
Program
Microsoft Azure Fundamentals (AZ-900)
9 Hr
Azure Data Factory (ADF) adalah layanan integrasi data berbasis cloud yang disediakan oleh Microsoft Azure.
Seiring pengambilan keputusan berbasis data menjadi aspek sentral operasi bisnis, permintaan terhadap alat rekayasa data berbasis cloud mencapai titik tertinggi! Karena ADF adalah layanan terdepan, perusahaan semakin mencari profesional data dengan pengalaman langsung untuk mengelola pipeline data dan mengintegrasikan sistem mereka.
Dalam artikel ini, kami bertujuan membimbing calon profesional ADF melalui pertanyaan dan jawaban wawancara Azure Data Factory yang esensial—mencakup pertanyaan umum, teknis, lanjutan, dan berbasis skenario—serta memberikan kiat untuk sukses dalam wawancara.
Azure Data Factory adalah layanan ETL berbasis cloud yang memungkinkan Anda membuat workflow berbasis data untuk mengorkestrasi dan mengotomatisasi pemindahan dan transformasi data. Layanan ini terintegrasi dengan berbagai sumber dan tujuan data, baik on-premise maupun di cloud.
Saat tim beralih ke infrastruktur cloud-native, kebutuhan untuk mengelola data di berbagai lingkungan semakin meningkat. Integrasi ADF dengan ekosistem Azure dan sumber data pihak ketiga memfasilitasi hal ini, menjadikan keahlian menggunakan layanan tersebut sangat dicari oleh organisasi.
Arsitektur BI otomatis menggunakan Azure Data Factory. Sumber gambar: Microsoft
Pada bagian ini, kami berfokus pada pertanyaan-pertanyaan dasar yang sering diajukan dalam wawancara untuk mengukur pengetahuan umum Anda tentang ADF. Pertanyaan ini menguji pemahaman Anda tentang konsep, arsitektur, dan komponen dasar.
Deskripsi: Pertanyaan ini sering diajukan untuk menilai apakah Anda memahami blok bangunan ADF.
Contoh jawaban: Komponen utama Azure Data Factory adalah:
Deskripsi: Pertanyaan ini menguji pemahaman Anda tentang bagaimana Azure Data Factory memfasilitasi perpindahan data hibrida secara aman dan efisien.
Contoh jawaban: Azure Data Factory memungkinkan perpindahan data yang aman antara lingkungan cloud dan on-premise melalui Self-hosted Integration Runtime (IR), yang bertindak sebagai jembatan antara ADF dan sumber data on-premise.
Misalnya, saat memindahkan data dari SQL Server on-premise ke Azure Blob Storage, self-hosted IR terhubung dengan aman ke sistem on-premise. Ini memungkinkan ADF mentransfer data sambil memastikan keamanan melalui enkripsi saat transit dan saat tersimpan. Ini sangat berguna untuk skenario cloud hibrida di mana data tersebar di infrastruktur on-prem dan cloud.
