
Programma
Fondamenti di Microsoft Azure (AZ-900)
9 h
Azure Data Factory (ADF) è un servizio di integrazione dei dati basato su cloud offerto da Microsoft Azure.
Poiché le decisioni basate sui dati diventano un elemento centrale delle operazioni aziendali, la domanda di strumenti di data engineering in cloud è ai massimi storici! Dato che ADF è un servizio leader, le aziende cercano sempre più professionisti dei dati con esperienza pratica per gestire le pipeline e integrare i loro sistemi.
In questo articolo, vogliamo guidare gli aspiranti professionisti ADF attraverso le domande e risposte essenziali per i colloqui su Azure Data Factory — includendo domande generali, tecniche, avanzate e basate su scenari — e offrendo consigli per affrontare al meglio il colloquio.
Azure Data Factory è un servizio ETL basato su cloud che ti consente di creare workflow data-driven per orchestrare e automatizzare il movimento e la trasformazione dei dati. Il servizio si integra con varie origini e destinazioni di dati, sia on-premise sia nel cloud.
Man mano che i team adottano infrastrutture cloud-native, cresce l’esigenza di gestire i dati in ambienti eterogenei. L’integrazione di ADF con l’ecosistema Azure e con origini di terze parti facilita questo compito, rendendo l’esperienza con il servizio una competenza molto richiesta dalle organizzazioni.
Architettura BI automatizzata con Azure Data Factory. Fonte immagine: Microsoft
In questa sezione ci concentreremo sulle domande di base spesso poste nei colloqui per valutare la tua conoscenza generale di ADF. Queste domande testano la comprensione dei concetti fondamentali, dell’architettura e dei componenti.
Descrizione: questa domanda serve spesso a valutare se conosci i mattoni di base di ADF.
Esempio di risposta: I componenti principali di Azure Data Factory sono:
Descrizione: questa domanda verifica come ADF faciliti lo spostamento ibrido dei dati in modo sicuro ed efficiente.
Esempio di risposta: Azure Data Factory abilita lo spostamento sicuro dei dati tra cloud e ambienti on-premise tramite il Self-hosted Integration Runtime (IR), che funge da ponte tra ADF e le origini dati on-premise.
Ad esempio, quando si spostano dati da un SQL Server on-premise ad Azure Blob Storage, il self-hosted IR si collega in modo sicuro al sistema on-premise. Questo consente ad ADF di trasferire i dati garantendo la sicurezza tramite crittografia in transito e a riposo. È particolarmente utile per scenari ibridi in cui i dati sono distribuiti tra infrastrutture on-prem e cloud.
