
Tracks
Microsoft Azure Fundamentals (AZ-900)
9 giờ
Azure Data Factory (ADF) là dịch vụ tích hợp dữ liệu dựa trên đám mây do Microsoft Azure cung cấp.
Khi ra quyết định dựa trên dữ liệu trở thành trọng tâm của vận hành doanh nghiệp, nhu cầu về các công cụ kỹ thuật dữ liệu trên đám mây đang ở mức cao nhất! Vì ADF là dịch vụ dẫn đầu, các công ty ngày càng tìm kiếm những chuyên gia dữ liệu có kinh nghiệm thực hành để quản lý pipeline dữ liệu và tích hợp hệ thống.
Trong bài viết này, chúng tôi hướng dẫn các ứng viên ADF qua những câu hỏi và câu trả lời phỏng vấn Azure Data Factory thiết yếu — bao gồm câu hỏi tổng quát, kỹ thuật, nâng cao và theo tình huống — đồng thời cung cấp mẹo để bạn ghi điểm trong buổi phỏng vấn.
Azure Data Factory là dịch vụ ETL trên đám mây cho phép bạn tạo các quy trình làm việc dựa trên dữ liệu nhằm điều phối và tự động hóa việc di chuyển và chuyển đổi dữ liệu. Dịch vụ tích hợp với nhiều nguồn và đích dữ liệu cả on-premises và trên đám mây.
Khi các nhóm chuyển dịch sang hạ tầng cloud-native, nhu cầu quản lý dữ liệu trên các môi trường đa dạng ngày càng tăng. Việc ADF tích hợp với hệ sinh thái Azure và các nguồn dữ liệu bên thứ ba giúp hiện thực hóa điều này, biến kỹ năng sử dụng dịch vụ thành năng lực được các tổ chức săn đón.
Kiến trúc BI tự động sử dụng Azure Data Factory. Nguồn ảnh: Microsoft
Phần này tập trung vào các câu hỏi nền tảng thường gặp trong phỏng vấn để đánh giá kiến thức tổng quát của bạn về ADF. Những câu hỏi này kiểm tra hiểu biết của bạn về các khái niệm cơ bản, kiến trúc và thành phần.
Mô tả: Câu hỏi này thường dùng để đánh giá liệu bạn hiểu các khối xây dựng của ADF hay không.
Câu trả lời mẫu: Các thành phần chính của Azure Data Factory gồm:
Mô tả: Câu hỏi này kiểm tra hiểu biết của bạn về cách ADF tạo điều kiện cho di chuyển dữ liệu lai một cách an toàn và hiệu quả.
Câu trả lời mẫu: Azure Data Factory cho phép di chuyển dữ liệu an toàn giữa đám mây và on-premise thông qua Self-hosted Integration Runtime (IR), hoạt động như cầu nối giữa ADF và nguồn dữ liệu on-premise.
