
programa
Microsoft Azure Fundamentals (AZ-900)
9 h
Azure Data Factory (ADF) es un servicio de integración de datos basado en la nube proporcionado por Microsoft Azure.
A medida que la toma de decisiones basada en datos se convierte en un aspecto central de las operaciones comerciales, ¡la demanda de herramientas de ingeniería de datos basadas en la nube está en su punto más alto! Dado que ADF es un servicio líder, las empresas buscan cada vez más profesionales de datos con experiencia práctica para gestionar sus canales de datos e integrar sus sistemas.
En este artículo, nuestro objetivo es orientar a los aspirantes a profesionales de ADF a través de preguntas y respuestas esenciales para las entrevistas de Azure Data Factory, que abarcan cuestiones generales, técnicas, avanzadas y basadas en escenarios, al tiempo que ofrecemos consejos para superar con éxito la entrevista.
Azure Data Factory es un servicio ETL basado en la nube que te permite crear flujos de trabajo basados en datos para coordinar y automatizar el movimiento y la transformación de datos. El servicio se integra con diversas fuentes y destinos de datos locales y en la nube.
A medida que los equipos avanzan hacia infraestructuras nativas de la nube, existe una necesidad creciente de gestionar datos en entornos diversos. La integración de ADF con el ecosistema de Azure y fuentes de datos de terceros facilita esto, lo que hace que la experiencia con el servicio sea una habilidad muy buscada por las organizaciones.
Arquitectura de BI automatizada mediante Azure Data Factory. Fuente de la imagen: Microsoft
En esta sección, nos centraremos en preguntas básicas que suelen plantearse en las entrevistas para evaluar tus conocimientos generales sobre ADF. Estas preguntas evalúan tu comprensión de los conceptos básicos, la arquitectura y los componentes.
Descripción: Esta pregunta se suele hacer para evaluar si entiendes los componentes básicos de ADF.
Ejemplo de respuesta: Los componentes principales de Azure Data Factory son:
Descripción: Esta pregunta evalúa tu comprensión de cómo Azure Data Factory facilita el movimiento híbrido de datos de forma segura y eficiente.
Ejemplo de respuesta: Azure Data Factory permite el traslado seguro de datos entre entornos en la nube y locales a través del tiempo de ejecución de integración autohospedado (IR), que actúa como puente entre ADF y las fuentes de datos locales.
Por ejemplo, al mover datos de un servidor SQL local a Azure Blob Storage, el IR autohospedado se conecta de forma segura al sistema local. Esto permite a ADF transferir datos garantizando la seguridad mediante el cifrado tanto en tránsito como en reposo. Esto resulta especialmente útil en entornos de nube híbrida, en los que los datos se distribuyen entre infraestructuras locales y en la nube.
