
Programa
Fundamentos do Microsoft Azure (AZ-900)
9 h
O Azure Data Factory (ADF) é um serviço de integração de dados baseado em nuvem oferecido pelo Microsoft Azure.
À medida que a tomada de decisões baseada em dados se torna um aspecto central das operações comerciais, a procura por ferramentas de engenharia de dados baseadas na nuvem está em alta! Como o ADF é um serviço líder, as empresas estão cada vez mais procurando profissionais de dados com experiência prática para gerenciar seus pipelines de dados e integrar seus sistemas.
Neste artigo, a gente quer ajudar quem quer ser profissional de ADF com perguntas e respostas essenciais para entrevistas sobre o Azure Data Factory — incluindo perguntas gerais, técnicas, avançadas e baseadas em cenários — e ainda dar dicas para arrasar na entrevista.
O Azure Data Factory é um serviço ETL baseado em nuvem que permite criar fluxos de trabalho orientados por dados para orquestrar e automatizar a movimentação e a transformação de dados. O serviço se conecta com várias fontes e destinos de dados no local e na nuvem.
À medida que as equipes migram para infraestruturas nativas da nuvem, cresce a necessidade de gerenciar dados em diversos ambientes. A integração do ADF com o ecossistema do Azure e fontes de dados de terceiros facilita isso, tornando o conhecimento do serviço uma habilidade muito procurada pelas organizações.
Arquitetura de BI automatizada usando o Azure Data Factory. Fonte da imagem: Microsoft
Nesta seção, vamos focar em perguntas básicas que costumam aparecer em entrevistas para avaliar o seu conhecimento geral sobre ADF. Essas perguntas testam sua compreensão dos conceitos básicos, arquitetura e componentes.
Descrição: Essa pergunta é sempre feita pra ver se você entende os fundamentos do ADF.
Exemplo de resposta: Os principais componentes do Azure Data Factory são:
Descrição: Essa pergunta testa o seu entendimento sobre como o Azure Data Factory facilita a movimentação híbrida de dados de forma segura e eficiente.
Exemplo de resposta: O Azure Data Factory permite a transferência segura de dados entre ambientes na nuvem e locais por meio do Self-hosted Integration Runtime (IR), que funciona como uma ponte entre o ADF e as fontes de dados locais.
Por exemplo, quando você está transferindo dados de um SQL Server local para o Azure Blob Storage, o IR auto-hospedado se conecta com segurança ao sistema local. Isso permite que o ADF transfira dados garantindo a segurança por meio de criptografia em trânsito e em repouso. Isso é super útil pra cenários de nuvem híbrida, onde os dados ficam espalhados entre infraestruturas locais e na nuvem.