Ví dụ, khi chuyển dữ liệu từ SQL Server on-premise sang Azure Blob Storage, self-hosted IR kết nối an toàn tới hệ thống on-premise. Điều này cho phép ADF truyền dữ liệu đồng thời đảm bảo bảo mật bằng mã hóa khi truyền và khi lưu. Cách tiếp cận này đặc biệt hữu ích cho kịch bản đám mây lai, nơi dữ liệu phân tán trên hạ tầng on-prem và đám mây.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về cách ADF tự động hóa và lập lịch pipeline bằng các loại trigger khác nhau.
Câu trả lời mẫu: Trong Azure Data Factory, trigger dùng để tự động khởi chạy thực thi pipeline dựa trên điều kiện hoặc lịch trình cụ thể. Có ba loại trigger chính:
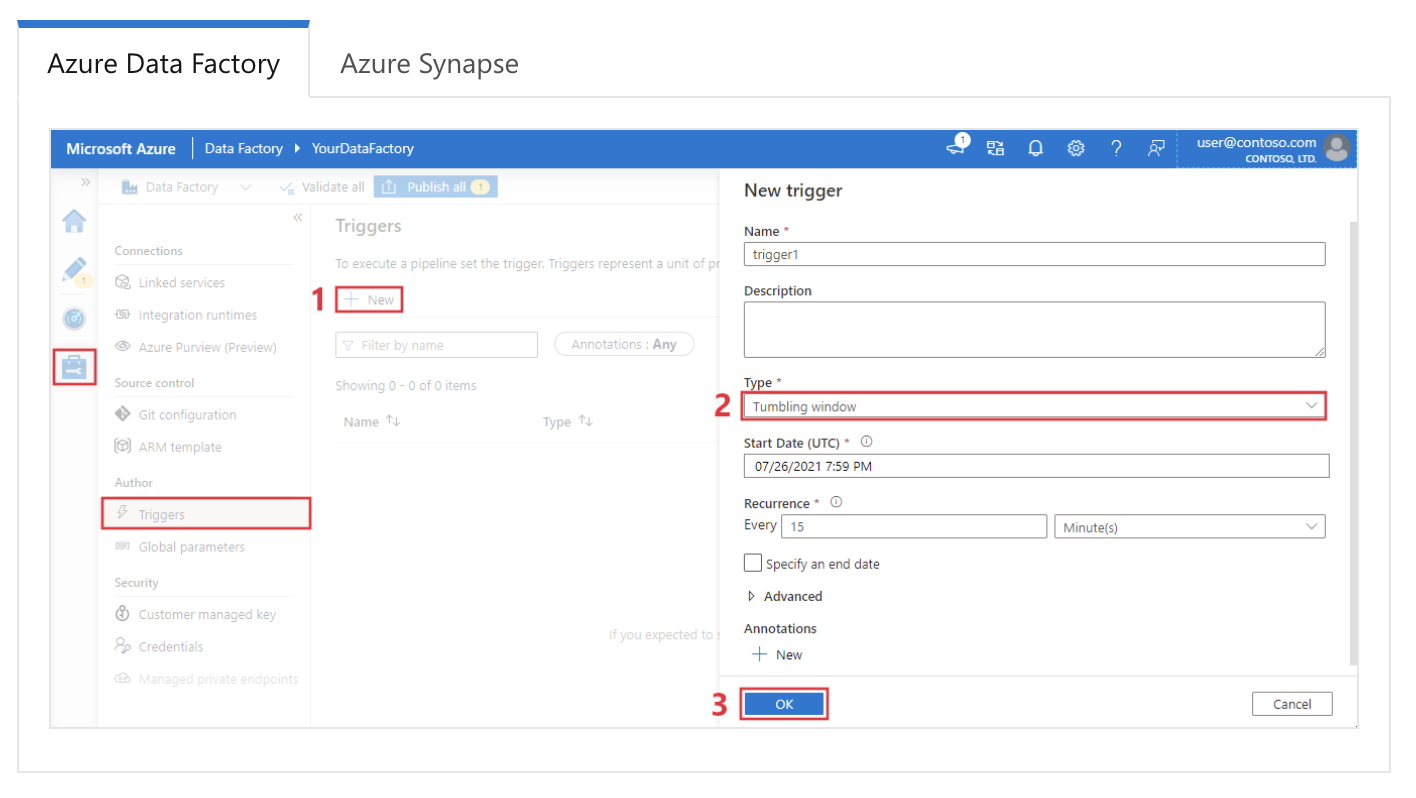
Cấu hình tumbling window trigger trong Azure Data Factory. Nguồn ảnh: Microsoft.
Mô tả: Câu hỏi này đánh giá kiến thức của bạn về các tác vụ mà pipeline ADF có thể thực hiện.
Câu trả lời mẫu: Pipeline Azure Data Factory hỗ trợ nhiều loại activity. Đây là những loại phổ biến nhất:
|
Loại activity |
Mô tả |
|
Di chuyển dữ liệu |
Di chuyển dữ liệu giữa các kho dữ liệu được hỗ trợ (ví dụ: Azure Blob Storage, SQL Database) với Copy Activity. |
|
Chuyển đổi dữ liệu |
Bao gồm Data Flow Activity cho logic chuyển đổi dữ liệu dùng Spark, Mapping Data Flows cho tác vụ ETL, và Wrangling Data Flows cho bước chuẩn bị dữ liệu. |
|
Luồng điều khiển |
Kiểm soát thực thi pipeline bằng các activity như ForEach, If Condition, Switch, Wait và Until để tạo logic điều kiện. |
|
Thực thi bên ngoài |
Thực thi ứng dụng hoặc hàm bên ngoài, bao gồm Azure Functions, Web Activity (gọi REST API), và Stored Procedure Activity cho SQL. |
|
Activity tùy chỉnh |
Cho phép chạy mã tùy chỉnh trong Custom Activity bằng .NET hoặc Azure Batch, mang lại linh hoạt cho nhu cầu xử lý dữ liệu nâng cao. |
|
Dịch vụ khác |
Hỗ trợ hoạt động của HDInsight, Databricks và Data Lake Analytics, tích hợp với các dịch vụ phân tích Azure khác cho tác vụ dữ liệu phức tạp. |
Mô tả: Câu hỏi này kiểm tra mức độ quen thuộc của bạn với công cụ giám sát và gỡ lỗi của ADF.
Câu trả lời mẫu: Azure Data Factory cung cấp giao diện giám sát và gỡ lỗi mạnh mẽ qua tab Monitor trong Azure portal. Tại đây tôi có thể theo dõi lượt chạy pipeline, xem trạng thái activity và chẩn đoán lỗi. Mỗi activity sinh log để xem xét, xác định lỗi và xử lý sự cố.
Ngoài ra, có thể cấu hình Azure Monitor để gửi cảnh báo dựa trên lỗi pipeline hoặc vấn đề hiệu năng. Khi gỡ lỗi, tôi thường bắt đầu từ log của activity thất bại, xem chi tiết lỗi rồi chạy lại pipeline sau khi khắc phục.