Deskripsi: Pertanyaan ini mengevaluasi pemahaman Anda tentang bagaimana ADF mengotomatisasi dan menjadwalkan pipeline menggunakan berbagai jenis trigger.
Contoh jawaban: Di Azure Data Factory, trigger digunakan untuk secara otomatis memulai eksekusi pipeline berdasarkan kondisi atau jadwal tertentu. Ada tiga jenis trigger utama:
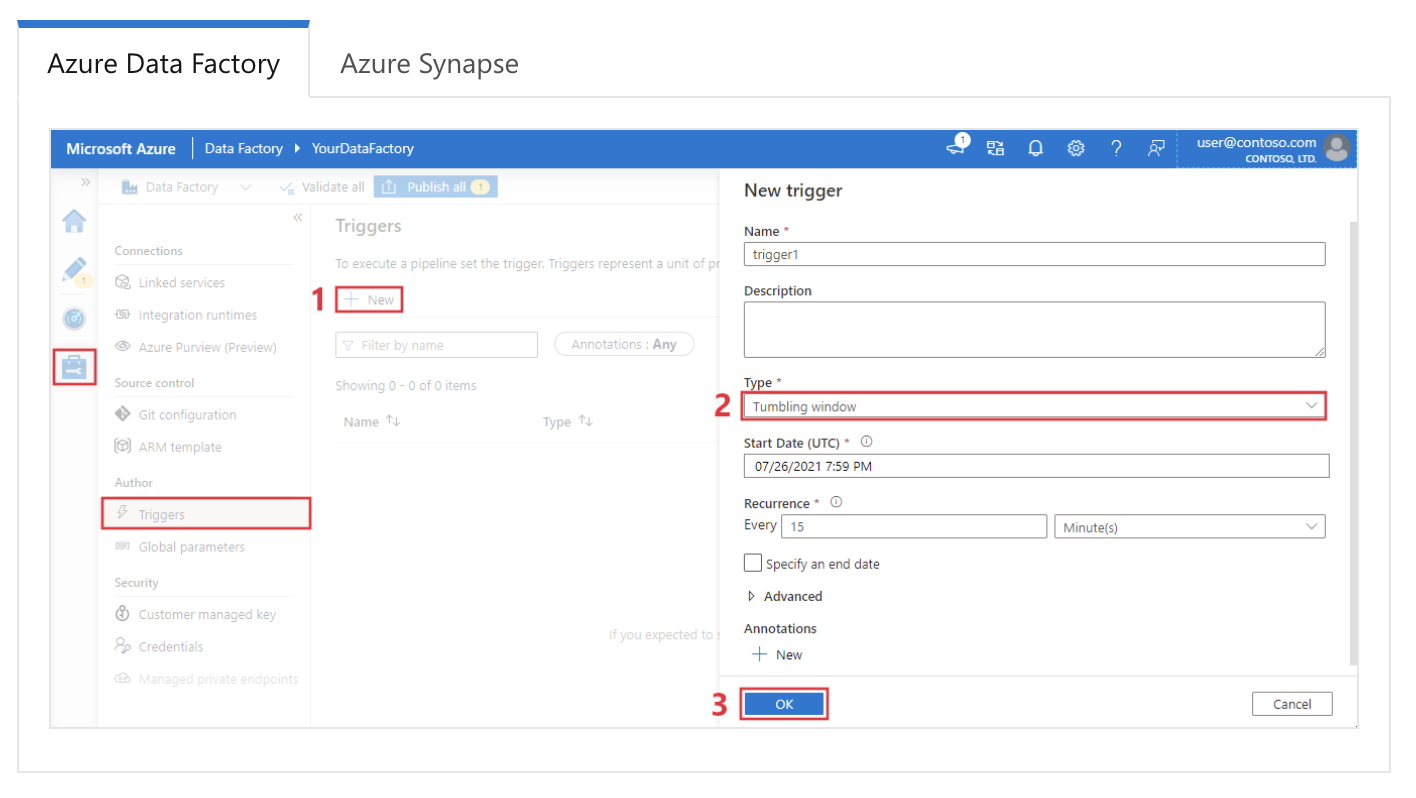
Konfigurasi tumbling window trigger di Azure Data Factory. Sumber gambar: Microsoft.
Deskripsi: Pertanyaan ini menilai pengetahuan Anda tentang berbagai tugas yang dapat dilakukan pipeline ADF.
Contoh jawaban: Pipeline Azure Data Factory mendukung beberapa jenis aktivitas. Berikut yang paling umum:
|
Jenis aktivitas |
Deskripsi |
|
Pemindahan data |
Memindahkan data antar data store yang didukung (misalnya, Azure Blob Storage, SQL Database) dengan Copy Activity. |
|
Transformasi data |
Mencakup Data Flow Activity untuk logika transformasi data menggunakan Spark, Mapping Data Flows untuk operasi ETL, dan Wrangling Data Flows untuk persiapan data. |
|
Alur kendali |
Memberikan kontrol atas eksekusi pipeline menggunakan aktivitas seperti ForEach, If Condition, Switch, Wait, dan Until untuk membuat logika kondisional. |
|
Eksekusi eksternal |
Mengeksekusi aplikasi atau fungsi eksternal, termasuk Azure Functions, Web Activities (memanggil REST API), dan Stored Procedure Activities untuk SQL. |
|
Aktivitas kustom |
Memungkinkan eksekusi kode kustom dalam Custom Activity menggunakan .NET atau layanan Azure Batch, memberikan fleksibilitas untuk kebutuhan pemrosesan data lanjutan. |
|
Layanan lain |
Mendukung aktivitas HDInsight, Databricks, dan Data Lake Analytics, yang terintegrasi dengan layanan analitik Azure lainnya untuk tugas data kompleks. |
Deskripsi: Pertanyaan ini memeriksa familiaritas Anda dengan alat pemantauan dan debug ADF.
Contoh jawaban: Azure Data Factory menyediakan antarmuka pemantauan dan debug yang andal melalui tab Monitor di portal Azure. Di sini saya dapat melacak run pipeline, melihat status aktivitas, dan mendiagnosis kegagalan. Setiap aktivitas menghasilkan log yang bisa ditinjau untuk mengidentifikasi error dan memecahkan masalah.
Selain itu, Azure Monitor dapat dikonfigurasi untuk mengirim peringatan berdasarkan kegagalan pipeline atau masalah kinerja. Untuk debugging, saya biasanya mulai dengan melihat log aktivitas yang gagal, meninjau detail error, lalu menjalankan ulang pipeline setelah memperbaiki masalah.
Deskripsi: Pertanyaan ini menguji apakah Anda mengikuti evolusi terbaru platform data Microsoft.
