
Leerpad
Microsoft Azure Fundamentals (AZ-900)
9 Hr
Azure Data Factory (ADF) is een cloudgebaseerde data-integratieservice van Microsoft Azure.
Nu datagedreven besluitvorming een centraal onderdeel wordt van bedrijfsvoering, is de vraag naar cloudgebaseerde data-engineeringtools groter dan ooit! Omdat ADF een toonaangevende dienst is, zijn bedrijven steeds vaker op zoek naar dataprofessionals met praktische ervaring om hun datapijplijnen te beheren en hun systemen te integreren.
In dit artikel willen we aspirant-ADF-professionals begeleiden met essentiële interviewvragen en -antwoorden over Azure Data Factory — van algemene, technische en geavanceerde tot scenario-gebaseerde vragen — en geven we tips om te excelleren tijdens het gesprek.
Azure Data Factory is een cloudgebaseerde ETL-service waarmee je datagedreven workflows kunt maken om databeweging en -transformatie te orkestreren en te automatiseren. De service integreert met diverse databronnen en -bestemmingen, zowel on-premises als in de cloud.
Nu teams overstappen op cloud-native infrastructuren, groeit de behoefte om data te beheren in uiteenlopende omgevingen. ADF’s integratie met het Azure-ecosysteem en externe databronnen faciliteert dit, waardoor expertise met de dienst een zeer gewilde vaardigheid is bij organisaties.
Geautomatiseerde BI-architectuur met Azure Data Factory. Beeldbron: Microsoft
In deze sectie focussen we op basisvragen die vaak in interviews worden gesteld om je algemene kennis van ADF te peilen. Deze vragen testen je begrip van basisconcepten, architectuur en componenten.
Beschrijving: Deze vraag wordt vaak gesteld om te beoordelen of je de bouwstenen van ADF begrijpt.
Voorbeeldantwoord: De belangrijkste componenten van Azure Data Factory zijn:
Beschrijving: Deze vraag test je begrip van hoe Azure Data Factory hybride databeweging veilig en efficiënt faciliteert.
Voorbeeldantwoord: Azure Data Factory maakt veilige databeweging tussen cloud- en on-premisesomgevingen mogelijk via de Self-hosted Integration Runtime (IR), die fungeert als brug tussen ADF en on-premises databronnen.
Bijvoorbeeld: bij het verplaatsen van data van een on-premises SQL Server naar Azure Blob Storage maakt de self-hosted IR veilig verbinding met het on-premises systeem. Hierdoor kan ADF data overzetten met beveiliging via versleuteling tijdens transport en in rust. Dit is vooral nuttig voor hybride cloudscenario’s waarbij data is verspreid over on-prem en cloudinfrastructuren.