Descripción: Esta pregunta evalúa tu comprensión de cómo ADF automatiza y programa canalizaciones utilizando diferentes tipos de desencadenadores.
Ejemplo de respuesta: En Azure Data Factory, los desencadenadores se utilizan para iniciar automáticamente ejecuciones de canalizaciones en función de condiciones o programaciones específicas. Hay tres tipos principales de desencadenantes:
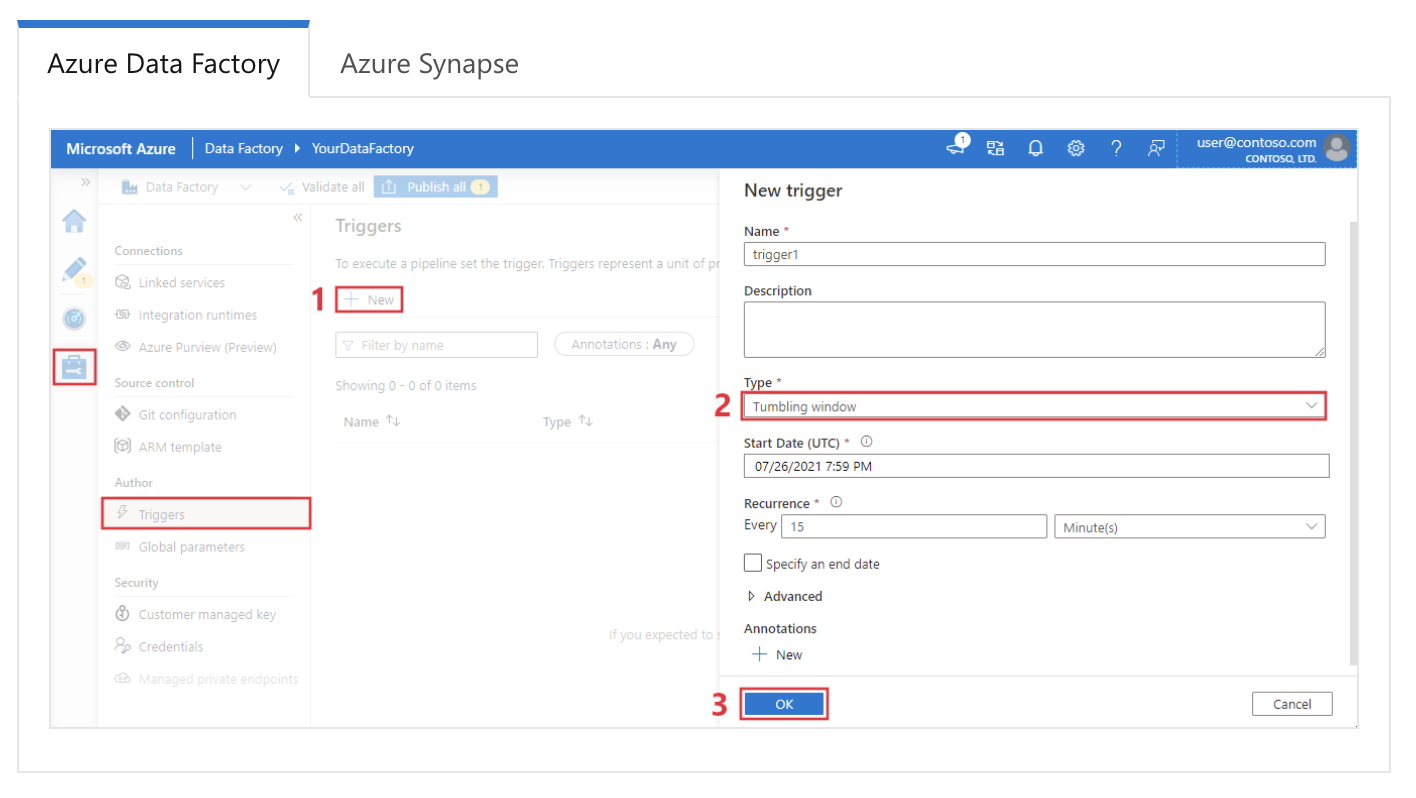
Configuración de un desencadenador de ventana móvil en Azure Data Factory. Fuente de la imagen: Microsoft.
Descripción: Esta pregunta evalúa tus conocimientos sobre las diversas tareas que pueden realizar las canalizaciones ADF.
Ejemplo de respuesta: Las canalizaciones de Azure Data Factory admiten varios tipos de actividades. Estos son los más comunes:
|
Tipo de actividad |
Descripción |
|
Movimiento de datos |
Mueve datos entre almacenes de datos compatibles (por ejemplo, Azure Blob Storage, SQL Database) con la actividad Copiar. |
|
Transformación de datos |
Incluye actividad de flujo de datos para la lógica de transformación de datos mediante Spark, mapeo de flujos de datos para operaciones ETL y manipulación de flujos de datos para la preparación de datos. |
|
Flujo de control |
Proporciona control sobre la ejecución del proceso mediante actividades como ForEach, If Condition, Switch, Wait y Until para crear lógica condicional. |
|
Ejecución externa |
Ejecuta aplicaciones o funciones externas, incluidas Azure Functions, actividades web (llamadas a API REST) y actividades de procedimientos almacenados para SQL. |
|
Actividades personalizadas |
Permite la ejecución de código personalizado en Custom Activity utilizando servicios .NET o Azure Batch, lo que proporciona flexibilidad para necesidades avanzadas de procesamiento de datos. |
|
Otros servicios |
Admite actividades de HDInsight, Databricks y Data Lake Analytics, que se integran con otros servicios de análisis de Azure para tareas de datos complejas. |
Descripción: Esta pregunta comprueba tu familiaridad con las herramientas de supervisión y depuración de ADF.
Ejemplo de respuesta: Azure Data Factory proporciona una interfaz sólida de supervisión y depuración a través de la pestaña Supervisar del portal de Azure. Aquí puedo programar las ejecuciones de los procesos, ver el estado de las actividades y diagnosticar fallos. Cada actividad genera registros, que pueden revisarse para identificar errores y solucionar problemas.
Además, Azure Monitor se puede configurar para enviar alertas basadas en fallos del canal o problemas de rendimiento. Para depurar, normalmente empiezo por consultar los registros de las actividades fallidas, reviso los detalles del error y, a continuación, vuelvo a ejecutar el proceso después de solucionar el problema.
Descripción: Esta pregunta evalúa si estás al día con la última evolución de la plataforma de datos de Microsoft.