Descrição: Essa pergunta avalia o quanto você entende como o ADF automatiza e programa pipelines usando diferentes tipos de gatilhos.
Exemplo de resposta: No Azure Data Factory, os gatilhos são usados para iniciar automaticamente as execuções do pipeline com base em condições ou programações específicas. Existem três tipos principais de gatilhos:
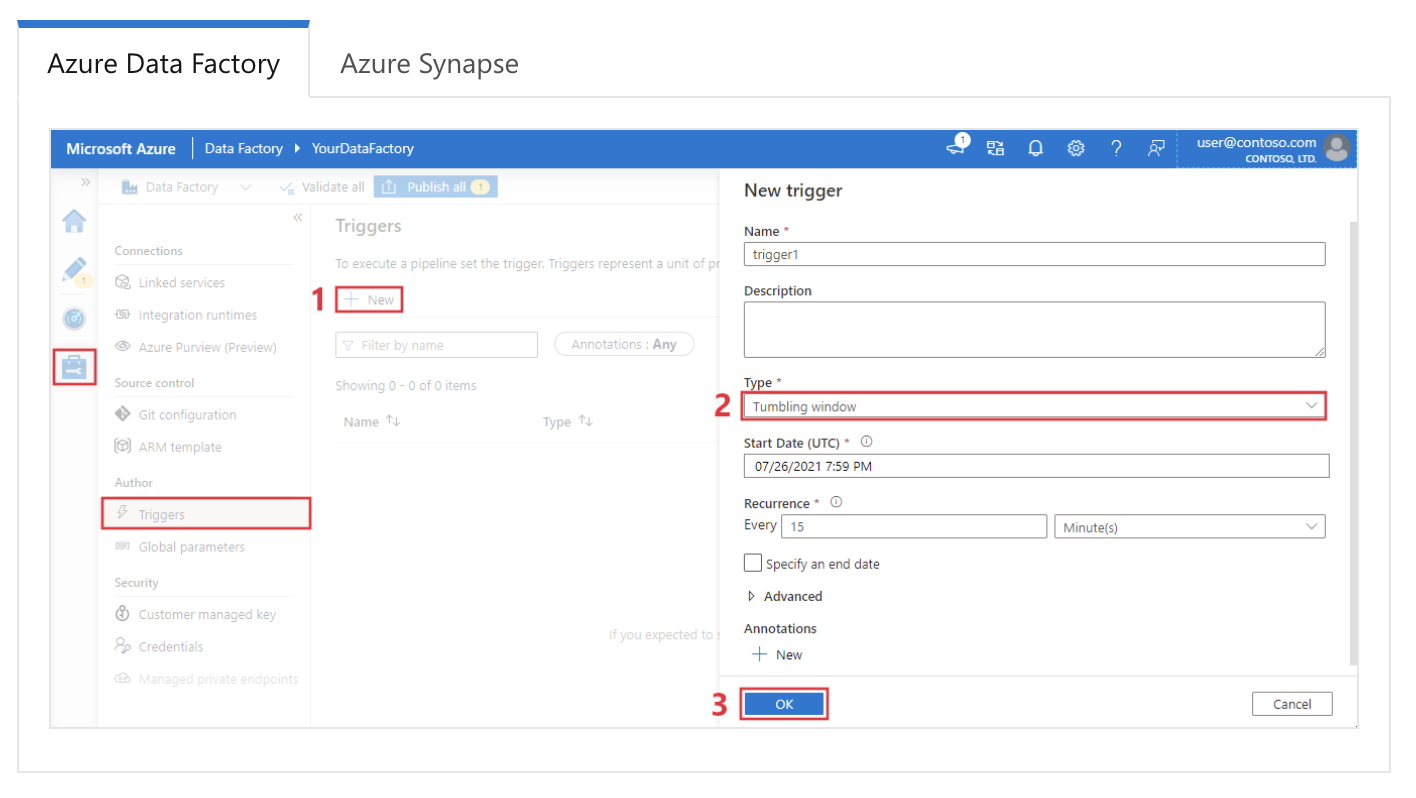
Configurando um gatilho de janela móvel no Azure Data Factory. Fonte da imagem: Microsoft.
Descrição: Essa pergunta avalia o seu conhecimento sobre as várias tarefas que os pipelines ADF podem fazer.
Exemplo de resposta: Os pipelines do Azure Data Factory suportam vários tipos de atividades. Esses são os mais comuns:
|
Tipo de atividade |
Descrição |
|
Movimentação de dados |
Move dados entre armazenamentos de dados compatíveis (por exemplo, Azure Blob Storage, SQL Database) com a atividade Copiar. |
|
Transformação de dados |
Inclui atividade de fluxo de dados para lógica de transformação de dados usando Spark, mapeamento de fluxos de dados para operações ETL e manipulação de fluxos de dados para preparação de dados. |
|
Controle de fluxo |
Dá controle sobre a execução do pipeline usando atividades como ForEach, If Condition, Switch, Wait e Until para criar lógica condicional. |
|
Execução externa |
Executa aplicativos ou funções externos, incluindo Funções do Azure, Atividades da Web (chamando APIs REST) e Atividades de Procedimento Armazenado para SQL. |
|
Atividades personalizadas |
Permite a execução de código personalizado na Atividade Personalizada usando os serviços .NET ou Azure Batch, oferecendo flexibilidade para necessidades avançadas de processamento de dados. |
|
Outros serviços |
Suporta atividades do HDInsight, Databricks e Data Lake Analytics, que se juntam a outros serviços de análise do Azure para tarefas complexas com dados. |
Descrição: Essa pergunta verifica sua familiaridade com as ferramentas de monitoramento e depuração do ADF.
Exemplo de resposta: O Azure Data Factory oferece uma interface robusta de monitoramento e depuração na guia Monitorar do portal do Azure. Posso acompanhar o andamento dos pipelines, ver o status das atividades e diagnosticar falhas aqui. Cada atividade gera registros, que podem ser analisados para identificar erros e resolver problemas.
Além disso, o Azure Monitor pode ser configurado para enviar alertas com base em falhas no pipeline ou problemas de desempenho. Pra depurar, geralmente começo olhando os registros das atividades que deram errado, vejo os detalhes do erro e, depois de resolver o problema, executo o pipeline de novo.
Descrição: Essa pergunta testa se você está por dentro das últimas novidades da plataforma de dados da Microsoft.