Descrizione: questa domanda valuta la tua comprensione di come ADF automatizzi e pianifichi le pipeline usando diversi tipi di trigger.
Esempio di risposta: in Azure Data Factory, i trigger servono ad avviare automaticamente l’esecuzione delle pipeline in base a condizioni o pianificazioni specifiche. Esistono tre tipi principali di trigger:
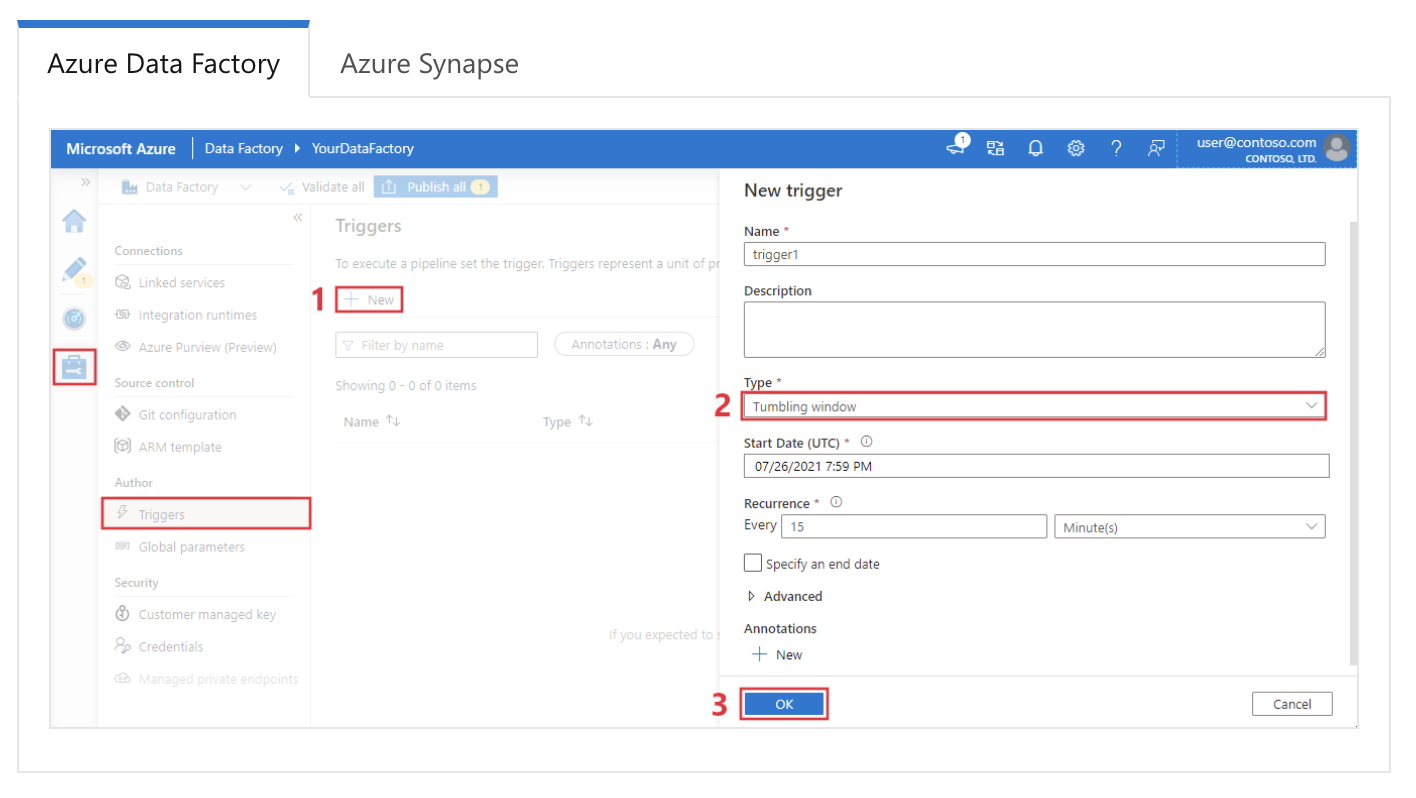
Configurazione di un trigger tumbling window in Azure Data Factory. Fonte immagine: Microsoft.
Descrizione: questa domanda valuta la tua conoscenza dei vari task che le pipeline ADF possono eseguire.
Esempio di risposta: Le pipeline di Azure Data Factory supportano diversi tipi di attività. Ecco le più comuni:
|
Tipo di attività |
Descrizione |
|
Spostamento dati |
Sposta i dati tra archivi supportati (ad es. Azure Blob Storage, SQL Database) con la Copy Activity. |
|
Trasformazione dati |
Include Data Flow Activity per la logica di trasformazione usando Spark, Mapping Data Flows per operazioni ETL e Wrangling Data Flows per la preparazione dei dati. |
|
Control flow |
Offre controllo sull’esecuzione della pipeline con attività come ForEach, If Condition, Switch, Wait e Until per creare logica condizionale. |
|
Esecuzione esterna |
Esegue applicazioni o funzioni esterne, incluse Azure Functions, Web Activities (chiamata a API REST) e Stored Procedure Activities per SQL. |
|
Attività personalizzate |
Consente l’esecuzione di codice personalizzato in Custom Activity usando .NET o servizi Azure Batch, offrendo flessibilità per esigenze avanzate di elaborazione dati. |
|
Altri servizi |
Supporta attività HDInsight, Databricks e Data Lake Analytics, integrandosi con altri servizi di analisi Azure per task complessi sui dati. |
Descrizione: questa domanda verifica la tua familiarità con gli strumenti di monitoraggio e debug di ADF.
Esempio di risposta: Azure Data Factory offre un’interfaccia solida per monitoraggio e debug tramite la scheda Monitor nel portale Azure. Qui posso tracciare le esecuzioni delle pipeline, vedere lo stato delle attività e diagnosticare i fallimenti. Ogni attività genera log che possono essere analizzati per individuare errori e risolvere problemi.
Inoltre, è possibile configurare Azure Monitor per inviare avvisi in base ai fallimenti delle pipeline o a problemi di performance. Per il debug, di solito inizio consultando i log delle attività fallite, analizzo i dettagli dell’errore e poi rieseguo la pipeline dopo aver risolto il problema.