Contoh jawaban: Meskipun keduanya berbagi mesin yang sama, Data Factory di Fabric adalah penawaran SaaS (Software as a Service) yang terintegrasi ke dalam ekosistem Fabric, sedangkan Azure Data Factory (ADF) adalah sumber daya PaaS (Platform as a Service). Perbedaan kunci meliputi:
Deskripsi: Pertanyaan ini mengevaluasi pengetahuan Anda tentang mekanisme keamanan ADF untuk melindungi data sepanjang siklus hidupnya.
Contoh jawaban: Azure Data Factory memastikan keamanan data melalui beberapa mekanisme.
Pertama, ADF menggunakan enkripsi untuk data saat transit dan saat tersimpan, dengan protokol seperti TLS dan AES untuk mengamankan transfer data. ADF terintegrasi dengan Azure Active Directory (AAD) untuk autentikasi dan menggunakan Role-Based Access Control (RBAC) untuk membatasi siapa yang dapat mengakses dan mengelola factory.
Selain itu, Managed Identity memungkinkan ADF mengakses layanan Azure lainnya secara aman tanpa mengekspos kredensial. Untuk keamanan jaringan, ADF mendukung Private Endpoint, memastikan lalu lintas data tetap berada dalam jaringan Azure dan menambahkan lapisan perlindungan lainnya.
Deskripsi: Pertanyaan ini menilai pemahaman Anda tentang peran berbeda yang dimainkan Linked Service dan Dataset di ADF.
Contoh jawaban: Di Azure Data Factory, Linked Service mendefinisikan koneksi ke sumber data eksternal atau layanan komputasi, mirip dengan connection string. Ini mencakup informasi autentikasi yang diperlukan untuk terhubung ke sumber daya.
Sementara itu, Dataset merepresentasikan data spesifik yang akan Anda gunakan, seperti tabel di database atau file di Blob Storage.
Jika Linked Service mendefinisikan di mana data berada, Dataset menjelaskan seperti apa data tersebut dan bagaimana strukturnya. Kedua komponen ini bekerja bersama untuk memfasilitasi pemindahan dan transformasi data.
Pertanyaan teknis sering berfokus pada pemahaman Anda tentang fitur spesifik, implementasinya, dan bagaimana fitur-fitur tersebut bekerja bersama untuk membangun pipeline data yang efektif. Pertanyaan ini menilai pengalaman langsung dan pengetahuan Anda tentang komponen inti serta kapabilitas ADF.
Deskripsi: Pertanyaan ini menguji kemampuan Anda menerapkan strategi penanganan error dalam pipeline ADF.
Contoh jawaban: Penanganan error di Azure Data Factory dapat diterapkan menggunakan Retry Policy dan Error Handling Activity. ADF menawarkan mekanisme retry bawaan, di mana Anda dapat mengonfigurasi jumlah percobaan ulang dan interval antar percobaan jika suatu aktivitas gagal.
Misalnya, jika Copy Activity gagal karena masalah jaringan sementara, Anda dapat mengonfigurasinya untuk mencoba ulang 3 kali dengan interval 10 menit di antara setiap percobaan.
Selain itu, atur Dependency Condition Activity seperti Failure, Completion, dan Skipped untuk memicu tindakan tertentu bergantung pada apakah suatu aktivitas berhasil atau gagal.
Contohnya, saya dapat mendefinisikan alur pipeline sehingga saat suatu aktivitas gagal, aktivitas penanganan error kustom seperti mengirim peringatan atau mengeksekusi proses fallback akan dijalankan.
Deskripsi: Pertanyaan ini mengevaluasi pemahaman Anda tentang infrastruktur komputasi di balik pemindahan data dan pengiriman aktivitas di ADF.
Contoh jawaban: Integration Runtime (IR) adalah infrastruktur komputasi yang digunakan Azure Data Factory untuk melakukan pemindahan data, transformasi, dan pengiriman aktivitas. IR menjadi pusat untuk mengelola bagaimana dan di mana data diproses, dan dapat dioptimalkan berdasarkan sumber, tujuan, dan kebutuhan transformasi. Untuk konteks lebih lanjut, ada tiga tipe IR:
|
Tipe Integration Runtime (IR) |
Deskripsi |
|
Azure Integration Runtime |
Digunakan untuk aktivitas pemindahan dan transformasi data dalam pusat data Azure. Mendukung copy activity, transformasi data flow, dan mengirim aktivitas ke sumber daya Azure. |
|
Self-hosted Integration Runtime |
Diinstal di on-premise atau mesin virtual dalam jaringan privat untuk memungkinkan integrasi data lintas on-premise, privat, dan sumber daya Azure. Berguna untuk menyalin data dari on-premise ke Azure. |
|
Azure-SSIS Integration Runtime |
Memungkinkan Anda melakukan lift-and-shift paket SQL Server Integration Services (SSIS) yang ada ke Azure, mendukung eksekusi paket SSIS secara native di dalam Azure Data Factory. Ideal bagi pengguna yang ingin memigrasikan beban kerja SSIS tanpa pengerjaan ulang yang ekstensif. |
Deskripsi: Pertanyaan ini memeriksa pemahaman Anda tentang cara kerja parameterisasi di ADF untuk membuat pipeline yang dapat digunakan ulang dan fleksibel.