Ejemplo de respuesta: Aunque ambos comparten el mismo motor, Data Factory en Fabric es una oferta SaaS (Software as a Service) integrada en el ecosistema Fabric, mientras que Azure Data Factory (ADF) es un recurso PaaS (Platform as a Service). Las diferencias principales incluyen:
Descripción: Esta pregunta evalúa tus conocimientos sobre los mecanismos de seguridad de ADF para proteger los datos a lo largo de su ciclo de vida.
Ejemplo de respuesta: Azure Data Factory garantiza la seguridad de los datos mediante varios mecanismos.
En primer lugar, utiliza cifrado para los datos tanto en tránsito como en reposo, empleando protocolos como TLS y AES para proteger las transferencias de datos. ADF se integra con Azure Active Directory (AAD) para la autenticación y utiliza el control de acceso basado en roles (RBAC) para restringir quién puede acceder y gestionar la fábrica.
Además, las identidades administradas permiten a ADF acceder de forma segura a otros servicios de Azure sin exponer las credenciales. Para garantizar la seguridad de la red, ADF admite puntos de conexión privados, lo que garantiza que el tráfico de datos permanezca dentro de la red de Azure y añade otra capa de protección.
Descripción: Esta pregunta evalúa tu comprensión de las diferentes funciones que desempeñan los servicios vinculados y los conjuntos de datos en ADF.
Ejemplo de respuesta: En Azure Data Factory, un servicio vinculado define la conexión a una fuente de datos externa o un servicio informático, de forma muy similar a una cadena de conexión. Incluye la información de autenticación necesaria para conectarse al recurso.
Por otro lado, un conjunto de datos representa los datos específicos con los que trabajarás, como una tabla en una base de datos o un archivo en Blob Storage.
Mientras que el servicio vinculado define dónde se encuentran los datos, el conjunto de datos describe cómo son y cómo están estructurados. Estos dos componentes trabajan juntos para facilitar el movimiento y la transformación de datos.
Las preguntas de las entrevistas técnicas suelen centrarse en tu comprensión de características específicas, su implementación y cómo funcionan conjuntamente para crear canales de datos eficaces. Estas preguntas evalúan tu experiencia práctica y tus conocimientos sobre los componentes y capacidades principales de ADF.
Descripción: Esta pregunta evalúa tu capacidad para implementar estrategias de gestión de errores en canalizaciones ADF.
Ejemplo de respuesta: La gestión de errores en Azure Data Factory se puede implementar mediante políticas de reintento y actividades de gestión de errores. ADF ofrece mecanismos de reintento integrados, en los que puedes configurar el número de reintentos y el intervalo entre ellos si una actividad falla.
Por ejemplo, si una actividad de copia falla debido a un problema temporal de red, puedes configurar la actividad para que vuelva a intentarlo tres veces con un intervalo de 10 minutos entre cada intento.
Además, las condiciones de dependencia de la actividad establecida, como «Fallo», «Finalización» y «Omisión», pueden desencadenar acciones específicas en función de si una actividad tiene éxito o fracasa.
Por ejemplo, podría definir un flujo de canalización de tal manera que, ante el fallo de una actividad, se ejecute una actividad personalizada de gestión de errores, como enviar una alerta o ejecutar un proceso alternativo.
Descripción: Esta pregunta evalúa tu comprensión de la infraestructura informática que hay detrás del movimiento de datos y el envío de actividades en ADF.
Ejemplo de respuesta: El tiempo de ejecución de integración (IR) es la infraestructura informática que Azure Data Factory utiliza para realizar el movimiento de datos, la transformación y el envío de actividades. Es fundamental para gestionar cómo y dónde se procesan los datos, y se puede optimizar en función de la fuente, el destino y los requisitos de transformación. Para más contexto, hay tres tipos de IR:
|
Tipo de tiempo de ejecución de integración (IR) |
Descripción |
|
Tiempo de ejecución de integración de Azure |
Se utiliza para actividades de movimiento y transformación de datos dentro de los centros de datos de Azure. Admite actividades de copia, transformaciones de flujo de datos y envía actividades a recursos de Azure. |
|
Tiempo de ejecución de integración autohospedado |
Instalado en máquinas locales o virtuales en una red privada para permitir la integración de datos entre recursos locales, privados y de Azure. Útil para copiar datos de las instalaciones locales a Azure. |
|
Tiempo de ejecución de integración de Azure-SSIS |
Te permite trasladar tus paquetes actuales de SQL Server Integration Services (SSIS) a Azure, lo que permite la ejecución nativa de paquetes SSIS en Azure Data Factory. Ideal para usuarios que desean migrar cargas de trabajo SSIS sin necesidad de realizar grandes modificaciones. |
Descripción: Esta pregunta comprueba tu comprensión de cómo funciona la parametrización en ADF para crear canalizaciones reutilizables y flexibles.
