
Program
Microsoft Azure Temelleri (AZ-900)
9 sa
Azure Data Factory (ADF), Microsoft Azure tarafından sunulan bulut tabanlı bir veri entegrasyonu hizmetidir.
Veriye dayalı karar alma, iş operasyonlarının merkezine yerleştikçe bulut tabanlı veri mühendisliği araçlarına olan talep hiç olmadığı kadar yüksek! ADF önde gelen bir hizmet olduğundan, şirketler veri hatlarını yönetmek ve sistemlerini entegre etmek için uygulamalı deneyime sahip veri profesyonellerini giderek daha fazla arıyor.
Bu yazıda, ADF alanında kariyer hedefleyenlere temel Azure Data Factory mülakat soruları ve cevapları konusunda rehberlik etmeyi; genel, teknik, ileri düzey ve senaryo tabanlı soruları kapsarken mülakatta başarıya ulaşmanız için ipuçları sunmayı amaçlıyoruz.
Azure Data Factory, veri hareketi ve dönüşümünü düzenlemek ve otomatikleştirmek için veri odaklı iş akışları oluşturmanızı sağlayan bulut tabanlı bir ETL hizmetidir. Hizmet, hem şirket içi ortamda hem de bulutta çeşitli veri kaynakları ve hedeflerle entegre olur.
Ekipler bulut-yerel altyapılara geçtikçe, farklı ortamlardaki verileri yönetme ihtiyacı artıyor. ADF’nin Azure ekosistemi ve üçüncü taraf veri kaynaklarıyla entegrasyonu bunu kolaylaştırır; bu da hizmette uzmanlığı, kurumlar tarafından son derece talep edilen bir yetkinlik haline getirir.
Azure Data Factory kullanılarak otomatikleştirilmiş BI mimarisi. Görsel kaynağı: Microsoft
Bu bölümde, ADF’ye ilişkin genel bilginizi ölçmek için mülakatlarda sıkça sorulan temel sorulara odaklanacağız. Bu sorular, temel kavramlar, mimari ve bileşenlere ilişkin anlayışınızı test eder.
Açıklama: Bu soru, ADF’nin yapı taşlarını anlayıp anlamadığınızı değerlendirmek için sıklıkla sorulur.
Örnek cevap: Azure Data Factory’nin başlıca bileşenleri şunlardır:
Açıklama: Bu soru, Azure Data Factory’nin hibrit veri hareketini güvenli ve verimli şekilde nasıl sağladığına dair anlayışınızı test eder.
Örnek cevap: Azure Data Factory, bulut ve şirket içi ortamlar arasında güvenli veri hareketini, ADF ile şirket içi veri kaynakları arasında köprü görevi gören Self-hosted Integration Runtime (IR) aracılığıyla sağlar.
Örneğin, bir şirket içi SQL Server’dan Azure Blob Storage’a veri taşınırken, self-hosted IR şirket içi sisteme güvenli bir şekilde bağlanır. Bu sayede ADF, hem aktarım sırasında hem de bekleme halinde şifreleme sağlayarak veriyi güvenli biçimde aktarır. Bu yaklaşım, verinin şirket içi ve bulut altyapıları arasında dağıtıldığı hibrit bulut senaryolarında özellikle faydalıdır.