Contoh jawaban: Parameterisasi di Azure Data Factory memungkinkan eksekusi pipeline yang dinamis, di mana Anda dapat memberikan nilai berbeda pada setiap run.
Sebagai contoh, dalam Copy Activity, saya dapat menggunakan parameter untuk menentukan path file sumber dan folder tujuan secara dinamis. Saya akan mendefinisikan parameter pada level pipeline dan meneruskannya ke dataset atau activity yang relevan.
Berikut contoh sederhana:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}Parameterisasi membuat pipeline dapat digunakan ulang dan memungkinkan skala dengan mudah dengan menyesuaikan input secara dinamis saat runtime.
Deskripsi: Pertanyaan ini mengevaluasi pengetahuan Anda tentang transformasi data di ADF tanpa perlu layanan komputasi eksternal.
Contoh jawaban: Mapping Data Flow di Azure Data Factory memungkinkan Anda melakukan transformasi pada data tanpa menulis kode atau memindahkan data ke luar ekosistem ADF. Data Flow menyediakan antarmuka visual untuk membangun transformasi kompleks.
Data flow dieksekusi pada cluster Spark di lingkungan terkelola ADF, yang memungkinkan transformasi data yang skalabel dan efisien.
Sebagai contoh, dalam skenario transformasi tipikal, saya dapat menggunakan data flow untuk menggabungkan dua dataset, melakukan agregasi hasil, dan menulis output ke tujuan baru—semua secara visual dan tanpa layanan seperti Databricks di luar ADF.
Deskripsi: Pertanyaan ini menguji kemampuan Anda mengelola perubahan skema yang dinamis selama transformasi data.
Contoh jawaban: Schema drift mengacu pada perubahan struktur data sumber dari waktu ke waktu.
Azure Data Factory mengatasinya dengan opsi Allow Schema Drift di Mapping Data Flows. Ini memungkinkan ADF menyesuaikan secara otomatis terhadap perubahan skema data yang masuk, seperti penambahan atau penghapusan kolom, tanpa perlu mendefinisikan ulang seluruh skema.
Dengan mengaktifkan schema drift, saya dapat mengonfigurasi pipeline untuk memetakan kolom secara dinamis meskipun skema sumber berubah.
Opsi Allow schema drift di Azure Data Factory. Sumber gambar: Microsoft
Deskripsi: Pertanyaan ini mengevaluasi pemahaman Anda tentang metode pemasukan data berkelanjutan yang modern dibandingkan pemrosesan batch.
Contoh jawaban: Resource CDC di ADF menyediakan cara low-code untuk mereplikasi data yang berubah secara kontinu dari sumber (seperti database SQL atau Cosmos) ke tujuan tanpa logika watermark yang kompleks.
Berbeda dengan trigger pipeline standar yang berjalan terjadwal, resource CDC berjalan terus-menerus (atau dalam micro-batch), secara otomatis melacak insert, update, dan delete di sumber serta menerapkannya ke target. Ini ideal untuk skenario yang memerlukan sinkronisasi data hampir real-time.
Pertanyaan lanjutan menggali lebih dalam fungsionalitas ADF, berfokus pada optimisasi kinerja, kasus penggunaan nyata, dan keputusan arsitektural tingkat lanjut.
Pertanyaan ini dimaksudkan untuk mengukur pengalaman Anda dalam skenario data yang kompleks dan kemampuan Anda memecahkan masalah menantang menggunakan ADF.
Deskripsi: Pertanyaan ini menilai kemampuan Anda memecahkan masalah dan meningkatkan efisiensi pipeline.
Contoh jawaban: Saya biasanya menerapkan beberapa strategi untuk mengoptimalkan kinerja pipeline Azure Data Factory.
Pertama, saya memastikan paralelisme dimanfaatkan dengan menggunakan Concurrent Pipeline Runs untuk memproses data secara paralel jika memungkinkan. Saya juga menggunakan Partitioning dalam Copy Activity untuk membagi dataset besar dan mentransfer potongan lebih kecil secara bersamaan.
Optimisasi penting lainnya adalah memilih Integration Runtime yang tepat berdasarkan sumber data dan kebutuhan transformasi. Misalnya, menggunakan Self-hosted IR untuk data on-premise dapat mempercepat transfer dari on-prem ke cloud.