Beschrijving: Deze vraag beoordeelt je begrip van hoe ADF pipelines automatiseert en plant met verschillende triggertypen.
Voorbeeldantwoord: In Azure Data Factory worden triggers gebruikt om pipeline-uitvoeringen automatisch te starten op basis van specifieke voorwaarden of planningen. Er zijn drie hoofdtypen triggers:
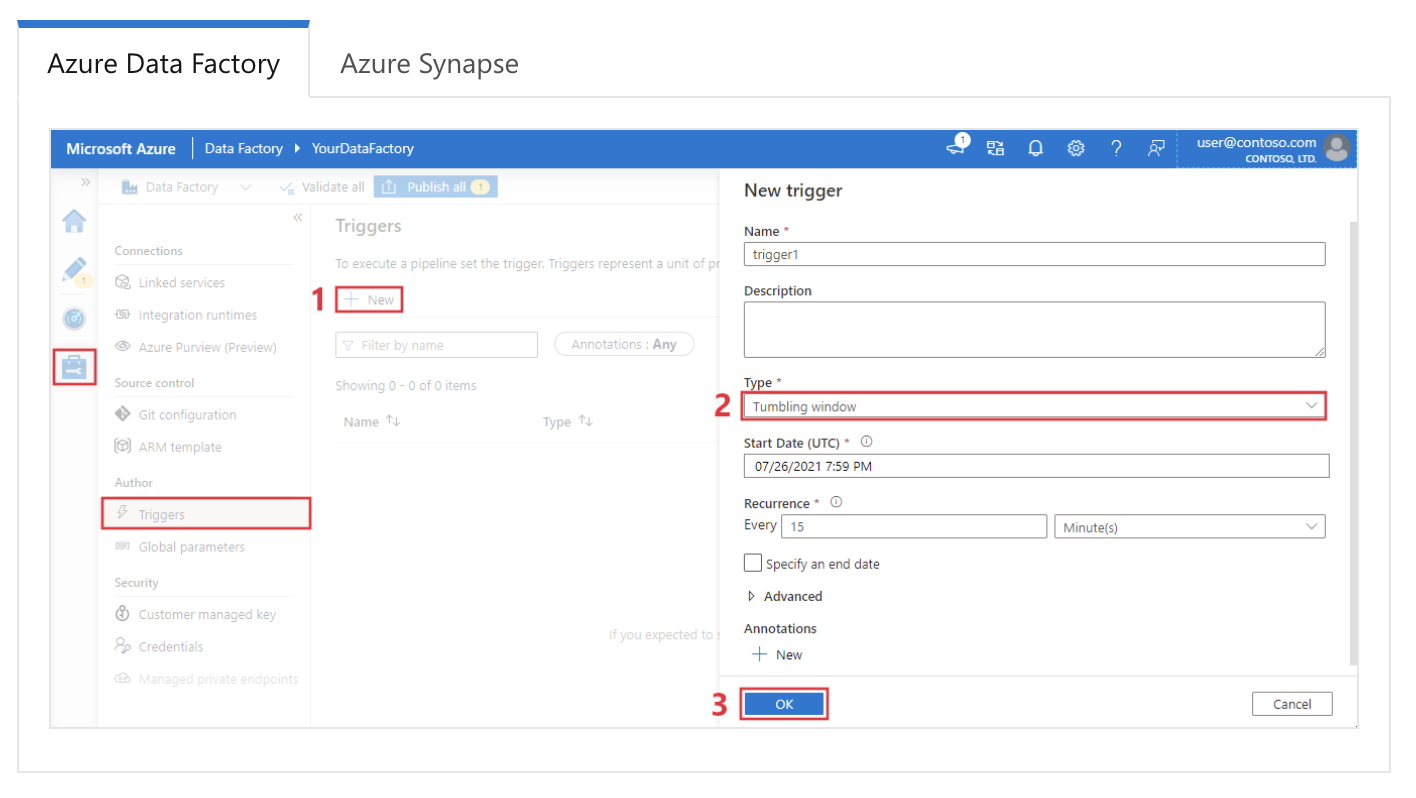
Een tumbling window-trigger configureren in Azure Data Factory. Beeldbron: Microsoft.
Beschrijving: Deze vraag toetst je kennis van de verschillende taken die ADF-pipelines kunnen uitvoeren.
Voorbeeldantwoord: Azure Data Factory-pipelines ondersteunen verschillende typen activiteiten. Dit zijn de meest voorkomende:
|
Activiteitstype |
Beschrijving |
|
Databeweging |
Verplaatst data tussen ondersteunde datastores (bijv. Azure Blob Storage, SQL Database) met de Copy Activity. |
|
Datatransformatie |
Omvat Data Flow Activity voor transformatielogica met Spark, Mapping Data Flows voor ETL-bewerkingen en Wrangling Data Flows voor datapreparatie. |
|
Control flow |
Biedt controle over pipeline-uitvoering met activiteiten zoals ForEach, If Condition, Switch, Wait en Until om conditionele logica te maken. |
|
Externe uitvoering |
Voert externe applicaties of functies uit, waaronder Azure Functions, Web Activities (REST API’s aanroepen) en Stored Procedure Activities voor SQL. |
|
Aangepaste activiteiten |
Maakt het uitvoeren van aangepaste code mogelijk in Custom Activity met .NET of Azure Batch-services, wat flexibiliteit biedt voor geavanceerde dataverwerkingsbehoeften. |
|
Andere services |
Ondersteunt HDInsight-, Databricks- en Data Lake Analytics-activiteiten, die integreren met andere Azure-analyticadiensten voor complexe datataken. |
Beschrijving: Deze vraag controleert je bekendheid met de monitoring- en debuggingtools van ADF.
Voorbeeldantwoord: Azure Data Factory biedt een robuuste monitorings- en debugginginterface via het tabblad Monitor in de Azure-portal. Hier kan ik pipelineruns volgen, activiteitstatussen bekijken en storingen diagnosticeren. Elke activiteit genereert logs die kunnen worden geraadpleegd om fouten te identificeren en problemen op te lossen.
Daarnaast kan Azure Monitor worden geconfigureerd om waarschuwingen te versturen op basis van pipelinefouten of prestatieproblemen. Voor debugging begin ik meestal met het bekijken van de logs van mislukte activiteiten, bekijk ik de foutdetails en voer ik de pipeline opnieuw uit nadat het probleem is verholpen.
Beschrijving: Deze vraag test of je op de hoogte bent van de nieuwste evolutie van Microsofts dataplatform.