Exemplo de resposta: Embora ambos tenham o mesmo mecanismo, o Data Factory no Fabric é um SaaS (Software as a Service) integrado ao ecossistema Fabric, enquanto o Azure Data Factory (ADF) é um recurso PaaS (Platform as a Service). As principais diferenças são:
Descrição: Essa pergunta avalia o seu conhecimento sobre os mecanismos de segurança do ADF para proteger os dados durante todo o seu ciclo de vida.
Exemplo de resposta: O Azure Data Factory garante a segurança dos dados por meio de vários mecanismos.
Primeiro, ele usa criptografia para dados em trânsito e em repouso, empregando protocolos como TLS e AES para proteger as transferências de dados. O ADF se integra ao Azure Active Directory (AAD) para autenticação e usa o Controle de Acesso Baseado em Função (RBAC) para restringir quem pode acessar e gerenciar a fábrica.
Além disso, as identidades gerenciadas permitem que o ADF acesse com segurança outros serviços do Azure sem expor credenciais. Para segurança de rede, o ADF oferece suporte a pontos de extremidade privados, garantindo que o tráfego de dados permaneça dentro da rede do Azure e adicionando outra camada de proteção.
Descrição: Essa pergunta avalia o quanto você entende os diferentes papéis que os Serviços vinculados e os Conjuntos de dados têm no ADF.
Exemplo de resposta: No Azure Data Factory, um serviço vinculado define a conexão com uma fonte de dados externa ou serviço de computação, tipo uma string de conexão. Inclui as informações de autenticação necessárias para se conectar ao recurso.
Um conjunto de dados, por outro lado, representa os dados específicos com os quais você vai trabalhar, como uma tabela em um banco de dados ou um arquivo no Blob Storage.
Enquanto o Serviço Vinculado define onde os dados estão, o Conjunto de Dados descreve como eles são e como estão estruturados. Esses dois componentes trabalham juntos para facilitar a movimentação e a transformação de dados.
As perguntas da entrevista técnica geralmente focam no seu entendimento de recursos específicos, suas implementações e como eles funcionam juntos para criar pipelines de dados eficazes. Essas perguntas avaliam sua experiência prática e conhecimento dos principais componentes e recursos do ADF.
Descrição: Essa pergunta testa sua habilidade de implementar estratégias de tratamento de erros em pipelines ADF.
Exemplo de resposta: O tratamento de erros no Azure Data Factory pode ser implementado usando políticas de repetição e atividades de tratamento de erros. O ADF oferece mecanismos de repetição integrados, nos quais você pode configurar o número de repetições e o intervalo entre elas caso uma atividade falhe.
Por exemplo, se uma atividade de cópia falhar por causa de um problema temporário na rede, você pode configurar a atividade para tentar de novo 3 vezes, com um intervalo de 10 minutos entre cada tentativa.
Além disso, condições de dependência de atividade definidas, como falha, conclusão e ignorado, podem desencadear ações específicas dependendo do sucesso ou fracasso de uma atividade.
Por exemplo, eu poderia definir um fluxo de pipeline de tal forma que, em caso de falha de uma atividade, uma atividade personalizada de tratamento de erros, como o envio de um alerta ou a execução de um processo alternativo, fosse executada.
Descrição: Essa pergunta avalia o quanto você entende da infraestrutura de computação por trás da movimentação de dados e do envio de atividades no ADF.
Exemplo de resposta: O Integration Runtime (IR) é a infraestrutura de computação que o Azure Data Factory usa para fazer movimentação de dados, transformação e envio de atividades. É essencial para gerenciar como e onde os dados são processados e pode ser otimizado com base na fonte, no destino e nos requisitos de transformação. Para mais contexto, existem três tipos de IR:
|
Tipo de tempo de execução de integração (IR) |
Descrição |
|
Tempo de execução da integração do Azure |
Usado para atividades de movimentação e transformação de dados nos centros de dados do Azure. Ele suporta atividades de cópia, transformações de fluxo de dados e envia atividades para recursos do Azure. |
|
Tempo de execução de integração auto-hospedado |
Instalado em máquinas locais ou virtuais em uma rede privada para permitir a integração de dados entre recursos locais, privados e do Azure. Ótimo pra copiar dados do local pro Azure. |
|
Tempo de execução da integração do Azure-SSIS |
Permite que você transfira seus pacotes existentes do SQL Server Integration Services (SSIS) para o Azure, com suporte à execução nativa de pacotes SSIS no Azure Data Factory. Ideal para quem quer migrar cargas de trabalho SSIS sem precisar refazer tudo. |
Descrição: Essa pergunta testa o seu entendimento de como a parametrização funciona no ADF para criar pipelines reutilizáveis e flexíveis.