Descrizione: questa domanda verifica se sei aggiornato sull’evoluzione più recente della piattaforma dati di Microsoft.
Esempio di risposta: Pur condividendo lo stesso motore, Data Factory in Fabric è un’offerta SaaS (Software as a Service) integrata nell’ecosistema Fabric, mentre Azure Data Factory (ADF) è una risorsa PaaS (Platform as a Service). Le differenze chiave includono:
Descrizione: questa domanda valuta la tua conoscenza dei meccanismi di sicurezza di ADF per proteggere i dati lungo il loro ciclo di vita.
Esempio di risposta: Azure Data Factory garantisce la sicurezza dei dati attraverso diversi meccanismi.
Innanzitutto, utilizza la crittografia dei dati sia in transito sia a riposo, adottando protocolli come TLS e AES per proteggere i trasferimenti. ADF si integra con Azure Active Directory (AAD) per l’autenticazione e usa il controllo degli accessi basato sui ruoli (RBAC) per limitare chi può accedere e gestire la factory.
Inoltre, le Managed Identity consentono ad ADF di accedere in modo sicuro ad altri servizi Azure senza esporre credenziali. Per la sicurezza di rete, ADF supporta i Private Endpoint, assicurando che il traffico rimanga all’interno della rete Azure e aggiungendo un ulteriore livello di protezione.
Descrizione: questa domanda valuta la tua comprensione dei ruoli diversi che Linked Service e Dataset svolgono in ADF.
Esempio di risposta: in Azure Data Factory, un Linked Service definisce la connessione a un’origine dati esterna o a un servizio di calcolo, in modo simile a una stringa di connessione. Include le informazioni di autenticazione necessarie per connettersi alla risorsa.
Un Dataset, invece, rappresenta i dati specifici con cui lavorerai, come una tabella in un database o un file in Blob Storage.
Mentre il Linked Service definisce dove si trovano i dati, il Dataset descrive com’è fatto e com’è strutturato. Questi due componenti lavorano insieme per facilitare lo spostamento e la trasformazione dei dati.
Le domande tecniche si concentrano spesso sulla comprensione di funzionalità specifiche, della loro implementazione e di come lavorano insieme per costruire pipeline dati efficaci. Queste domande valutano la tua esperienza pratica e la conoscenza dei componenti e delle capacità principali di ADF.
Descrizione: questa domanda verifica la tua capacità di implementare strategie di gestione degli errori nelle pipeline ADF.
Esempio di risposta: la gestione degli errori in Azure Data Factory può essere implementata usando Retry Policies e attività di gestione errori. ADF offre meccanismi di retry integrati, in cui puoi configurare il numero di tentativi e l’intervallo tra i retry se un’attività fallisce.
Per esempio, se una Copy Activity fallisce per un problema di rete temporaneo, puoi configurare l’attività per riprovare 3 volte con un intervallo di 10 minuti tra i tentativi.
Inoltre, impostare le condizioni di dipendenza dell’attività (Failure, Completion, Skipped) può attivare azioni specifiche a seconda che un’attività abbia successo o fallisca.
Ad esempio, potrei definire un flusso di pipeline in modo che, al fallimento di un’attività, venga eseguita un’attività personalizzata di gestione errori, come l’invio di un avviso o l’esecuzione di un processo di fallback.
Descrizione: questa domanda valuta la tua comprensione dell’infrastruttura di calcolo alla base dello spostamento dei dati e dell’instradamento delle attività in ADF.
Esempio di risposta: l’Integration Runtime (IR) è l’infrastruttura di calcolo che Azure Data Factory usa per eseguire lo spostamento e la trasformazione dei dati e l’inoltro delle attività. È centrale nella gestione di come e dove vengono elaborati i dati e può essere ottimizzato in base a origine, destinazione e requisiti di trasformazione. Per contesto, esistono tre tipi di IR:
|
Tipo di Integration Runtime (IR) |
Descrizione |
|
Azure Integration Runtime |
Usato per attività di spostamento e trasformazione dati all’interno dei data center Azure. Supporta attività di copia, trasformazioni dei data flow e instrada attività verso risorse Azure. |
|
Self-hosted Integration Runtime |
Installato on-premise o su macchine virtuali in una rete privata per abilitare l’integrazione dei dati tra risorse on-premise, private e Azure. Utile per copiare dati da on-premise verso Azure. |
|
Azure-SSIS Integration Runtime |
Consente di lift-and-shift dei pacchetti SQL Server Integration Services (SSIS) in Azure, supportando l’esecuzione nativa dei pacchetti SSIS all’interno di Azure Data Factory. Ideale per chi vuole migrare i carichi SSIS senza lavori estesi di reingegnerizzazione. |
Descrizione: questa domanda verifica la tua comprensione di come funziona la parametrizzazione in ADF per creare pipeline riutilizzabili e flessibili.