Açıklama: Bu soru, ADF’nin farklı tetikleyici türleriyle boru hatlarını nasıl otomatikleştirdiğini ve zamanladığını kavrayıp kavramadığınızı ölçer.
Örnek cevap: Azure Data Factory’de tetikleyiciler, belirli koşullar veya zamanlamalar temelinde boru hattı yürütmelerini otomatik olarak başlatmak için kullanılır. Üç ana tetikleyici türü vardır:
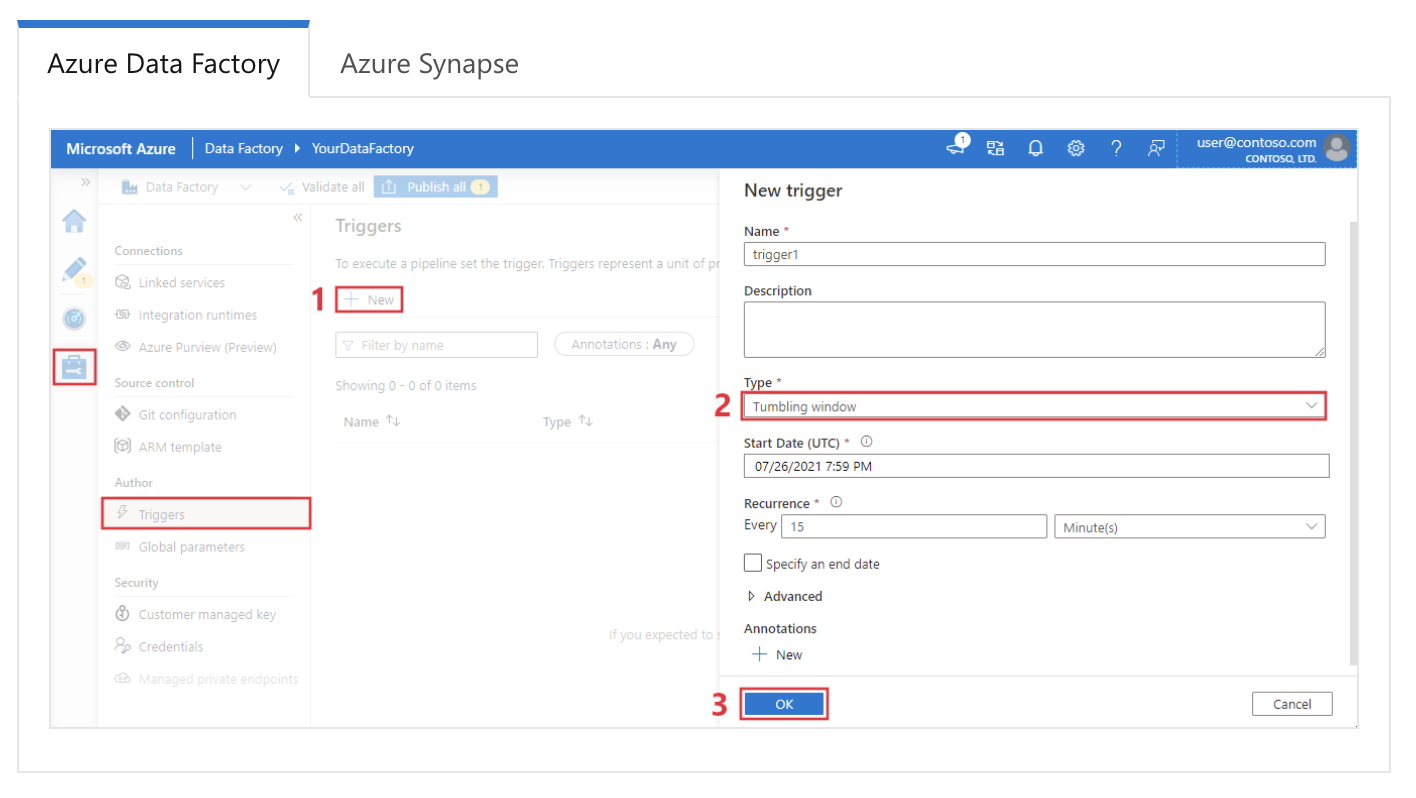
Azure Data Factory’de tumbling window tetikleyicisinin yapılandırılması. Görsel kaynağı: Microsoft.
Açıklama: Bu soru, ADF boru hatlarının gerçekleştirebileceği çeşitli görevler konusundaki bilginizi değerlendirir.
Örnek cevap: Azure Data Factory boru hatları çeşitli aktivite türlerini destekler. En yaygın olanlar şunlardır:
|
Aktivite türü |
Açıklama |
|
Veri hareketi |
Copy Activity ile desteklenen veri depoları (ör. Azure Blob Storage, SQL Database) arasında veri taşır. |
|
Veri dönüşümü |
Spark kullanan Data Flow Activity ile dönüşüm mantığı, ETL işlemleri için Mapping Data Flows ve veri hazırlığı için Wrangling Data Flows içerir. |
|
Kontrol akışı |
ForEach, If Condition, Switch, Wait ve Until gibi aktivitelerle koşullu mantık oluşturarak boru hattı yürütmesini kontrol eder. |
|
Harici yürütme |
Azure Functions, Web Activities (REST API çağrıları) ve SQL için Stored Procedure Activities dahil olmak üzere harici uygulama veya fonksiyonları çalıştırır. |
|
Özel aktiviteler |
Gelişmiş veri işleme ihtiyaçları için esneklik sağlayan, .NET veya Azure Batch hizmetlerini kullanarak Custom Activity’de özel kod çalıştırılmasına olanak tanır. |
|
Diğer hizmetler |
Karmaşık veri görevleri için diğer Azure analiz hizmetleriyle entegrasyon sağlayan HDInsight, Databricks ve Data Lake Analytics aktivitelerini destekler. |
Açıklama: Bu soru, ADF’nin izleme ve hata ayıklama araçlarına aşinalığınızı kontrol eder.
Örnek cevap: Azure Data Factory, Azure portalındaki Monitor sekmesi aracılığıyla kapsamlı bir izleme ve hata ayıklama arayüzü sunar. Burada boru hattı çalıştırmalarını takip eder, aktivite durumlarını görüntüler ve hataları teşhis ederim. Her aktivite log üretir; bu loglar hataları belirlemek ve sorun gidermek için incelenebilir.
Ek olarak, Azure Monitor, boru hattı hataları veya performans sorunlarına göre uyarılar gönderecek şekilde yapılandırılabilir. Hata ayıklamada genellikle önce başarısız olan aktivitelerin loglarına bakar, hata ayrıntılarını inceler ve sorunu düzelttikten sonra boru hattını yeniden çalıştırırım.
Açıklama: Bu soru, Microsoft’un en güncel veri platformu evrimine ne kadar hâkim olduğunuzu test eder.