Ejemplo de respuesta: La parametrización en Azure Data Factory permite la ejecución dinámica de canalizaciones, en la que puedes pasar diferentes valores durante cada ejecución.
Por ejemplo, en una actividad Copiar, podría utilizar parámetros para especificar dinámicamente la ruta del archivo de origen y la carpeta de destino. Definiría los parámetros a nivel de canalización y los pasaría al conjunto de datos o actividad pertinentes.
Aquí tienes un ejemplo sencillo:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}La parametrización hace que las canalizaciones sean reutilizables y permite un fácil escalado mediante el ajuste dinámico de las entradas durante el tiempo de ejecución.
Descripción: Esta pregunta evalúa tus conocimientos sobre la transformación de datos en ADF sin necesidad de servicios informáticos externos.
Ejemplo de respuesta: Un flujo de datos de mapeo en Azure Data Factory te permite realizar transformaciones en los datos sin escribir código ni mover datos fuera del ecosistema ADF. Proporciona una interfaz visual en la que puedes crear transformaciones complejas.
Los flujos de datos se ejecutan en clústeres Spark dentro del entorno gestionado de ADF, lo que permite transformaciones de datos escalables y eficientes.
Por ejemplo, en un escenario de transformación típico, podría utilizar un flujo de datos para unir dos conjuntos de datos, agregar los resultados y escribir el resultado en un nuevo destino, todo ello de forma visual y sin servicios externos como Databricks.
Descripción: Esta pregunta evalúa tu capacidad para gestionar cambios dinámicos en el esquema durante la transformación de datos.
Ejemplo de respuesta: La deriva del esquema se refiere a los cambios en la estructura de los datos de origen a lo largo del tiempo.
Azure Data Factory soluciona la desviación de esquemas ofreciendo la opción Permitir desviación de esquemas en Flujos de datos de asignación. Esto permite que ADF se ajuste automáticamente a los cambios en el esquema de los datos entrantes, como la adición o eliminación de nuevas columnas, sin necesidad de redefinir todo el esquema.
Al habilitar la deriva del esquema, puedes configurar una canalización para asignar dinámicamente columnas incluso si cambia el esquema de origen.
Permitir la opción de desviación de esquema en Azure Data Factory. Fuente de la imagen: Microsoft
Descripción: Esta pregunta evalúa tu familiaridad con los métodos modernos de ingestión continua de datos frente al procesamiento por lotes.
Ejemplo de respuesta: El recurso CDC de ADF ofrece una forma sencilla de replicar continuamente los datos modificados de las fuentes (como una base de datos SQL o Cosmos) a un destino sin necesidad de utilizar una lógica de marca de agua compleja.
A diferencia de un activador de canalización estándar que se ejecuta según una programación, el recurso CDC se ejecuta de forma continua (o en micro lotes), programando automáticamente las inserciones, actualizaciones y eliminaciones en el origen y aplicándolas al destino. Es ideal para situaciones que requieren una sincronización de datos casi en tiempo real.
Las preguntas avanzadas de la entrevista profundizan en las funcionalidades más avanzadas de ADF, centrándose en la optimización del rendimiento, los casos de uso en el mundo real y las decisiones arquitectónicas avanzadas.
Estas preguntas tienen como objetivo evaluar tu experiencia con escenarios de datos complejos y tu capacidad para resolver problemas difíciles utilizando ADF.
Descripción: Esta pregunta evalúa tu capacidad para resolver problemas y mejorar la eficiencia del proceso.
Ejemplo de respuesta: Normalmente sigo varias estrategias para optimizar el rendimiento de una canalización de Azure Data Factory.
En primer lugar, me aseguro de aprovechar el paralelismo utilizando ejecuciones simultáneas de canalizaciones para procesar los datos en paralelo siempre que sea posible. También utilizo la partición dentro de la actividad de copia para dividir conjuntos de datos grandes y transferir fragmentos más pequeños de forma simultánea.
Otra optimización importante es seleccionar el tiempo de ejecución de integración adecuado en función de la fuente de datos y los requisitos de transformación. Por ejemplo, el uso de un IR autohospedado para datos locales puede acelerar las transferencias de los datos locales a la nube.
Además, habilitar la preparación en la actividad de copia puede mejorar el rendimiento al almacenar en búfer grandes conjuntos de datos antes de la carga final.
Descripción: Esta pregunta evalúa tu comprensión de la gestión segura de credenciales en ADF.