Esempio di risposta: la parametrizzazione in Azure Data Factory consente un’esecuzione dinamica delle pipeline, in cui puoi passare valori diversi a ogni run.
Per esempio, in una Copy Activity potrei usare parametri per specificare dinamicamente il percorso del file sorgente e la cartella di destinazione. Definirei i parametri a livello di pipeline e li passerei al dataset o all’attività pertinente.
Ecco un semplice esempio:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}La parametrizzazione rende le pipeline riutilizzabili e consente di scalare facilmente regolando gli input in modo dinamico durante il runtime.
Descrizione: questa domanda valuta la tua conoscenza della trasformazione dei dati in ADF senza necessità di servizi di calcolo esterni.
Esempio di risposta: Un Mapping Data Flow in Azure Data Factory ti consente di eseguire trasformazioni sui dati senza scrivere codice o spostare i dati al di fuori dell’ecosistema ADF. Fornisce un’interfaccia visiva con cui puoi costruire trasformazioni complesse.
I data flow vengono eseguiti su cluster Spark nell’ambiente gestito di ADF, consentendo trasformazioni scalabili ed efficienti.
Per esempio, in uno scenario tipico di trasformazione, potrei usare un data flow per unire due dataset, aggregare i risultati e scrivere l’output in una nuova destinazione — tutto in modo visivo e senza servizi esterni come Databricks.
Descrizione: questa domanda testa la tua capacità di gestire cambiamenti dinamici dello schema durante la trasformazione dei dati.
Esempio di risposta: Lo schema drift si riferisce ai cambiamenti della struttura dei dati sorgente nel tempo.
Azure Data Factory affronta lo schema drift offrendo l’opzione Allow Schema Drift nei Mapping Data Flow. Ciò consente ad ADF di adattarsi automaticamente alle variazioni dello schema dei dati in ingresso, come l’aggiunta o la rimozione di colonne, senza dover ridefinire l’intero schema.
Abilitando lo schema drift, posso configurare una pipeline per mappare dinamicamente le colonne anche se cambia lo schema della fonte.
Opzione Allow schema drift in Azure Data Factory. Fonte immagine: Microsoft
Descrizione: questa domanda valuta la tua familiarità con metodi moderni di ingestion continua rispetto all’elaborazione batch.
Esempio di risposta: la risorsa CDC in ADF fornisce un modo low-code per replicare continuamente i dati modificati dalle origini (come un database SQL o Cosmos) verso una destinazione senza logiche di watermark complesse.
A differenza di un trigger di pipeline standard che gira a intervalli, la risorsa CDC funziona in continuo (o in micro-batch), tracciando automaticamente insert, update e delete alla sorgente e applicandoli al target. È ideale per scenari che richiedono sincronizzazione dei dati quasi real time.
Le domande avanzate approfondiscono funzionalità più complesse di ADF, con focus su ottimizzazione delle performance, casi d’uso reali e decisioni architetturali avanzate.
Queste domande servono a valutare la tua esperienza in scenari complessi e la capacità di risolvere problemi impegnativi usando ADF.
Descrizione: questa domanda valuta la tua capacità di diagnosticare e migliorare l’efficienza della pipeline.
Esempio di risposta: seguo in genere diverse strategie per ottimizzare le prestazioni di una pipeline ADF.
Innanzitutto sfrutto il parallelismo usando Concurrent Pipeline Runs per elaborare i dati in parallelo dove possibile. Uso anche il Partitioning nella Copy Activity per suddividere dataset di grandi dimensioni e trasferire più blocchi in contemporanea.
Un’altra ottimizzazione importante è scegliere l’Integration Runtime più adatto in base a fonte e requisiti di trasformazione. Per esempio, usare un Self-hosted IR per dati on-premise può accelerare i trasferimenti on-prem verso cloud.