Örnek cevap: İkisi de aynı motoru paylaşsa da, Fabric’teki Data Factory, Fabric ekosistemine entegre bir SaaS (Hizmet olarak Yazılım) sunumudur; Azure Data Factory (ADF) ise bir PaaS (Hizmet Olarak Platform) kaynağıdır. Temel farklar şunlardır:
Açıklama: Bu soru, verinin yaşam döngüsü boyunca korunmasına yönelik ADF güvenlik mekanizmaları hakkındaki bilginizi ölçer.
Örnek cevap: Azure Data Factory, çeşitli mekanizmalarla veri güvenliğini sağlar.
Öncelikle, hem aktarım sırasında hem de bekleme halinde veriyi şifrelemek için TLS ve AES gibi protokoller kullanılır. ADF, kimlik doğrulama için Azure Active Directory (AAD) ile entegre olur ve fabrikaya kimin erişebileceğini ve yönetebileceğini sınırlamak için Rol Tabanlı Erişim Denetimi (RBAC) uygular.
Ayrıca, Managed Identity’ler ADF’nin kimlik bilgilerini açığa çıkarmadan diğer Azure hizmetlerine güvenli erişim sağlamasına imkân tanır. Ağ güvenliği için ADF, verinin Azure ağı içinde kalmasını sağlayan Private Endpoint’leri destekler ve ek bir koruma katmanı sunar.
Açıklama: Bu soru, ADF’de Linked Services ve Datasets’in farklı rollerini ne kadar anladığınızı değerlendirir.
Örnek cevap: Azure Data Factory’de Linked Service, bir bağlantı dizgesine benzer şekilde harici bir veri kaynağına veya hesaplama hizmetine bağlantıyı tanımlar. Kaynağa bağlanmak için gerekli kimlik doğrulama bilgilerini içerir.
Dataset ise üzerinde çalışacağınız belirli veriyi temsil eder; örneğin bir veritabanındaki tablo veya Blob Storage’daki bir dosya.
Linked Service, verinin nerede olduğunu tanımlarken Dataset, verinin nasıl göründüğünü ve nasıl yapılandığını açıklar. Bu iki bileşen, veri hareketi ve dönüşümünü sağlamak için birlikte çalışır.
Teknik mülakat soruları genellikle belirli özelliklere, bunların uygulamalarına ve etkili veri boru hatları oluşturmak için nasıl birlikte çalıştıklarına ilişkin anlayışınıza odaklanır. Bu sorular, ADF’nin temel bileşenleri ve yetenekleri konusundaki uygulamalı deneyiminizi ve bilginizi değerlendirir.
Açıklama: Bu soru, ADF boru hatlarında hata yönetimi stratejileri uygulama becerinizi test eder.
Örnek cevap: Azure Data Factory’de hata yönetimi, Yeniden Deneme İlkeleri ve Hata Yönetimi Aktiviteleri kullanılarak uygulanabilir. ADF, bir aktivite başarısız olduğunda yeniden deneme sayısını ve denemeler arası aralığı yapılandırabileceğiniz yerleşik yeniden deneme mekanizmaları sunar.
Örneğin, Copy Activity geçici bir ağ sorunu nedeniyle başarısız olursa, aktiviteyi her deneme arasında 10 dakikalık arayla 3 kez yeniden denenecek şekilde yapılandırabilirsiniz.
Buna ek olarak, Failure, Completion ve Skipped gibi Aktivite Bağımlılık Koşullarını ayarlayarak bir aktivitenin başarılı olup olmamasına göre belirli eylemleri tetikleyebilirsiniz.
Örneğin, bir aktivite başarısız olduğunda uyarı göndermek veya bir geri dönüş sürecini çalıştırmak gibi özel bir hata yönetimi aktivitesinin yürütülmesini sağlayacak bir boru hattı akışı tanımlayabilirim.
Açıklama: Bu soru, ADF’de veri hareketi ve aktivite yönlendirmesinin arkasındaki hesaplama altyapısını anlama düzeyinizi değerlendirir.
Örnek cevap: Integration Runtime (IR), Azure Data Factory’nin veri hareketi, dönüşümü ve aktivite yönlendirmesini gerçekleştirmek için kullandığı hesaplama altyapısıdır. Verinin nasıl ve nerede işlendiğini yönetmede merkezidir ve kaynak, hedef ve dönüşüm gereksinimlerine göre optimize edilebilir. Daha fazla bağlam için üç IR türü vardır:
|
Integration Runtime (IR) Türü |
Açıklama |
|
Azure Integration Runtime |
Azure veri merkezleri içinde veri hareketi ve dönüşüm aktiviteleri için kullanılır. Kopyalama aktivitelerini, veri akışı dönüşümlerini destekler ve aktiviteleri Azure kaynaklarına yönlendirir. |
|
Self-hosted Integration Runtime |
Şirket içi, özel ağdaki sanal makineler veya ortamlar üzerine kurularak şirket içi, özel ve Azure kaynakları arasında veri entegrasyonu sağlar. Şirket içinden Azure’a veri kopyalamak için kullanışlıdır. |
|
Azure-SSIS Integration Runtime |
Mevcut SQL Server Integration Services (SSIS) paketlerinizi Azure’a taşımanıza olanak tanır ve SSIS paket yürütmesini Azure Data Factory içinde yerel olarak destekler. SSIS iş yüklerini kapsamlı yeniden çalışma olmadan taşımak isteyenler için idealdir. |
Açıklama: Bu soru, yeniden kullanılabilir ve esnek boru hatları oluşturmak için ADF’de parametreleştirmenin nasıl çalıştığını anlama düzeyinizi kontrol eder.