Voorbeeldantwoord: Hoewel beide dezelfde engine delen, is Data Factory in Fabric een SaaS (Software as a Service)-aanbod dat is geïntegreerd in het Fabric-ecosysteem, terwijl Azure Data Factory (ADF) een PaaS (Platform as a Service)-resource is. Belangrijke verschillen zijn:
Beschrijving: Deze vraag beoordeelt je kennis van de beveiligingsmechanismen van ADF om data gedurende de hele levenscyclus te beschermen.
Voorbeeldantwoord: Azure Data Factory waarborgt databeveiliging via verschillende mechanismen.
Ten eerste gebruikt het versleuteling voor data zowel tijdens transport als in rust, met protocollen zoals TLS en AES om datatransfers te beveiligen. ADF integreert met Azure Active Directory (AAD) voor authenticatie en gebruikt Role-Based Access Control (RBAC) om te beperken wie de factory kan openen en beheren.
Daarnaast stellen Managed Identities ADF in staat om andere Azure-services veilig te benaderen zonder inloggegevens bloot te leggen. Voor netwerkbeveiliging ondersteunt ADF Private Endpoints, zodat dataverkeer binnen het Azure-netwerk blijft en er een extra beveiligingslaag wordt toegevoegd.
Beschrijving: Deze vraag toetst je begrip van de verschillende rollen die Linked Services en Datasets in ADF spelen.
Voorbeeldantwoord: In Azure Data Factory definieert een Linked Service de verbinding met een externe databron of compute-service, vergelijkbaar met een connection string. Het bevat de authenticatie-informatie die nodig is om met de resource te verbinden.
Een Dataset daarentegen vertegenwoordigt de specifieke data waarmee je werkt, zoals een tabel in een database of een bestand in Blob Storage.
Waar de Linked Service aangeeft waar de data zich bevindt, beschrijft de Dataset hoe die eruitziet en hoe deze is gestructureerd. Deze twee componenten werken samen om databeweging en -transformatie te faciliteren.
Technische interviewvragen richten zich vaak op je begrip van specifieke functies, hun implementaties en hoe ze samenwerken om effectieve datapijplijnen te bouwen. Deze vragen beoordelen je hands-on ervaring en kennis van de kerncomponenten en mogelijkheden van ADF.
Beschrijving: Deze vraag test je vermogen om strategieën voor foutafhandeling in ADF-pipelines te implementeren.
Voorbeeldantwoord: Foutafhandeling in Azure Data Factory kan worden geïmplementeerd met Retry Policies en Error Handling Activities. ADF biedt ingebouwde retrymechanismen, waarbij je het aantal pogingen en het interval tussen pogingen kunt configureren als een activiteit faalt.
Als een Copy Activity bijvoorbeeld faalt door een tijdelijk netwerkprobleem, kun je de activiteit zo instellen dat deze 3 keer opnieuw probeert met een interval van 10 minuten tussen elke poging.
Daarnaast kunnen Set-Activity Dependency Conditions zoals Failure, Completion en Skipped specifieke acties triggeren afhankelijk van of een activiteit slaagt of faalt.
Zo kan ik bijvoorbeeld een pipelineflow definiëren zodat bij een mislukking van een activiteit een aangepaste foutafhandelingsactiviteit wordt uitgevoerd, zoals het versturen van een alert of het uitvoeren van een fallbackproces.
Beschrijving: Deze vraag beoordeelt je begrip van de compute-infrastructuur achter databeweging en activity dispatch in ADF.
Voorbeeldantwoord: De Integration Runtime (IR) is de compute-infrastructuur die Azure Data Factory gebruikt voor databeweging, transformatie en activity dispatch. Het is cruciaal voor het beheren van hoe en waar data wordt verwerkt en kan worden geoptimaliseerd op basis van de bron, bestemming en transformatievereisten. Ter context zijn er drie typen IR:
|
Integration Runtime (IR)-type |
Beschrijving |
|
Azure Integration Runtime |
Gebruikt voor databeweging en transformatieactiviteiten binnen Azure-datacenters. Ondersteunt copy-activiteiten, dataflowtransformaties en verzendt activiteiten naar Azure-resources. |
|
Self-hosted Integration Runtime |
Geïnstalleerd on-premises of op virtuele machines in een privé netwerk om dataintegratie mogelijk te maken tussen on-premises, privé en Azure-resources. Nuttig voor het kopiëren van data van on-premises naar Azure. |
|
Azure-SSIS Integration Runtime |
Stelt je in staat om bestaande SQL Server Integration Services (SSIS)-pakketten te lift-and-shiften naar Azure, met native ondersteuning voor SSIS-pakketuitvoering binnen Azure Data Factory. Ideaal voor gebruikers die SSIS-werkbelasting willen migreren zonder uitgebreide herwerking. |
Beschrijving: Deze vraag controleert je begrip van hoe parameterisatie in ADF werkt om herbruikbare en flexibele pipelines te maken.