Inoltre, abilitare lo Staging nella Copy Activity può migliorare le prestazioni bufferizzando i dataset di grandi dimensioni prima del caricamento finale.
Descrizione: questa domanda valuta la tua comprensione della gestione sicura delle credenziali in ADF.
Esempio di risposta: Azure Key Vault ha un ruolo fondamentale nel proteggere informazioni sensibili come stringhe di connessione, password e chiavi API all’interno di ADF. Invece di inserire i segreti direttamente nelle pipeline o nei Linked Service, utilizzo Key Vault per memorizzarli e gestirli.
La pipeline ADF può recuperare in modo sicuro i segreti da Key Vault durante il runtime, assicurando che le credenziali restino protette e non esposte nel codice. Ad esempio, quando configuro un Linked Service verso un Azure SQL Database, uso un riferimento a un secret in Key Vault per autenticarmi in modo sicuro.
Descrizione: questa domanda verifica la tua familiarità con il controllo versione e la distribuzione automatizzata in ADF.
Esempio di risposta: Azure Data Factory si integra con Azure DevOps o GitHub per workflow CI/CD. In genere configuro ADF per connettersi a un repository Git, abilito il versionamento per pipeline, dataset e Linked Service. Il processo prevede la creazione di branch, le modifiche in ambiente di sviluppo e il commit al repository.
Per la distribuzione, ADF supporta gli ARM template che possono essere esportati e usati in ambienti diversi, come staging e produzione. Usando pipeline, posso automatizzare il deployment, assicurando che le modifiche siano testate e promosse in modo efficiente tra i vari ambienti.
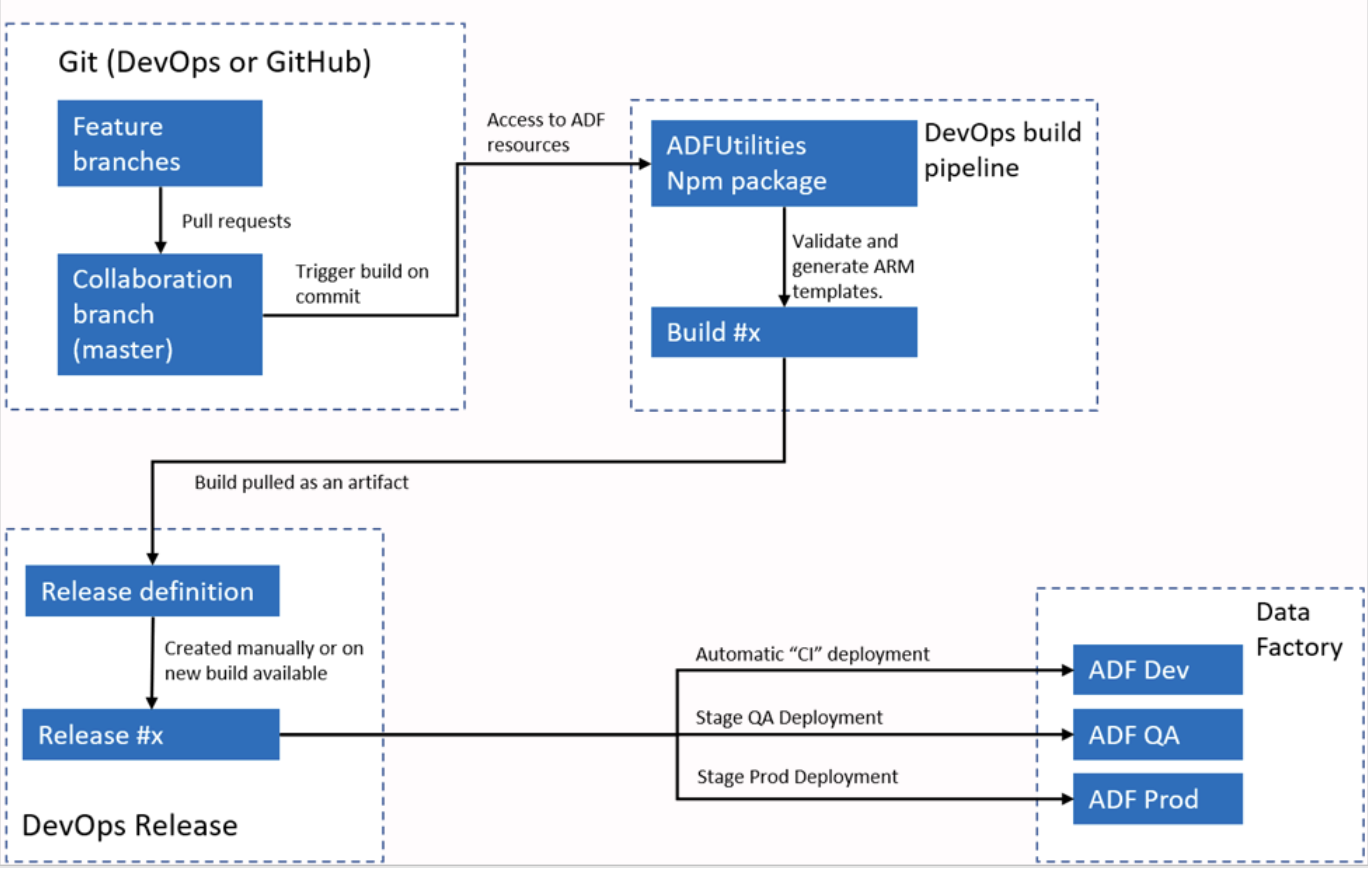
Workflow CI/CD automatizzato di Azure Data Factory. Fonte immagine: Microsoft.
Descrizione: questa domanda valuta la tua comprensione delle capacità di ADF nella gestione di ambienti dati ibridi.
Esempio di risposta: progettare una pipeline ibrida con ADF richiede l’uso del Self-hosted Integration Runtime (IR) per fare da ponte tra ambienti on-premise e cloud. L’IR viene installato su una macchina all’interno della rete on-premise, consentendo ad ADF di spostare dati in modo sicuro tra risorse on-premise e cloud come Azure Blob Storage o Azure SQL Database.
Ad esempio, quando devo trasferire dati da SQL Server on-premise ad Azure Data Lake, configuro il Self-hosted IR per accedere in sicurezza a SQL Server, definisco i dataset per sorgente e destinazione e uso una Copy Activity per spostare i dati. Posso anche aggiungere trasformazioni o fasi di pulizia usando i Mapping Data Flow.