Örnek cevap: Azure Data Factory’de parametreleştirme, her çalıştırmada farklı değerler geçebileceğiniz dinamik boru hattı yürütmesine olanak tanır.
Örneğin, bir Copy Activity’de kaynak dosya yolunu ve hedef klasörü dinamik olarak belirtmek için parametreleri kullanabilirim. Parametreleri boru hattı düzeyinde tanımlar ve ilgili veri kümesine veya aktiviteye iletirim.
Basit bir örnek:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}Parametreleştirme, boru hatlarını yeniden kullanılabilir kılar ve çalışma zamanında girdileri dinamik olarak ayarlayarak kolay ölçeklenme sağlar.
Açıklama: Bu soru, harici hesaplama hizmetlerine ihtiyaç duymadan ADF’de veri dönüşümü konusundaki bilginizi değerlendirir.
Örnek cevap: Azure Data Factory’de Mapping Data Flow, kod yazmadan veya veriyi ADF ekosistemi dışına çıkarmadan veri üzerinde dönüşümler yapmanıza olanak tanır. Karmaşık dönüşümleri görsel bir arayüz üzerinden oluşturabilirsiniz.
Veri akışları, ADF’nin yönetilen ortamındaki Spark kümeleri üzerinde yürütülür; bu da ölçeklenebilir ve verimli veri dönüşümleri sağlar.
Örneğin, tipik bir dönüşüm senaryosunda iki veri kümesini birleştirebilir, sonuçları toplulaştırabilir ve çıktıyı yeni bir hedefe yazabilirim—tüm bunları görsel olarak ve Databricks gibi hizmetlere ihtiyaç duymadan.
Açıklama: Bu soru, veri dönüşümü sırasında dinamik şema değişikliklerini yönetme becerinizi test eder.
Örnek cevap: Şema kayması, kaynak veri yapısının zaman içinde değişmesine denir.
Azure Data Factory, Mapping Data Flows içindeki Allow Schema Drift seçeneğiyle şema kaymasını ele alır. Bu seçenek, gelen verinin şemasında yeni sütun eklenmesi veya kaldırılması gibi değişikliklere, tüm şemayı yeniden tanımlamaya gerek kalmadan, ADF’nin otomatik olarak uyum sağlamasına imkân verir.
Şema kaymasını etkinleştirerek, kaynak şema değişse bile sütunları dinamik olarak eşleyecek şekilde bir boru hattı yapılandırabilirim.
Azure Data Factory’de allow schema drift seçeneği. Görsel kaynağı: Microsoft
Açıklama: Bu soru, toplu işlemeye kıyasla modern, sürekli veri alma yöntemlerine aşinalığınızı değerlendirir.
Örnek cevap: ADF’deki CDC kaynağı, kaynaklardaki (ör. SQL veya Cosmos veritabanı) değişen veriyi karmaşık watermark mantığı olmadan sürekli olarak hedefe çoğaltmanın düşük kodlu bir yolunu sağlar.
Planlanmış bir standard boru hattı tetikleyicisinden farklı olarak CDC kaynağı sürekli (veya mikro partiler halinde) çalışır; ekleme, güncelleme ve silmeleri kaynakta otomatik olarak izler ve hedefe uygular. Gerçek zamana yakın veri senkronizasyonu gerektiren senaryolar için idealdir.
İleri düzey mülakat soruları, performans optimizasyonu, gerçek dünya kullanım örnekleri ve gelişmiş mimari kararlar gibi ADF’nin daha derin işlevlerine iner.
Bu sorular, karmaşık veri senaryolarındaki deneyiminizi ve ADF kullanarak zorlu problemleri çözme becerinizi ölçmeyi amaçlar.
Açıklama: Bu soru, boru hattı verimliliğini sorun giderme ve iyileştirme yeteneğinizi değerlendirir.
Örnek cevap: Bir Azure Data Factory boru hattının performansını optimize etmek için genellikle birkaç strateji izlerim.
Öncelikle, mümkün olduğunda veriyi paralel işlemek için Concurrent Pipeline Runs kullanarak paralellikten yararlanırım. Ayrıca, büyük veri kümelerini bölümlere ayırmak ve küçük parçaları eşzamanlı olarak aktarmak için Copy Activity içinde Partitioning kullanırım.
Bir diğer önemli optimizasyon, veri kaynağı ve dönüşüm gereksinimlerine göre doğru Integration Runtime’ı seçmektir. Örneğin, şirket içi veri için Self-hosted IR kullanmak, şirket içinden buluta aktarımları hızlandırabilir.