Voorbeeldantwoord: Parameterisatie in Azure Data Factory maakt dynamische pipeline-uitvoering mogelijk, waarbij je bij elke run verschillende waarden kunt meegeven.
Zo kan ik in een Copy Activity parameters gebruiken om het bronbestandspad en de doelmap dynamisch op te geven. Ik zou de parameters op pipelineniveau definiëren en ze doorgeven aan de relevante dataset of activiteit.
Hier is een eenvoudig voorbeeld:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}Parameterisatie maakt pipelines herbruikbaar en maakt schalen eenvoudig door invoer tijdens runtime dynamisch aan te passen.
Beschrijving: Deze vraag beoordeelt je kennis van datatransformatie in ADF zonder externe compute-services nodig te hebben.
Voorbeeldantwoord: Een Mapping Data Flow in Azure Data Factory stelt je in staat om transformaties op data uit te voeren zonder code te schrijven of data buiten het ADF-ecosysteem te verplaatsen. Het biedt een visuele interface waarmee je complexe transformaties kunt bouwen.
Dataflows worden uitgevoerd op Spark-clusters binnen de beheerde omgeving van ADF, wat schaalbare en efficiënte datatransformaties mogelijk maakt.
In een typisch transformatiescenario kan ik bijvoorbeeld een dataflow gebruiken om twee datasets te joinen, de resultaten te aggregeren en de output naar een nieuwe bestemming te schrijven — allemaal visueel en zonder externe services zoals Databricks.
Beschrijving: Deze vraag test je vermogen om dynamische schemawijzigingen tijdens datatransformatie te beheren.
Voorbeeldantwoord: Schema drift verwijst naar veranderingen in de structuur van brondata in de tijd.
Azure Data Factory pakt schema drift aan met de optie Allow Schema Drift in Mapping Data Flows. Hiermee kan ADF zich automatisch aanpassen aan wijzigingen in het schema van binnenkomende data, zoals toegevoegde of verwijderde kolommen, zonder het hele schema opnieuw te definiëren.
Door schema drift in te schakelen kan ik een pipeline configureren om kolommen dynamisch te mappen, zelfs als het bronschema verandert.
Optie Allow schema drift in Azure Data Factory. Beeldbron: Microsoft
Beschrijving: Deze vraag beoordeelt je bekendheid met moderne methoden voor continue data-inname versus batchverwerking.
Voorbeeldantwoord: De CDC-resource in ADF biedt een low-code manier om gewijzigde data continu te repliceren van bronnen (zoals een SQL- of Cosmos-database) naar een bestemming, zonder complexe watermarklogica.
In tegenstelling tot een standaard pipelinetrigger die op schema draait, draait de CDC-resource continu (of in microbatches), waarbij automatisch inserts, updates en deletes aan de bron worden bijgehouden en toegepast op het doel. Dit is ideaal voor scenario’s die near-real-time datasynchronisatie vereisen.
Geavanceerde interviewvragen gaan dieper in op ADF-functionaliteiten en focussen op prestatieoptimalisatie, praktijkcases en geavanceerde architectuurbeslissingen.
Deze vragen zijn bedoeld om je ervaring met complexe datasituaties te peilen en je vermogen om uitdagende problemen met ADF op te lossen.
Beschrijving: Deze vraag beoordeelt je vermogen om problemen op te lossen en de efficiëntie van pipelines te verbeteren.
Voorbeeldantwoord: Ik volg doorgaans verschillende strategieën om de prestaties van een Azure Data Factory-pipeline te optimaliseren.
Allereerst zorg ik dat ik parallelle uitvoering benut door Concurrent Pipeline Runs te gebruiken om data waar mogelijk parallel te verwerken. Ook gebruik ik Partitioning binnen de Copy Activity om grote datasets op te splitsen en kleinere delen gelijktijdig over te zetten.
Een andere belangrijke optimalisatie is het kiezen van de juiste Integration Runtime op basis van de databron en transformatievereisten. Het gebruik van een Self-hosted IR voor on-premisedata kan bijvoorbeeld on-prem-naar-cloudtransfers versnellen.
Daarnaast kan het inschakelen van Staging in de Copy Activity de prestaties verbeteren door grote datasets te bufferen vóór de definitieve laadstap.
Beschrijving: Deze vraag beoordeelt je begrip van veilig beheer van inloggegevens in ADF.