Mô tả: Câu hỏi này kiểm tra việc bạn cập nhật với tiến hóa nền tảng dữ liệu mới nhất của Microsoft.
Câu trả lời mẫu: Dù cùng dùng một engine, Data Factory trong Fabric là dịch vụ SaaS (Software as a Service) tích hợp trong hệ sinh thái Fabric, trong khi Azure Data Factory (ADF) là tài nguyên PaaS (Platform as a Service). Khác biệt chính gồm:
Mô tả: Câu hỏi này đánh giá kiến thức của bạn về cơ chế bảo mật của ADF để bảo vệ dữ liệu trong suốt vòng đời.
Câu trả lời mẫu: Azure Data Factory đảm bảo an toàn dữ liệu qua nhiều cơ chế.
Trước hết, ADF sử dụng mã hóa cho dữ liệu cả khi truyền và khi lưu, áp dụng các giao thức như TLS và AES để bảo vệ truyền tải. ADF tích hợp Azure Active Directory (AAD) để xác thực và dùng Kiểm soát truy cập dựa trên vai trò (RBAC) nhằm hạn chế ai có thể truy cập và quản lý factory.
Ngoài ra, Managed Identity cho phép ADF truy cập an toàn các dịch vụ Azure khác mà không lộ thông tin xác thực. Về bảo mật mạng, ADF hỗ trợ Private Endpoint, đảm bảo lưu lượng dữ liệu ở trong mạng Azure và tăng thêm một lớp bảo vệ.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về vai trò khác nhau của Linked Service và Dataset trong ADF.
Câu trả lời mẫu: Trong Azure Data Factory, Linked Service định nghĩa kết nối tới nguồn dữ liệu hoặc dịch vụ tính toán bên ngoài, tương tự chuỗi kết nối. Nó bao gồm thông tin xác thực cần thiết để kết nối tới tài nguyên.
Ngược lại, Dataset đại diện cho tập dữ liệu cụ thể bạn sẽ làm việc, như bảng trong cơ sở dữ liệu hoặc tệp trong Blob Storage.
Trong khi Linked Service xác định dữ liệu ở đâu, Dataset mô tả dữ liệu trông như thế nào và cấu trúc ra sao. Hai thành phần này phối hợp để tạo điều kiện cho việc di chuyển và chuyển đổi dữ liệu.
Các câu hỏi kỹ thuật thường tập trung vào hiểu biết của bạn về các tính năng cụ thể, cách triển khai và cách chúng phối hợp để xây dựng pipeline dữ liệu hiệu quả. Những câu hỏi này đánh giá kinh nghiệm thực hành và kiến thức về các thành phần, năng lực cốt lõi của ADF.
Mô tả: Câu hỏi này kiểm tra khả năng của bạn triển khai chiến lược xử lý lỗi trong pipeline ADF.
Câu trả lời mẫu: Xử lý lỗi trong Azure Data Factory có thể thực hiện bằng Retry Policy và Error Handling Activity. ADF cung cấp cơ chế retry tích hợp, nơi bạn cấu hình số lần thử lại và khoảng thời gian giữa các lần nếu activity thất bại.
Ví dụ, nếu Copy Activity thất bại do sự cố mạng tạm thời, bạn có thể cấu hình activity thử lại 3 lần với khoảng nghỉ 10 phút giữa mỗi lần.
Ngoài ra, đặt điều kiện phụ thuộc Activity như Failure, Completion và Skipped có thể kích hoạt hành động cụ thể tùy theo việc activity thành công hay thất bại.
Chẳng hạn, tôi có thể định nghĩa luồng pipeline sao cho khi một activity thất bại, một activity xử lý lỗi tùy chỉnh như gửi cảnh báo hoặc chạy quy trình dự phòng sẽ được thực thi.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về hạ tầng tính toán đằng sau di chuyển dữ liệu và phân phối activity trong ADF.
Câu trả lời mẫu: Integration Runtime (IR) là hạ tầng tính toán mà Azure Data Factory sử dụng để thực hiện di chuyển dữ liệu, chuyển đổi và phân phối activity. Đây là trung tâm quản lý cách và nơi dữ liệu được xử lý, và có thể tối ưu theo nguồn, đích và yêu cầu chuyển đổi. Để rõ hơn, có ba loại IR:
|
Loại Integration Runtime (IR) |
Mô tả |
|
Azure Integration Runtime |
Dùng cho hoạt động di chuyển và chuyển đổi dữ liệu trong các trung tâm dữ liệu Azure. Hỗ trợ copy activity, chuyển đổi data flow và phân phối activity tới tài nguyên Azure. |
|
Self-hosted Integration Runtime |
Cài đặt on-premises hoặc máy ảo trong mạng riêng để cho phép tích hợp dữ liệu xuyên suốt on-premises, mạng riêng và Azure. Hữu ích khi sao chép dữ liệu từ on-premises lên Azure. |
|
Azure-SSIS Integration Runtime |
Cho phép lift-and-shift các gói SQL Server Integration Services (SSIS) hiện có lên Azure, hỗ trợ chạy gói SSIS gốc trong Azure Data Factory. Lý tưởng cho người dùng muốn di chuyển workload SSIS mà không phải làm lại nhiều. |
Mô tả: Câu hỏi này kiểm tra hiểu biết của bạn về cách tham số hóa hoạt động trong ADF để tạo pipeline có thể tái sử dụng và linh hoạt.