Ayrıca, Copy Activity’de Staging’i etkinleştirmek, büyük veri kümelerini nihai yüklemeden önce tamponlayarak performansı artırabilir.
Açıklama: Bu soru, ADF’de güvenli kimlik bilgisi yönetimine ilişkin anlayışınızı değerlendirir.
Örnek cevap: Azure Key Vault, Azure Data Factory içinde bağlantı dizeleri, parolalar ve API anahtarları gibi hassas bilgilerin güvenliğini sağlamada kritik bir rol oynar. Sırlar boru hatlarına veya Linked Services’e gömülmek yerine Key Vault’ta saklanır ve yönetilir.
ADF boru hattı, çalışma zamanında sırları Key Vault’tan güvenli bir şekilde alabilir; böylece kimlik bilgileri korunur ve kodda açığa çıkmaz. Örneğin, bir Azure SQL Database’e bağlanacak Linked Service kurarken, güvenli kimlik doğrulama için Key Vault’taki bir sır referansını kullanırım.
Açıklama: Bu soru, ADF’de sürüm kontrolü ve otomatik dağıtıma aşinalığınızı kontrol eder.
Örnek cevap: Azure Data Factory, CI/CD iş akışları için Azure DevOps veya GitHub ile entegre olur. Genellikle ADF’yi bir Git deposuna bağlayarak boru hatları, veri kümeleri ve Linked Services için sürüm kontrolünü etkinleştiririm. Süreç; dallar oluşturmayı, geliştirme ortamında değişiklik yapmayı ve ardından bu değişiklikleri depoya göndermeyi içerir.
Dağıtım için, ADF farklı ortamlarda (ör. hazırlık ve üretim) kullanılabilecek ARM şablonlarını dışa aktarmayı destekler. Boru hatlarını kullanarak dağıtım sürecini otomatikleştirebilir, değişikliklerin farklı ortamlarda verimli biçimde test edilip terfi ettirilmesini sağlayabilirim.
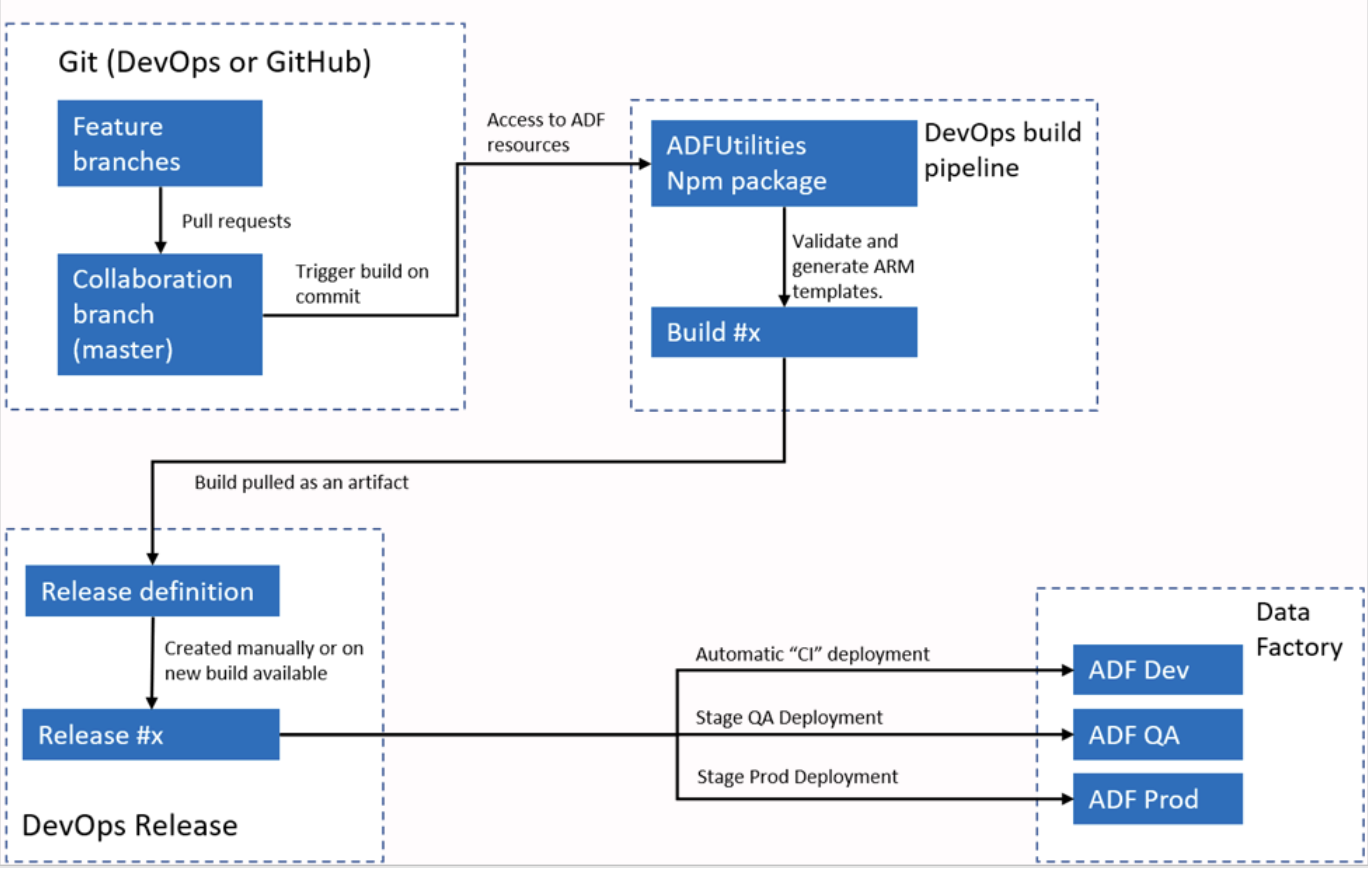
Azure Data Factory otomatik CI/CI iş akışı. Görsel kaynağı: Microsoft.