Voorbeeldantwoord: Azure Key Vault speelt een cruciale rol bij het beveiligen van gevoelige informatie zoals connection strings, wachtwoorden en API-sleutels binnen Azure Data Factory. In plaats van secrets hardcoded op te nemen in pipelines of Linked Services, gebruik ik Key Vault om deze secrets op te slaan en te beheren.
De ADF-pipeline kan tijdens runtime secrets veilig ophalen uit Key Vault, zodat inloggegevens beschermd blijven en niet in code worden blootgesteld. Bij het instellen van een Linked Service om verbinding te maken met een Azure SQL Database gebruik ik bijvoorbeeld een secretreferentie uit Key Vault voor veilige authenticatie.
Beschrijving: Deze vraag controleert je bekendheid met versiebeheer en geautomatiseerde deployment in ADF.
Voorbeeldantwoord: Azure Data Factory integreert met Azure DevOps of GitHub voor CI/CD-workflows. Meestal configureer ik ADF om verbinding te maken met een Git-repository, zodat er versiebeheer is voor pipelines, datasets en Linked Services. Het proces omvat het maken van branches, wijzigingen doorvoeren in een ontwikkelomgeving en die wijzigingen committen naar de repository.
Voor deployment ondersteunt ADF ARM-sjablonen die kunnen worden geëxporteerd en gebruikt in verschillende omgevingen, zoals staging en productie. Met pipelines kan ik het deploymentproces automatiseren, zodat wijzigingen worden getest en efficiënt worden gepromoveerd door verschillende omgevingen heen.
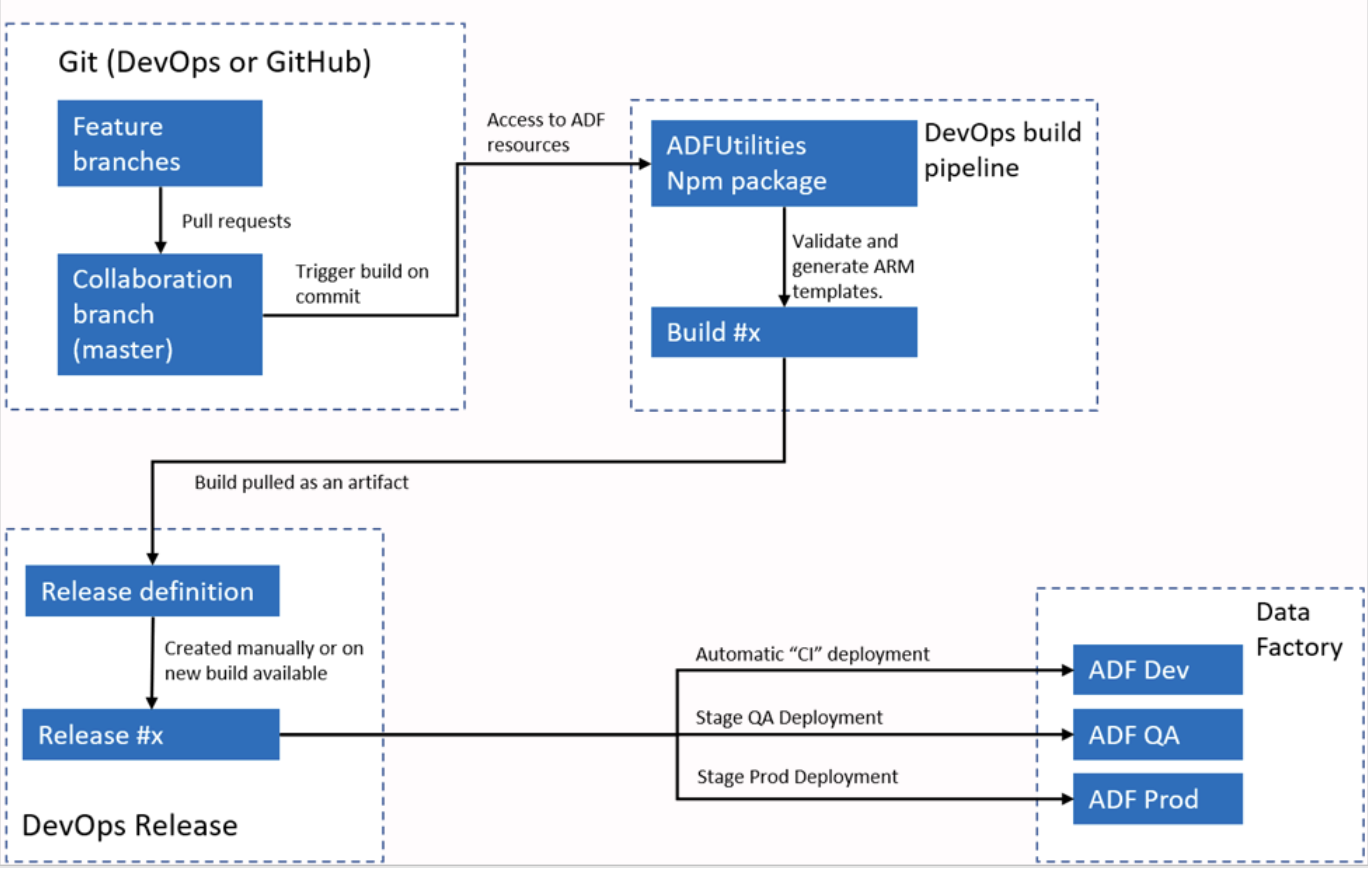
Geautomatiseerde CI/CI-workflow van Azure Data Factory. Beeldbron: Microsoft.