Selain itu, mengaktifkan Staging dalam Copy Activity dapat meningkatkan kinerja dengan melakukan buffer pada dataset besar sebelum loading akhir.
Deskripsi: Pertanyaan ini mengevaluasi pemahaman Anda tentang manajemen kredensial yang aman di ADF.
Contoh jawaban: Azure Key Vault berperan penting dalam mengamankan informasi sensitif seperti connection string, kata sandi, dan API key di Azure Data Factory. Alih-alih menanamkan secret di pipeline atau Linked Service, saya menggunakan Key Vault untuk menyimpan dan mengelola secret tersebut.
Pipeline ADF dapat mengambil secret dari Key Vault secara aman saat runtime, memastikan kredensial tetap terlindungi dan tidak terekspos di kode. Misalnya, saat menyiapkan Linked Service untuk terhubung ke Azure SQL Database, saya menggunakan referensi secret dari Key Vault untuk autentikasi yang aman.
Deskripsi: Pertanyaan ini memeriksa familiaritas Anda dengan version control dan deployment otomatis di ADF.
Contoh jawaban: Azure Data Factory terintegrasi dengan Azure DevOps atau GitHub untuk workflow CI/CD. Saya biasanya mengonfigurasi ADF untuk terhubung ke repositori Git, sehingga memungkinkan version control untuk pipeline, dataset, dan Linked Service. Prosesnya mencakup membuat branch, melakukan perubahan di lingkungan pengembangan, lalu melakukan commit perubahan ke repositori.
Untuk deployment, ADF mendukung template ARM yang dapat diekspor dan digunakan di lingkungan berbeda, seperti staging dan produksi. Dengan pipeline, saya dapat mengotomatiskan proses deployment, memastikan perubahan diuji dan dipromosikan secara efisien di berbagai lingkungan.
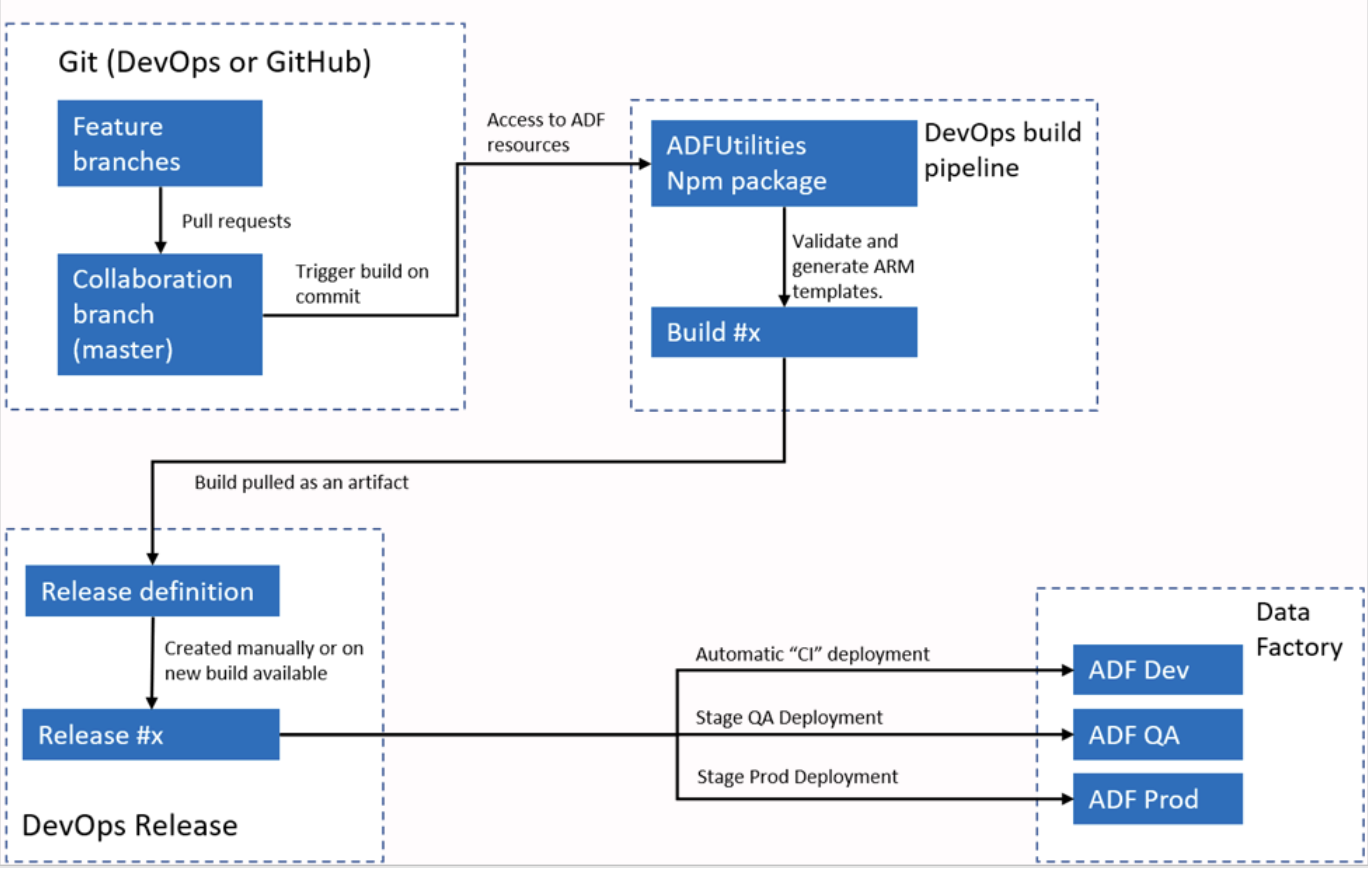
Workflow CI/CI otomatis Azure Data Factory. Sumber gambar: Microsoft.