Açıklama: Bu soru, ADF’nin hibrit veri ortamlarını yönetme yeteneklerine ilişkin anlayışınızı değerlendirir.
Örnek cevap: Azure Data Factory ile hibrit bir veri boru hattı tasarlamak, şirket içi ve bulut ortamları arasında köprü kurmak için Self-hosted Integration Runtime (IR) kullanımını gerektirir. IR, şirket içi ağa ait bir makineye kurulur ve ADF’nin şirket içi kaynaklar ile Azure Blob Storage veya Azure SQL Database gibi bulut kaynakları arasında veriyi güvenle taşımasını sağlar.
Örneğin, şirket içi SQL Server verisini Azure Data Lake’e aktarmam gerektiğinde, SQL Server’a güvenli erişim için Self-hosted IR’yi kurar, kaynak ve hedef için veri kümeleri tanımlar ve veriyi taşımak için Copy Activity kullanırım. Ayrıca, Mapping Data Flows ile dönüşüm veya temizlik adımları ekleyebilirim.
Açıklama: Bu soru, karmaşık veri akışlarında dinamik şema eşlemeleri yapılandırma becerinizi test eder.
Örnek cevap: Mapping Data Flow’da dinamik eşleme, kaynak veri şemasının değişebildiği durumlarda esneklik sağlar. Veri Akışı’nda Auto Mapping özelliğini kullanarak, kaynak sütunları hedef sütunlara ada göre otomatik olarak eşleyerek dinamik eşleme uygularım.
Daha karmaşık senaryolarda, meta verilere dayanarak sütunları dinamik olarak atamak veya değiştirmek için Derived Columns ve Veri Akışı İfade Dili’ni kullanırım. Bu yaklaşım, şema kaymasıyla başa çıkarken veya veri boru hattının manuel yeniden eşleme olmadan birden fazla farklı kaynak şemayı işlemesi gerektiğinde yardımcı olur.
Açıklama: Bu soru, kurumsal veri yönetişimi standartlarına uygun boru hatları tasarlama becerinizi kontrol eder.
Örnek cevap: ADF, soy ağacı (lineage) verilerini iletmek için Microsoft Purview ile yerel olarak entegre olur. Bir boru hattı çalıştığında, ADF Purview’a şu bilgileri tanımlayan meta veriler gönderir:
Bu sayede veri sorumluları, kuruluş genelinde verinin akışını görselleştirebilir. ADF örneğini Purview yönetişim portalında kaydederek bağlantı kurarsınız.
Davranışsal ve senaryo tabanlı mülakat soruları, adayların teknik becerilerini gerçek dünya durumlarında nasıl uyguladıklarına odaklanır.
Bu sorular, karmaşık veri iş akışlarında sorun çözme, arıza giderme ve optimizasyon yeteneklerini değerlendirir. Ayrıca adayın karar verme sürecine ve veri entegrasyonu ile ETL süreçlerine ilişkin zorluklarla başa çıkma deneyimine dair fikir verir.
Açıklama: Bu soru, özellikle boru hattı hataları veya beklenmedik sorunlarla karşılaşıldığında sorun çözme becerilerinizi değerlendirir.
Örnek cevap: Bir projede, şirket içi SQL Server’dan Azure Blob Storage’a veri aktarımı denemelerinde boru hattı sürekli olarak başarısız oluyordu.
Hata logları, veri hareketi sürecinde zaman aşımı hatası olduğunu gösteriyordu. Sorun gidermek için, şirket içi veri bağlantısından sorumlu olan Self-hosted Integration Runtime (IR) yapılandırmasını önce kontrol ettim.
İnceleme sonucunda, IR’yi barındıran makinenin yüksek CPU kullandığını ve bunun veri aktarımında gecikmelere neden olduğunu gördüm.
Sorunu çözmek için makinenin işlem gücünü artırdım ve Copy Activity ayarlarını kullanarak veriyi daha küçük parçalara bölümlendirip işi dağıttım.
Bu sayede paralel veri işleme mümkün oldu, yükleme süreleri azaldı ve zaman aşımı hataları önlendi. Değişikliklerden sonra boru hattı başarıyla çalıştı ve hata ortadan kalktı.
Açıklama: Bu soru, veri iş akışlarında optimizasyon tekniklerini belirleme ve uygulama becerinizi değerlendirir.