Câu trả lời mẫu: Tham số hóa trong Azure Data Factory cho phép thực thi pipeline động, nơi bạn có thể truyền các giá trị khác nhau cho mỗi lần chạy.
Ví dụ, trong Copy Activity, tôi có thể dùng tham số để chỉ định đường dẫn tệp nguồn và thư mục đích một cách linh hoạt. Tôi sẽ định nghĩa tham số ở cấp pipeline và truyền chúng cho dataset hoặc activity liên quan.
Đây là ví dụ đơn giản:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}Tham số hóa giúp pipeline có thể tái sử dụng và dễ mở rộng bằng cách điều chỉnh đầu vào động trong thời gian chạy.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về chuyển đổi dữ liệu trong ADF mà không cần dịch vụ tính toán bên ngoài.
Câu trả lời mẫu: Mapping Data Flow trong Azure Data Factory cho phép bạn thực hiện các chuyển đổi dữ liệu mà không cần viết mã hoặc đưa dữ liệu ra ngoài hệ sinh thái ADF. Nó cung cấp giao diện trực quan để xây dựng các chuyển đổi phức tạp.
Data flow được thực thi trên cụm Spark trong môi trường được quản lý của ADF, cho phép chuyển đổi dữ liệu hiệu quả và có khả năng mở rộng.
Ví dụ, trong một kịch bản chuyển đổi điển hình, tôi có thể dùng data flow để join hai dataset, tổng hợp kết quả, và ghi đầu ra tới đích mới — tất cả đều trực quan và không cần dịch vụ như Databricks bên ngoài.
Mô tả: Câu hỏi này kiểm tra khả năng của bạn trong việc quản lý thay đổi schema động trong quá trình chuyển đổi dữ liệu.
Câu trả lời mẫu: Schema drift đề cập tới thay đổi cấu trúc dữ liệu nguồn theo thời gian.
Azure Data Factory xử lý schema drift bằng tùy chọn Allow Schema Drift trong Mapping Data Flows. Tùy chọn này cho phép ADF tự động điều chỉnh theo thay đổi schema của dữ liệu đầu vào, như thêm hoặc xóa cột, mà không phải định nghĩa lại toàn bộ schema.
Bằng cách bật schema drift, tôi có thể cấu hình pipeline để ánh xạ cột động ngay cả khi schema nguồn thay đổi.
Tùy chọn Allow schema drift trong Azure Data Factory. Nguồn ảnh: Microsoft
Mô tả: Câu hỏi này đánh giá mức độ quen thuộc của bạn với phương pháp nạp dữ liệu liên tục, hiện đại so với xử lý theo lô.
Câu trả lời mẫu: Tài nguyên CDC trong ADF cung cấp cách low-code để liên tục sao chép dữ liệu thay đổi từ nguồn (như cơ sở dữ liệu SQL hoặc Cosmos) tới đích mà không cần logic watermark phức tạp.
Không giống trigger pipeline tiêu chuẩn chạy theo lịch, tài nguyên CDC chạy liên tục (hoặc theo vi lô), tự động theo dõi insert, update và delete ở nguồn và áp dụng chúng lên đích. Nó lý tưởng cho các kịch bản đồng bộ dữ liệu gần thời gian thực.
Các câu hỏi nâng cao đi sâu vào chức năng ADF, tập trung vào tối ưu hiệu năng, tình huống thực tế và quyết định kiến trúc nâng cao.
Những câu hỏi này nhằm đánh giá kinh nghiệm của bạn với các kịch bản dữ liệu phức tạp và khả năng giải quyết vấn đề thách thức bằng ADF.
Mô tả: Câu hỏi này đánh giá khả năng khắc phục sự cố và cải thiện hiệu quả pipeline của bạn.
Câu trả lời mẫu: Tôi thường áp dụng vài chiến lược để tối ưu hiệu năng pipeline Azure Data Factory.
Đầu tiên, tôi đảm bảo tận dụng tính song song bằng Concurrent Pipeline Runs để xử lý dữ liệu song song khi có thể. Tôi cũng dùng Partitioning trong Copy Activity để chia nhỏ dataset lớn và truyền đồng thời nhiều phần nhỏ.
Một tối ưu quan trọng khác là chọn Integration Runtime phù hợp theo nguồn dữ liệu và yêu cầu chuyển đổi. Ví dụ, dùng Self-hosted IR cho dữ liệu on-prem có thể tăng tốc truyền từ on-prem lên đám mây.