Ejemplo de respuesta: Azure Key Vault desempeña un papel fundamental en la protección de información confidencial, como cadenas de conexión, contraseñas y claves de API, dentro de Azure Data Factory. En lugar de codificar secretos en canalizaciones o servicios vinculados, utilizas Key Vault para almacenar y administrar estos secretos.
La canalización ADF puede recuperar de forma segura los secretos de Key Vault durante el tiempo de ejecución, lo que garantiza que las credenciales permanezcan protegidas y no queden expuestas en el código. Por ejemplo, al configurar un servicio vinculado para conectarse a una base de datos SQL de Azure, utilizaría una referencia secreta de Key Vault para autenticarte de forma segura.
Descripción: Esta pregunta comprueba tu familiaridad con el control de versiones y la implementación automatizada en ADF.
Ejemplo de respuesta: Azure Data Factory se integra con Azure DevOps o GitHub para flujos de trabajo de CI/CD. Normalmente configuro ADF para conectarse a un repositorio Git, lo que permite el control de versiones para canalizaciones, conjuntos de datos y servicios vinculados. El proceso consiste en crear ramas, realizar cambios en un entorno de desarrollo y, a continuación, confirmar esos cambios en el repositorio.
Para la implementación, ADF admite plantillas ARM que se pueden exportar y utilizar en diferentes entornos, como los de ensayo y producción. Mediante el uso de canalizaciones, puedo automatizar el proceso de implementación, garantizando que los cambios se prueben y promuevan de manera eficiente a través de diferentes entornos.
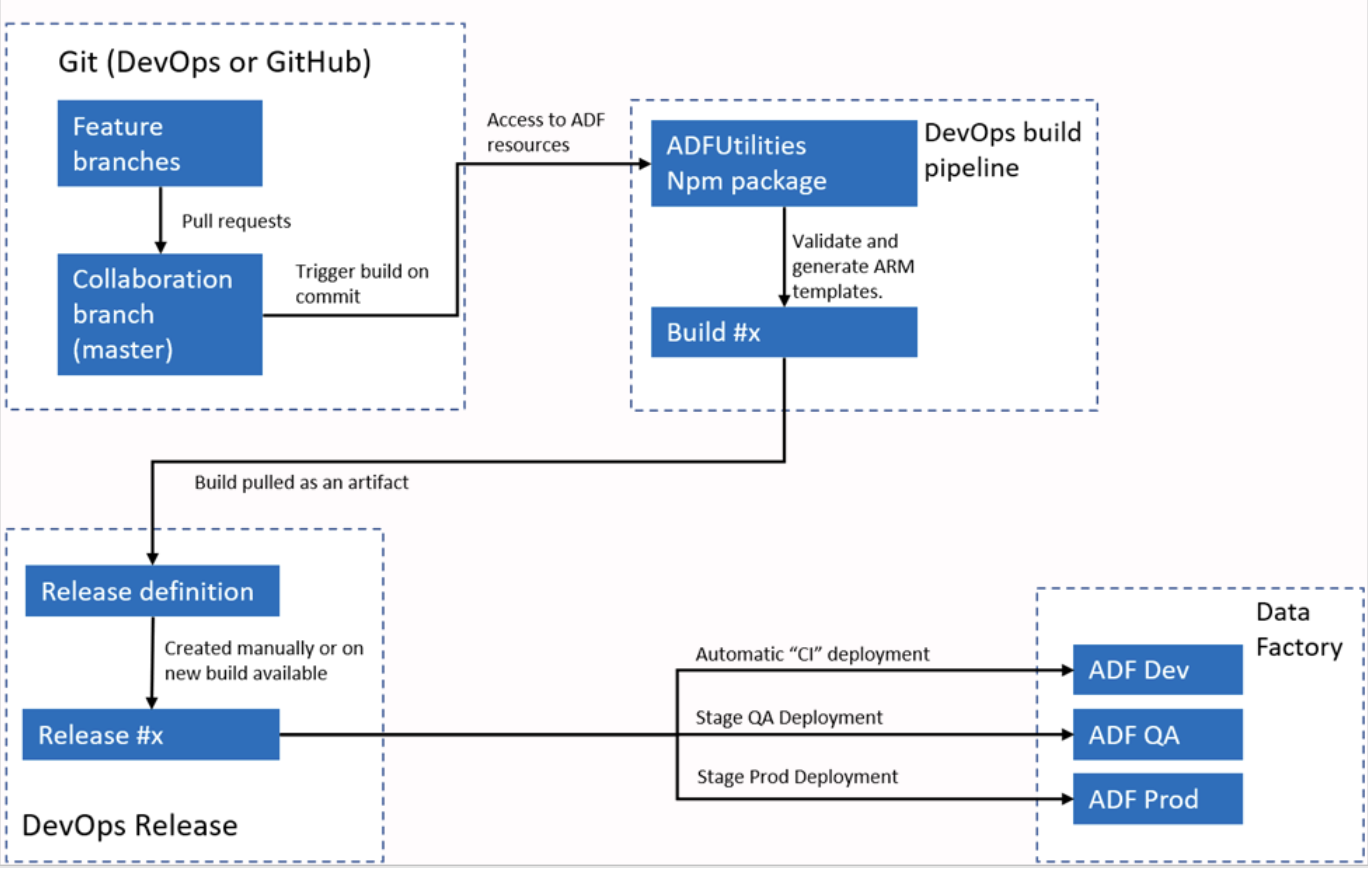
Flujo de trabajo automatizado de CI/CI de Azure Data Factory. Fuente de la imagene: Microsoft.