Örnek cevap: Bir projede, birden fazla kaynaktan büyük miktarda finansal veriyi işlememiz gerekiyordu ve verinin hacmi nedeniyle ilk boru hattı çok uzun sürüyordu. Bunu optimize etmek için öncelikle paralelliği etkinleştirdim; birden fazla Copy Activity’yi aynı anda çalışacak şekilde ayarlayarak her birinin farklı bir veri kümesi bölümünü işlemesini sağladım.
Sonrasında, Copy Activity’deki staging özelliğini kullanarak veriyi daha ileri işlemden önce geçici olarak Azure Blob Storage’da tamponladım; bu da aktarım hızını önemli ölçüde artırdı. Dönüşümlerde kullanılan başvuru tablolarını önbelleğe alarak Data Flow optimizasyonlarından da yararlandım.
Bu ayarlamalar, boru hattı performansını %40 iyileştirerek yürütme süresini kısalttı.
Açıklama: Bu soru, beklenmedik şema değişikliklerini nasıl yönettiğinizi ve boru hatlarının işlevselliğini nasıl koruduğunuzu kontrol eder.
Örnek cevap: Evet, projelerimden birinde bir veri kaynağının (harici bir API) şeması beklenmedik şekilde değişti ve veri kümesine yeni bir sütun eklendi. Mapping Data Flow’daki şema artık hizalı olmadığı için boru hattı başarısız oldu.
Bunu ele almak için Data Flow’da Allow Schema Drift seçeneğini etkinleştirdim; bu sayede boru hattı, şemadaki değişiklikleri otomatik olarak algılayıp yönetebildi.
Ayrıca, Derived Columns kullanarak dinamik sütun eşlemeleri yapılandırdım; böylece belirli sütun adlarını sabitlemeden yeni sütun yakalanabildi. Bu sayede boru hattı, gelecekteki şema değişikliklerine de manuel müdahale olmadan uyum sağlayabildi.
Açıklama: Bu soru, karmaşık ETL süreçlerinde yaygın bir gereksinim olan çok kaynaklı veri entegrasyonunu yönetme becerinizi değerlendirir.
Örnek cevap: Yakın zamanda bir projede, üç kaynaktan veri entegre etmem gerekiyordu: şirket içi SQL Server, Azure Data Lake ve bir REST API. Şirket içi SQL Server bağlantısı için Self-hosted Integration Runtime ve bulut tabanlı hizmetler için Azure Integration Runtime kombinasyonunu kullandım.
SQL Server ve REST API’den veriyi çekmek için Copy Activity kullanan, Mapping Data Flows ile dönüştüren ve Azure Data Lake’de depolanan verilerle birleştiren bir boru hattı oluşturdum.
Boru hatlarını parametreleştirerek farklı veri kümelerini ve zamanlamaları esnek şekilde yönetebildim. Bu, müşterinin veri analitiği platformu için kritik olan çok kaynaklı veri entegrasyonunu sağladı.
Açıklama: Bu soru, boru hattı iş akışlarınızda veri kalitesi problemlerini nasıl tespit edip ele aldığınızı inceler.
Örnek cevap: Bir durumda, bir CRM sisteminden müşteri verisi çıkaran bir boru hattı üzerinde çalışıyordum. Ancak verilerde eksik değerler ve yinelenen kayıtlar vardı ve bu da nihai raporlamayı etkiliyordu. Bu veri kalitesi sorunlarını ele almak için, boru hattına veri temizleme işlemleri yapan bir Data Flow entegre ettim.
Yinelenenleri kaldırmak için filtreler, eksik değerleri yönetmek için koşullu ayırma (conditional split) kullandım. Eksik veya hatalı veriler için ise bir başvuru veri kümesinden varsayılan değerleri çekmek üzere bir lookup yapılandırdım. Sürecin sonunda veri kalitesi belirgin ölçüde arttı ve aşağı akış analitiklerinin doğruluğu ve güvenilirliği sağlandı.
Açıklama: Bu soru, ADF kullanarak gelişmiş veri dönüşümleri konusundaki deneyiminizi test eder.
Örnek cevap: Bir finansal raporlama projesinde, birden fazla kaynaktan gelen işlem verilerini birleştirmem, toplulaştırmalar uygulamam ve farklı bölgeler için özet raporlar üretmem gerekiyordu. Zorluk, her veri kaynağının biraz farklı yapı ve adlandırma kurallarına sahip olmasıydı. Dönüşümü Mapping Data Flows kullanarak gerçekleştirdim.
Önce tüm veri kümelerinde sütun adlarını Derived Columns ile standartlaştırdım. Ardından, bölge bazlı metrikleri (toplam satış, ortalama işlem tutarı gibi) hesaplamak için toplulaştırmalar uyguladım. Son olarak, veriyi kolay raporlama için yeniden şekillendirmek üzere pivot dönüşümü kullandım. Tüm dönüşüm, ADF’nin yerleşik dönüşümleri ve ölçeklenebilir altyapısından yararlanılarak ADF içinde gerçekleştirildi.