Ngoài ra, bật Staging trong Copy Activity có thể cải thiện hiệu năng bằng cách đệm dataset lớn trước khi nạp cuối cùng.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về quản lý thông tin xác thực an toàn trong ADF.
Câu trả lời mẫu: Azure Key Vault đóng vai trò quan trọng trong bảo mật thông tin nhạy cảm như chuỗi kết nối, mật khẩu và API key trong Azure Data Factory. Thay vì hardcode bí mật trong pipeline hoặc Linked Service, tôi dùng Key Vault để lưu trữ và quản lý các bí mật này.
Pipeline ADF có thể truy xuất bí mật từ Key Vault một cách an toàn trong thời gian chạy, đảm bảo thông tin xác thực được bảo vệ và không lộ trong mã. Ví dụ, khi thiết lập Linked Service kết nối tới Azure SQL Database, tôi sẽ dùng tham chiếu bí mật từ Key Vault để xác thực an toàn.
Mô tả: Câu hỏi này kiểm tra mức độ quen thuộc của bạn với kiểm soát phiên bản và triển khai tự động trong ADF.
Câu trả lời mẫu: Azure Data Factory tích hợp với Azure DevOps hoặc GitHub cho quy trình CI/CD. Tôi thường cấu hình ADF kết nối tới kho Git, cho phép kiểm soát phiên bản cho pipeline, dataset và Linked Service. Quy trình gồm tạo nhánh, thay đổi trong môi trường phát triển, rồi commit các thay đổi lên kho.
Để triển khai, ADF hỗ trợ ARM template có thể xuất và dùng cho các môi trường khác nhau như staging và production. Bằng cách dùng pipeline, tôi có thể tự động hóa triển khai, đảm bảo thay đổi được kiểm thử và đẩy qua các môi trường một cách hiệu quả.
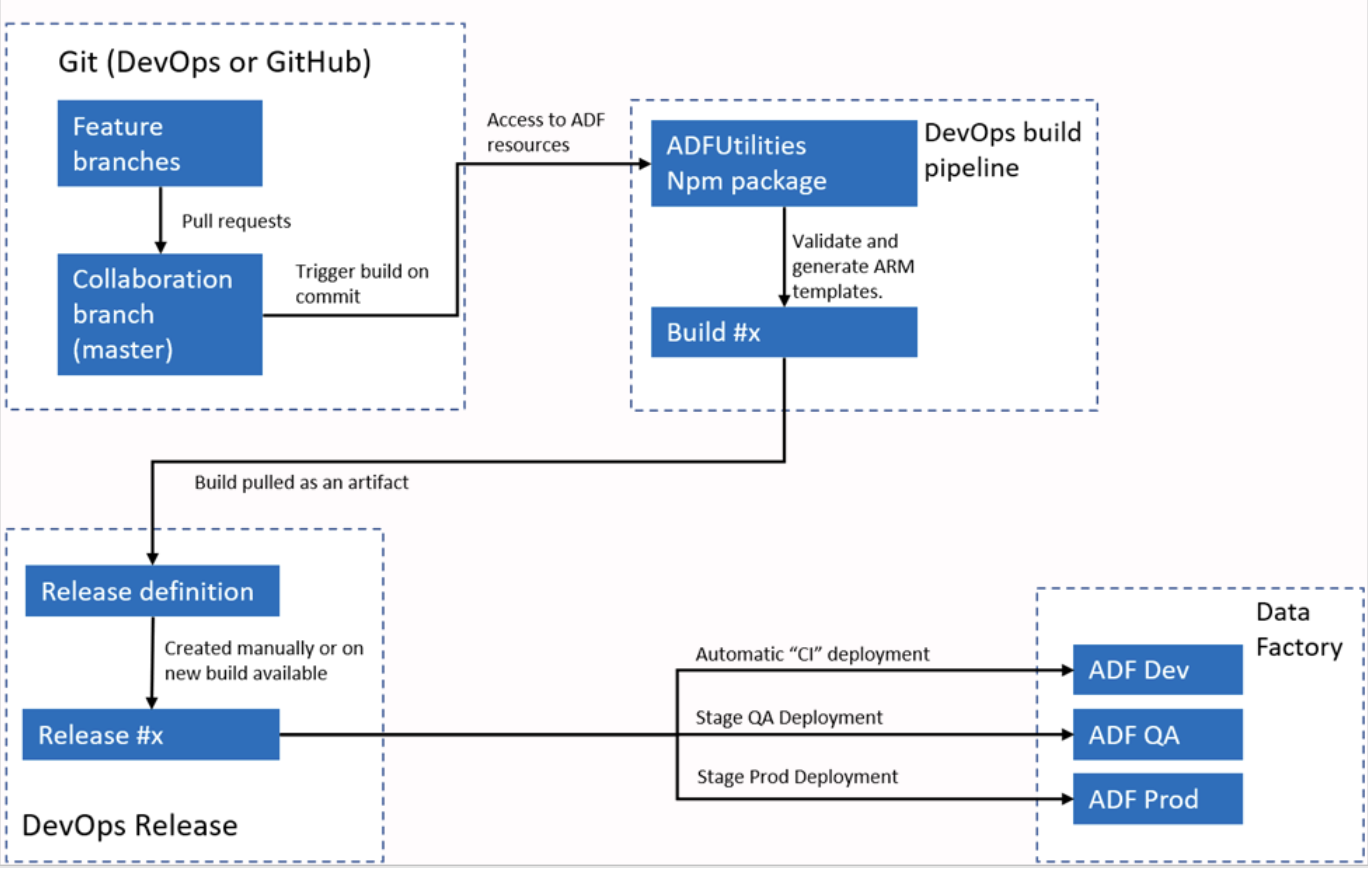
Quy trình CI/CI tự động của Azure Data Factory. Image source: Microsoft.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về khả năng của ADF trong xử lý môi trường dữ liệu lai.