Descrizione: questa domanda verifica la tua capacità di configurare mappature di schema dinamiche in data flow complessi.
Esempio di risposta: il mapping dinamico in un Mapping Data Flow offre flessibilità quando lo schema dei dati sorgente può cambiare. Lo implemento usando la funzione Auto Mapping del Data Flow, che mappa automaticamente le colonne di origine a quelle di destinazione per nome.
Per scenari più complessi, uso Derived Columns e il linguaggio di espressione nei Data Flow per assegnare o modificare dinamicamente le colonne in base ai loro metadati. Questo approccio aiuta con lo schema drift o quando la pipeline deve gestire più schemi di origine diversi senza rimappature manuali.
Descrizione: questa domanda verifica la tua capacità di progettare pipeline conformi agli standard di data governance aziendale.
Esempio di risposta: ADF si integra nativamente con Microsoft Purview per inviare i dati di lineage. Quando una pipeline viene eseguita, ADF invia a Purview metadati che descrivono:
Questo consente ai data steward di visualizzare il flusso dei dati nell’organizzazione. Li colleghi registrando l’istanza ADF nel portale di governance di Purview.
Le domande comportamentali e basate su scenari si concentrano su come i candidati applicano le competenze tecniche in situazioni reali.
Queste domande aiutano a valutare capacità di problem solving, troubleshooting e ottimizzazione in workflow dati complessi. Offrono anche insight sul processo decisionale e sull’esperienza nella gestione delle sfide legate a integrazione dati e processi ETL.
Descrizione: questa domanda valuta le tue capacità di problem solving, soprattutto nella gestione di fallimenti o problemi imprevisti delle pipeline.
Esempio di risposta: in un progetto, avevo una pipeline che falliva costantemente durante il trasferimento di dati da SQL Server on-premise ad Azure Blob Storage.
I log degli errori indicavano un timeout durante lo spostamento dei dati. Per il troubleshooting, ho innanzitutto controllato la configurazione del Self-hosted Integration Runtime (IR), responsabile della connessione ai dati on-premise.
Dall’analisi ho riscontrato che la macchina che ospitava l’IR aveva un uso elevato della CPU, causando ritardi nel trasferimento.