Açıklama: Bu soru, ADF’de veri güvenliği uygulamaları konusundaki anlayışınızı değerlendirir.
Örnek cevap: Bir projede, şirket içi SQL Server’dan Azure SQL Database’e güvenli şekilde aktarılması gereken hassas müşteri verileriyle çalışıyorduk. Veritabanı kimlik bilgilerini saklamak ve veriyi güvence altına almak için Azure Key Vault kullandım; böylece parola gibi hassas bilgiler boru hattında veya Linked Services’te gömülü olmadı.
Ayrıca, şirket içi SQL Server ile Azure arasındaki bağlantılarda SSL’yi etkinleştirerek veri hareketi sırasında Şifreleme uyguladım.
Buna ek olarak, ADF boru hattına erişimi sınırlamak için rol tabanlı erişim denetimi (RBAC) kullandım; böylece yalnızca yetkili kullanıcılar boru hattını tetikleyebilir veya değiştirebilirdi. Bu kurulum, hem güvenli veri aktarımını hem de uygun erişim yönetimini sağladı.
Açıklama: Bu soru, olay odaklı boru hattı yürütmelerini uygulama becerinizi değerlendirir.
Örnek cevap: Bir senaryoda, satış verilerini içeren yeni bir dosya Azure Blob Storage’a yüklendiğinde boru hattının çalışması gerekiyordu. Bunu uygulamak için Azure Data Factory’de Olay Tabanlı Tetikleyici kullandım. Tetikleyici, belirli bir kapsayıcıda Blob Created olaylarını dinleyecek şekilde ayarlandı ve yeni bir dosya yüklendiği anda boru hattını otomatik olarak tetikledi.
Bu olay odaklı yaklaşım, boru hattının yalnızca yeni veri mevcut olduğunda çalışmasını sağlayarak manuel yürütme veya zamanlanmış çalışmalara olan ihtiyacı ortadan kaldırdı. Boru hattı ardından dosyayı işledi, dönüştürdü ve daha fazla analiz için veri ambarına yükledi.
Açıklama: Bu soru, geleneksel ETL süreçlerini ADF kullanarak buluta taşıma konusundaki deneyiminizi değerlendirir.
Örnek cevap: Şirket içindeki mevcut SSIS tabanlı ETL sürecini buluta taşımak için Azure Data Factory ile Azure-SSIS Integration Runtime kullandım.
Önce mevcut SSIS paketlerini, ADF ile uyumlu olduklarından emin olmak için değerlendirdim ve bulut tabanlı veri kaynaklarını ele almak üzere gerekli düzenlemeleri yaptım.
Azure-SSIS IR’yi, SSIS paketlerini bulutta çalıştıracak şekilde kurdum ve mevcut iş akışlarını korudum. Yeni bulut ortamı için ayrıca bazı geleneksel ETL aktivitelerini, Copy Activities ve Mapping Data Flows gibi yerel ADF bileşenleriyle değiştirdim; bu da veri iş akışlarının genel performansını ve ölçeklenebilirliğini artırdı.
Açıklama: Bu soru, operasyonel olgunluğunuzu ve ADF’nin faturalama modeline ilişkin anlayışınızı test eder.
Örnek cevap: Öncelikle Azure Monitor’daki Pipeline Run Consumption raporunu inceleyerek maliyet sürücülerini (ör. yüksek Data Flow hesaplama saatleri veya aşırı API çağrıları) belirlerim. Yaygın optimizasyon stratejileri şunları içerir:
Bir Azure Data Factory mülakatına hazırlanmak, platformun teknik ve pratik yönlerini derinlemesine anlamayı gerektirir. ADF’nin temel özelliklerine hâkimiyetinizi ve bunları gerçek dünya senaryolarında uygulama becerinizi göstermek esastır.
Mülakata hazırlanmanıza yardımcı olacak en iyi ipuçlarım şunlardır:
Azure Data Factory, bulut tabanlı ETL çözümleri oluşturmak için güçlü bir araçtır ve veri mühendisliği dünyasında bu alandaki uzmanlık oldukça talep görmektedir!
Bu yazıda, genel kavramlardan teknik ve senaryo tabanlı konulara kadar temel mülakat sorularını inceledik ve ADF özellikleri ve araçlarına dair bilginin önemini vurguladık. Boru hattı yönetimi, veri dönüşümü ve sorun giderme konularındaki gerçek dünya örnekleri, bulut tabanlı bir ETL ortamında gereken kritik becerileri gözler önüne serer.
Microsoft Azure’u daha derinlemesine anlamak için, Azure mimarisi, yönetim ve yönetişimi üzerine temel kursları incelemeyi düşünebilirsiniz: Understanding Microsoft Azure, Understanding Microsoft Azure Architecture and Services ve Understanding Microsoft Azure Management and Governance. Bu kaynaklar, Azure Data Factory bilginizi tamamlayarak daha geniş Azure ekosistemine ilişkin değerli içgörüler sunar ve veri mühendisliğinde başarılı bir kariyer için sizi hazırlar.
Bu kurslarla Azure hakkında daha fazla bilgi edinin!
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