Exemplo de resposta: A parametrização no Azure Data Factory permite a execução dinâmica do pipeline, onde você pode passar valores diferentes durante cada execução.
Por exemplo, em uma atividade de cópia, eu poderia usar parâmetros para especificar dinamicamente o caminho do arquivo de origem e a pasta de destino. Eu definiria os parâmetros no nível do pipeline e os passaria para o conjunto de dados ou atividade relevante.
Aqui vai um exemplo simples:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}A parametrização torna os pipelines reutilizáveis e facilita o dimensionamento, ajustando as entradas dinamicamente durante o tempo de execução.
Descrição: Essa pergunta avalia o seu conhecimento sobre transformação de dados no ADF sem precisar de serviços de computação externos.
Exemplo de resposta: Um fluxo de dados de mapeamento no Azure Data Factory permite que você faça transformações nos dados sem precisar escrever código ou mover os dados para fora do ecossistema ADF. Ele oferece uma interface visual onde você pode criar transformações complexas.
Os fluxos de dados são executados em clusters Spark dentro do ambiente gerenciado do ADF, o que permite transformações de dados escaláveis e eficientes.
Por exemplo, em um cenário típico de transformação, eu poderia usar um fluxo de dados para juntar dois conjuntos de dados, juntar os resultados e gravar a saída em um novo destino — tudo isso visualmente e sem precisar de serviços externos como o Databricks.
Descrição: Essa pergunta testa sua habilidade de lidar com mudanças dinâmicas de esquema durante a transformação de dados.
Exemplo de resposta: Desvio de esquema é quando a estrutura dos dados de origem muda com o tempo.
O Azure Data Factory resolve o problema de desvio de esquema oferecendo a opção Permitir desvio de esquema em Fluxos de dados de mapeamento. Isso permite que o ADF se ajuste automaticamente às mudanças no esquema dos dados recebidos, como novas colunas sendo adicionadas ou removidas, sem precisar redefinir todo o esquema.
Ao ativar o desvio de esquema, posso configurar um pipeline para mapear colunas dinamicamente, mesmo que o esquema de origem mude.
Permita a opção de desvio de esquema no Azure Data Factory. Fonte da imagem: Microsoft
Descrição: Essa pergunta avalia o quanto você conhece os métodos modernos de ingestão contínua de dados em comparação com o processamento em lote.
Exemplo de resposta: O recurso CDC no ADF oferece uma maneira simples de replicar continuamente os dados alterados das fontes (como um banco de dados SQL ou Cosmos) para um destino sem uma lógica complexa de marca d'água.
Diferente de um gatilho de pipeline padrão que funciona de acordo com uma programação, o recurso CDC funciona o tempo todo (ou em micro-lotes), programando automaticamente inserções, atualizações e exclusões na fonte e aplicando-as ao destino. É ideal para situações que precisam de sincronização de dados quase em tempo real.
As perguntas avançadas da entrevista exploram funcionalidades mais profundas do ADF, com foco em otimização de desempenho, casos de uso reais e decisões arquitetônicas avançadas.
Essas perguntas têm como objetivo avaliar sua experiência com cenários de dados complexos e sua capacidade de resolver problemas desafiadores usando o ADF.
Descrição: Essa pergunta avalia sua capacidade de resolver problemas e melhorar a eficiência do pipeline.
Exemplo de resposta: Normalmente, sigo várias estratégias para otimizar o desempenho de um pipeline do Azure Data Factory.
Primeiro, eu garanto que o paralelismo seja aproveitado usando execuções simultâneas de pipeline para processar dados em paralelo sempre que possível. Eu também uso o particionamento na atividade de cópia para dividir grandes conjuntos de dados e transferir partes menores ao mesmo tempo.
Outra otimização importante é escolher o Integration Runtime certo com base na fonte de dados e nos requisitos de transformação. Por exemplo, usar um IR auto-hospedado para dados locais pode acelerar as transferências locais para a nuvem.
Além disso, ativar o Staging na atividade de cópia pode melhorar o desempenho, armazenando em buffer grandes conjuntos de dados antes do carregamento final.
Descrição: Essa pergunta avalia o quanto você entende sobre gerenciamento seguro de credenciais no ADF.