Deskripsi: Pertanyaan ini mengevaluasi pemahaman Anda tentang kapabilitas ADF dalam menangani lingkungan data hibrida.
Contoh jawaban: Merancang pipeline data hibrida dengan Azure Data Factory memerlukan penggunaan Self-hosted Integration Runtime (IR) untuk menjembatani lingkungan on-premise dan cloud. IR diinstal pada mesin di jaringan on-premise, yang memungkinkan ADF memindahkan data secara aman antara on-premise dan sumber daya cloud seperti Azure Blob Storage atau Azure SQL Database.
Misalnya, saat saya perlu mentransfer data SQL Server on-prem ke Azure Data Lake, saya akan menyiapkan Self-hosted IR untuk mengakses SQL Server secara aman, mendefinisikan dataset untuk sumber dan tujuan, dan menggunakan Copy Activity untuk memindahkan data. Saya juga dapat menambahkan langkah transformasi atau pembersihan menggunakan Mapping Data Flows.
Deskripsi: Pertanyaan ini menguji kemampuan Anda mengonfigurasi pemetaan skema dinamis dalam data flow yang kompleks.
Contoh jawaban: Pemetaan dinamis dalam Mapping Data Flow memungkinkan fleksibilitas saat skema data sumber dapat berubah. Saya menerapkannya dengan fitur Auto Mapping di Data Flow, yang secara otomatis memetakan kolom sumber ke kolom tujuan berdasarkan nama.
Untuk skenario yang lebih kompleks, saya menggunakan Derived Column dan Expression Language di Data Flow untuk menetapkan atau memodifikasi kolom secara dinamis berdasarkan metadata-nya. Pendekatan ini membantu saat menghadapi schema drift atau ketika pipeline harus menangani beragam skema sumber tanpa pemetaan ulang manual.
Deskripsi: Pertanyaan ini memeriksa kemampuan Anda merancang pipeline yang memenuhi standar tata kelola data perusahaan.
Contoh jawaban: ADF terintegrasi secara native dengan Microsoft Purview untuk mengirim data lineage. Saat pipeline berjalan, ADF mengirim metadata ke Purview yang menjelaskan:
Ini memungkinkan data steward memvisualisasikan aliran data di seluruh organisasi. Anda menghubungkannya dengan mendaftarkan instance ADF di portal tata kelola Purview.
Pertanyaan perilaku dan berbasis skenario berfokus pada bagaimana kandidat menerapkan keterampilan teknis mereka dalam situasi nyata.
Pertanyaan ini membantu menilai kemampuan pemecahan masalah, troubleshooting, dan optimisasi dalam workflow data yang kompleks. Pertanyaan ini juga memberikan wawasan tentang proses pengambilan keputusan kandidat dan pengalamannya menangani tantangan terkait integrasi data dan proses ETL.
Deskripsi: Pertanyaan ini mengevaluasi keterampilan pemecahan masalah Anda, terutama saat menghadapi kegagalan pipeline atau masalah yang tidak terduga.
Contoh jawaban: Dalam sebuah proyek, saya menghadapi pipeline yang konsisten gagal saat mencoba mentransfer data dari SQL Server on-premise ke Azure Blob Storage.
Log error menunjukkan masalah timeout selama proses pemindahan data. Untuk men-troubleshoot, pertama saya memeriksa konfigurasi Self-hosted Integration Runtime (IR) yang bertanggung jawab atas koneksi data on-premise.
Setelah diperiksa, saya menemukan bahwa mesin yang menjalankan IR menggunakan banyak daya CPU, yang menyebabkan keterlambatan transfer data.
Untuk menyelesaikannya, saya meningkatkan daya pemrosesan mesin dan mendistribusikan beban kerja dengan mempartisi data menjadi potongan lebih kecil menggunakan pengaturan Copy Activity.