Per risolvere, ho aumentato la potenza di calcolo della macchina e distribuito il carico partizionando i dati in blocchi più piccoli tramite le impostazioni della Copy Activity.
Questo ha consentito l’elaborazione parallela, riducendo i tempi di caricamento ed evitando i timeout. Dopo le modifiche, la pipeline è andata a buon fine, eliminando l’errore.
Descrizione: questa domanda valuta la tua capacità di identificare e implementare tecniche di ottimizzazione nei workflow dati.
Esempio di risposta: In un progetto dove dovevamo elaborare grandi volumi di dati finanziari da più fonti, la pipeline iniziale impiegava troppo tempo per via della mole di dati. Per ottimizzare, ho abilitato il parallelismo configurando più Copy Activity in esecuzione concorrente, ognuna su una diversa partizione del dataset.
Successivamente, ho usato la funzione di staging nella Copy Activity per bufferizzare temporaneamente i dati in Azure Blob Storage prima di ulteriori elaborazioni, migliorando notevolmente il throughput. Ho anche ottimizzato i Data Flow facendo caching delle tabelle di lookup usate nelle trasformazioni.
Questi accorgimenti hanno migliorato le prestazioni della pipeline del 40%, riducendo i tempi di esecuzione.
Descrizione: questa domanda verifica come gestisci cambiamenti imprevisti dello schema garantendo il funzionamento delle pipeline.
Esempio di risposta: sì, in un progetto lo schema di una fonte dati (un’API esterna) è cambiato inaspettatamente quando è stata aggiunta una nuova colonna. Questo ha causato il fallimento della pipeline poiché lo schema nel Mapping Data Flow non era più allineato.
Per risolvere, ho abilitato l’opzione Allow Schema Drift nel Data Flow, che ha permesso alla pipeline di rilevare e gestire automaticamente le variazioni dello schema.
Inoltre, ho configurato il mapping dinamico delle colonne usando Derived Columns, garantendo che la nuova colonna venisse acquisita senza hardcoding dei nomi. Questo ha reso la pipeline in grado di adattarsi a futuri cambiamenti di schema senza interventi manuali.
Descrizione: questa domanda valuta la tua capacità di gestire integrazioni multi-fonte, requisito comune nei processi ETL complessi.
Esempio di risposta: in un progetto recente ho dovuto integrare dati da tre fonti: SQL Server on-premise, Azure Data Lake e una REST API. Ho usato una combinazione di Self-hosted Integration Runtime per la connessione a SQL Server on-premise e Azure Integration Runtime per i servizi cloud.
Ho creato una pipeline che usava la Copy Activity per prelevare i dati da SQL Server e dalla REST API, trasformarli con i Mapping Data Flow e combinarli con i dati in Azure Data Lake.
Parametrizzando le pipeline, ho garantito flessibilità nella gestione di dataset e pianificazioni differenti. Questo ha abilitato l’integrazione multi-fonte, fondamentale per la piattaforma di analytics del cliente.
Descrizione: questa domanda esamina come identifichi e gestisci problemi di data quality all’interno dei workflow.
Esempio di risposta: In un caso, stavo lavorando su una pipeline che estraeva dati clienti da un sistema CRM. Tuttavia, i dati contenevano valori mancanti e duplicati, influenzando i report finali. Per affrontare questi problemi di qualità, ho inserito un Data Flow nella pipeline per eseguire operazioni di pulizia.
Ho usato filtri per rimuovere i duplicati e uno split condizionale per gestire i valori mancanti. Ho impostato un lookup per eventuali dati mancanti o errati per recuperare valori di default da un dataset di riferimento. Al termine, la qualità dei dati è migliorata sensibilmente, garantendo analisi a valle accurate e affidabili.
Descrizione: questa domanda testa la tua esperienza con trasformazioni avanzate usando ADF.
Esempio di risposta: in un progetto di reporting finanziario ho dovuto unire dati transazionali da più fonti, applicare aggregazioni e generare report di sintesi per diverse regioni. La sfida era che ogni fonte aveva struttura e convenzioni di naming leggermente diverse. Ho implementato la trasformazione usando i Mapping Data Flow.
Per prima cosa ho standardizzato i nomi delle colonne su tutti i dataset con Derived Columns. Poi ho applicato aggregazioni per calcolare metriche specifiche per regione, come vendite totali e valore medio transazione. Infine, ho usato una trasformazione pivot per rimodellare i dati in modo da agevolare il reporting. L’intera trasformazione è stata eseguita in ADF, sfruttando le trasformazioni integrate e l’infrastruttura scalabile.