Descripción: Esta pregunta evalúa tu comprensión de las capacidades de ADF para gestionar entornos de datos híbridos.
Ejemplo de respuesta: El diseño de una canalización de datos híbrida con Azure Data Factory requiere el uso del tiempo de ejecución de integración (IR) autohospedado para conectar los entornos locales y en la nube. El IR se instala en un equipo dentro de la red local, lo que permite a ADF mover datos de forma segura entre recursos locales y en la nube, como Azure Blob Storage o Azure SQL Database.
Por ejemplo, cuando necesitas transferir datos de SQL Server local a Azure Data Lake, configurarías el IR autohospedado para acceder de forma segura a SQL Server, definirías los conjuntos de datos para el origen y el destino, y utilizarías una actividad de copia para mover los datos. También podría añadir transformaciones o pasos de limpieza utilizando flujos de datos de mapeo.
Descripción: Esta pregunta evalúa tu capacidad para configurar asignaciones de esquemas dinámicos en flujos de datos complejos.
Ejemplo de respuesta: El mapeo dinámico en un flujo de datos de mapeo permite flexibilidad cuando el esquema de datos de origen puede cambiar. Implemento el mapeo dinámico utilizando la función de mapeo automático en Flujo de datos, que asigna automáticamente las columnas de origen a las columnas de destino por nombre.
Utilizo columnas derivadas y lenguaje de expresión en flujos de datos para asignar o modificar dinámicamente columnas en función de sus metadatos para escenarios más complejos. Este enfoque resulta útil cuando se produce una deriva del esquema o cuando el canal de datos tiene que gestionar varios esquemas de origen diferentes sin necesidad de realizar una reasignación manual.
Descripción: Esta pregunta evalúa tu capacidad para diseñar canalizaciones que cumplan con los estándares de gobernanza de datos de la empresa.
Ejemplo de respuesta: ADF se integra de forma nativa con Microsoft Purview para enviar datos de linaje. Cuando se ejecuta una canalización, ADF envía metadatos a Purview que describen:
Esto permite a los administradores de datos visualizar el flujo de datos en toda la organización. Los conectas registrando la instancia de ADF en el portal de gobernanza de Purview.
Las preguntas de la entrevista basadas en el comportamiento y en situaciones hipotéticas se centran en cómo los candidatos aplican sus habilidades técnicas en situaciones reales.
Estas preguntas ayudan a evaluar las capacidades de resolución de problemas, solución de incidencias y optimización dentro de flujos de trabajo de datos complejos. También proporcionan información sobre el proceso de toma de decisiones del candidato y su experiencia en el manejo de retos relacionados con la integración de datos y los procesos ETL.
Descripción: Esta pregunta evalúa tus habilidades para resolver problemas, especialmente cuando se trata de fallos en el proceso o problemas inesperados.
Ejemplo de respuesta: En un proyecto, tuve un problema constante con el canal al intentar transferir datos desde un servidor SQL local a Azure Blob Storage.
Los registros de errores indicaban un problema de tiempo de espera durante el proceso de transferencia de datos. Para solucionar el problema, primero comprobé la configuración del tiempo de ejecución de integración (IR) autohospedado, que era responsable de la conexión de datos local.
Tras inspeccionarlo, descubrí que la máquina que alojaba el IR estaba consumiendo mucha potencia de CPU, lo que provocaba retrasos en la transferencia de datos.
Para resolver el problema, aumenté la potencia de procesamiento de la máquina y distribuí la carga de trabajo dividiendo los datos en fragmentos más pequeños mediante la configuración de la actividad Copiar.
Esto permitió el procesamiento paralelo de datos, lo que redujo los tiempos de carga y evitó los tiempos de espera. Tras los cambios, la canalización funcionó correctamente y se eliminó el error.