Exemplo de resposta: O Azure Key Vault é super importante pra proteger informações confidenciais, tipo strings de conexão, senhas e chaves de API dentro do Azure Data Factory. Em vez de codificar segredos em pipelines ou Serviços vinculados, eu uso o Key Vault para guardar e gerenciar esses segredos.
O pipeline ADF pode pegar segredos do Key Vault com segurança durante o tempo de execução, garantindo que as credenciais continuem protegidas e não sejam expostas no código. Por exemplo, ao configurar um serviço vinculado para se conectar a um banco de dados SQL do Azure, eu usaria uma referência secreta do Key Vault para autenticar com segurança.
Descrição: Essa pergunta testa o quanto você conhece controle de versão e implantação automática no ADF.
Exemplo de resposta: O Azure Data Factory se integra ao Azure DevOps ou ao GitHub para fluxos de trabalho de CI/CD. Normalmente, eu configuro o ADF para se conectar a um repositório Git, ativando o controle de versão para pipelines, conjuntos de dados e serviços vinculados. O processo envolve criar ramificações, fazer alterações em um ambiente de desenvolvimento e, em seguida, enviar essas alterações para o repositório.
Para implantação, o ADF oferece suporte a modelos ARM que podem ser exportados e usados em diferentes ambientes, como staging e produção. Usando pipelines, posso automatizar o processo de implantação, garantindo que as alterações sejam testadas e promovidas de forma eficiente em diferentes ambientes.
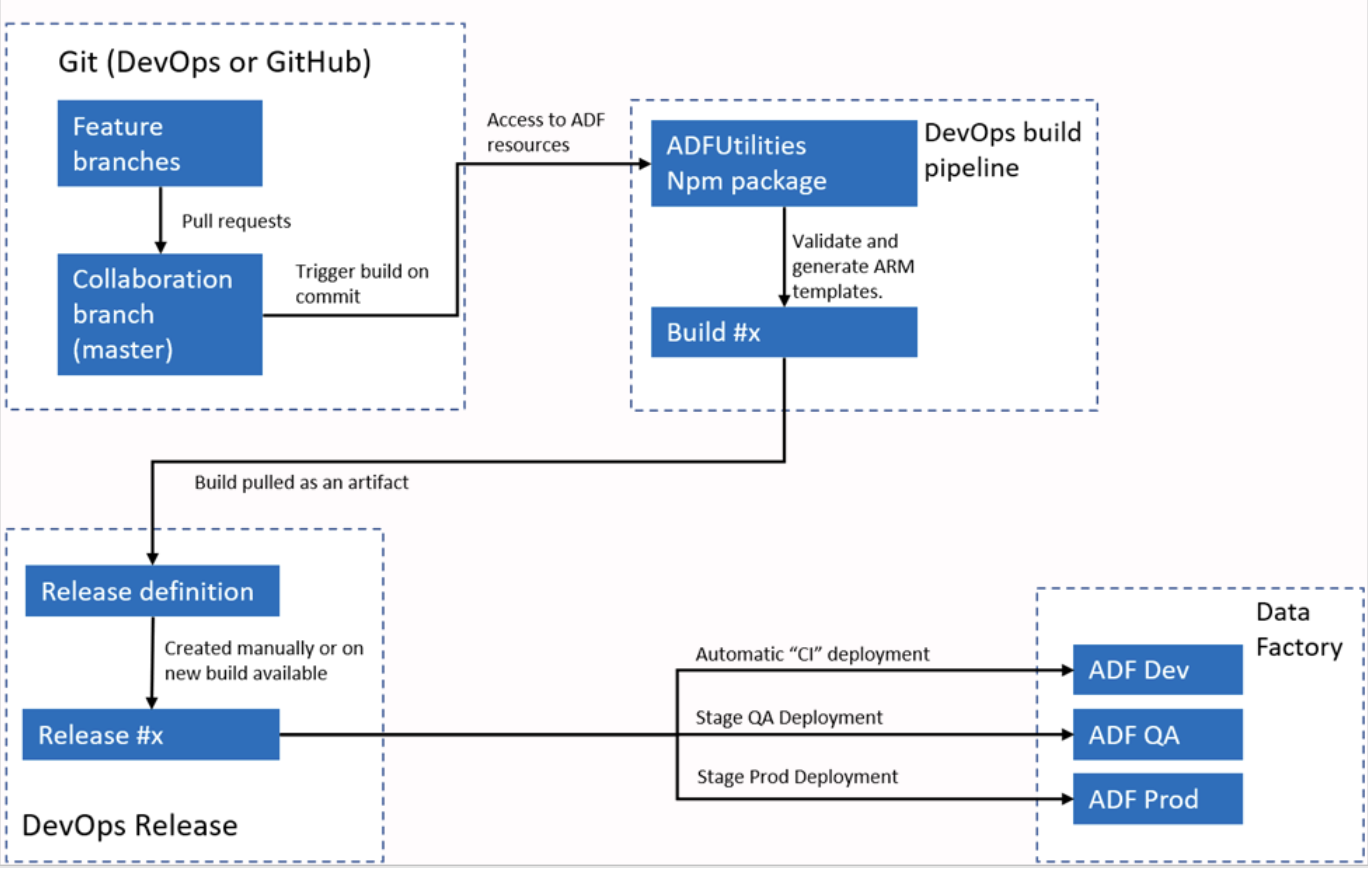
Fluxo de trabalho automatizado de CI/CI do Azure Data Factory. Fonte da imageme: Microsoft.