Câu trả lời mẫu: Thiết kế pipeline dữ liệu lai với Azure Data Factory yêu cầu dùng Self-hosted Integration Runtime (IR) để bắc cầu giữa môi trường on-premise và đám mây. IR được cài trên máy trong mạng on-premise, cho phép ADF di chuyển dữ liệu an toàn giữa on-premise và tài nguyên đám mây như Azure Blob Storage hoặc Azure SQL Database.
Chẳng hạn, khi cần chuyển dữ liệu SQL Server on-prem lên Azure Data Lake, tôi sẽ thiết lập Self-hosted IR để truy cập an toàn SQL Server, định nghĩa dataset cho nguồn và đích, và dùng Copy Activity để di chuyển dữ liệu. Tôi cũng có thể thêm bước chuyển đổi hoặc làm sạch bằng Mapping Data Flows.
Mô tả: Câu hỏi này kiểm tra khả năng cấu hình ánh xạ schema động trong data flow phức tạp.
Câu trả lời mẫu: Ánh xạ động trong Mapping Data Flow cho phép linh hoạt khi schema dữ liệu nguồn có thể thay đổi. Tôi triển khai ánh xạ động bằng tính năng Auto Mapping trong Data Flow, tự động ánh xạ cột nguồn sang cột đích theo tên.
Với các tình huống phức tạp hơn, tôi dùng Derived Column và Expression Language trong Data Flow để gán hoặc chỉnh sửa cột động dựa trên metadata. Cách tiếp cận này hữu ích khi xử lý schema drift hoặc khi pipeline cần xử lý nhiều schema nguồn khác nhau mà không phải remap thủ công.
Mô tả: Câu hỏi này kiểm tra khả năng của bạn thiết kế pipeline tuân thủ tiêu chuẩn quản trị dữ liệu doanh nghiệp.
Câu trả lời mẫu: ADF tích hợp gốc với Microsoft Purview để đẩy dữ liệu phả hệ (lineage). Khi pipeline chạy, ADF gửi metadata tới Purview mô tả:
Điều này cho phép các quản trị dữ liệu trực quan hóa dòng chảy dữ liệu trong toàn tổ chức. Bạn kết nối bằng cách đăng ký phiên bản ADF trong cổng quản trị Purview.
Các câu hỏi hành vi và theo tình huống tập trung vào cách ứng viên áp dụng kỹ năng kỹ thuật trong bối cảnh thực tế.
Những câu hỏi này giúp đánh giá khả năng giải quyết vấn đề, khắc phục sự cố và tối ưu trong quy trình dữ liệu phức tạp. Chúng cũng cung cấp góc nhìn về quá trình ra quyết định và kinh nghiệm xử lý thách thức liên quan đến tích hợp dữ liệu và ETL.
Mô tả: Câu hỏi này đánh giá kỹ năng giải quyết vấn đề của bạn, đặc biệt khi đối mặt với lỗi pipeline hoặc sự cố bất ngờ.
Câu trả lời mẫu: Trong một dự án, tôi có pipeline liên tục thất bại khi chuyển dữ liệu từ SQL Server on-premise lên Azure Blob Storage.
Log lỗi cho thấy vấn đề timeout trong quá trình di chuyển dữ liệu. Để khắc phục, tôi kiểm tra cấu hình Self-hosted Integration Runtime (IR), chịu trách nhiệm kết nối dữ liệu on-premise.
Kiểm tra cho thấy máy chủ IR sử dụng nhiều CPU, gây trễ truyền dữ liệu.
Để giải quyết, tôi nâng cấp năng lực xử lý của máy và phân phối workload bằng cách phân vùng dữ liệu thành các phần nhỏ hơn trong cài đặt Copy Activity.
Điều này cho phép xử lý dữ liệu song song, giảm thời gian tải và tránh timeout. Sau thay đổi, pipeline chạy thành công, loại bỏ lỗi.
Mô tả: Câu hỏi này đánh giá khả năng của bạn xác định và triển khai kỹ thuật tối ưu trong quy trình dữ liệu.
