlakukan setiap kata secara independen |
|
Kekuatan |
Menangkap ketergantungan jarak jauh, menyelesaikan ambiguitas, memahami nuansa |
Lebih sederhana, lebih murah secara komputasi |
|
Kelemahan |
Dapat mahal secara komputasi |
Kemampuan terbatas memahami bahasa kompleks, kesulitan dengan konteks |
|
Mekanisme yang Mendasari |
Jaringan encoder-decoder dengan attention (berbagai arsitektur) |
Teknik seperti parsing, stemming, named entity recognition, word embedding |
Dalam artikel ini, kita mengeksplorasi mekanisme attention, sebuah inovasi yang merevolusi NLP. Berbeda dari metode sebelumnya, attention memungkinkan model bahasa fokus pada bagian krusial dari sebuah kalimat dengan mempertimbangkan konteks. Ini membuat mereka mampu memahami bahasa yang kompleks, koneksi jarak jauh, dan ambiguitas kata.
Anda dapat terus mempelajari mekanisme attention dengan:
Mulai belajar Deep Learning!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