Descrição: Essa pergunta avalia o quanto você entende das capacidades do ADF em lidar com ambientes de dados híbridos.
Exemplo de resposta: Para criar um pipeline de dados híbrido com o Azure Data Factory, você precisa usar o Self-hosted Integration Runtime (IR) para conectar os ambientes locais e na nuvem. O IR é instalado em uma máquina dentro da rede local, o que permite que o ADF mova dados com segurança entre recursos locais e na nuvem, como o Azure Blob Storage ou o Azure SQL Database.
Por exemplo, quando eu preciso passar dados do SQL Server local para um Azure Data Lake, eu configuro o IR auto-hospedado para acessar o SQL Server com segurança, defino conjuntos de dados para a origem e o destino e uso uma atividade de cópia para mover os dados. Eu também poderia adicionar transformações ou etapas de limpeza usando o Mapeamento de Fluxos de Dados.
Descrição: Essa pergunta testa sua habilidade de configurar mapeamentos de esquema dinâmicos em fluxos de dados complexos.
Exemplo de resposta: O mapeamento dinâmico em um fluxo de dados de mapeamento dá flexibilidade quando o esquema dos dados de origem pode mudar. Eu implemento o mapeamento dinâmico usando o recurso Auto Mapping no Data Flow, que mapeia automaticamente as colunas de origem para as colunas de destino por nome.
Eu uso colunas derivadas e linguagem de expressão em fluxos de dados para atribuir ou modificar colunas de forma dinâmica com base em seus metadados para cenários mais complexos. Essa abordagem ajuda quando a gente lida com desvios de esquema ou quando o pipeline de dados precisa lidar com vários esquemas de origem diferentes sem remapeamento manual.
Descrição: Essa pergunta testa sua habilidade de projetar pipelines que sigam as normas de governança de dados da empresa.
Exemplo de resposta: O ADF se integra nativamente ao Microsoft Purview para enviar dados de linhagem. Quando um pipeline é executado, o ADF manda metadados para o Purview descrevendo:
Isso permite que os administradores de dados visualizem o fluxo de dados em toda a organização. Você conecta-os registrando a instância ADF no portal de governança Purview.
As perguntas comportamentais e baseadas em cenários focam em como os candidatos aplicam suas habilidades técnicas em situações reais.
Essas perguntas ajudam a avaliar as capacidades de resolução de problemas, solução de falhas e otimização em fluxos de trabalho de dados complexos. Eles também dão uma ideia sobre como o candidato toma decisões e como ele lida com desafios relacionados à integração de dados e processos ETL.
Descrição: Essa pergunta avalia suas habilidades de resolução de problemas, especialmente quando se trata de falhas no pipeline ou questões inesperadas.
Exemplo de resposta: Em um projeto, eu tinha um pipeline que falhava constantemente ao tentar transferir dados de um SQL Server local para o Azure Blob Storage.
Os registros de erros mostraram um problema de tempo limite durante o processo de movimentação de dados. Para resolver o problema, primeiro verifiquei a configuração do Self-hosted Integration Runtime (IR), que era responsável pela conexão de dados local.
Quando dei uma olhada, vi que a máquina que estava hospedando o IR estava usando muita energia da CPU, o que estava causando atrasos na transferência de dados.
Pra resolver o problema, aumentei a capacidade de processamento da máquina e dividi a carga de trabalho em partes menores usando as configurações da atividade de cópia.
Isso permitiu o processamento paralelo de dados, reduzindo os tempos de carregamento e evitando tempos limite. Depois das mudanças, o pipeline funcionou direitinho, sem erros.