Câu trả lời mẫu: Trong một dự án xử lý lượng lớn dữ liệu tài chính từ nhiều nguồn, pipeline ban đầu chạy quá lâu do khối lượng dữ liệu. Để tối ưu, trước tiên tôi bật song song bằng cách thiết lập nhiều Copy Activity chạy đồng thời, mỗi activity xử lý một phân vùng dataset khác nhau.
Tiếp theo, tôi dùng tính năng staging trong Copy Activity để đệm tạm dữ liệu vào Azure Blob Storage trước khi xử lý tiếp, giúp tăng đáng kể thông lượng. Tôi cũng tối ưu Data Flow bằng cách cache bảng tra cứu dùng trong chuyển đổi.
Những điều chỉnh này cải thiện hiệu năng pipeline 40%, rút ngắn thời gian thực thi.
Mô tả: Câu hỏi này kiểm tra cách bạn quản lý thay đổi schema bất ngờ và đảm bảo pipeline vẫn hoạt động.
Câu trả lời mẫu: Có, trong một dự án, schema của nguồn dữ liệu (một API bên ngoài) thay đổi đột ngột khi thêm cột mới. Điều này khiến pipeline thất bại do schema trong Mapping Data Flow không còn khớp.
Để xử lý, tôi bật tùy chọn Allow Schema Drift trong Data Flow, cho phép pipeline tự động phát hiện và xử lý thay đổi schema.
Ngoài ra, tôi cấu hình ánh xạ cột động bằng Derived Column, đảm bảo cột mới được ghi nhận mà không cần hardcode tên cột cụ thể. Điều này giúp pipeline thích ứng với thay đổi schema trong tương lai mà không cần can thiệp thủ công.
Mô tả: Câu hỏi này đánh giá khả năng của bạn xử lý tích hợp dữ liệu đa nguồn, một yêu cầu phổ biến trong quy trình ETL phức tạp.
Câu trả lời mẫu: Trong một dự án gần đây, tôi cần tích hợp dữ liệu từ ba nguồn: SQL Server on-premise, Azure Data Lake và một REST API. Tôi dùng kết hợp Self-hosted Integration Runtime cho kết nối SQL Server on-premise và Azure Integration Runtime cho dịch vụ trên đám mây.
Tôi tạo pipeline dùng Copy Activity để kéo dữ liệu từ SQL Server và REST API, chuyển đổi bằng Mapping Data Flows, và kết hợp với dữ liệu trong Azure Data Lake.
Bằng cách tham số hóa pipeline, tôi đảm bảo linh hoạt trong xử lý các dataset và lịch trình khác nhau. Điều này cho phép tích hợp dữ liệu từ nhiều nguồn, rất quan trọng cho nền tảng phân tích dữ liệu của khách hàng.
Mô tả: Câu hỏi này xem xét cách bạn xác định và xử lý vấn đề chất lượng dữ liệu trong quy trình pipeline.
Câu trả lời mẫu: Trong một trường hợp, tôi làm việc với pipeline trích xuất dữ liệu khách hàng từ hệ thống CRM. Tuy nhiên, dữ liệu có giá trị thiếu và trùng lặp, ảnh hưởng đến báo cáo cuối. Để xử lý, tôi thêm Data Flow vào pipeline để thực hiện làm sạch dữ liệu.
Tôi dùng bộ lọc để loại bỏ trùng lặp và conditional split để xử lý giá trị thiếu. Tôi thiết lập lookup cho dữ liệu thiếu hoặc sai để lấy giá trị mặc định từ dataset tham chiếu. Sau quá trình này, chất lượng dữ liệu cải thiện đáng kể, đảm bảo phân tích phía sau chính xác và tin cậy.
Mô tả: Câu hỏi này kiểm tra kinh nghiệm của bạn với chuyển đổi dữ liệu nâng cao bằng ADF.
Câu trả lời mẫu: Trong dự án báo cáo tài chính, tôi phải hợp nhất dữ liệu giao dịch từ nhiều nguồn, áp dụng tổng hợp và tạo báo cáo tóm tắt theo vùng. Thách thức là mỗi nguồn có cấu trúc và quy ước đặt tên hơi khác. Tôi triển khai chuyển đổi bằng Mapping Data Flows.
Đầu tiên, tôi chuẩn hóa tên cột trên tất cả dataset bằng Derived Column. Tiếp đó, tôi áp dụng tổng hợp để tính chỉ số theo vùng như tổng doanh số và giá trị giao dịch trung bình. Cuối cùng, tôi dùng chuyển đổi pivot để định hình lại dữ liệu nhằm dễ báo cáo. Toàn bộ chuyển đổi thực hiện trong ADF, tận dụng các phép biến đổi tích hợp và hạ tầng có khả năng mở rộng.
Mô tả: Câu hỏi này đánh giá hiểu biết của bạn về thực hành bảo mật dữ liệu trong ADF.