Descrizione: questa domanda valuta la tua comprensione delle pratiche di sicurezza dei dati in ADF.
Esempio di risposta: In un progetto, abbiamo gestito dati sensibili dei clienti da trasferire in sicurezza da SQL Server on-premise ad Azure SQL Database. Ho usato Azure Key Vault per memorizzare le credenziali del database e proteggere i dati, evitando che informazioni sensibili come le password fossero hardcodate nella pipeline o nei Linked Service.
Inoltre, ho implementato la cifratura dei dati durante lo spostamento abilitando connessioni SSL tra SQL Server on-premise e Azure.
Ho anche usato RBAC (role-based access control) per limitare l’accesso alla pipeline ADF, garantendo che solo utenti autorizzati potessero avviarla o modificarla. Questa configurazione ha garantito sia il trasferimento sicuro dei dati sia una corretta gestione degli accessi.
Descrizione: questa domanda valuta la tua capacità di implementare esecuzioni di pipeline guidate da eventi.
Esempio di risposta: In uno scenario, la pipeline doveva essere eseguita ogni volta che un nuovo file con dati di vendita veniva caricato su Azure Blob Storage. Per implementarlo, ho usato un Event-Based Trigger in ADF. Il trigger era impostato per ascoltare gli eventi Blob Created in un container specifico e, non appena veniva caricato un nuovo file, attivava automaticamente la pipeline.
Questo approccio event-driven ha garantito che la pipeline girasse solo quando erano disponibili nuovi dati, eliminando la necessità di esecuzioni manuali o pianificate. La pipeline poi processava il file, lo trasformava e lo caricava nel data warehouse per ulteriori analisi.
Descrizione: questa domanda valuta la tua esperienza nel migrare processi ETL tradizionali al cloud usando ADF.
Esempio di risposta: in un progetto di migrazione di un processo ETL basato su SSIS dall’on-premise al cloud, ho usato ADF con l’Azure-SSIS Integration Runtime.
Per prima cosa ho valutato i pacchetti SSIS esistenti per assicurarne la compatibilità con ADF e ho apportato le modifiche necessarie per gestire origini dati cloud.
Ho configurato l’Azure-SSIS IR per eseguire i pacchetti SSIS nel cloud mantenendo i workflow esistenti. Per il nuovo ambiente cloud, ho anche sostituito alcune attività ETL tradizionali con componenti nativi ADF come Copy Activity e Mapping Data Flow, migliorando complessivamente performance e scalabilità dei workflow.
Descrizione: questa domanda valuta la tua maturità operativa e la comprensione del modello di billing di ADF.
Esempio di risposta: inizierei analizzando il report Pipeline Run Consumption in Azure Monitor per identificare i driver di costo (ad es. molte ore di compute dei Data Flow o chiamate API eccessive). Strategie di ottimizzazione comuni includono:
Prepararsi a un colloquio su Azure Data Factory richiede una solida comprensione degli aspetti tecnici e pratici della piattaforma. È essenziale dimostrare la conoscenza delle funzionalità chiave di ADF e la capacità di applicarle in scenari reali.
Ecco i miei migliori consigli per arrivare pronti al colloquio:
Azure Data Factory è uno strumento potente per creare soluzioni ETL in cloud, e la sua padronanza è molto richiesta nel mondo del data engineering!
In questo articolo, abbiamo esplorato domande essenziali per i colloqui, dai concetti generali a quelli tecnici e basati su scenari, sottolineando l’importanza della conoscenza delle funzionalità e degli strumenti di ADF. Gli esempi reali di gestione pipeline, trasformazione dati e troubleshooting illustrano le competenze chiave richieste in un ambiente ETL basato sul cloud.
Per approfondire Microsoft Azure, valuta corsi fondamentali su architettura, gestione e governance di Azure, come Understanding Microsoft Azure, Understanding Microsoft Azure Architecture and Services e Understanding Microsoft Azure Management and Governance. Queste risorse offrono spunti preziosi sull’ecosistema Azure, completando la tua conoscenza di Azure Data Factory e preparandoti a una carriera di successo nel data engineering.
Approfondisci Azure con questi corsi!
Programma
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