Descrição: Essa pergunta avalia sua capacidade de identificar e implementar técnicas de otimização em fluxos de trabalho de dados.
Exemplo de resposta: Num projeto em que a gente precisava processar um monte de dados financeiros de várias fontes, o pipeline inicial demorava muito pra ser executado por causa do volume de dados. Para otimizar isso, inicialmente habilitei o paralelismo configurando várias atividades de cópia para serem executadas simultaneamente, cada uma lidando com uma partição diferente do conjunto de dados.
Depois, usei o recurso de preparação na atividade Copiar para armazenar temporariamente os dados no Azure Blob Storage antes de continuar o processamento, o que melhorou bastante a taxa de transferência. Também usei otimizações de fluxo de dados, armazenando em cache tabelas de pesquisa usadas nas transformações.
Esses ajustes melhoraram o desempenho do pipeline em 40%, reduzindo o tempo de execução.
Descrição: Essa pergunta verifica como você lida com mudanças inesperadas no esquema e garante que os pipelines continuem funcionando.
Exemplo de resposta: Sim, em um dos meus projetos, o esquema de uma fonte de dados (uma API externa) mudou de repente quando uma nova coluna foi adicionada ao conjunto de dados. Isso fez com que o pipeline falhasse, já que o esquema no fluxo de dados de mapeamento não estava mais alinhado.
Para resolver isso, habilitei a opção Permitir desvio de esquema no fluxo de dados, o que permitiu que o pipeline detectasse e lidasse com as alterações no esquema automaticamente.
Além disso, configurei o mapeamento dinâmico de colunas usando Colunas Derivadas, o que garantiu que a nova coluna fosse capturada sem a necessidade de codificar nomes de colunas específicos. Isso garantiu que o pipeline pudesse se adaptar a futuras alterações no esquema sem intervenção manual.
Descrição: Essa pergunta avalia sua habilidade de lidar com a integração de dados de várias fontes, um requisito comum em processos ETL complexos.
Exemplo de resposta: Num projeto recente, precisei juntar dados de três fontes: um SQL Server local, o Azure Data Lake e uma API REST. Usei uma combinação de um Self-hosted Integration Runtime para a conexão SQL Server local e um Azure Integration Runtime para os serviços baseados na nuvem.
Criei um pipeline que usava a atividade Copiar para extrair dados do SQL Server e da API REST, transformá-los usando Fluxos de dados de mapeamento e combiná-los com os dados armazenados no Azure Data Lake.
Ao parametrizar os pipelines, eu garanti flexibilidade no manuseio de diferentes conjuntos de dados e cronogramas. Isso permitiu a integração de dados de várias fontes, o que era essencial para a plataforma de análise de dados do cliente.
Descrição: Essa pergunta analisa como você identifica e lida com problemas de qualidade de dados nos fluxos de trabalho do seu pipeline.
Exemplo de resposta: Em um caso, eu estava trabalhando em um pipeline que extraía dados de clientes de um sistema de CRM. Mas, os dados tinham valores faltando e duplicados, o que afetou o relatório final. Para resolver esses problemas de qualidade dos dados, eu coloquei um fluxo de dados no pipeline que fazia operações de limpeza de dados.
Usei filtros para tirar as duplicatas e uma divisão condicional para lidar com os valores que estavam faltando. Eu configurei uma pesquisa para quaisquer dados ausentes ou incorretos para extrair valores padrão de um conjunto de dados de referência. No final desse processo, a qualidade dos dados melhorou bastante, garantindo que as análises posteriores fossem precisas e confiáveis.
Descrição: Essa pergunta testa sua experiência com transformações avançadas de dados usando ADF.
Exemplo de resposta: Num projeto de relatórios financeiros, tive que juntar dados de transações de várias fontes, fazer agregações e criar relatórios resumidos para diferentes regiões. O desafio era que cada fonte de dados tinha uma estrutura e uma convenção de nomenclatura ligeiramente diferentes. Eu fiz a transformação usando o Mapping Data Flows.
Primeiro, padronizei os nomes das colunas em todos os conjuntos de dados usando Colunas Derivadas. Depois, usei agregações para calcular métricas específicas da região, como vendas totais e valor médio das transações. Por fim, usei uma transformação pivot para reorganizar os dados e facilitar a geração de relatórios. Toda a transformação foi feita dentro do ADF, aproveitando suas transformações integradas e infraestrutura escalável.
Descrição: Essa pergunta avalia o quanto você entende sobre práticas de segurança de dados no ADF.