Câu trả lời mẫu: Trong một dự án, chúng tôi xử lý dữ liệu khách hàng nhạy cảm cần truyền an toàn từ SQL Server on-premise tới Azure SQL Database. Tôi dùng Azure Key Vault để lưu thông tin xác thực cơ sở dữ liệu và bảo mật dữ liệu, đảm bảo thông tin như mật khẩu không bị hardcode trong pipeline hoặc Linked Service.
Ngoài ra, tôi triển khai Mã hóa dữ liệu trong quá trình di chuyển bằng cách bật kết nối SSL giữa SQL Server on-premise và Azure.
Tôi cũng dùng RBAC để hạn chế truy cập pipeline ADF, đảm bảo chỉ người dùng được ủy quyền mới có thể kích hoạt hoặc chỉnh sửa. Thiết lập này đảm bảo truyền dữ liệu an toàn và quản lý truy cập đúng đắn.
Mô tả: Câu hỏi này đánh giá khả năng của bạn triển khai thực thi pipeline theo sự kiện.
Câu trả lời mẫu: Trong một kịch bản, pipeline cần chạy bất cứ khi nào có tệp mới chứa dữ liệu bán hàng được tải lên Azure Blob Storage. Để triển khai, tôi dùng Event-Based Trigger trong Azure Data Factory. Trigger được thiết lập lắng nghe sự kiện Blob Created trong một container cụ thể, và ngay khi tệp mới được tải lên, nó tự động kích hoạt pipeline.
Cách tiếp cận theo sự kiện này đảm bảo pipeline chỉ chạy khi có dữ liệu mới, loại bỏ nhu cầu chạy thủ công hoặc theo lịch. Pipeline sau đó xử lý tệp, chuyển đổi và nạp vào kho dữ liệu để phân tích tiếp.
Mô tả: Câu hỏi này đánh giá kinh nghiệm của bạn trong việc di chuyển quy trình ETL truyền thống lên đám mây bằng ADF.
Câu trả lời mẫu: Trong một dự án di chuyển quy trình ETL dựa trên SSIS từ on-premise lên đám mây, tôi dùng Azure Data Factory với Azure-SSIS Integration Runtime.
Trước tiên, tôi đánh giá các gói SSIS hiện có để đảm bảo tương thích với ADF và điều chỉnh cần thiết để xử lý nguồn dữ liệu trên đám mây.
Tôi thiết lập Azure-SSIS IR để chạy gói SSIS trên đám mây trong khi vẫn duy trì quy trình làm việc hiện tại. Với môi trường đám mây mới, tôi cũng thay thế một số hoạt động ETL truyền thống bằng thành phần gốc của ADF như Copy Activity và Mapping Data Flows, giúp cải thiện hiệu năng và khả năng mở rộng của quy trình dữ liệu.
Mô tả: Câu hỏi này kiểm tra mức độ vận hành trưởng thành và hiểu biết của bạn về mô hình tính phí của ADF.
Câu trả lời mẫu: Tôi sẽ phân tích báo cáo Pipeline Run Consumption trong Azure Monitor để xác định yếu tố gây chi phí (ví dụ: giờ compute của Data Flow cao hoặc số cuộc gọi API quá nhiều). Các chiến lược tối ưu phổ biến gồm:
Chuẩn bị cho phỏng vấn Azure Data Factory đòi hỏi hiểu sâu cả khía cạnh kỹ thuật lẫn thực tiễn của nền tảng. Điều quan trọng là thể hiện kiến thức về tính năng cốt lõi của ADF và khả năng áp dụng chúng trong tình huống thực tế.
Dưới đây là những mẹo hay nhất để bạn sẵn sàng cho buổi phỏng vấn:
Azure Data Factory là công cụ mạnh mẽ để xây dựng giải pháp ETL trên đám mây, và chuyên môn về nó rất được săn đón trong lĩnh vực kỹ thuật dữ liệu!
Trong bài viết này, chúng tôi đã khám phá các câu hỏi phỏng vấn thiết yếu từ khái niệm tổng quát tới kỹ thuật và theo tình huống, nhấn mạnh tầm quan trọng của việc hiểu các tính năng và công cụ của ADF. Những ví dụ thực tế về quản lý pipeline, chuyển đổi dữ liệu và khắc phục sự cố minh họa các kỹ năng cốt lõi cần thiết trong môi trường ETL trên đám mây.
Để đào sâu hiểu biết về Microsoft Azure, hãy xem các khóa học nền tảng về kiến trúc, quản trị và quản trị tuân thủ Azure như Understanding Microsoft Azure, Understanding Microsoft Azure Architecture and Services và Understanding Microsoft Azure Management and Governance. Những tài nguyên này cung cấp góc nhìn giá trị về hệ sinh thái Azure rộng lớn, bổ trợ kiến thức về Azure Data Factory và chuẩn bị cho sự nghiệp thành công trong kỹ thuật dữ liệu.
Tìm hiểu thêm về Azure với các khóa học này!
Tracks
Courses
Courses