Descripción: Esta pregunta evalúa tu capacidad para identificar e implementar técnicas de optimización en flujos de trabajo de datos.
Ejemplo de respuesta: En un proyecto en el que teníamos que procesar grandes cantidades de datos financieros procedentes de múltiples fuentes, el proceso inicial tardaba demasiado en ejecutarse debido al volumen de datos. Para optimizar esto, inicialmente habilité el paralelismo configurando varias actividades de copia para que se ejecutaran simultáneamente, cada una de ellas gestionando una partición diferente del conjunto de datos.
A continuación, utilicé la función de almacenamiento temporal de la actividad Copiar para almacenar temporalmente los datos en Azure Blob Storage antes de seguir procesándolos, lo que mejoró significativamente el rendimiento. También usé optimizaciones de flujo de datos almacenando en caché las tablas de búsqueda utilizadas en las transformaciones.
Estos ajustes mejoraron el rendimiento del proceso en un 40 %, reduciendo el tiempo de ejecución.
Descripción: Esta pregunta comprueba cómo gestionas los cambios inesperados en el esquema y garantizas que los procesos sigan funcionando.
Ejemplo de respuesta: Sí, en uno de mis proyectos, el esquema de una fuente de datos (una API externa) cambió inesperadamente cuando se añadió una nueva columna al conjunto de datos. Esto provocó un fallo en el proceso, ya que el esquema del flujo de datos de asignación ya no estaba alineado.
Para solucionar este problema, habilité la opción Permitir desviación del esquema en el flujo de datos, lo que permitió que la canalización detectara y gestionara los cambios en el esquema de forma automática.
Además, configuré la asignación dinámica de columnas utilizando columnas derivadas, lo que garantizó que la nueva columna se capturara sin codificar nombres de columnas específicos. Esto garantizó que el canal pudiera adaptarse a futuros cambios de esquema sin intervención manual.
Descripción: Esta pregunta evalúa tu capacidad para gestionar la integración de datos de múltiples fuentes, un requisito habitual en los procesos ETL complejos.
Ejemplo de respuesta: En un proyecto reciente, necesitaba integrar datos de tres fuentes: un servidor SQL local, Azure Data Lake y una API REST. Utilicé una combinación de un tiempo de ejecución de integración autohospedado para la conexión con SQL Server local y un tiempo de ejecución de integración de Azure para los servicios basados en la nube.
Creé una canalización que utilizaba la actividad Copiar para extraer datos del servidor SQL y la API REST, transformarlos mediante flujos de datos de asignación y combinarlos con los datos almacenados en Azure Data Lake.
Al parametrizar los procesos, garanticé la flexibilidad en el manejo de diferentes conjuntos de datos y calendarios. Esto permitió la integración de datos procedentes de múltiples fuentes, lo cual era fundamental para la plataforma de análisis de datos del cliente.
Descripción: Esta pregunta examina cómo identificas y gestionas los problemas de calidad de los datos dentro de tus flujos de trabajo de canalización.
Ejemplo de respuesta: En un caso, estaba trabajando en un proceso que extraía datos de clientes de un sistema CRM. Sin embargo, los datos contenían valores faltantes y duplicados, lo que afectó el informe final. Para abordar estos problemas de calidad de los datos, incorporé un flujo de datos en el proceso que realizaba operaciones de limpieza de datos.
Utilicé filtros para eliminar duplicados y una división condicional para gestionar los valores que faltaban. He configurado una búsqueda de datos faltantes o incorrectos para extraer valores predeterminados de un conjunto de datos de referencia. Al final de este proceso, la calidad de los datos mejoró significativamente, lo que garantizó que los análisis posteriores fueran precisos y fiables.
Descripción: Esta pregunta evalúa tu experiencia con transformaciones de datos avanzadas utilizando ADF.
Ejemplo de respuesta: En un proyecto de información financiera, tuve que fusionar datos transaccionales de múltiples fuentes, aplicar agregaciones y generar informes resumidos para diferentes regiones. El reto era que cada fuente de datos tenía una estructura y una convención de nomenclatura ligeramente diferentes. Implementé la transformación utilizando flujos de datos de mapeo.
En primer lugar, estandaricé los nombres de las columnas en todos los conjuntos de datos utilizando columnas derivadas. A continuación, apliqué agregaciones para calcular métricas específicas de cada región, como las ventas totales y el valor medio de las transacciones. Por último, utilicé una transformación pivotante para reorganizar los datos y facilitar la elaboración de informes. Toda la transformación se realizó dentro de ADF, aprovechando sus transformaciones integradas y su infraestructura escalable.
Descripción: Esta pregunta evalúa tu comprensión de las prácticas de seguridad de datos en ADF.