Ini memungkinkan pemrosesan data paralel, mengurangi waktu muat dan mencegah timeout. Setelah perubahan, pipeline berjalan sukses dan error hilang.
Deskripsi: Pertanyaan ini menilai kemampuan Anda mengidentifikasi dan menerapkan teknik optimisasi dalam workflow data.
Contoh jawaban: Dalam sebuah proyek untuk memproses data keuangan dalam jumlah besar dari banyak sumber, pipeline awal memakan waktu terlalu lama karena volume data. Untuk mengoptimalkannya, saya mengaktifkan paralelisme dengan mengatur beberapa Copy Activity berjalan bersamaan, masing-masing menangani partisi dataset yang berbeda.
Selanjutnya, saya menggunakan fitur staging di Copy Activity untuk melakukan buffer sementara di Azure Blob Storage sebelum pemrosesan lanjutan, yang secara signifikan meningkatkan throughput. Saya juga melakukan optimisasi Data Flow dengan caching tabel lookup yang digunakan dalam transformasi.
Penyesuaian ini meningkatkan kinerja pipeline sebesar 40%, mengurangi waktu eksekusi.
Deskripsi: Pertanyaan ini memeriksa bagaimana Anda mengelola perubahan skema tak terduga dan memastikan pipeline tetap berfungsi.
Contoh jawaban: Ya, dalam salah satu proyek saya, skema sumber data (sebuah API eksternal) berubah tiba-tiba ketika sebuah kolom baru ditambahkan ke dataset. Ini menyebabkan pipeline gagal karena skema di Mapping Data Flow tidak lagi selaras.
Untuk mengatasinya, saya mengaktifkan opsi Allow Schema Drift di Data Flow, yang memungkinkan pipeline mendeteksi dan menangani perubahan skema secara otomatis.
Selain itu, saya mengonfigurasi pemetaan kolom dinamis menggunakan Derived Column, yang memastikan kolom baru tertangkap tanpa hardcode nama kolom tertentu. Ini memastikan pipeline dapat beradaptasi dengan perubahan skema di masa depan tanpa intervensi manual.
Deskripsi: Pertanyaan ini menilai kemampuan Anda menangani integrasi data multi-sumber, kebutuhan umum dalam proses ETL yang kompleks.
Contoh jawaban: Dalam proyek terbaru, saya perlu mengintegrasikan data dari tiga sumber: SQL Server on-premise, Azure Data Lake, dan REST API. Saya menggunakan kombinasi Self-hosted Integration Runtime untuk koneksi SQL Server on-premise dan Azure Integration Runtime untuk layanan berbasis cloud.
Saya membuat pipeline yang menggunakan Copy Activity untuk menarik data dari SQL Server dan REST API, mentransformasinya dengan Mapping Data Flows, dan menggabungkannya dengan data yang tersimpan di Azure Data Lake.
Dengan memparametrisasi pipeline, saya memastikan fleksibilitas dalam menangani dataset dan jadwal yang berbeda. Ini memungkinkan integrasi data dari banyak sumber, yang krusial untuk platform analitik data klien.
Deskripsi: Pertanyaan ini menelaah bagaimana Anda mengidentifikasi dan menangani masalah kualitas data dalam workflow pipeline.
Contoh jawaban: Dalam satu kasus, saya mengerjakan pipeline yang mengekstraksi data pelanggan dari sistem CRM. Namun, data tersebut mengandung nilai hilang dan duplikasi, yang memengaruhi pelaporan akhir. Untuk mengatasi masalah kualitas data ini, saya memasukkan Data Flow dalam pipeline yang melakukan operasi pembersihan data.
Saya menggunakan filter untuk menghapus duplikasi dan conditional split untuk menangani nilai yang hilang. Saya menyiapkan lookup untuk data yang hilang atau tidak benar guna menarik nilai default dari dataset referensi. Pada akhir proses, kualitas data meningkat signifikan, memastikan analitik hilir akurat dan andal.
Deskripsi: Pertanyaan ini menguji pengalaman Anda dengan transformasi data tingkat lanjut menggunakan ADF.
Contoh jawaban: Dalam proyek pelaporan keuangan, saya harus menggabungkan data transaksi dari banyak sumber, menerapkan agregasi, dan menghasilkan laporan ringkasan untuk berbagai wilayah. Tantangannya adalah setiap sumber data memiliki struktur dan penamaan yang sedikit berbeda. Saya menerapkan transformasi menggunakan Mapping Data Flows.
Pertama, saya menstandarkan nama kolom di seluruh dataset menggunakan Derived Column. Selanjutnya, saya menerapkan agregasi untuk menghitung metrik spesifik wilayah, seperti total penjualan dan nilai transaksi rata-rata. Terakhir, saya menggunakan transformasi pivot untuk membentuk ulang data agar mudah dilaporkan. Seluruh transformasi dilakukan di dalam ADF, memanfaatkan transformasi bawaan dan infrastruktur yang skalabel.