Exemplo de resposta: Em um projeto, a gente estava lidando com dados confidenciais de clientes que precisavam ser transferidos com segurança de um SQL Server local para o Banco de Dados SQL do Azure. Usei o Azure Key Vault para guardar as credenciais do banco de dados e proteger os dados, garantindo que informações confidenciais, como senhas, não fossem codificadas no pipeline ou nos Serviços Vinculados.
Além disso, implementei a criptografia de dados durante a movimentação de dados, ativando conexões SSL entre o SQL Server local e o Azure.
Também usei o controle de acesso baseado em função (RBAC) para restringir o acesso ao pipeline ADF, garantindo que só usuários autorizados pudessem acioná-lo ou modificá-lo. Essa configuração garantiu tanto a transferência segura de dados quanto o gerenciamento adequado do acesso.
Descrição: Essa pergunta avalia sua capacidade de implementar execuções de pipeline orientadas por eventos.
Exemplo de resposta: Em um cenário, o pipeline precisava ser executado sempre que um novo arquivo com dados de vendas fosse carregado no Azure Blob Storage. Para fazer isso, usei um gatilho baseado em evento no Azure Data Factory. O gatilho foi configurado para ficar de olho nos eventos Blob Created em um contêiner específico e, assim que um novo arquivo era enviado, ele automaticamente acionava o pipeline.
Essa abordagem orientada por eventos garantiu que o pipeline só fosse executado quando novos dados estivessem disponíveis, eliminando a necessidade de execução manual ou execuções programadas. O pipeline então processou o arquivo, transformou-o e carregou-o no warehouse para análise posterior.
Descrição: Essa pergunta avalia sua experiência na migração de processos ETL tradicionais para a nuvem usando o ADF.
Exemplo de resposta: Num projeto pra migrar um processo ETL baseado em SSIS de local pra nuvem, usei o Azure Data Factory com o Azure-SSIS Integration Runtime.
Primeiro, dei uma olhada nos pacotes SSIS que já existiam pra ter certeza de que eram compatíveis com o ADF e fiz as mudanças necessárias pra lidar com fontes de dados na nuvem.
Configurei o Azure-SSIS IR para rodar os pacotes SSIS na nuvem, mantendo os fluxos de trabalho que já existiam. Para o novo ambiente em nuvem, também troquei algumas das atividades tradicionais de ETL por componentes nativos do ADF, como atividades de cópia e mapeamento de fluxos de dados, o que melhorou o desempenho geral e a escalabilidade dos fluxos de trabalho de dados.
Descrição: Essa pergunta testa sua maturidade operacional e compreensão do modelo de faturamento do ADF.
Exemplo de resposta: Primeiro, eu analisaria o relatório Pipeline Run Consumption no Azure Monitor para identificar os fatores que aumentam os custos (por exemplo, muitas horas de computação do Data Flow ou chamadas excessivas à API). Algumas estratégias comuns de otimização são:
A preparação para uma entrevista sobre o Azure Data Factory exige um conhecimento profundo dos aspectos técnicos e práticos da plataforma. É essencial mostrar que você conhece os principais recursos do ADF e sabe como usá-los em situações reais.
Aqui estão minhas melhores dicas para te ajudar a se preparar para a entrevista:
O Azure Data Factory é uma ferramenta poderosa para criar soluções ETL baseadas na nuvem, e saber como usá-lo é super valorizado no mundo da engenharia de dados!
Neste artigo, a gente explorou perguntas essenciais para entrevistas, desde conceitos gerais até questões técnicas e baseadas em cenários, com ênfase na importância do conhecimento dos recursos e ferramentas do ADF. Os exemplos reais de gerenciamento de pipeline, transformação de dados e solução de problemas mostram as habilidades essenciais necessárias em um ambiente ETL baseado em nuvem.
Para entender melhor o Microsoft Azure, dá uma olhada nos cursos básicos sobre arquitetura, gerenciamento e governança do Azure, como Noções básicas do Microsoft Azure, Noções básicas da arquitetura e dos serviços do Microsoft Azure e Noções básicas do gerenciamento e da governança do Microsoft Azure. Esses recursos oferecem informações valiosas sobre o ecossistema mais amplo do Azure, complementando seu conhecimento sobre o Azure Data Factory e preparando você para uma carreira de sucesso em engenharia de dados.
Aprenda mais sobre o Azure com esses cursos!
Programa
Curso
Curso
blog
Nisha Arya Ahmed
15 min
blog
Austin Chia
15 min
blog
Javier Canales Luna
15 min
blog
Hesam Sheikh Hassani
15 min