Ejemplo de respuesta: En un proyecto, manejabais datos confidenciales de clientes que debían transferirse de forma segura desde un servidor SQL local a Azure SQL Database. Utilicé Azure Key Vault para almacenar las credenciales de la base de datos y proteger los datos, asegurándome de que la información confidencial, como las contraseñas, no quedara codificada en el canal o en los servicios vinculados.
Además, implementé el cifrado de datos durante el traslado de datos habilitando conexiones SSL entre el servidor SQL local y Azure.
También utilicé el control de acceso basado en roles (RBAC) para restringir el acceso al canal ADF, asegurándome de que solo los usuarios autorizados pudieran activarlo o modificarlo. Esta configuración garantizaba tanto la seguridad en la transferencia de datos como una gestión adecuada del acceso.
Descripción: Esta pregunta evalúa tu capacidad para implementar ejecuciones de canalizaciones basadas en eventos.
Ejemplo de respuesta: En un escenario, la canalización debía ejecutarse cada vez que se cargara un nuevo archivo con datos de ventas en Azure Blob Storage. Para implementar esto, usé un desencadenador basado en eventos en Azure Data Factory. El desencadenador se configuró para escuchar los eventos «Blob creado» en un contenedor específico y, tan pronto como se cargaba un nuevo archivo, se activaba automáticamente el canal.
Este enfoque basado en eventos garantizaba que el proceso solo se ejecutara cuando hubiera nuevos datos disponibles, lo que eliminaba la necesidad de ejecuciones manuales o programadas. A continuación, el proceso procesó el archivo, lo transformó y lo cargó en el almacén de datos para su posterior análisis.
Descripción: Esta pregunta evalúa tu experiencia en la migración de procesos ETL tradicionales a la nube utilizando ADF.
Ejemplo de respuesta: En un proyecto para migrar un proceso ETL basado en SSIS existente desde las instalaciones locales a la nube, utilicé Azure Data Factory con Azure-SSIS Integration Runtime.
En primer lugar, evalué los paquetes SSIS existentes para asegurarme de que fueran compatibles con ADF y realicé las modificaciones necesarias para gestionar fuentes de datos basadas en la nube.
Configuré Azure-SSIS IR para ejecutar los paquetes SSIS en la nube, manteniendo los flujos de trabajo existentes. Para el nuevo entorno en la nube, también sustituí algunas de las actividades ETL tradicionales por componentes ADF nativos, como Copy Activities y Mapping Data Flows, lo que mejoró el rendimiento general y la escalabilidad de los flujos de trabajo de datos.
Descripción: Esta pregunta evalúa tu madurez operativa y tu comprensión del modelo de facturación de ADF.
Ejemplo de respuesta: En primer lugar, analizaría el informe de consumo de ejecución de canalizaciones en Azure Monitor para identificar los factores que influyen en los costes (por ejemplo, un elevado número de horas de cálculo de flujo de datos o un exceso de llamadas a la API). Las estrategias de optimización comunes incluyen:
Prepararse para una entrevista sobre Azure Data Factory requiere un profundo conocimiento de los aspectos técnicos y prácticos de la plataforma. Es fundamental demostrar tus conocimientos sobre las características principales de ADF y tu capacidad para aplicarlas en situaciones reales.
Estos son mis mejores consejos para ayudarte a prepararte para la entrevista:
Azure Data Factory es una potente herramienta para crear soluciones ETL basadas en la nube, y los conocimientos especializados en ella son muy solicitados en el mundo de la ingeniería de datos.
En este artículo, hemos analizado preguntas esenciales para una entrevista, desde conceptos generales hasta cuestiones técnicas y basadas en situaciones hipotéticas, haciendo hincapié en la importancia de conocer las características y herramientas de ADF. Los ejemplos reales de gestión de canalizaciones, transformación de datos y resolución de problemas ilustran las habilidades fundamentales que se requieren en un entorno ETL basado en la nube.
Para profundizar en tus conocimientos sobre Microsoft Azure, te recomendamos que explores cursos básicos sobre la arquitectura, la administración y la gobernanza de Azure, como Introducción a Microsoft Azure, Introducción a la arquitectura y los servicios de Microsoft Azure e Introducción a la administración y la gobernanza de Microsoft Azure. Estos recursos ofrecen información valiosa sobre el ecosistema general de Azure, complementan tus conocimientos sobre Azure Data Factory y te preparan para una carrera exitosa en ingeniería de datos.
¡Obtén más información sobre Azure con estos cursos!
programa
Curso
Curso
blog
Josep Ferrer
15 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
9 min
blog
Nisha Arya Ahmed
15 min