Beschrijving: Deze vraag beoordeelt je begrip van de mogelijkheden van ADF bij het afhandelen van hybride dataomgevingen.
Voorbeeldantwoord: Het ontwerpen van een hybride datapipeline met Azure Data Factory vereist het gebruik van de Self-hosted Integration Runtime (IR) om on-premises en cloudomgevingen te overbruggen. De IR wordt geïnstalleerd op een machine binnen het on-premises netwerk, waardoor ADF veilig data kan verplaatsen tussen on-premises en cloudresources zoals Azure Blob Storage of Azure SQL Database.
Wanneer ik bijvoorbeeld on-prem SQL Server-data moet overzetten naar een Azure Data Lake, zet ik de Self-hosted IR op om veilig toegang te krijgen tot de SQL Server, definieer ik datasets voor de bron en bestemming, en gebruik ik een Copy Activity om de data te verplaatsen. Ik kan ook transformaties of opschoningsstappen toevoegen met Mapping Data Flows.
Beschrijving: Deze vraag test je vermogen om dynamische schemamapping in complexe dataflows te configureren.
Voorbeeldantwoord: Dynamische mapping in een Mapping Data Flow biedt flexibiliteit wanneer het bronschema kan veranderen. Ik implementeer dynamische mapping met de Auto Mapping-functie in Data Flow, die bronkolommen automatisch op naam aan bestemmingkolommen koppelt.
Voor complexere scenario’s gebruik ik Derived Columns en de Expression Language in Data Flows om kolommen dynamisch toe te wijzen of te wijzigen op basis van hun metadata. Deze aanpak helpt bij schema drift of wanneer de pipeline meerdere verschillende bronschema’s moet verwerken zonder handmatige remapping.
Beschrijving: Deze vraag controleert je vermogen om pipelines te ontwerpen die voldoen aan enterprise data governance-standaarden.
Voorbeeldantwoord: ADF integreert native met Microsoft Purview om lineage-data door te geven. Wanneer een pipeline draait, stuurt ADF metadata naar Purview die beschrijft:
Hiermee kunnen datastewards de stroom van data binnen de organisatie visualiseren. Je koppelt ze door de ADF-instantie te registreren binnen het Purview-governanceportaal.
Gedrags- en scenario-gebaseerde interviewvragen richten zich op hoe kandidaten hun technische vaardigheden toepassen in praktijksituaties.
Deze vragen helpen om probleemoplossend vermogen, troubleshooting en optimalisatievaardigheden binnen complexe dataworkflows te beoordelen. Ze geven ook inzicht in het beslissingsproces van een kandidaat en diens ervaring met uitdagingen rond dataintegratie en ETL-processen.
Beschrijving: Deze vraag beoordeelt je probleemoplossende vaardigheden, vooral bij pipelinefalen of onverwachte issues.
Voorbeeldantwoord: In een project had ik een pipeline die consequent faalde bij het overzetten van data van een on-premises SQL Server naar Azure Blob Storage.
De foutlogs wezen op een timeout tijdens het databewegingsproces. Voor de troubleshooting controleerde ik eerst de configuratie van de Self-hosted Integration Runtime (IR), die verantwoordelijk was voor de on-premises dataverbinding.
Na inspectie bleek dat de machine waarop de IR draaide veel CPU gebruikte, wat vertragingen veroorzaakte bij de datatransfer.
Om het probleem op te lossen, verhoogde ik de rekenkracht van de machine en verdeelde ik de werklast door de data in kleinere delen te partitioneren via de instellingen van de Copy Activity.