Deskripsi: Pertanyaan ini mengevaluasi pemahaman Anda tentang praktik keamanan data di ADF.
Contoh jawaban: Dalam satu proyek, kami menangani data pelanggan sensitif yang harus ditransfer secara aman dari SQL Server on-premise ke Azure SQL Database. Saya menggunakan Azure Key Vault untuk menyimpan kredensial database dan mengamankan data, memastikan informasi sensitif seperti kata sandi tidak di-hardcode dalam pipeline atau Linked Service.
Selain itu, saya menerapkan Enkripsi Data selama pemindahan data dengan mengaktifkan koneksi SSL antara SQL Server on-premise dan Azure.
Saya juga menggunakan role-based access control (RBAC) untuk membatasi akses ke pipeline ADF, memastikan hanya pengguna berwenang yang dapat memicu atau memodifikasinya. Pengaturan ini memastikan transfer data yang aman dan manajemen akses yang tepat.
Deskripsi: Pertanyaan ini menilai kemampuan Anda menerapkan eksekusi pipeline berbasis peristiwa.
Contoh jawaban: Dalam satu skenario, pipeline perlu berjalan setiap kali file baru yang berisi data penjualan diunggah ke Azure Blob Storage. Untuk menerapkannya, saya menggunakan Event-Based Trigger di Azure Data Factory. Trigger ini disetel untuk mendengarkan peristiwa Blob Created di kontainer tertentu, dan segera setelah file baru diunggah, pipeline otomatis dipicu.
Pendekatan berbasis peristiwa ini memastikan pipeline hanya berjalan saat data baru tersedia, menghilangkan kebutuhan eksekusi manual atau penjadwalan. Pipeline kemudian memproses file, mentransformasikannya, dan memuatnya ke data warehouse untuk analisis lebih lanjut.
Deskripsi: Pertanyaan ini mengevaluasi pengalaman Anda memigrasikan proses ETL tradisional ke cloud menggunakan ADF.
Contoh jawaban: Dalam proyek memigrasikan proses ETL berbasis SSIS dari on-premise ke cloud, saya menggunakan Azure Data Factory dengan Azure-SSIS Integration Runtime.
Pertama, saya menilai paket SSIS yang ada untuk memastikan kompatibel dengan ADF dan melakukan modifikasi yang diperlukan untuk menangani sumber data berbasis cloud.
Saya menyiapkan Azure-SSIS IR untuk menjalankan paket SSIS di cloud sambil mempertahankan workflow yang ada. Untuk lingkungan cloud baru, saya juga mengganti beberapa aktivitas ETL tradisional dengan komponen native ADF seperti Copy Activity dan Mapping Data Flows, yang meningkatkan kinerja dan skalabilitas keseluruhan workflow data.
Deskripsi: Pertanyaan ini menguji kematangan operasional dan pemahaman Anda tentang model penagihan ADF.
Contoh jawaban: Pertama saya akan menganalisis laporan Pipeline Run Consumption di Azure Monitor untuk mengidentifikasi pendorong biaya (misalnya jam komputasi Data Flow yang tinggi atau panggilan API berlebihan). Strategi optimisasi umum meliputi:
Mempersiapkan wawancara Azure Data Factory memerlukan pemahaman mendalam tentang aspek teknis dan praktis platform. Penting untuk menunjukkan pengetahuan Anda tentang fitur inti ADF dan kemampuan menerapkannya dalam skenario dunia nyata.
Berikut kiat terbaik saya untuk membantu Anda siap menghadapi wawancara:
Azure Data Factory adalah alat yang kuat untuk membangun solusi ETL berbasis cloud, dan keahlian di dalamnya sangat diminati di dunia rekayasa data!
Dalam artikel ini, kami membahas pertanyaan wawancara esensial mulai dari konsep umum hingga teknis dan berbasis skenario, menekankan pentingnya pengetahuan tentang fitur dan alat ADF. Contoh nyata pengelolaan pipeline, transformasi data, dan troubleshooting menggambarkan keterampilan kritis yang dibutuhkan dalam lingkungan ETL berbasis cloud.
Untuk memperdalam pemahaman Anda tentang Microsoft Azure, pertimbangkan untuk mengeksplorasi kursus dasar tentang arsitektur, manajemen, dan tata kelola Azure, seperti Understanding Microsoft Azure, Understanding Microsoft Azure Architecture and Services, dan Understanding Microsoft Azure Management and Governance. Sumber daya ini menawarkan wawasan berharga tentang ekosistem Azure yang lebih luas, melengkapi pengetahuan Anda tentang Azure Data Factory dan mempersiapkan Anda untuk karier sukses di bidang rekayasa data.
Pelajari lebih lanjut tentang Azure dengan kursus-kursus ini!
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