Dit maakte parallelle dataverwerking mogelijk, wat de laadtijden verkortte en timeouts voorkwam. Na deze wijzigingen draaide de pipeline succesvol en verdween de fout.
Beschrijving: Deze vraag beoordeelt je vermogen om optimalisatietechnieken te identificeren en te implementeren in dataworkflows.
Voorbeeldantwoord: In een project waarin we grote hoeveelheden financiële data uit meerdere bronnen moesten verwerken, duurde de initiële pipeline te lang door het datavolume. Om te optimaliseren heb ik eerst parallelisme ingeschakeld door meerdere Copy Activities gelijktijdig te laten draaien, elk met een andere datasetpartitie.
Vervolgens gebruikte ik de stagingfunctie in de Copy Activity om data tijdelijk te bufferen in Azure Blob Storage voordat deze verder werd verwerkt, wat de throughput aanzienlijk verbeterde. Ook paste ik Data Flow-optimalisaties toe door lookuptabellen die in transformaties werden gebruikt te cachen.
Deze aanpassingen verbeterden de prestaties van de pipeline met 40%, waardoor de uitvoeringstijd afnam.
Beschrijving: Deze vraag controleert hoe je onverwachte schemawijzigingen beheert en zorgt dat pipelines blijven functioneren.
Voorbeeldantwoord: Ja, in een van mijn projecten veranderde het schema van een databron (een externe API) onverwacht toen er een nieuwe kolom aan de dataset werd toegevoegd. Hierdoor faalde de pipeline omdat het schema in de Mapping Data Flow niet langer aansloot.
Om dit op te lossen schakelde ik de optie Allow Schema Drift in de Data Flow in, waardoor de pipeline wijzigingen in het schema automatisch kon detecteren en verwerken.
Daarnaast configureerde ik dynamische kolommapping met Derived Columns, zodat de nieuwe kolom werd meegenomen zonder specifieke kolomnamen hardcoded op te nemen. Hierdoor kon de pipeline zich aanpassen aan toekomstige schemawijzigingen zonder handmatig ingrijpen.
Beschrijving: Deze vraag beoordeelt je vermogen om integratie van meerdere bronnen aan te pakken, een veelvoorkomende eis in complexe ETL-processen.
Voorbeeldantwoord: In een recent project moest ik data integreren uit drie bronnen: een on-premises SQL Server, Azure Data Lake en een REST API. Ik gebruikte een combinatie van een Self-hosted Integration Runtime voor de on-premises SQL Server-verbinding en een Azure Integration Runtime voor de cloudgebaseerde services.
Ik maakte een pipeline die de Copy Activity gebruikte om data op te halen uit de SQL Server en de REST API, deze te transformeren met Mapping Data Flows en te combineren met data die was opgeslagen in Azure Data Lake.
Door de pipelines te parameteriseren, zorgde ik voor flexibiliteit bij het verwerken van verschillende datasets en planningen. Dit maakte integratie van meerdere bronnen mogelijk, wat cruciaal was voor het data-analyseplatform van de klant.
Beschrijving: Deze vraag onderzoekt hoe je datakwaliteitsproblemen identificeert en aanpakt binnen je pipelineworkflows.
Voorbeeldantwoord: In één geval werkte ik aan een pipeline die klantdata uit een CRM-systeem extraheerde. De data bevatte echter missende waarden en duplicaten, wat de uiteindelijke rapportage beïnvloedde. Om deze datakwaliteitsproblemen aan te pakken, nam ik een Data Flow op in de pipeline die opschoningsbewerkingen uitvoerde.
Ik gebruikte filters om duplicaten te verwijderen en een conditional split om missende waarden af te handelen. Ik zette een lookup op voor ontbrekende of onjuiste data om standaardwaarden uit een referentiedataset op te halen. Aan het einde van dit proces was de datakwaliteit aanzienlijk verbeterd, waardoor de downstream-analyse nauwkeurig en betrouwbaar was.
Beschrijving: Deze vraag test je ervaring met geavanceerde datatransformaties met ADF.
Voorbeeldantwoord: In een financieel rapportageproject moest ik transactionele data uit meerdere bronnen samenvoegen, aggregaties toepassen en samenvattende rapporten per regio genereren. De uitdaging was dat elke databron een iets andere structuur en naamgeving had. Ik implementeerde de transformatie met Mapping Data Flows.
Eerst standaardiseerde ik de kolomnamen over alle datasets met Derived Columns. Vervolgens paste ik aggregaties toe om regiogebonden metrics te berekenen, zoals totale omzet en gemiddelde transactiewaarde. Tot slot gebruikte ik een pivottransformatie om de data te herschikken voor eenvoudige rapportage. De hele transformatie werd binnen ADF uitgevoerd, met gebruik van de ingebouwde transformaties en schaalbare infrastructuur.
Beschrijving: Deze vraag beoordeelt je begrip van databeveiligingspraktijken in ADF.
Voorbeeldantwoord: In een project werkten we met gevoelige klantdata die veilig moest worden overgezet van een on-premises SQL Server naar Azure SQL Database. Ik gebruikte Azure Key Vault om de database-inloggegevens op te slaan en de data te beveiligen, zodat gevoelige informatie zoals wachtwoorden niet hardcoded in de pipeline of Linked Services stond.
Daarnaast implementeerde ik data-encryptie tijdens databeweging door SSL-verbindingen in te schakelen tussen de on-premises SQL Server en Azure.
Ook gebruikte ik role-based access control (RBAC) om de toegang tot de ADF-pipeline te beperken, zodat alleen geautoriseerde gebruikers deze konden starten of wijzigen. Deze setup zorgde zowel voor een veilige datatransfer als voor goed toegangsbeheer.
Beschrijving: Deze vraag beoordeelt je vermogen om event-driven pipeline-uitvoeringen te implementeren.
Voorbeeldantwoord: In één scenario moest de pipeline draaien zodra er een nieuw bestand met verkoopdata werd geüpload naar Azure Blob Storage. Om dit te implementeren, gebruikte ik een Event-Based Trigger in Azure Data Factory. De trigger luisterde naar Blob Created-events in een specifieke container en startte automatisch de pipeline zodra er een nieuw bestand werd geüpload.
Deze event-driven aanpak zorgde ervoor dat de pipeline alleen draaide wanneer er nieuwe data beschikbaar was, waardoor handmatige uitvoering of geplande runs overbodig werden. De pipeline verwerkte vervolgens het bestand, transformeerde het en laadde het in het datawarehouse voor verdere analyse.
Beschrijving: Deze vraag beoordeelt je ervaring met het migreren van traditionele ETL-processen naar de cloud met ADF.
Voorbeeldantwoord: In een project om een bestaand, op SSIS gebaseerd ETL-proces van on-premises naar de cloud te migreren, gebruikte ik Azure Data Factory met de Azure-SSIS Integration Runtime.
Eerst beoordeelde ik de bestaande SSIS-pakketten om te zorgen dat ze compatibel waren met ADF en voerde ik de noodzakelijke aanpassingen door om cloudgebaseerde databronnen te ondersteunen.
Ik zette de Azure-SSIS IR op om de SSIS-pakketten in de cloud te draaien met behoud van de bestaande workflows. Voor de nieuwe cloudomgeving verving ik ook enkele traditionele ETL-activiteiten door native ADF-componenten zoals Copy Activities en Mapping Data Flows, wat de algehele prestaties en schaalbaarheid van de dataworkflows verbeterde.
Beschrijving: Deze vraag test je operationele volwassenheid en begrip van het factureringsmodel van ADF.
Voorbeeldantwoord: Ik zou eerst het Pipeline Run Consumption-rapport in Azure Monitor analyseren om de kostenveroorzakers te identificeren (bijv. veel Data Flow-compute-uren of overmatige API-calls). Veelvoorkomende optimalisatiestrategieën zijn:
Voorbereiden op een Azure Data Factory-interview vraagt om een diep begrip van zowel de technische als praktische aspecten van het platform. Het is essentieel om je kennis van de kernfuncties van ADF te tonen en je vermogen om die in praktijksituaties toe te passen.
Hier zijn mijn beste tips om je klaar te stomen voor het gesprek:
Azure Data Factory is een krachtig hulpmiddel voor het bouwen van cloudgebaseerde ETL-oplossingen, en expertise daarin is zeer gewild in de data-engineeringwereld!
In dit artikel hebben we essentiële interviewvragen behandeld, variërend van algemene concepten tot technische en scenario-gebaseerde onderwerpen, en benadrukt hoe belangrijk kennis is van ADF-functies en tools. De praktijkvoorbeelden van pipelinebeheer, datatransformatie en troubleshooting illustreren de cruciale vaardigheden die nodig zijn in een cloudgebaseerde ETL-omgeving.
Wil je je begrip van Microsoft Azure verdiepen? Verken dan basiscursussen over Azure-architectuur, -beheer en -governance, zoals Understanding Microsoft Azure, Understanding Microsoft Azure Architecture and Services en Understanding Microsoft Azure Management and Governance. Deze resources bieden waardevolle inzichten in het bredere Azure-ecosysteem, vullen je kennis van Azure Data Factory aan en bereiden je voor op een succesvolle carrière in data-engineering.
Leer meer over Azure met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
